Masalah kinerja yang sering saya lihat adalah ketika pengguna harus mencocokkan bagian dari string dengan kueri seperti berikut:
... WHERE SomeColumn LIKE N'%SomePortion%';
Dengan wildcard terkemuka, predikat ini "non-SARGable" – hanya cara yang bagus untuk mengatakan bahwa kami tidak dapat menemukan baris yang relevan dengan menggunakan pencarian terhadap indeks di SomeColumn .
Salah satu solusi yang kami dapatkan adalah pencarian teks lengkap; namun, ini adalah solusi yang kompleks, dan memerlukan pola pencarian yang terdiri dari kata-kata lengkap, tidak menggunakan kata-kata berhenti, dan seterusnya. Ini dapat membantu jika kita mencari baris yang deskripsinya berisi kata "soft" (atau turunan lain seperti "softer" atau "softly"), tetapi tidak membantu saat kita mencari string yang dapat ditampung dalam kata-kata (atau yang bukan kata-kata sama sekali, seperti semua SKU produk yang berisi "X45-B" atau semua plat nomor yang berisi urutan "7RA").
Bagaimana jika SQL Server entah bagaimana tahu tentang semua kemungkinan bagian dari sebuah string? Proses berpikir saya sejalan dengan trigram / trigraph di PostgreSQL. Konsep dasarnya adalah bahwa mesin memiliki kemampuan untuk melakukan pencarian gaya titik pada substring, artinya Anda tidak perlu memindai seluruh tabel dan mengurai setiap nilai penuh.
Contoh spesifik yang mereka gunakan adalah kata cat . Selain kata lengkap, dapat dipecah menjadi beberapa bagian:c , ca , dan at (mereka meninggalkan a dan t menurut definisi - tidak ada substring tambahan yang lebih pendek dari dua karakter). Di SQL Server, kita tidak perlu rumit; kita hanya benar-benar membutuhkan setengah trigram – jika kita berpikir tentang membangun struktur data yang berisi semua substring cat , kita hanya membutuhkan nilai berikut:
- kucing
- di
- t
Kami tidak membutuhkan c atau ca , karena siapa pun yang mencari LIKE '%ca%' dapat dengan mudah menemukan nilai 1 dengan menggunakan LIKE 'ca%' sebagai gantinya. Demikian pula, siapa pun yang menelusuri LIKE '%at%' atau LIKE '%a%' dapat menggunakan karakter pengganti hanya untuk ketiga nilai ini dan menemukan nilai yang cocok (mis. LIKE 'at%' akan menemukan nilai 2, dan LIKE 'a%' juga akan menemukan nilai 2, tanpa harus menemukan substring tersebut di dalam nilai 1, dari situlah rasa sakit yang sebenarnya akan datang).
Jadi, mengingat SQL Server tidak memiliki bawaan seperti ini, bagaimana kita menghasilkan trigram seperti itu?
Tabel Fragmen Terpisah
Saya akan berhenti merujuk "trigram" di sini karena ini tidak benar-benar analog dengan fitur itu di PostgreSQL. Pada dasarnya, apa yang akan kita lakukan adalah membuat tabel terpisah dengan semua "fragmen" dari string asli. (Jadi di cat contoh, akan ada tabel baru dengan tiga baris tersebut, dan LIKE '%pattern%' pencarian akan diarahkan ke tabel baru itu sebagai LIKE 'pattern%' predikat.)
Sebelum saya mulai menunjukkan bagaimana solusi yang saya usulkan akan bekerja, izinkan saya menjelaskan bahwa solusi ini tidak boleh digunakan dalam setiap kasus di mana LIKE '%wildcard%' pencarian lambat. Karena cara kita akan "meledak" data sumber menjadi fragmen, kemungkinan praktisnya terbatas pada string yang lebih kecil, seperti alamat atau nama, sebagai lawan dari string yang lebih besar, seperti deskripsi produk atau abstrak sesi.
