Baru-baru ini, saya terlibat dalam pengembangan fungsionalitas yang membutuhkan transfer data dalam volume besar yang cepat dan sering ke disk. Selain itu, data ini seharusnya dibaca dari disk dari waktu ke waktu. Oleh karena itu, saya ditakdirkan untuk mencari tahu tempat, cara dan sarana untuk menyimpan data ini. Dalam artikel ini, saya akan meninjau tugas secara singkat, serta menyelidiki dan membandingkan solusi untuk penyelesaian tugas ini.
Konteks tugas :Saya bekerja dalam tim yang mengembangkan alat untuk pengembangan basis data relatif (SQL Server, MySQL, Oracle). Rentang alat mencakup keduanya, alat mandiri, dan add-in untuk MS SSMS.
Tugas :Memulihkan dokumen yang dibuka pada saat IDE ditutup pada awal IDE berikutnya.
Kasus Penggunaan :Untuk menutup IDE dengan cepat sebelum meninggalkan kantor tanpa memikirkan dokumen mana yang disimpan, dan mana yang tidak. Pada awal IDE berikutnya, kita perlu mendapatkan lingkungan yang sama dengan saat menutup dan melanjutkan pekerjaan. Semua hasil pekerjaan harus disimpan pada saat penutupan tidak teratur, mis. selama crash program atau sistem operasi, atau selama power-off.
Analisis tugas :Fitur serupa hadir di browser web. Namun, browser hanya menyimpan URL yang terdiri dari sekitar 100 simbol. Dalam kasus kami, kami perlu menyimpan seluruh konten dokumen. Oleh karena itu, diperlukan suatu tempat untuk menyimpan dan menyimpan dokumen pengguna. Terlebih lagi, terkadang pengguna bekerja dengan SQL dengan cara yang berbeda dibandingkan dengan bahasa lain. Misalnya, jika saya menulis kelas C# dengan panjang lebih dari 1000 baris, itu hampir tidak dapat diterima. Sementara, di alam semesta SQL, bersama dengan kueri 10-20 baris, ada dump database yang mengerikan. Dump seperti itu hampir tidak dapat diedit, yang berarti bahwa pengguna lebih memilih untuk menyimpan hasil edit mereka dengan aman.
Persyaratan untuk penyimpanan:
- Ini harus menjadi solusi tertanam yang ringan.
- Harus memiliki kecepatan menulis yang tinggi.
- Ini harus memiliki opsi akses multiprosesor. Persyaratan ini tidak penting, karena kami dapat memastikan akses dengan bantuan objek sinkronisasi, tetapi tetap saja, akan menyenangkan untuk memiliki opsi ini.
Calon
Kandidat pertama agak canggung, yaitu menyimpan semuanya di folder, di suatu tempat di AppData.
Kandidat kedua jelas – SQLite, standar database tertanam. Kandidat yang sangat solid dan populer.
Kandidat ketiga adalah database LiteDB. Ini adalah hasil pertama untuk kueri “basis data tertanam untuk .net” di Google.
Penglihatan pertama
Berkas sistem. File adalah file, mereka membutuhkan pemeliharaan dan penamaan yang tepat. Selain konten file, kita perlu menyimpan satu set kecil properti (jalur asli pada disk, string koneksi, versi IDE, di mana ia dibuka). Artinya, kita harus membuat dua file untuk satu dokumen, atau menciptakan format yang memisahkan properti dari konten.
SQLite adalah database relasional klasik. Basis data diwakili oleh satu file pada disk. File ini terikat dengan skema database, setelah itu kita harus berinteraksi dengannya dengan bantuan sarana SQL. Kami akan dapat membuat 2 tabel, satu untuk properti, dan satu lagi untuk konten, – jika kami perlu menggunakan properti atau konten secara terpisah.
LiteDB adalah database non-relasional. Mirip dengan SQLite, database diwakili oleh satu file. Itu seluruhnya ditulis dalam #. Ini memiliki kesederhanaan penggunaan yang menawan:kita hanya perlu memberikan objek ke perpustakaan, sementara serialisasi akan dilakukan dengan caranya sendiri.
