Saat tumbuh dewasa, saya menyukai game yang menguji kemampuan memori dan pencocokan pola. Beberapa teman saya memiliki Simon, sementara saya memiliki tiruan yang disebut Einstein. Yang lain memiliki Atari Touch Me, yang bahkan saat itu saya tahu adalah keputusan penamaan yang dipertanyakan. Saat ini, pencocokan pola memiliki arti yang jauh berbeda bagi saya, dan dapat menjadi bagian mahal dari kueri basis data sehari-hari.
Saat tumbuh dewasa, saya menyukai game yang menguji kemampuan memori dan pencocokan pola. Beberapa teman saya memiliki Simon, sementara saya memiliki tiruan yang disebut Einstein. Yang lain memiliki Atari Touch Me, yang bahkan saat itu saya tahu adalah keputusan penamaan yang dipertanyakan. Saat ini, pencocokan pola memiliki arti yang jauh berbeda bagi saya, dan dapat menjadi bagian mahal dari kueri basis data sehari-hari.
Saya baru-baru ini menemukan beberapa komentar di Stack Overflow di mana pengguna menyatakan, seolah-olah fakta, bahwa CHARINDEX berkinerja lebih baik daripada LEFT atau LIKE . Dalam satu kasus, orang tersebut mengutip sebuah artikel oleh David Lozinski, "SQL:LIKE vs SUBSTRING vs LEFT/RIGHT vs CHARINDEX." Ya, artikel menunjukkan bahwa, dalam contoh yang dibuat-buat, CHARINDEX dilakukan terbaik. Namun, karena saya selalu skeptis tentang pernyataan menyeluruh seperti itu, dan tidak dapat memikirkan alasan logis mengapa satu fungsi string selalu tampil lebih baik dari yang lain, dengan semua yang lain sama , saya menjalankan tesnya. Benar saja, saya mendapatkan hasil yang berbeda pada mesin saya (klik untuk memperbesar):
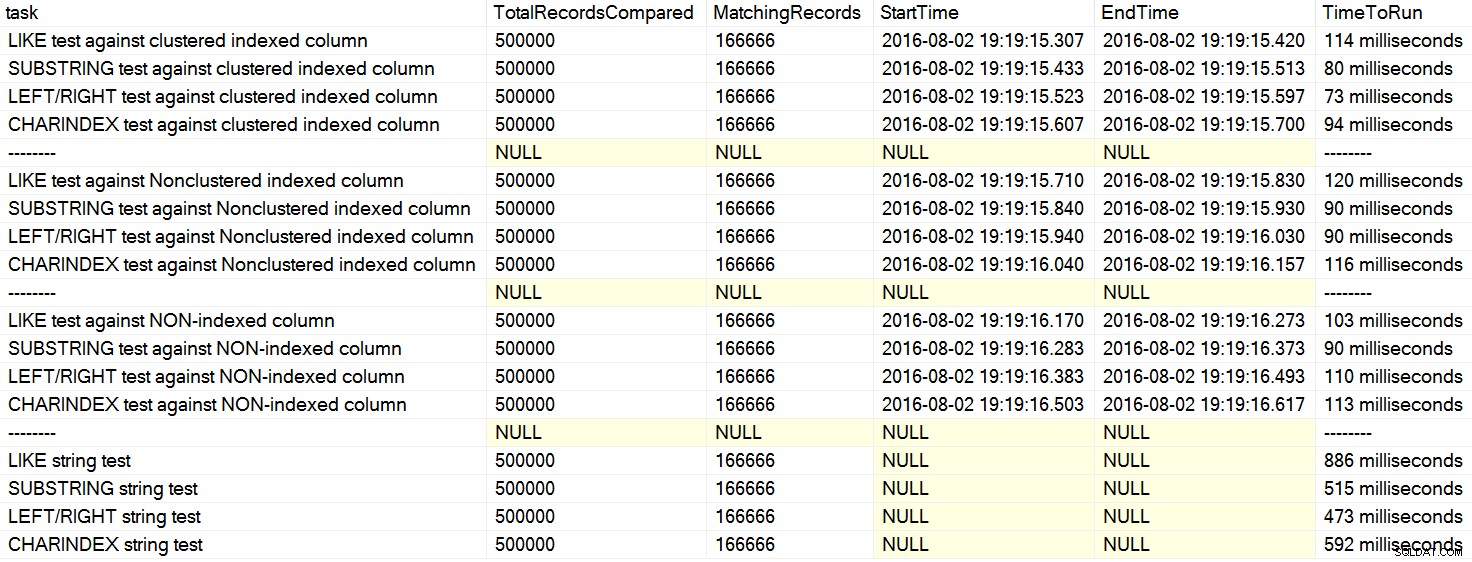 Di mesin saya, CHARINDEX lebih lambat daripada KIRI/KANAN/SUBSTRING.