Contoh yang lebih praktis daripada cat adalah dengan melihat Sales.Customer tabel di database sampel WideWorldImporters. Ini memiliki baris alamat (keduanya nvarchar(60) ), dengan info alamat yang berharga di kolom DeliveryAddressLine2 (untuk alasan yang tidak diketahui). Seseorang mungkin mencari siapa saja yang tinggal di jalan bernama Hudecova , jadi mereka akan menjalankan pencarian seperti ini:
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
*/ Seperti yang Anda harapkan, SQL Server perlu melakukan pemindaian untuk menemukan dua baris tersebut. Yang seharusnya sederhana; namun, karena kerumitan tabel, kueri sepele ini menghasilkan rencana eksekusi yang sangat berantakan (pemindaian disorot, dan memiliki peringatan untuk I/O sisa):
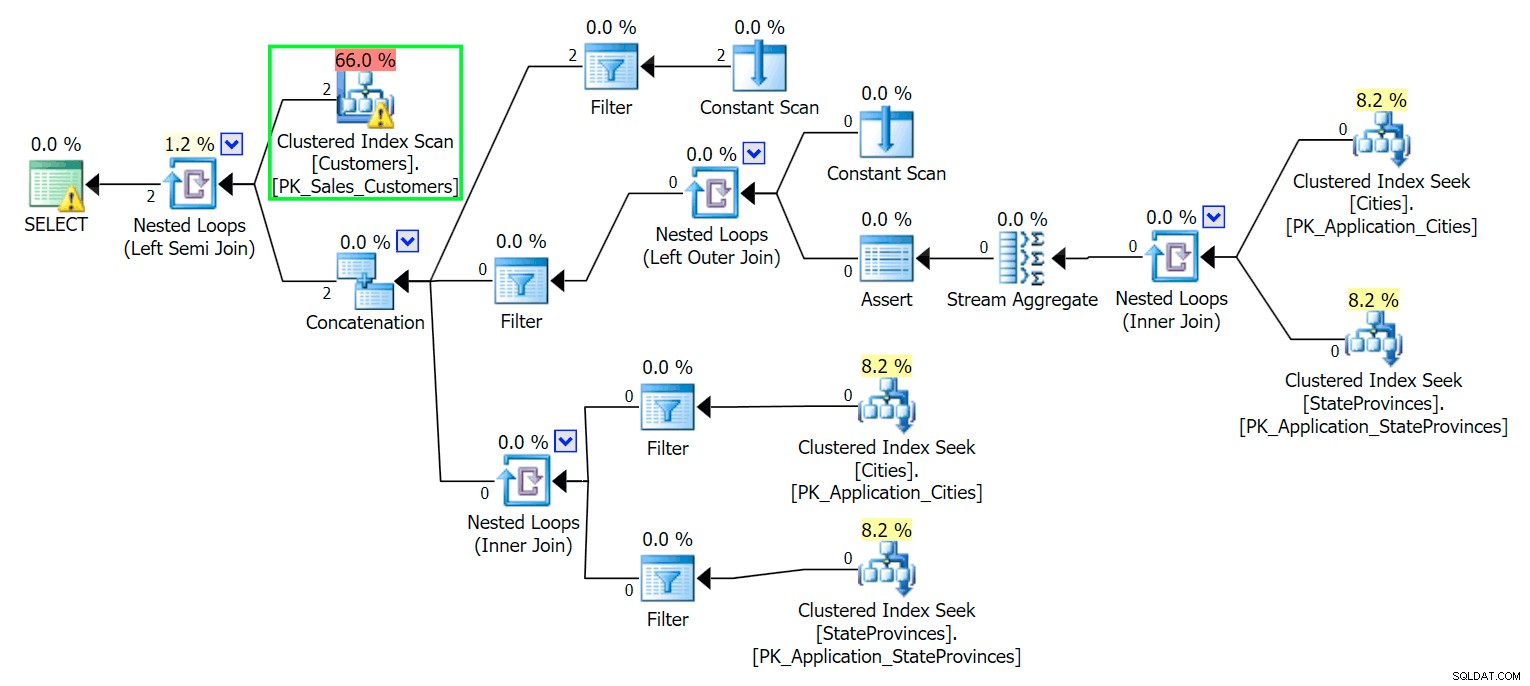
pemutih. Untuk menjaga hidup kita tetap sederhana, dan untuk memastikan kita tidak mengejar sekelompok ikan haring merah, mari buat tabel baru dengan subset kolom, dan untuk memulai kita cukup memasukkan dua baris yang sama dari atas:
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
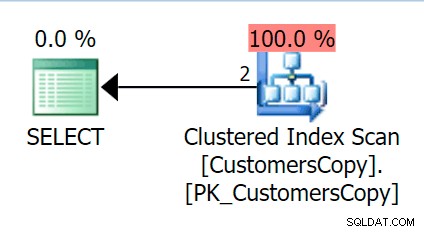
