Benjamin Nevarez adalah konsultan independen yang berbasis di Los Angeles, California yang berspesialisasi dalam penyetelan dan pengoptimalan kueri SQL Server. Dia adalah penulis "SQL Server 2014 Query Tuning &Optimization" dan "Inside the SQL Server Query Optimizer" dan rekan penulis "SQL Server 2012 Internals". Dengan pengalaman lebih dari 20 tahun dalam database relasional, Benjamin juga telah menjadi pembicara di banyak konferensi SQL Server, termasuk PASS Summit, SQL Server Connections, dan SQLBits. Blog Benjamin dapat ditemukan di https://www.benjaminnevarez.com dan dia juga dapat dihubungi melalui email di admin di benjaminnevarez dot com dan di twitter di @BenjaminNevarez.
Sementara sebagian besar informasi, blog, dan dokumentasi tentang SQL Server 2014 berfokus pada Hekaton dan fitur baru lainnya, tidak banyak detail yang diberikan tentang penaksir kardinalitas baru. Saat ini BOL hanya secara tidak langsung membicarakannya di bagian Apa yang Baru (Mesin Database), mengatakan bahwa SQL Server 2014 "mencakup peningkatan substansial pada komponen yang membuat dan mengoptimalkan rencana kueri," dan ALTER DATABASE pernyataan menunjukkan cara mengaktifkan atau menonaktifkan perilakunya. Untungnya kita bisa mendapatkan beberapa informasi tambahan dengan membaca makalah penelitian Pengujian Model Estimasi Kardinalitas di SQL Server oleh Campbell Fraser et al. Meskipun fokus makalah ini adalah proses penjaminan kualitas model estimasi baru, makalah ini juga menawarkan pengenalan dasar untuk penduga kardinalitas baru, dan motivasi desain ulangnya.
Jadi, apa itu penduga kardinalitas? Penaksir kardinalitas adalah komponen pemroses kueri yang tugasnya memperkirakan jumlah baris yang dikembalikan oleh operasi relasional dalam kueri. Informasi ini, bersama dengan beberapa data lainnya, digunakan oleh pengoptimal kueri untuk memilih rencana eksekusi yang efisien. Estimasi kardinalitas secara inheren tidak tepat, karena merupakan model matematika yang bergantung pada informasi statistik. Hal ini juga didasarkan pada beberapa asumsi yang, meskipun tidak didokumentasikan, telah diketahui selama bertahun-tahun – beberapa di antaranya termasuk asumsi keseragaman, independensi, penahanan dan inklusi. Deskripsi singkat dari asumsi ini berikut.
- Keseragaman . Digunakan saat distribusi untuk atribut tidak diketahui, misalnya, di dalam baris rentang dalam langkah histogram atau saat histogram tidak tersedia.
- Kemerdekaan . Digunakan ketika atribut-atribut dalam suatu relasi independen, kecuali jika korelasi di antara mereka diketahui.
- Penahanan . Digunakan ketika dua atribut mungkin sama, mereka dianggap sama.
- Inklusi . Digunakan saat membandingkan atribut dengan konstanta, diasumsikan selalu ada kecocokan.
Sangat menarik bahwa saya baru-baru ini berbicara tentang beberapa keterbatasan asumsi ini pada pembicaraan terakhir saya di PASS Summit, yang disebut Mengalahkan Keterbatasan Pengoptimal Kueri. Namun saya terkejut membaca di koran bahwa penulis mengakui bahwa, menurut pengalaman mereka dalam praktik, asumsi ini “sering salah.”
Penaksir kardinalitas saat ini ditulis bersama dengan seluruh prosesor kueri untuk SQL Server 7.0, yang dirilis kembali pada bulan Desember 1998. Jelas komponen ini telah menghadapi banyak perubahan selama beberapa tahun dan beberapa rilis SQL Server, termasuk perbaikan, penyesuaian, dan ekstensi ke mengakomodasi estimasi kardinalitas untuk fitur T-SQL baru. Jadi Anda mungkin berpikir, mengapa mengganti komponen yang telah berhasil digunakan selama sekitar 15 tahun?
Mengapa Penaksir Kardinalitas Baru
Makalah ini menjelaskan beberapa alasan desain ulang termasuk:
- Untuk mengakomodasi estimator kardinalitas ke pola beban kerja baru.
- Perubahan yang dilakukan pada penduga kardinalitas selama bertahun-tahun membuat komponen sulit untuk “di-debug, diprediksi, dan dipahami”.
- Mencoba untuk meningkatkan model saat ini sulit menggunakan arsitektur saat ini, sehingga desain baru dibuat, berfokus pada pemisahan tugas (a) memutuskan bagaimana menghitung perkiraan tertentu, dan (b) benar-benar melakukan perhitungan .