Di mesin saya, CHARINDEX lebih lambat daripada KIRI/KANAN/SUBSTRING.
Pengujian David pada dasarnya membandingkan struktur kueri ini – mencari pola string baik di awal atau akhir nilai kolom – dalam hal durasi mentah:
WHERE Kolom LIKE @pattern + '%' ATAU Kolom LIKE '%' + @pattern; WHERE SUBSTRING(Kolom, 1, LEN(@pattern)) =@pattern OR SUBSTRING(Kolom, LEN(Kolom) - LEN(@pattern) + 1, LEN(@pattern)) =@pattern; DI MANA KIRI(Kolom, LEN(@pola)) =@pola ATAU KANAN(Kolom, LEN(@pola)) =@pola; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0)> 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern )), 0)> 0;
Hanya dengan melihat klausa ini, Anda dapat melihat mengapa CHARINDEX mungkin kurang efisien – ini membuat beberapa panggilan fungsional tambahan yang tidak harus dilakukan oleh pendekatan lain. Mengapa pendekatan ini bekerja paling baik pada mesin David, saya tidak yakin; mungkin dia menjalankan kode persis seperti yang diposting, dan tidak benar-benar menjatuhkan buffer di antara pengujian, sehingga pengujian terakhir mendapat manfaat dari data yang di-cache.
Secara teori, CHARINDEX dapat diekspresikan dengan lebih sederhana, misalnya:
WHERE CHARINDEX(@pattern, Column) =1 ATAU CHARINDEX(@pattern, Column) =LEN(Column) - LEN(@pattern) + 1;
(Tapi ini sebenarnya tampil lebih buruk dalam tes biasa saya.)
Dan mengapa ini bahkan OR kondisi, saya tidak yakin. Secara realistis, sebagian besar waktu Anda melakukan salah satu dari dua jenis penelusuran pola:dimulai dengan atau berisi (jauh lebih jarang mencari diakhiri dengan ). Dan dalam sebagian besar kasus tersebut, pengguna cenderung menyatakan di awal apakah mereka ingin dimulai dengan atau berisi , setidaknya di setiap lamaran yang pernah saya ikuti dalam karier saya.
Masuk akal untuk memisahkannya sebagai jenis kueri yang terpisah, daripada menggunakan ATAU kondisional, karena dimulai dengan dapat menggunakan indeks (jika ada yang cukup cocok untuk pencarian, atau lebih kurus dari indeks berkerumun), sedangkan diakhiri dengan tidak bisa (dan ATAU kondisi cenderung melempar kunci pas ke pengoptimal secara umum). Jika saya bisa mempercayai LIKE untuk menggunakan indeks ketika bisa, dan untuk tampil sebaik atau lebih baik daripada solusi lain di atas dalam sebagian besar atau semua kasus, maka saya dapat membuat logika ini sangat mudah. Prosedur tersimpan dapat mengambil dua parameter – pola yang dicari, dan jenis pencarian yang akan dilakukan (umumnya ada empat jenis pencocokan string – dimulai dengan, diakhiri dengan, berisi, atau sama persis).
CREATE PROCEDURE dbo.Search @pattern nvarchar(100), @option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains' -- dua yang terakhir didukung tetapi tidak akan diuji di siniASBEGIN SET NOCOUNT ON; SELECT ... WHERE Column LIKE -- jika berisi atau diakhiri dengan, perlu karakter pengganti CASE WHEN @option IN ('Contains','EndsWith') THEN N'%' ELSE N'' END + @pattern + -- if berisi atau dimulai dengan, membutuhkan karakter pengganti CASE WHEN @option IN ('Contains','StartsWith') THEN N'%' ELSE N'' END OPTION (RECOMPILE); SELESAI
Ini menangani setiap kasus potensial tanpa menggunakan SQL dinamis; OPTION (RECOMPILE) apakah ada karena Anda tidak ingin paket yang dioptimalkan untuk "berakhir dengan" (yang hampir pasti perlu dipindai) untuk digunakan kembali untuk kueri "dimulai dengan", atau sebaliknya; itu juga akan memastikan bahwa perkiraannya benar ("dimulai dengan S" mungkin memiliki kardinalitas yang jauh berbeda dari "dimulai dengan QX"). Bahkan jika Anda memiliki skenario di mana pengguna memilih satu jenis pencarian 99% dari waktu, Anda dapat menggunakan SQL dinamis di sini daripada mengkompilasi ulang, tetapi dalam kasus itu Anda masih rentan terhadap parameter sniffing. Dalam banyak kueri logika bersyarat, kompilasi ulang dan/atau SQL dinamis lengkap sering kali merupakan pendekatan yang paling masuk akal (lihat posting saya tentang "Dapur Wastafel").