Sekarang, jika kita menjalankan kueri yang sama dengan yang kita jalankan terhadap tabel utama, kita mendapatkan sesuatu yang jauh lebih masuk akal untuk dilihat sebagai titik awal. Ini akan tetap menjadi pemindaian apa pun yang kami lakukan – jika kami menambahkan indeks dengan DeliveryAddressLine2 sebagai kolom kunci utama, kemungkinan besar kita akan mendapatkan pemindaian indeks, dengan pencarian kunci tergantung pada apakah indeks mencakup kolom dalam kueri. Apa adanya, kami mendapatkan pemindaian indeks berkerumun:
Selanjutnya, mari buat fungsi yang akan "meledak" nilai alamat ini menjadi fragmen. Kami mengharapkan 1846 Hudecova Crescent , misalnya, untuk memiliki kumpulan fragmen berikut:
- Bulan Sabit Hudecova 1846
- 846 Bulan Sabit Hudecova
- 46 Bulan Sabit Hudecova
- 6 Bulan Sabit Hudecova
- Bulan Sabit Hudecova
- Bulan Sabit Hudecova
- Udecova Bulan Sabit
- Decova Bulan Sabit
- Ecova Bulan Sabit
- Sabit cova
- Bulan Sabit ova
- va bulan sabit
- Bulan Sabit
- Bulan Sabit
- Bulan Sabit
- baru
- berkurang
- aroma
- sen
- ent
- t
- t
Cukup sepele untuk menulis sebuah fungsi yang akan menghasilkan output ini – kita hanya membutuhkan CTE rekursif yang dapat digunakan untuk melangkah melalui setiap karakter sepanjang input:
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list Sekarang, mari buat tabel yang akan menyimpan semua fragmen alamat, dan milik Pelanggan mana:
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
Kemudian kita bisa mengisinya seperti ini:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
