@rob_farley solusi stackoverflow terbaru Anda untuk memesan berdasarkan nilai terlebih dahulu, lalu bidang adalah jenius! Ingin mengucapkan terima kasih secara pribadi.
— Joel Sacco (@Jsac90) 11 Agustus 2016
Saya melihat tweet ini muncul…
Dan itu membuat saya melihat apa yang dimaksud, karena saya belum menulis apa pun 'baru-baru ini' di StackOverflow tentang memesan data. Ternyata itu jawaban yang saya tulis , yang meskipun bukan jawaban yang diterima, telah mengumpulkan lebih dari seratus suara.
Orang yang mengajukan pertanyaan memiliki masalah yang sangat sederhana – ingin agar baris tertentu muncul terlebih dahulu. Dan solusi saya sederhana:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Sepertinya itu jawaban yang populer, termasuk untuk Joel Sacco (menurut tweet di atas).
Idenya adalah untuk membentuk ekspresi, dan ketertiban dengan itu. ORDER BY tidak peduli apakah itu kolom yang sebenarnya atau tidak. Anda dapat melakukan hal yang sama menggunakan APPLY, jika Anda lebih suka menggunakan 'kolom' dalam klausa ORDER BY Anda.
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
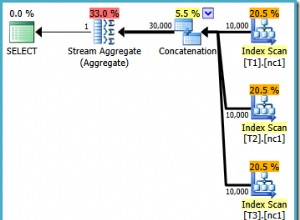
Jika saya menggunakan beberapa kueri terhadap WideWorldImporters, saya dapat menunjukkan kepada Anda mengapa kedua kueri ini benar-benar sama. Saya akan menanyakan tabel Sales.Orders, meminta agar Orders for Salesperson 7 muncul terlebih dahulu. Saya juga akan membuat indeks penutup yang sesuai:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
Rencana untuk dua kueri ini terlihat identik. Mereka tampil identik – pembacaan yang sama, ekspresi yang sama, mereka benar-benar kueri yang sama. Jika ada sedikit perbedaan dalam CPU atau Durasi sebenarnya, itu hanya kebetulan karena faktor lain.
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
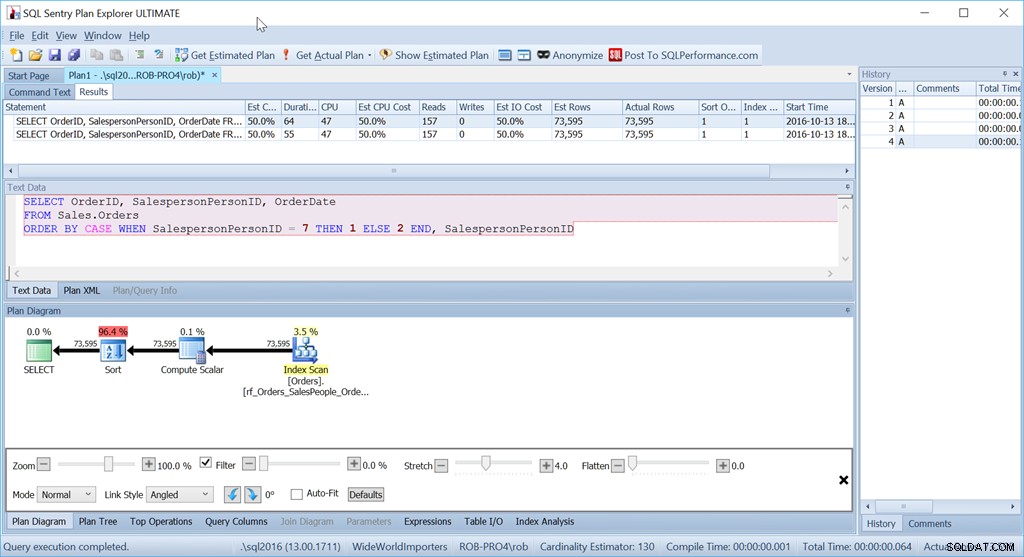
Namun ini bukan kueri yang sebenarnya akan saya gunakan dalam situasi ini. Tidak jika kinerja penting bagi saya. (Biasanya memang demikian, tetapi tidak selalu layak untuk menulis kueri jauh-jauh jika jumlah datanya kecil.)
Yang mengganggu saya adalah operator Sortir itu. Ini 96,4% dari biaya!