Ujian
Karena saya baru-baru ini mulai melihat database sampel WideWorldImporters baru, saya memutuskan untuk menjalankan tes saya sendiri di sana. Sulit menemukan tabel berukuran layak tanpa indeks ColumnStore atau tabel riwayat temporal, tetapi Sales.Invoices , yang memiliki 70.510 baris, memiliki nvarchar(20) simple sederhana kolom bernama CustomerPurchaseOrderNumber yang saya putuskan untuk digunakan untuk tes. (Mengapa nvarchar(20) ketika setiap nilai adalah angka 5 digit, saya tidak tahu, tetapi pencocokan pola tidak terlalu peduli jika byte di bawahnya mewakili angka atau string.)
| Sales.Faktur CustomerPurchaseOrderNumber | ||
|---|---|---|
| Pola | # Baris | % dari Tabel |
| Dimulai dengan "1" | 70.505 | 99,993% |
| Dimulai dengan "2" | 5 | 0,007% |
| Diakhiri dengan "5" | 6.897 | 9,782% |
| Diakhiri dengan "30" | 749 | 1,062% |
Saya melihat-lihat nilai dalam tabel untuk menghasilkan beberapa kriteria pencarian yang akan menghasilkan jumlah baris yang sangat berbeda, semoga dapat mengungkapkan perilaku titik kritis apa pun dengan pendekatan tertentu. Di sebelah kanan adalah kueri penelusuran yang saya dapatkan.
Saya ingin membuktikan kepada diri saya sendiri bahwa prosedur di atas tidak dapat disangkal lebih baik secara keseluruhan untuk semua kemungkinan pencarian daripada kueri mana pun yang menggunakan OR kondisional, terlepas dari apakah mereka menggunakan LIKE , LEFT/RIGHT , SUBSTRING , atau CHARINDEX . Saya mengambil struktur kueri dasar David dan memasukkannya ke dalam prosedur tersimpan (dengan peringatan bahwa saya tidak dapat benar-benar menguji "berisi" tanpa masukannya, dan bahwa saya harus membuat OR-nya logika sedikit lebih fleksibel untuk mendapatkan jumlah baris yang sama), bersama dengan versi logika saya. Saya juga berencana untuk menguji prosedur dengan dan tanpa indeks yang akan saya buat di kolom pencarian, dan di bawah cache hangat dan dingin.
Prosedurnya:
BUAT PROSEDUR dbo.David_LIKE @pattern nvarchar(10), @option varchar(10) -- StartsWith atau EndsWithASBEGIN SET NOCOUNT ON; PILIH CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND CustomerPurchaseOrderNumber LIKE @pattern + N'%') OR (@option ='EndsWith' AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern) OPTION (REKOMPILASI);ENDGO CREATE PROCEDURE dbo.David_SUBSTRING @pattern nvarchar(10), @option varchar(10) -- StartsWith atau EndsWithASBEGIN SET NOCOUNT ON; PILIH CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)) =@pattern) OR (@option ='EndsWith' DAN SUBSTRING(CustomerPurchaseOrderNumber, LENOrderNumber, - LEN(@pattern) + 1, LEN(@pattern)) =@pattern) OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_LEFTRIGHT @pattern nvarchar(10), @option varchar(10) -- StartsWith atau EndsWithASBEGIN SET NOCOUNT PADA; PILIH CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern) OR (@option ='EndsWith' AND RIGHT(CustomerPurchaseOrderNumber), LEN(@pattern) =@pattern) OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_CHARINDEX @pattern nvarchar(10), @option varchar(10) -- StartsWith atau EndsWithASBEGIN SET NOCOUNT ON; PILIH CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)), 0)> 0) ATAU (@option ='EndsWith' DAN CHARINDEX (@pattern, SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1, LEN(@pattern)), 0)> 0) OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.Aaron_Conditional @pattern nvarchar(10) , @option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'ASBEGIN SET NOCOUNT ON; PILIH CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE CustomerPurchaseOrderNumber LIKE -- jika berisi atau diakhiri dengan, perlu karakter pengganti CASE WHEN @option IN ('Contains','EndsWith') THEN N'%' ELSE N'' END + @pattern + -- jika berisi atau dimulai dengan, memerlukan karakter pengganti CASE WHEN @option IN ('Contains','StartsWith') THEN N'%' ELSE N'' END OPTION (RECOMPILE); SELESAI