Untuk dua nilai kami, ini menyisipkan 42 baris (satu alamat memiliki 20 karakter, dan yang lainnya memiliki 22). Sekarang kueri kita menjadi:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
AND f.Fragment LIKE N'Hudecova%'; Ini adalah paket yang jauh lebih bagus – dua indeks berkerumun *mencari* dan loop bersarang bergabung:
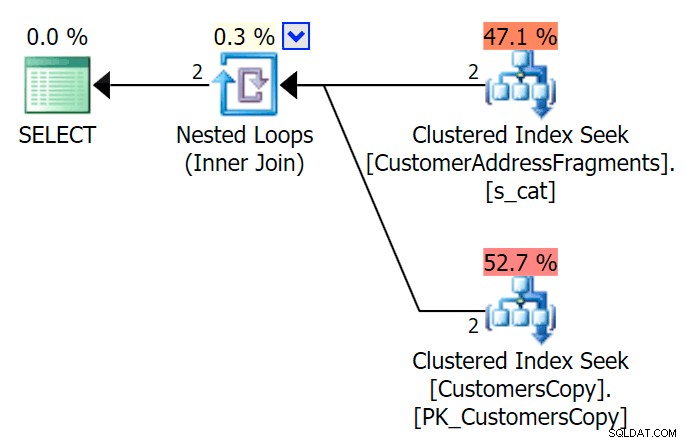
Kami juga dapat melakukan ini dengan cara lain, menggunakan EXISTS :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
); Inilah rencana itu, yang tampak di permukaan lebih mahal – ia memilih untuk memindai tabel CustomersCopy. Kita akan segera melihat mengapa ini adalah pendekatan kueri yang lebih baik:
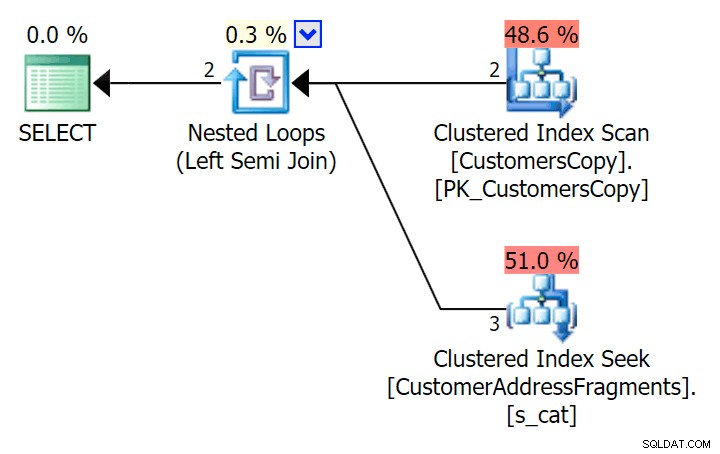
Sekarang, pada kumpulan data besar yang terdiri dari 42 baris ini, perbedaan yang terlihat dalam durasi dan I/O sangat kecil sehingga tidak relevan (dan kenyataannya, pada ukuran kecil ini, pemindaian terhadap tabel dasar terlihat lebih murah dalam hal I/ O daripada dua paket lain yang menggunakan tabel fragmen):

Bagaimana jika kita mengisi tabel ini dengan lebih banyak data? Salinan saya Sales.Customers memiliki 663 baris, jadi jika kita menyilangkannya, kita akan mendapatkan sekitar 440.000 baris. Jadi mari kita gabungkan 400K dan buat tabel yang jauh lebih besar:
TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
Sekarang untuk membandingkan kinerja dan rencana eksekusi dengan berbagai kemungkinan parameter pencarian, saya menguji tiga kueri di atas dengan predikat ini:
| Kueri | Predikat | ||||
|---|---|---|---|---|---|
| WHERE DeliveryLineAddress2 LIKE … | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| JOIN … WHERE Fragment LIKE … | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| DI MANA ADA (… MANA Fragmen SEPERTI ...) | |||||
Saat kami menghapus huruf dari pola pencarian, saya berharap untuk melihat lebih banyak output baris, dan mungkin strategi berbeda yang dipilih oleh pengoptimal. Mari kita lihat bagaimana hasilnya untuk setiap pola:
Hudecova%
Untuk pola ini, scan masih sama untuk kondisi LIKE; namun, dengan lebih banyak data, biayanya jauh lebih tinggi. Pencarian ke dalam tabel fragmen benar-benar terbayar pada jumlah baris ini (1.206), bahkan dengan perkiraan yang sangat rendah. Paket EXISTS menambahkan jenis yang berbeda, yang Anda harapkan akan ditambahkan ke biaya, meskipun dalam kasus ini akhirnya menghasilkan lebih sedikit pembacaan:

 Rencanakan GABUNG ke tabel fragmen
Rencanakan GABUNG ke tabel fragmen 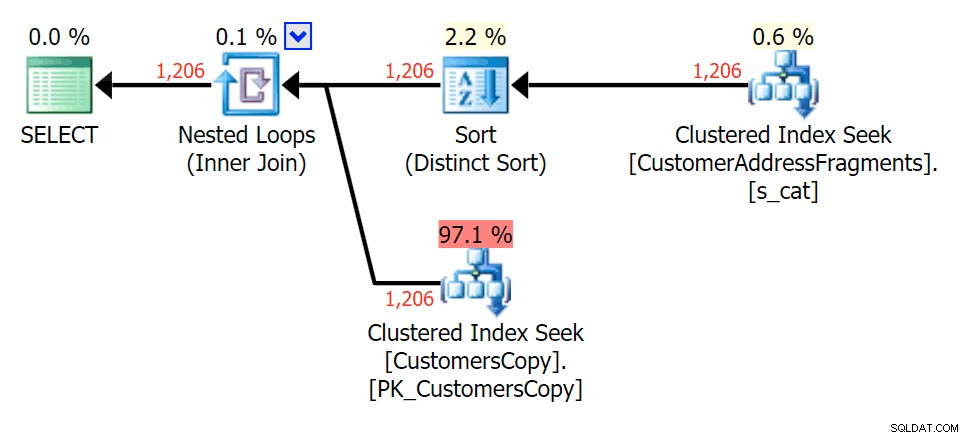 Rencanakan EXISTS terhadap tabel fragmen