Pertimbangkan jika kita hanya ingin memesan berdasarkan SalespersonPersonID:
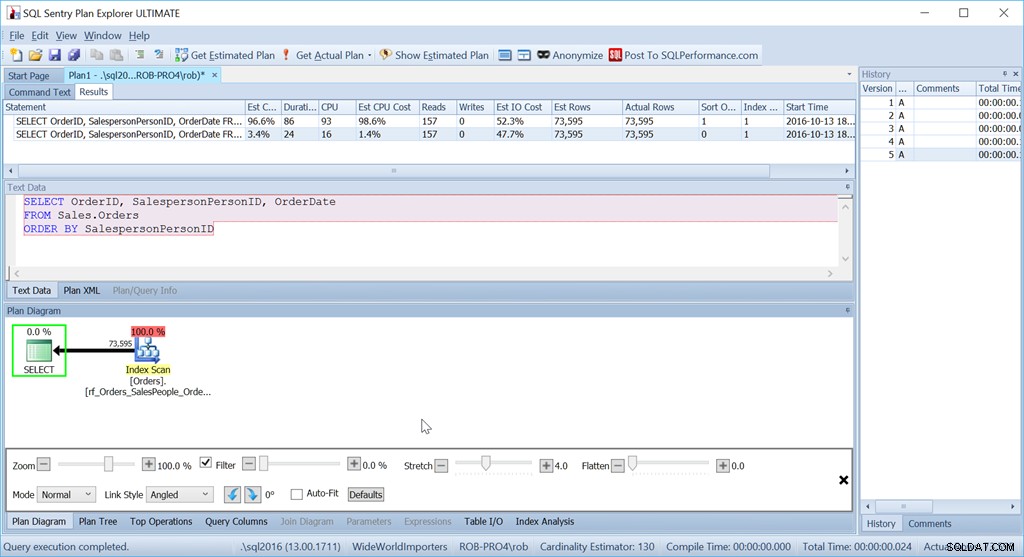
Kami melihat bahwa perkiraan biaya CPU kueri yang lebih sederhana ini adalah 1,4% dari batch, sedangkan versi yang diurutkan khusus adalah 98,6%. Itu TUJUH PULUH KALI lebih buruk. Bacaannya sama – itu bagus. Durasinya jauh lebih buruk, begitu juga CPU.
Saya tidak suka Sortir. Mereka bisa menjadi jahat.
Salah satu opsi yang saya miliki di sini adalah menambahkan kolom yang dihitung ke tabel saya dan mengindeksnya, tetapi itu akan berdampak pada apa pun yang mencari semua kolom di tabel, seperti ORM, Power BI, atau apa pun yang melakukan SELECT * . Jadi itu tidak terlalu bagus (walaupun jika kita bisa menambahkan kolom komputasi tersembunyi, itu akan menjadi pilihan yang sangat bagus di sini).
Pilihan lain, yang lebih bertele-tele (beberapa mungkin menyarankan itu cocok untuk saya – dan jika Anda berpikir bahwa:Oi! Jangan kasar!), dan menggunakan lebih banyak bacaan, adalah mempertimbangkan apa yang akan kita lakukan dalam kehidupan nyata jika kita perlu melakukan ini.
Jika saya memiliki setumpuk 73.595 pesanan, diurutkan berdasarkan pesanan Penjual, dan saya harus mengembalikannya dengan Penjual tertentu terlebih dahulu, saya tidak akan mengabaikan urutannya dan hanya menyortir semuanya, saya akan mulai dengan menyelam dan menemukan yang bukan untuk Penjual 7 – menyimpannya sesuai urutannya. Kemudian saya akan menemukan yang bukan Penjual 7 – meletakkannya di urutan berikutnya, dan sekali lagi menyimpannya dalam urutan yang sudah ada masuk.