Uji kinerja
Sebelum memberikan kode, saya ingin menjelaskan konsepsi umum dan memberikan hasil perbandingan.
Konsepsi umum adalah membandingkan kecepatan menulis sejumlah besar file kecil ke database, jumlah rata-rata file rata-rata, dan sejumlah kecil file besar. Kasus dengan file rata-rata sebagian besar mendekati kasus nyata, sedangkan kasus dengan file kecil dan besar adalah kasus batas, yang juga harus diperhitungkan.
Saya sedang menulis konten ke dalam file dengan bantuan FileStream dengan ukuran buffer standar.
Ada satu nuansa dalam SQLite yang ingin saya sebutkan. Kami tidak dapat menempatkan semua konten dokumen (seperti yang saya sebutkan di atas, mereka bisa sangat besar) ke dalam satu sel database. Masalahnya adalah untuk tujuan optimasi, kami menyimpan teks dokumen baris demi baris. Artinya, untuk memasukkan teks ke dalam satu sel, kita perlu meletakkan semua dokumen ke dalam satu baris, yang akan menggandakan jumlah memori operasi yang digunakan. Sisi lain dari masalah akan muncul dengan sendirinya selama data dibaca dari database. Itu sebabnya, ada tabel terpisah di SQLite, di mana data disimpan baris demi baris dan data ditautkan dengan bantuan kunci asing dengan tabel yang hanya berisi properti file. Selain itu, saya berhasil mempercepat database dengan memasukkan data batch (beberapa ribu baris sekaligus) dalam mode sinkronisasi OFF tanpa login dan dalam satu transaksi.
LiteDB menerima objek yang memiliki Daftar di antara propertinya dan perpustakaan menyimpannya ke disk sendiri.
Selama pengembangan aplikasi pengujian, saya mengerti bahwa saya lebih suka LiteDB. Masalahnya adalah kode pengujian untuk SQLite membutuhkan lebih dari 120 baris, sedangkan kode, yang memecahkan masalah yang sama di LiteDb, hanya membutuhkan 20 baris.
Uji Pembuatan Data
FileStrings.cs
kelas internal FileStrings { private static readonly Random random =new Random(); String Daftar publik { dapatkan; mengatur; } =Daftar baru(); public int SomeInfo { dapatkan; mengatur; } public FileStrings() { } public FileStrings(int id, int minLines, desimal lineIncrement) { SomeInfo =id; int baris =minLines + (int)(id * lineIncrement); for (int i =0; i new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (desimal)NUM_FILES)) .ToList();
SQLite
private static void SaveToDb(Daftar file) { using (koneksi var =new SQLiteConnection()) { koneksi.ConnectionString =@"Sumber Data=data\database.db;FailIfMissing=False;"; koneksi.Buka(); perintah var =koneksi.CreateCommand(); command.CommandText =@"CREATE TABLE files( id INTEGER PRIMARY KEY, file_name TEXT);CREATE TABLE strings( id INTEGER PRIMARY KEY, string TEXT, file_id INTEGER, line_number INTEGER);CREATE UNIQUE INDEX strings_file_id_line_number_uindex ON, string_uindex ON; PRAGMA sinkron =OFF;PRAGMA journal_mode =OFF"; perintah.ExecuteNonQuery(); var insertFilecommand =koneksi.CreateCommand(); insertFilecommand.CommandText ="INSERT INTO files(file_name) VALUES(?); SELECT last_insert_rowid();"; insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter()); insertFilecommand.Prepare(); var insertLineCommand =koneksi.CreateCommand(); insertLineCommand.CommandText ="INSERT INTO strings(string, file_id, line_number) VALUES(?, ?, ?);"; insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Prepare(); foreach (var item dalam file) { using (var tr =connection.BeginTransaction()) { SaveToDb(item, insertFilecommand, insertLineCommand); tr.Komit(); } } } } private static void SaveToDb(item FileStrings, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) { string namafile =Path.Combine("data", item.SomeInfo + ".sql"); insertFileCommand.Parameters[0].Value =namafile; var fileId =insertFileCommand.ExecuteScalar(); int barisIndeks =0; foreach (baris var di item.Strings) { insertLinesCommand.Parameters[0].Value =baris; insertLinesCommand.Parameters[1].Value =fileId; insertLinesCommand.Parameters[2].Nilai =lineIndex++; insertLinesCommand.ExecuteNonQuery(); } }
LiteDB
private static void SaveToNoSql(Daftar item) { using (var db =new LiteDatabase("data\\litedb.db")) { var data =db.GetCollection("file"); data.EnsureIndex(f => f.SomeInfo); data.Insert(item); } }
Tabel berikut menunjukkan hasil rata-rata untuk beberapa kali kode pengujian. Selama modifikasi, penyimpangan statistik cukup terlihat.