Rencanakan EXISTS terhadap tabel fragmen cova%
Saat kami menghapus beberapa huruf dari predikat kami, kami melihat pembacaan sebenarnya sedikit lebih tinggi daripada pemindaian indeks berkerumun asli, dan sekarang kami over -memperkirakan baris. Meski begitu, durasi kami tetap jauh lebih rendah dengan kedua kueri fragmen; perbedaan kali ini lebih halus – keduanya memiliki jenis (hanya ADA yang berbeda):

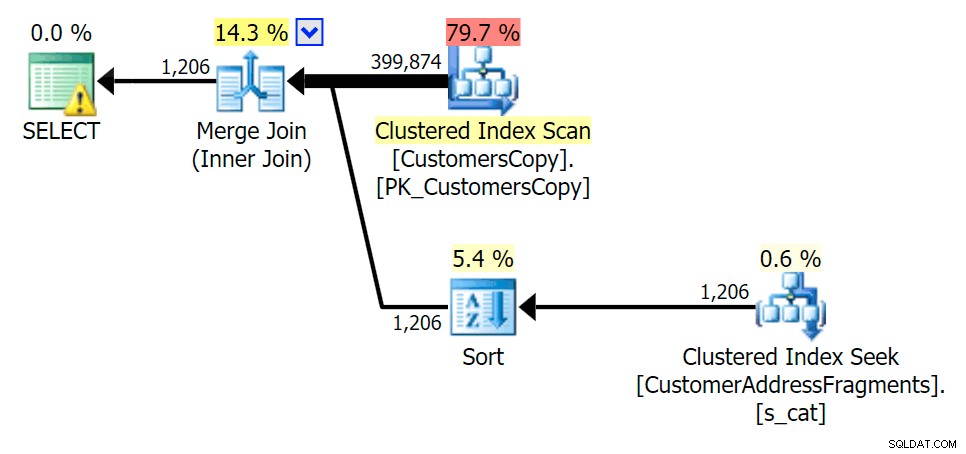 Rencanakan GABUNG ke tabel fragmen
Rencanakan GABUNG ke tabel fragmen 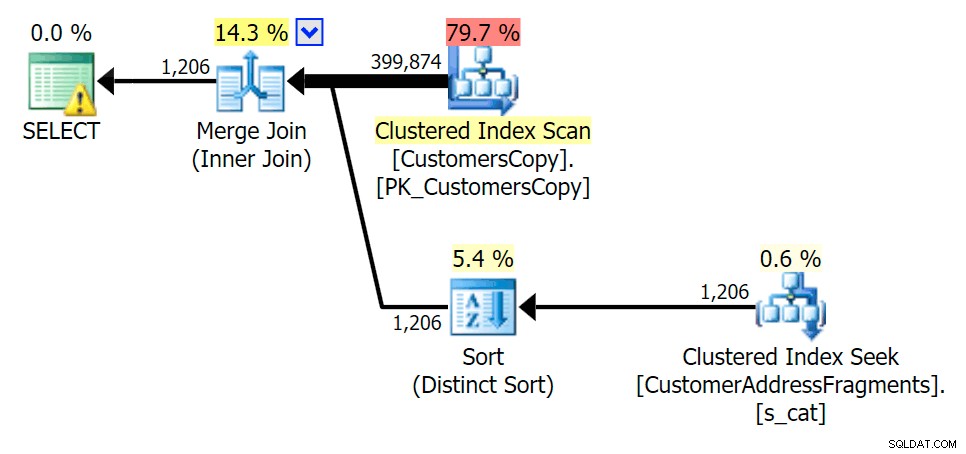 Rencanakan EXISTS terhadap tabel fragmen
Rencanakan EXISTS terhadap tabel fragmen ova%
Melucuti surat tambahan tidak banyak berubah; meskipun perlu dicatat berapa banyak baris yang diperkirakan dan yang sebenarnya melompat di sini – yang berarti bahwa ini mungkin merupakan pola substring yang umum. Kueri LIKE asli masih sedikit lebih lambat daripada kueri fragmen.

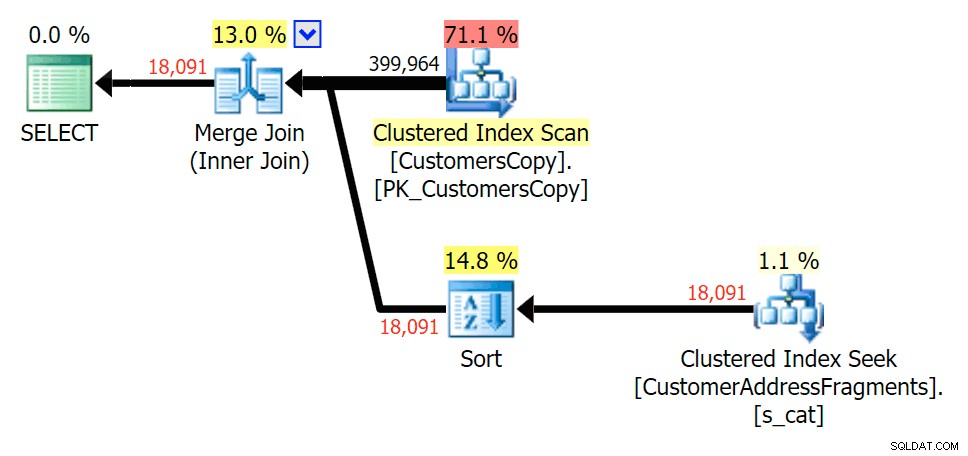 Rencanakan GABUNG ke tabel fragmen
Rencanakan GABUNG ke tabel fragmen 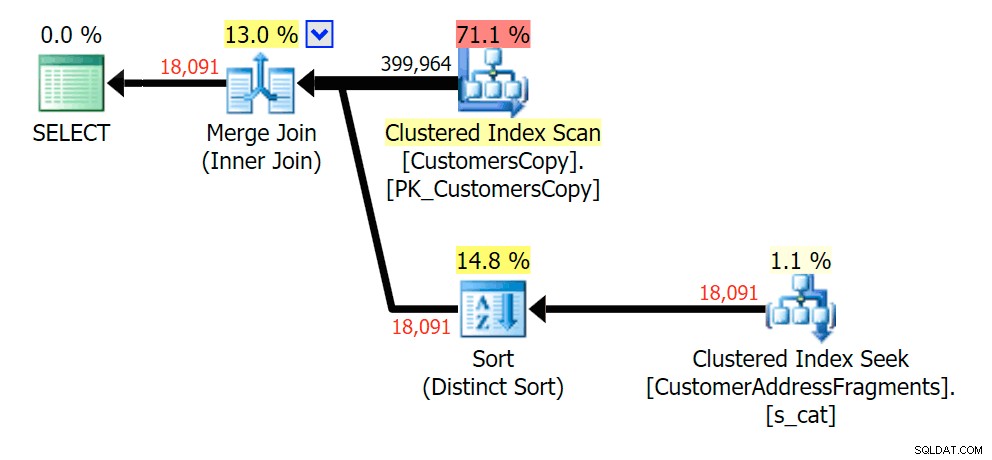 Rencanakan EXISTS terhadap tabel fragmen
Rencanakan EXISTS terhadap tabel fragmen va%
Turun ke dua huruf, ini memperkenalkan perbedaan pertama kami. Perhatikan bahwa JOIN menghasilkan lebih baris dari kueri asli atau EXISTS. Kenapa bisa begitu?