Saya tidak yakin apakah detail lebih lanjut tentang penaksir kardinalitas baru akan diterbitkan oleh Microsoft. Lagi pula, tidak banyak detail yang pernah dipublikasikan tentang penduga kardinalitas lama dalam 15 tahun; misalnya, bagaimana beberapa estimasi kardinalitas tertentu dihitung. Di sisi lain, ada kejadian diperpanjang baru yang dapat kita gunakan untuk memecahkan masalah dengan estimasi kardinalitas, atau hanya untuk mengeksplorasi cara kerjanya. Peristiwa ini termasuk query_optimizer_estimate_cardinality , inaccurate_cardinality_estimate , query_optimizer_force_both_cardinality_estimation_behaviors dan query_rpc_set_cardinality .
Rencanakan Regresi
Perhatian utama yang muncul dalam pikiran dengan perubahan besar di dalam pengoptimal kueri adalah rencana regresi. Ketakutan akan regresi rencana telah dianggap sebagai hambatan terbesar untuk peningkatan pengoptimal kueri. Regresi adalah masalah yang muncul setelah perbaikan diterapkan ke pengoptimal kueri dan terkadang disebut sebagai klasik “dua kesalahan menjadi benar”. Ini bisa terjadi ketika dua estimasi buruk, misalnya yang satu melebih-lebihkan suatu nilai dan yang kedua meremehkannya, membatalkan satu sama lain, untungnya memberikan perkiraan yang baik. Mengoreksi hanya satu dari nilai-nilai ini sekarang dapat menyebabkan estimasi buruk yang dapat berdampak negatif pada pilihan pemilihan rencana, menyebabkan regresi.
Untuk membantu menghindari regresi yang terkait dengan penaksir kardinalitas baru, SQL Server menyediakan cara untuk mengaktifkan atau menonaktifkannya, karena bergantung pada tingkat kompatibilitas database. Ini dapat diubah menggunakan ALTER DATABASE pernyataan, seperti yang ditunjukkan sebelumnya. Menyetel database ke tingkat kompatibilitas 120 akan menggunakan penduga kardinalitas baru, sedangkan tingkat kompatibilitas kurang dari 120 akan menggunakan penaksir kardinalitas lama. Selain itu, setelah Anda menggunakan penaksir kardinalitas tertentu, ada dua tanda jejak yang dapat Anda gunakan untuk mengubah yang lain. Meskipun saat ini saya tidak melihat tanda pelacakan didokumentasikan di mana pun, tanda tersebut disebutkan sebagai bagian dari deskripsi query_optimizer_force_both_cardinality_estimation_behaviors acara diperpanjang. Trace flag 2312 dapat digunakan untuk mengaktifkan estimator kardinalitas baru, sedangkan trace flag 9481 dapat digunakan untuk menonaktifkannya. Anda bahkan dapat menggunakan tanda pelacakan untuk kueri tertentu menggunakan QUERYTRACEON petunjuk (meskipun belum didokumentasikan apakah ini akan didukung juga).
Contoh
Akhirnya, makalah ini juga menyebutkan beberapa skenario yang diuji seperti kunci utama yang kelebihan populasi, gabungan sederhana, atau masalah kunci menaik. Ini juga menunjukkan bagaimana penulis bereksperimen dengan beberapa skenario (atau variasi model) dan dalam beberapa kasus "melonggarkan" beberapa asumsi yang dibuat oleh penaksir kardinalitas, misalnya, dalam kasus asumsi independensi, beralih dari independensi penuh ke korelasi lengkap. dan sesuatu di antaranya sampai hasil yang baik ditemukan.
Meskipun tidak ada detail yang diberikan di atas kertas, saya memutuskan untuk mulai menguji beberapa skenario ini untuk mencoba memahami cara kerja penaksir kardinalitas baru. Untuk saat ini saya akan menunjukkan kepada Anda contoh menggunakan asumsi independensi dan kunci menaik. Saya juga menguji asumsi keseragaman tetapi sejauh ini tidak dapat menemukan perbedaan estimasi.
Mari kita mulai dengan contoh asumsi independensi. Pertama mari kita lihat perilaku saat ini. Untuk itu, pastikan Anda menggunakan estimator kardinalitas lama dengan menjalankan pernyataan berikut pada database AdventureWorks2012:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
Kemudian jalankan:
SELECT * FROM Person.Address WHERE City = 'Burbank';
Kami mendapatkan perkiraan 196 catatan seperti yang ditunjukkan berikut ini:

Dengan cara yang sama, pernyataan berikut akan mendapatkan perkiraan 194:
SELECT * FROM Person.Address WHERE PostalCode = '91502';
Jika kita menggunakan kedua predikat, kita memiliki kueri berikut, yang akan memiliki perkiraan jumlah baris 1.93862 (dibulatkan menjadi 2 baris jika menggunakan SQL Sentry Plan Explorer):
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Nilai ini dihitung dengan asumsi independensi total dari kedua predikat, yang menggunakan rumus (196 * 194) / 19614.0 (di mana 19614 adalah jumlah baris dalam tabel). Menggunakan korelasi total akan memberi kita perkiraan 194, karena semua catatan dengan kode pos 91502 milik Burbank. Penaksir kardinalitas baru memperkirakan nilai yang tidak mengasumsikan independensi total atau korelasi total. Ubah ke penduga kardinalitas baru menggunakan pernyataan berikut:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Menjalankan pernyataan yang sama lagi akan memberikan perkiraan 19,3931 baris, yang dapat Anda lihat adalah nilai antara asumsi independensi total dan korelasi total (dibulatkan hingga 19 baris di Plan Explorer). Rumus yang digunakan adalah selektivitas filter paling selektif * SQRT(selektivitas filter paling selektif berikutnya) atau (194/19614.0) * SQRT(196/19614.0) * 19614 yang menghasilkan 19.393:

Jika Anda telah mengaktifkan penaksir kardinalitas baru di tingkat basis data, beli ingin menonaktifkannya untuk kueri tertentu guna menghindari regresi rencana, Anda dapat menggunakan tanda jejak 9481 seperti yang dijelaskan sebelumnya:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502' OPTION (QUERYTRACEON 9481);
Catatan:Petunjuk kueri QUERYTRACEON digunakan untuk menerapkan tanda pelacakan di tingkat kueri dan saat ini hanya didukung dalam sejumlah skenario terbatas. Untuk informasi selengkapnya tentang petunjuk kueri QUERYTRACEON, Anda dapat melihat di https://support.microsoft.com/kb/2801413.