Saya juga membuat versi prosedur David sesuai dengan maksud aslinya, dengan asumsi persyaratannya adalah menemukan baris di mana pola pencarian berada di awal *atau* akhir string. Saya melakukan ini hanya agar saya dapat membandingkan kinerja pendekatan yang berbeda, persis seperti yang dia tulis, untuk melihat apakah pada kumpulan data ini hasil saya akan cocok dengan pengujian saya terhadap skrip aslinya di sistem saya. Dalam hal ini tidak ada alasan untuk memperkenalkan versi saya sendiri, karena itu hanya akan cocok dengan LIKE % + @pattern OR LIKE @pattern + % variasi.
BUAT PROSEDUR dbo.David_LIKE_Original @pattern nvarchar(10)ASBEGIN SET NOCOUNT ON; PILIH CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%' OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_SUBSTRING_Original @pattern_Original PILIH CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)) =@pattern ATAU SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1, LEN(@pattern) =@ pattern OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_LEFTRIGHT_Original @pattern nvarchar(10)ASBEGIN SET NOCOUNT ON; PILIH CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern OPSI (RECOMPILE);ENDGO CREATE PROCED_CREATE (10) ASMULAI SET NOCOUNT ON; PILIH CustomerPurchaseOrderNumber, OrderID DARI Penjualan.Faktur WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)), 0)> 0 ATAU CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, LEN(PelangganPurchase) - LOrderN(@Purchase ) + 1, LEN(@pattern)), 0)> 0 OPTION (RECOMPILE);ENDGO
Dengan prosedur yang ada, saya dapat membuat kode pengujian – yang seringkali sama menyenangkannya dengan masalah aslinya. Pertama, tabel logging:
DROP TABLE JIKA ADA dbo.LoggingTable;GOSET NOCOUNT ON; CREATE TABLE dbo.LoggingTable( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), durasi int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME());Kemudian kode yang akan melakukan operasi pilih menggunakan berbagai prosedur dan argumen:
ATUR NOCOUNT AKTIF;;DENGAN prc(nama) AS ( SELECT name FROM sys.procedures WHERE LEFT(name,5) IN (N'David', N'Aaron')),args(opt,pattern) AS ( SELECT 'StartsWith', N' 1' UNION ALL SELECT 'StartsWith', N'2' UNION ALL SELECT 'EndsWith', N'5' UNION ALL SELECT 'EndsWith', N'30'),frame(w) AS ( SELECT 'BeforeIndex' UNION ALL SELECT 'AfterIndex'),y AS( -- beri komentar baris 2-4 di sini jika kita ingin cache hangat SELECT cmd ='GO DBCC FREEPROCCACHE() WITH NO_INFOMSGS; DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS; GO DECLARE @d datetime2, @delta int; SET @d =SYSUTCDATETIME(); EXEC dbo.' + prc.name + ' @pattern =N''' + args.pattern + '''' + CASE WHEN prc.name LIKE N'%_Original' THEN '' ELSE ',@option =''' + args.opt + '''' END + '; SET @delta =DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME()); INSERT dbo.LoggingTable(prc,opt,pattern,frame ,durasi) SELECT N''' + prc.name + ''',''' + args.opt + ''',N''' + args.pattern + ''',''' + frame.w + ''',@delta; ', *, rn =ROW_NUMBER() LEBIH (PARTITIO N BY frame.w ORDER BY frame.w DESC, LEN(prc.name), args.opt DESC, args.pattern) FROM prc CROSS JOIN args CROSS JOIN frame)SELECT cmd =cmd + CASE WHEN rn =36 THEN CASE WHEN w ='BeforeIndex' THEN 'CREATE INDEX testing ON '+ 'Sales.Invoices(CustomerPurchaseOrderNumber); ' LAINNYA 'TURUNKAN INDEKS Penjualan.Faktur.pengujian;' END ELSE '' END--, nama, pilihan, pola, w, rn FROM yORDER BY w DESC, rn;Hasil
Saya menjalankan tes ini pada mesin virtual, menjalankan Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149), dengan 4 CPU dan 32 GB RAM. Saya menjalankan setiap rangkaian tes 11 kali; untuk tes cache hangat, saya membuang kumpulan hasil pertama karena beberapa di antaranya benar-benar tes cache dingin.