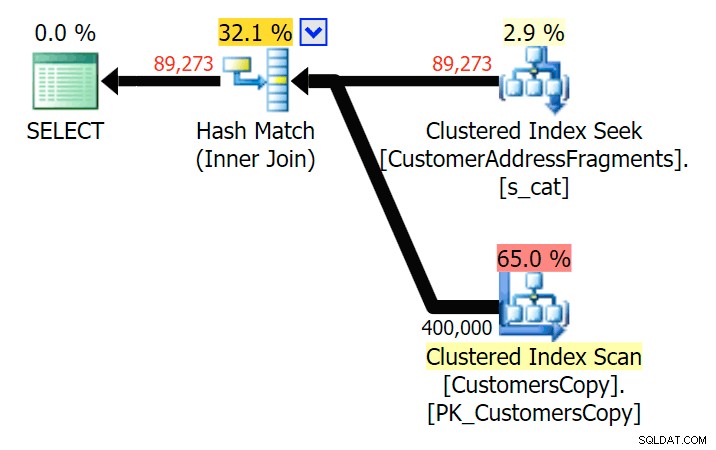 Rencanakan GABUNG ke tabel fragmen
Rencanakan GABUNG ke tabel fragmen 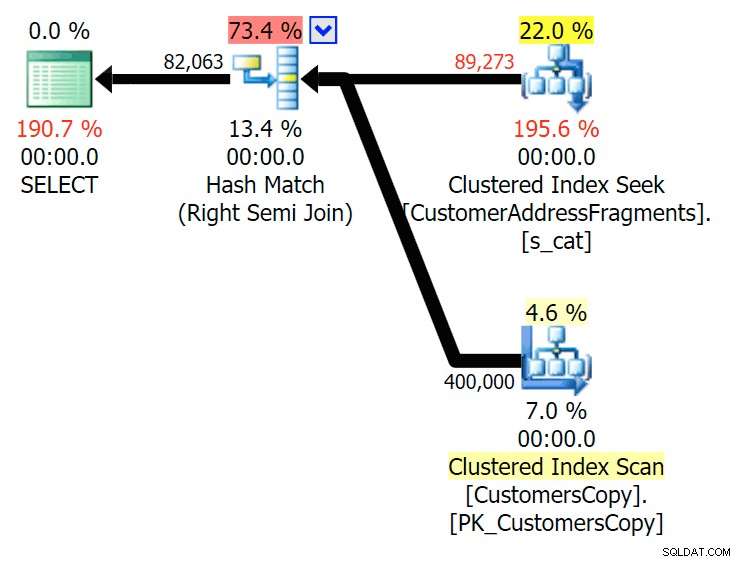 Rencanakan EXISTS terhadap tabel fragmen Kita tidak perlu melihat jauh. Ingat bahwa ada fragmen yang dimulai dari setiap karakter yang berurutan di alamat asli, yang artinya kira-kira seperti
Rencanakan EXISTS terhadap tabel fragmen Kita tidak perlu melihat jauh. Ingat bahwa ada fragmen yang dimulai dari setiap karakter yang berurutan di alamat asli, yang artinya kira-kira seperti 899 Valentova Road akan memiliki dua baris dalam tabel fragmen yang dimulai dengan va (disampingkan sensitivitas huruf besar-kecil). Jadi Anda akan cocok di kedua Fragment = N'Valentova Road' dan Fragment = N'va Road' . Saya akan menghemat pencarian Anda dan memberikan satu contoh dari banyak: SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
Ini dengan mudah menjelaskan mengapa JOIN menghasilkan lebih banyak baris; jika Anda ingin mencocokkan output dari kueri LIKE asli, Anda harus menggunakan EXISTS. Fakta bahwa hasil yang benar biasanya juga dapat diperoleh dengan cara yang kurang intensif sumber daya hanyalah bonus. (Saya akan gugup melihat orang memilih GABUNG jika itu adalah opsi yang berulang kali lebih efisien – Anda harus selalu memilih hasil yang benar daripada mengkhawatirkan kinerja.)
Ringkasan
Jelas bahwa dalam kasus khusus ini – dengan kolom alamat nvarchar(60) dan panjang maksimal 26 karakter – memecah setiap alamat menjadi beberapa bagian dapat memberikan sedikit kelegaan pada pencarian "wildcard terkemuka" yang mahal. Hasil yang lebih baik tampaknya terjadi ketika pola pencarian lebih besar dan, sebagai hasilnya, lebih unik. Saya juga telah menunjukkan mengapa EXISTS lebih baik dalam skenario di mana beberapa kecocokan dimungkinkan – dengan JOIN, Anda akan mendapatkan output yang berlebihan kecuali jika Anda menambahkan logika "n terbaik per grup".