Sekarang mari kita lihat masalah ascending key, topik yang telah saya jelaskan secara lebih rinci dalam posting ini. Rekomendasi tradisional dari Microsoft untuk memperbaiki masalah ini adalah memperbarui statistik secara manual setelah memuat data, seperti yang dijelaskan di sini – yang menjelaskan masalahnya sebagai berikut:
Statistik pada kolom kunci menaik atau menurun, seperti IDENTITY atau kolom stempel waktu waktu nyata, mungkin memerlukan pembaruan statistik yang lebih sering daripada yang dilakukan pengoptimal kueri. Operasi sisipkan menambahkan nilai baru ke kolom menaik atau menurun. Jumlah baris yang ditambahkan mungkin terlalu kecil untuk memicu pembaruan statistik. Jika statistik tidak mutakhir dan kueri dipilih dari baris yang paling baru ditambahkan, statistik saat ini tidak akan memiliki taksiran kardinalitas untuk nilai-nilai baru ini. Hal ini dapat mengakibatkan perkiraan kardinalitas yang tidak akurat dan kinerja kueri yang lambat. Misalnya, kueri yang memilih dari tanggal pesanan penjualan terbaru akan memiliki perkiraan kardinalitas yang tidak akurat jika statistik tidak diperbarui untuk menyertakan perkiraan kardinalitas untuk tanggal pesanan penjualan terbaru.
Rekomendasi dalam artikel saya adalah menggunakan bendera jejak 2389 dan 2390, yang pertama kali diterbitkan oleh Ian Jose dalam artikelnya Ascending Keys dan Auto Quick Corrected Statistics. Anda dapat membaca artikel saya untuk penjelasan dan contoh tentang cara menggunakan tanda jejak ini untuk menghindari masalah ini. Bendera pelacakan ini masih berfungsi di SQL Server 2014 CTP2. Namun lebih baik lagi, mereka tidak lagi diperlukan jika Anda menggunakan penduga kardinalitas baru.
Menggunakan contoh yang sama di posting saya:
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
); Masukkan beberapa data:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < '2008-07-20 00:00:00.000'; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
Karena kami membuat indeks, kami hanya memiliki statistik baru. Menjalankan kueri berikut akan menghasilkan perkiraan 35 baris yang baik:
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
Jika kita memasukkan data baru:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
Anda dapat melihat taksiran dengan penduga kardinalitas lama seperti yang ditunjukkan berikut ini:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

Karena sejumlah kecil catatan yang dimasukkan tidak cukup untuk memicu pembaruan otomatis objek statistik, histogram saat ini tidak mengetahui catatan baru yang ditambahkan dan pengoptimal kueri menggunakan perkiraan 1 baris. Secara opsional, Anda dapat menggunakan tanda jejak 2389 dan 2390 untuk membantu mendapatkan perkiraan yang lebih baik. Tetapi jika Anda mencoba kueri yang sama dengan penaksir kardinalitas baru, Anda mendapatkan estimasi berikut:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
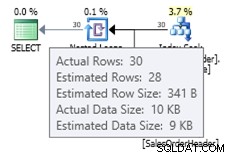
Dalam hal ini kita mendapatkan estimasi yang lebih baik daripada estimator kardinalitas lama (atau kita mendapatkan estimasi yang sama dengan menggunakan trace flags 2389 atau 2390). Nilai perkiraan 27,9631 (sekali lagi, dibulatkan menjadi 28 oleh Plan Explorer) dihitung menggunakan informasi kepadatan objek statistik dikalikan dengan jumlah baris tabel; yaitu 0,0008992806 * 31095. Nilai kerapatan dapat diperoleh dengan menggunakan:
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate'); Akhirnya, perlu diingat bahwa tidak ada yang disebutkan dalam artikel ini yang didokumentasikan, dan ini adalah perilaku yang saya amati sejauh ini di SQL Server 2014 CTP2. Semua ini dapat berubah di CTP atau versi RTM produk yang lebih baru.