Di T-SQL, itu dilakukan seperti ini:
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; Ini mendapatkan dua set data dan menggabungkannya. Namun, Pengoptimal Kueri dapat melihat bahwa ia perlu mempertahankan urutan SalespersonPersonID, setelah kedua kumpulan digabungkan, jadi ia melakukan jenis penggabungan khusus yang mempertahankan urutan itu. Ini adalah Gabung Gabung (Concatenation), dan rencananya terlihat seperti ini:
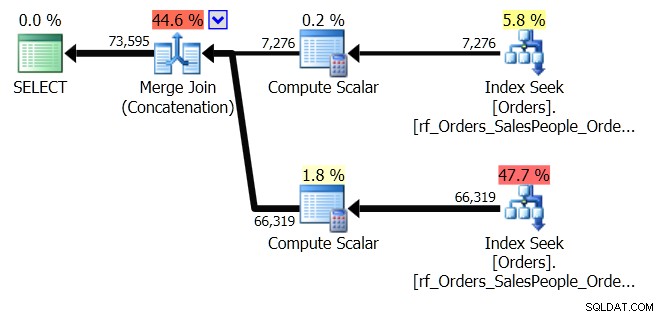
Anda dapat melihatnya jauh lebih rumit. Tapi mudah-mudahan Anda juga akan memperhatikan bahwa tidak ada operator Sortir. Merge Join (Concatenation) menarik data dari setiap cabang, dan menghasilkan kumpulan data yang dalam urutan yang benar. Dalam hal ini, ia akan menarik semua 7.276 baris untuk Penjual 7 terlebih dahulu, lalu menarik 66.319 baris lainnya, karena itu adalah urutan yang diperlukan. Dalam setiap set, data berada dalam urutan SalespersonPersonID, yang dipertahankan saat data mengalir.
Saya sebutkan sebelumnya bahwa ia menggunakan lebih banyak bacaan, dan memang demikian. Jika saya menunjukkan output SET STATISTICS IO, membandingkan dua kueri, saya melihat ini:
Meja 'Meja Kerja'. Hitungan pemindaian 0, pembacaan logis 0, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan depan pembacaan lob 0.Tabel 'Pesanan'. Hitungan pemindaian 1, pembacaan logis 157, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan ke depan lob pembacaan 0.
Tabel 'Pesanan '. Hitungan pemindaian 3, pembacaan logis 163, pembacaan fisik 0, pembacaan ke depan membaca 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan ke depan lob membaca 0.
Menggunakan versi "Urutan Kustom", itu hanya satu pemindaian indeks, menggunakan 157 bacaan. Menggunakan metode "Union All", ini adalah tiga pemindaian – satu untuk SalespersonPersonID =7, satu untuk SalespersonPersonID <7, dan satu untuk SalespersonPersonID> 7. Kita dapat melihat dua yang terakhir dengan melihat properti dari Pencarian Indeks kedua:
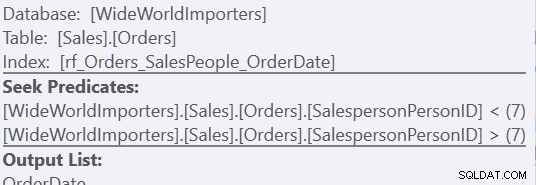
Namun, bagi saya, manfaatnya muncul karena kurangnya Meja Kerja.
Lihat perkiraan biaya CPU:

Ini tidak sekecil 1,4% kami ketika kami menghindari pengurutan sepenuhnya, tetapi ini masih merupakan peningkatan besar dibandingkan metode Pengurutan Kustom kami.
Tapi peringatan…
Misalkan saya telah membuat indeks itu secara berbeda, dan memiliki OrderDate sebagai kolom kunci daripada sebagai kolom yang disertakan.
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
Sekarang, metode "Union All" saya tidak berfungsi sama sekali.
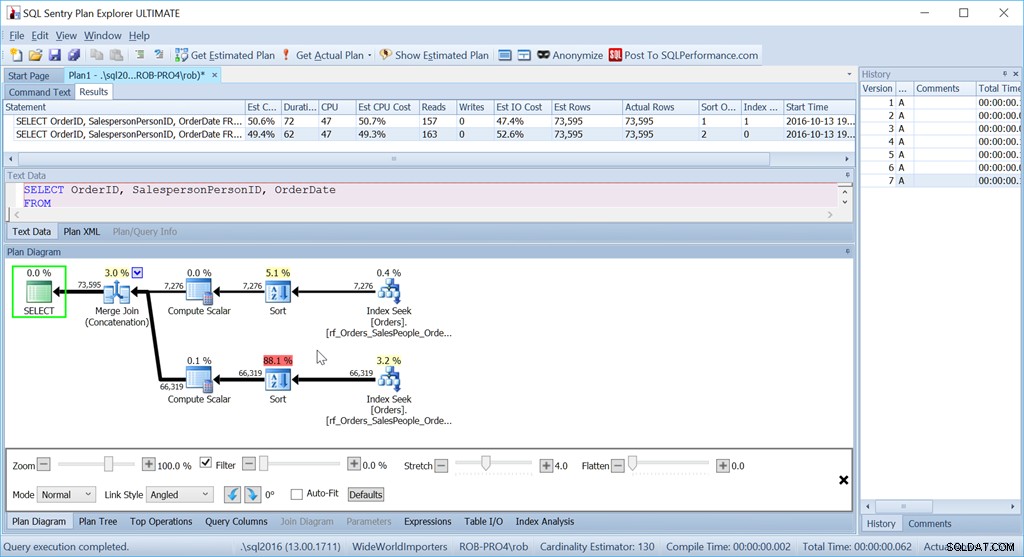
Meskipun menggunakan kueri yang sama persis seperti sebelumnya, paket Nice saya sekarang memiliki dua operator Sortir, dan kinerjanya hampir sama buruknya dengan versi Scan + Sort asli saya.