Peringatan
Saya akan menjadi orang pertama yang mengakui bahwa solusi ini tidak sempurna, tidak lengkap, dan tidak sepenuhnya disempurnakan:
- Anda harus menjaga agar tabel fragmen tetap sinkron dengan tabel dasar menggunakan pemicu – yang paling sederhana adalah untuk menyisipkan dan memperbarui, menghapus semua baris untuk pelanggan tersebut dan menyisipkannya kembali, dan untuk penghapusan jelas hapus baris dari fragmen meja.
- Seperti yang disebutkan, solusi ini bekerja lebih baik untuk ukuran data spesifik ini, dan mungkin tidak bekerja dengan baik untuk panjang string lainnya. Ini akan menjamin pengujian lebih lanjut untuk memastikan itu sesuai untuk ukuran kolom Anda, panjang nilai rata-rata, dan panjang parameter pencarian biasa.
- Karena kita akan memiliki banyak salinan fragmen seperti "Bulan Sabit" dan "Jalan" (apalagi nama jalan dan nomor rumah yang sama atau mirip), selanjutnya dapat menormalkannya dengan menyimpan setiap fragmen unik dalam tabel fragmen, dan kemudian tabel lain yang bertindak sebagai tabel persimpangan banyak-ke-banyak. Itu akan jauh lebih rumit untuk disiapkan, dan saya tidak yakin akan ada banyak keuntungan.
- Saya belum sepenuhnya menyelidiki kompresi halaman, tampaknya – setidaknya secara teori – ini dapat memberikan beberapa manfaat. Saya juga merasa implementasi columnstore mungkin bermanfaat dalam beberapa kasus juga.
Bagaimanapun, semua yang dikatakan, saya hanya ingin membagikannya sebagai ide yang berkembang, dan meminta umpan balik tentang kepraktisannya untuk kasus penggunaan tertentu. Saya dapat menggali lebih spesifik untuk posting mendatang jika Anda dapat memberi tahu saya aspek apa dari solusi ini yang menarik minat Anda.