Saya berjuang dengan cara membuat grafik hasil untuk menunjukkan pola, sebagian besar karena tidak ada pola. Hampir setiap metode adalah yang terbaik dalam satu skenario dan terburuk dalam skenario lainnya. Dalam tabel berikut, saya menyoroti prosedur dengan kinerja terbaik dan terburuk untuk setiap kolom, dan Anda dapat melihat bahwa hasilnya jauh dari meyakinkan:
Dalam pengujian ini, terkadang CHARINDEX menang, dan terkadang tidak.
Apa yang saya pelajari adalah bahwa, secara keseluruhan, jika Anda akan menghadapi banyak situasi berbeda (berbagai jenis pencocokan pola, dengan indeks pendukung atau tidak, data tidak selalu ada di memori), sebenarnya tidak ada pemenang yang jelas, dan kisaran kinerja rata-rata cukup kecil (pada kenyataannya, karena cache hangat tidak selalu membantu, saya menduga hasilnya lebih dipengaruhi oleh biaya rendering hasil daripada mengambilnya). Untuk skenario individu, jangan mengandalkan pengujian saya; jalankan sendiri beberapa tolok ukur berdasarkan perangkat keras, konfigurasi, data, dan pola penggunaan Anda.
Peringatan
Beberapa hal yang tidak saya pertimbangkan untuk tes ini:
- Berkelompok vs. tidak mengelompok . Karena kecil kemungkinan indeks berkerumun Anda akan berada di kolom tempat Anda melakukan pencarian pencocokan pola terhadap awal atau akhir string, dan karena pencarian sebagian besar akan sama dalam kedua kasus (dan perbedaan antara pemindaian sebagian besar akan menjadi fungsi lebar indeks vs lebar tabel), saya hanya menguji kinerja menggunakan indeks non-cluster. Jika Anda memiliki skenario khusus di mana perbedaan ini saja membuat perbedaan besar pada pencocokan pola, beri tahu saya.
- MAX jenis . Jika Anda mencari string dalam
varchar(max)/nvarchar(max), itu tidak dapat diindeks, jadi kecuali jika Anda menggunakan kolom yang dihitung untuk mewakili bagian dari nilai, pemindaian akan diperlukan – apakah Anda mencari dimulai dengan, diakhiri dengan, atau berisi. Apakah overhead kinerja berkorelasi dengan ukuran string, atau overhead tambahan diperkenalkan hanya karena jenisnya, saya tidak mengujinya.
- Penelusuran teks lengkap . Saya telah bermain dengan fitur ini di sini dan di sana, dan saya dapat mengejanya, tetapi jika pemahaman saya benar, ini hanya dapat membantu jika Anda mencari kata-kata tanpa henti secara keseluruhan, dan tidak peduli di mana kata itu berada. ditemukan. Tidak akan berguna jika Anda menyimpan paragraf teks dan ingin menemukan semua paragraf yang dimulai dengan "Y", mengandung kata "the", atau diakhiri dengan tanda tanya.
Ringkasan
Satu-satunya pernyataan selimut yang dapat saya buat dengan berjalan menjauh dari tes ini adalah bahwa tidak ada pernyataan menyeluruh tentang apa cara paling efisien untuk melakukan pencocokan pola string. Sementara saya bias terhadap pendekatan bersyarat saya untuk fleksibilitas dan pemeliharaan, itu bukan pemenang kinerja di semua skenario. Bagi saya, kecuali saya mencapai hambatan kinerja dan saya mengejar semua jalan, saya akan terus menggunakan pendekatan saya untuk konsistensi. Seperti yang saya sarankan di atas, jika Anda memiliki skenario yang sangat sempit dan sangat sensitif terhadap perbedaan kecil dalam durasi, Anda sebaiknya menjalankan pengujian Anda sendiri untuk menentukan metode mana yang secara konsisten berkinerja terbaik untuk Anda.