SQL Server memperkenalkan objek In-Memory OLTP di SQL Server 2014. Ada banyak batasan dalam rilis awal; beberapa telah ditangani di SQL Server 2016, dan diharapkan lebih banyak lagi yang akan dibahas di rilis berikutnya seiring dengan terus berkembangnya fitur. Sejauh ini, adopsi In-Memory OLTP tampaknya tidak terlalu meluas, tetapi seiring berkembangnya fitur, saya berharap lebih banyak klien akan mulai bertanya tentang implementasi. Seperti halnya perubahan skema atau kode utama, saya merekomendasikan pengujian menyeluruh untuk menentukan apakah OLTP Dalam Memori akan memberikan manfaat yang diharapkan. Dengan mengingat hal itu, saya tertarik untuk melihat bagaimana kinerja berubah untuk pernyataan INSERT, UPDATE, dan DELETE yang sangat sederhana dengan In-Memory OLTP. Saya berharap jika saya dapat mendemonstrasikan latching atau locking sebagai masalah dengan tabel berbasis disk, maka tabel dalam memori akan memberikan solusi, karena tabel tersebut bebas kunci dan gerendel.
Saya mengembangkan pengujian berikut kasus:
- Tabel berbasis disk dengan prosedur tersimpan tradisional untuk DML.
- Tabel Dalam Memori dengan prosedur tersimpan tradisional untuk DML.
- Tabel dalam Memori dengan prosedur yang dikompilasi secara native untuk DML.
Saya tertarik untuk membandingkan kinerja prosedur tersimpan tradisional dan prosedur yang dikompilasi secara asli, karena salah satu batasan dari prosedur yang dikompilasi secara asli adalah bahwa setiap tabel yang dirujuk harus dalam Memori. Sementara satu baris, modifikasi soliter mungkin umum di beberapa sistem, saya sering melihat modifikasi terjadi dalam prosedur tersimpan yang lebih besar dengan beberapa pernyataan (SELECT dan DML) mengakses satu atau lebih tabel. Dokumentasi OLTP Dalam Memori sangat menyarankan penggunaan prosedur yang dikompilasi secara asli untuk mendapatkan manfaat maksimal dalam hal kinerja. Saya ingin memahami seberapa besar peningkatan kinerjanya.
Penyiapan
Saya membuat database dengan filegroup yang dioptimalkan memori dan kemudian membuat tiga tabel berbeda dalam database (satu berbasis disk, dua dalam memori):
- DiskTable
- InMemory_Temp1
- InMemory_Temp2
DDL hampir sama untuk semua objek, memperhitungkan pada disk versus dalam memori jika sesuai. DDL DiskTable vs. DDL Dalam Memori:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
Saya juga membuat sembilan prosedur tersimpan – satu untuk setiap kombinasi tabel/modifikasi.
- DiskTable_Insert
- DiskTable_Update
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Update
- InMemRegularSP _Delete
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
Setiap prosedur tersimpan menerima input bilangan bulat untuk mengulang sejumlah modifikasi tersebut. Prosedur tersimpan mengikuti format yang sama, variasi hanya tabel yang diakses dan apakah objek dikompilasi secara asli atau tidak. Kode lengkap untuk membuat database dan objek dapat ditemukan di sini, dengan contoh pernyataan INSERT dan UPDATE di bawah ini:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Catatan:Tabel IDs_* diisi ulang setelah setiap set INSERT selesai, dan dikhususkan untuk tiga skenario berbeda.
Metodologi Pengujian
Pengujian dilakukan dengan menggunakan skrip .cmd yang menggunakan sqlcmd untuk memanggil skrip yang menjalankan prosedur tersimpan, misalnya:
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"keluar
Saya menggunakan pendekatan ini untuk membuat satu atau lebih koneksi ke database yang akan berjalan secara bersamaan. Selain memahami perubahan dasar pada kinerja, saya juga ingin memeriksa pengaruh beban kerja yang berbeda. Script ini dimulai dari mesin terpisah untuk menghilangkan overhead koneksi instantiating. Setiap prosedur tersimpan dieksekusi 1000 kali oleh koneksi, dan saya menguji 1 koneksi, 10 koneksi, dan 100 koneksi (masing-masing 1000, 10000, dan 100000 modifikasi). Saya menangkap metrik kinerja menggunakan Query Store, dan juga menangkap Statistik Tunggu. Dengan Query Store, saya dapat menangkap durasi rata-rata dan CPU untuk setiap prosedur tersimpan. Data statistik tunggu diambil untuk setiap koneksi menggunakan dm_exec_session_wait_stats, lalu dikumpulkan untuk keseluruhan pengujian.
Saya menjalankan setiap tes empat kali dan kemudian menghitung rata-rata keseluruhan untuk data yang digunakan dalam posting ini. Skrip yang digunakan untuk pengujian beban kerja dapat diunduh dari sini.
Hasil
Seperti yang bisa diprediksi, kinerja dengan objek Dalam Memori lebih baik daripada dengan objek berbasis disk. Namun, tabel Dalam Memori dengan prosedur tersimpan reguler terkadang memiliki kinerja yang sebanding atau hanya sedikit lebih baik dibandingkan dengan tabel berbasis disk dengan prosedur tersimpan reguler. Ingat:Saya tertarik untuk memahami apakah saya benar-benar membutuhkan prosedur tersimpan yang dikompilasi untuk mendapatkan manfaat besar dengan tabel dalam memori. Untuk skenario ini, saya melakukannya. Dalam semua kasus, tabel dalam memori dengan prosedur yang dikompilasi secara asli memiliki kinerja yang jauh lebih baik. Dua grafik di bawah ini menunjukkan data yang sama, tetapi dengan skala sumbu x yang berbeda, untuk menunjukkan kinerja tersebut untuk prosedur tersimpan reguler yang memodifikasi data yang diturunkan dengan koneksi yang lebih bersamaan.