Alasan untuk ini adalah kekhasan operator Gabung Gabung (Penggabungan), dan petunjuknya ada di operator Sortir.

Ini dipesan oleh SalespersonPersonID diikuti oleh OrderID – yang merupakan kunci indeks berkerumun dari tabel. Itu memilih ini karena ini dikenal unik, dan ini adalah kumpulan kolom yang lebih kecil untuk diurutkan daripada SalespersonPersonID diikuti oleh OrderDate diikuti oleh OrderID, yang merupakan urutan kumpulan data yang dihasilkan oleh tiga pemindaian rentang indeks. Salah satu saat ketika Pengoptimal Kueri tidak melihat opsi yang lebih baik yang ada di sana.
Dengan indeks ini, kami akan membutuhkan dataset kami yang diurutkan berdasarkan OrderDate juga untuk menghasilkan paket pilihan kami.
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
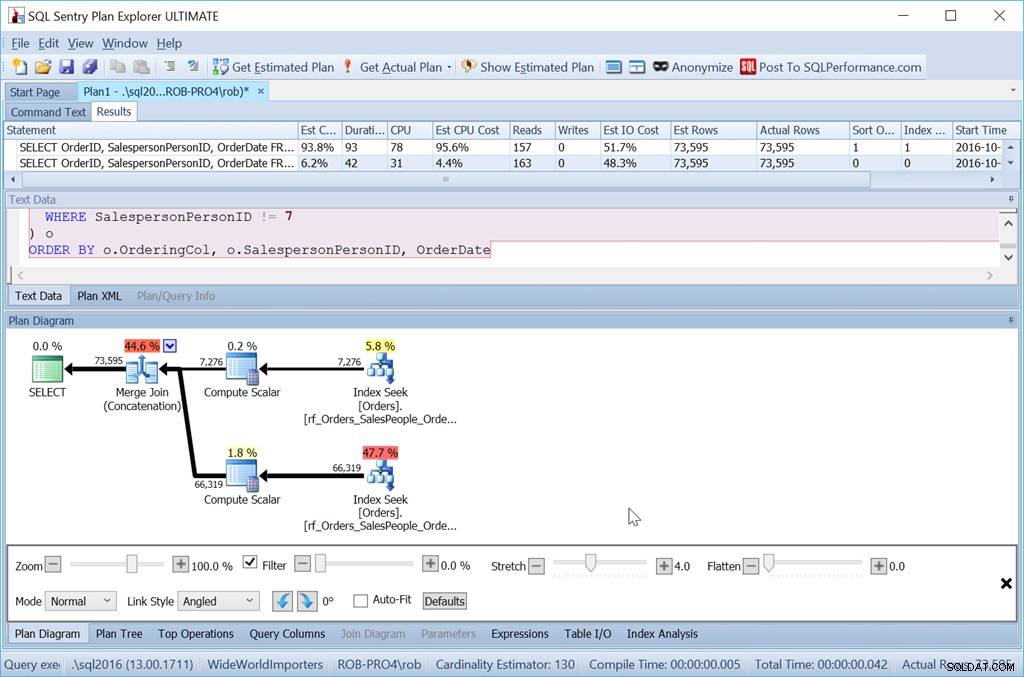
Jadi itu pasti lebih banyak usaha. Kueri lebih lama untuk saya tulis, lebih banyak dibaca, dan saya harus memiliki indeks tanpa kolom kunci tambahan. Tapi itu pasti lebih cepat. Dengan lebih banyak baris, dampaknya masih lebih besar, dan saya juga tidak perlu mengambil risiko Sortir tumpah ke tempdb.
Untuk set kecil, jawaban StackOverflow saya masih bagus. Tetapi ketika operator Sortir itu membebani kinerja saya, maka saya akan menggunakan metode Union All / Merge Join (Concatenation).