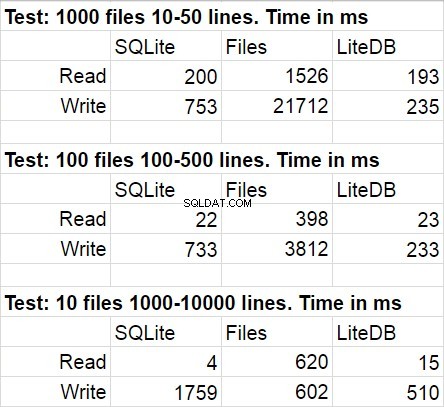
Saya tidak terkejut bahwa LiteDB menang dalam perbandingan ini. Namun, saya terkejut dengan kemenangan LiteDB atas file. Setelah studi singkat tentang repositori perpustakaan, saya menemukan bahwa penulisan paginal ke disk diimplementasikan dengan sangat cermat, tetapi saya yakin ini hanya salah satu dari banyak trik kinerja yang digunakan di sana. Satu hal lagi yang ingin saya tunjukkan adalah kecepatan akses sistem file yang cepat berkurang ketika jumlah file dalam folder menjadi sangat besar.
Kami memilih LiteDB untuk pengembangan fitur kami, dan kami hampir tidak menyesali pilihan ini. Masalahnya adalah pustaka ditulis dalam bahasa asli untuk semua orang C#, dan jika ada yang kurang jelas, kita selalu dapat merujuk ke kode sumber.
Kontra
Selain kelebihan LiteDB yang disebutkan di atas dibandingkan dengan pesaingnya, kami mulai memperhatikan kontra selama pengembangan. Sebagian besar kontra ini dapat dijelaskan oleh 'pemuda' perpustakaan. Setelah mulai menggunakan perpustakaan sedikit di luar batas skenario 'standar', kami menemukan beberapa masalah (#419, #420, #483, #496). Penulis perpustakaan menjawab pertanyaan dengan cukup cepat, dan sebagian besar masalah diselesaikan dengan cepat. Sekarang, hanya satu tugas yang tersisa (jangan bingung dengan statusnya Tertutup). Ini adalah masalah akses kompetitif. Sepertinya kondisi balapan yang sangat buruk bersembunyi di suatu tempat jauh di dalam perpustakaan. Kami melewati bug ini dengan cara yang cukup orisinal (saya bermaksud untuk menulis artikel terpisah tentang hal ini).
Saya juga ingin menyebutkan tidak adanya editor dan penampil yang rapi. Ada LiteDBShell, tetapi hanya untuk penggemar konsol sejati.
Ringkasan
Kami telah membangun fungsionalitas besar dan penting di atas LiteDB, dan sekarang kami sedang mengerjakan fitur besar lainnya di mana kami akan menggunakan perpustakaan ini juga. Bagi mereka yang mencari database dalam proses, saya sarankan untuk memperhatikan LiteDB dan cara itu akan membuktikan dirinya dalam konteks tugas Anda, karena, seperti yang Anda tahu, jika sesuatu berhasil untuk satu tugas, itu belum tentu mengerjakan tugas lain.