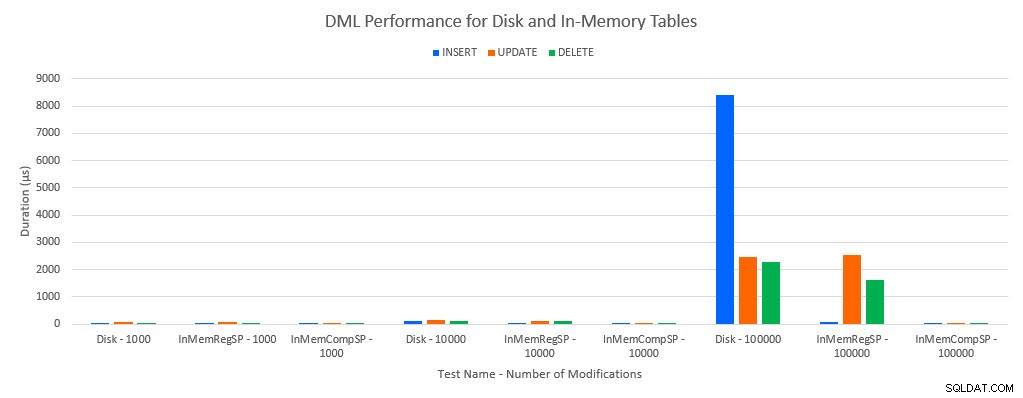
Kinerja DML menurut Pengujian dan Beban Kerja
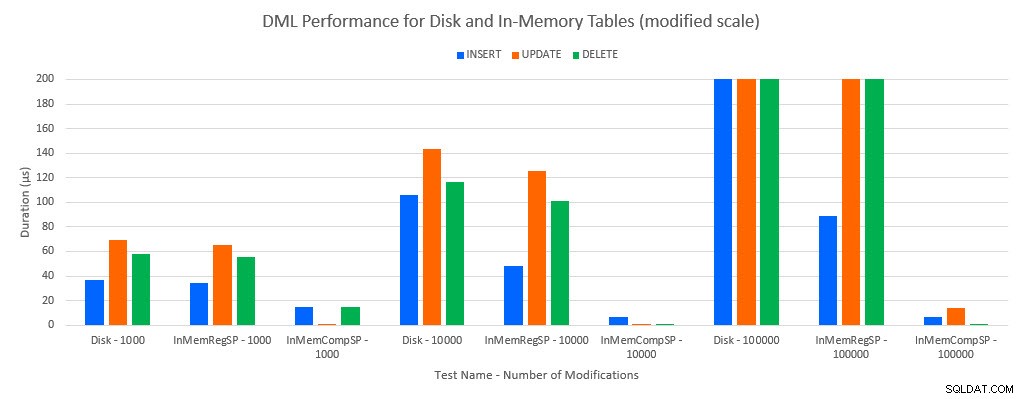
Kinerja DML menurut Pengujian dan Beban Kerja [Skala yang dimodifikasi]
Pengecualiannya adalah INSERT ke dalam tabel In-Memory dengan prosedur tersimpan reguler. Dengan 100 koneksi, durasi rata-rata lebih dari 8 md untuk tabel berbasis disk, tetapi kurang dari 100 mikrodetik untuk tabel Dalam Memori. Kemungkinan alasannya adalah tidak adanya penguncian dan penguncian dengan tabel Dalam Memori, dan ini didukung dengan data statistik tunggu:
Menunggu Statistik Berdasarkan Tes
Data statistik tunggu dicantumkan di sini berdasarkan Waktu Tunggu Sumber Daya Total (yang umumnya juga diterjemahkan ke waktu sumber daya rata-rata tertinggi, tetapi ada pengecualian). Jenis menunggu WRITELOG adalah faktor pembatas dalam sistem ini sebagian besar waktu. Namun, PAGELATCH_EX menunggu 100 koneksi bersamaan yang menjalankan pernyataan INSERT menunjukkan bahwa dengan beban tambahan, perilaku penguncian dan penguncian yang ada dengan tabel berbasis disk dapat menjadi faktor pembatas. Dalam skenario UPDATE dan DELETE dengan 10 dan 100 koneksi untuk pengujian tabel berbasis disk, Waktu Tunggu Sumber Daya Rata-rata adalah yang tertinggi untuk kunci (LCK_M_X).
Kesimpulan
OLTP dalam Memori benar-benar dapat memberikan peningkatan kinerja untuk beban kerja yang tepat. Namun, contoh yang diuji di sini sangat sederhana, dan tidak boleh dinilai sebagai alasan saja untuk bermigrasi ke solusi In-Memory. Ada beberapa batasan yang masih ada yang harus dipertimbangkan, dan pengujian menyeluruh harus dilakukan sebelum migrasi terjadi (terutama karena migrasi ke tabel In-Memory adalah proses offline). Tetapi untuk skenario yang tepat, fitur baru ini dapat memberikan peningkatan kinerja. Selama Anda memahami bahwa beberapa batasan mendasar akan tetap ada, seperti kecepatan log transaksi untuk tabel yang tahan lama, meskipun kemungkinan besar akan dikurangi – terlepas dari apakah tabel tersebut ada di disk atau di dalam memori.