Saya sebelumnya telah menulis tentang manfaat menggunakan NOEXPAND petunjuk, bahkan dalam Edisi Perusahaan. Semua detailnya ada di artikel tertaut, tetapi untuk meringkasnya secara singkat:
- SQL Server hanya akan secara otomatis membuat statistik pada tampilan yang diindeks ketika
NOEXPANDpetunjuk tabel digunakan. Menghilangkan petunjuk ini dapat menyebabkan peringatan rencana eksekusi tentang statistik yang hilang yang tidak dapat diselesaikan dengan membuat statistik secara manual. - SQL Server hanya akan menggunakan statistik tampilan yang dibuat secara otomatis atau manual dalam perhitungan estimasi kardinalitas saat kueri mereferensikan tampilan secara langsung dan
NOEXPANDpetunjuk digunakan. Untuk semua kecuali definisi tampilan yang paling sepele, ini berarti kualitas perkiraan kardinalitas cenderung lebih rendah ketika petunjuk ini tidak digunakan, sering kali mengakibatkan rencana eksekusi yang kurang optimal. - Kurangnya, atau ketidakmampuan untuk menggunakan, statistik tampilan dapat menyebabkan pengoptimal menebak perkiraan kardinalitas, bahkan jika statistik tabel dasar tersedia. Hal ini dapat terjadi jika bagian dari rencana kueri diganti dengan referensi tampilan yang diindeks oleh fitur pencocokan tampilan otomatis, tetapi statistik tampilan tidak tersedia, seperti yang dijelaskan di atas.
Ada konsekuensi lain dari tidak menggunakan NOEXPAND petunjuk, yang saya sebutkan secara sepintas beberapa tahun yang lalu di artikel saya, Batasan Pengoptimal dengan Indeks yang Difilter:
NOEXPANDpetunjuk diperlukan bahkan di Edisi Perusahaan untuk memastikan jaminan keunikan yang diberikan oleh indeks tampilan digunakan oleh pengoptimal.
Artikel ini membahas pernyataan itu, dan implikasinya secara lebih rinci.
Penyiapan Demo
Skrip berikut membuat tabel sederhana dan tampilan terindeks:
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); Itu membuat tabel tumpukan kolom tunggal, dan tampilan tak terbatas dari tabel yang sama dengan indeks berkerumun unik. Ini tidak dimaksudkan sebagai kasus penggunaan yang realistis untuk tampilan yang diindeks; tetapi ini akan membantu mengilustrasikan poin-poin penting dengan gangguan seminimal mungkin. Poin penting adalah bahwa tabel dasar di sini tidak memiliki indeks sama sekali (bahkan indeks berkerumun) tetapi tampilan memilikinya, dan indeks itu unik.
Contoh Kueri
Pertimbangkan kueri sederhana berikut terhadap tabel dasar:
SELECT DISTINCT
T.col1
FROM dbo.T AS T; Rencana eksekusi yang akan Anda lihat untuk kueri ini bergantung pada edisi SQL Server yang digunakan. Jika bukan Edisi Perusahaan (atau yang setara), Anda akan melihat paket seperti ini:

Pengoptimal kueri SQL Server telah memilih untuk memindai tabel dasar dan menerapkan perbedaan yang ditentukan menggunakan operator Distinct Sort. Bentuk rencana ini sepenuhnya diharapkan, karena pencocokan tampilan terindeks otomatis tidak tersedia di luar Edisi Perusahaan. Saya akan berhenti mengatakan "Edisi Perusahaan atau yang setara" mulai saat ini, tetapi harap terus menyimpulkan bahwa maksud saya edisi apa pun yang mendukung pencocokan tampilan otomatis saat saya mengatakan, "Edisi Perusahaan" mulai sekarang.
Petunjuk PERLUAS TAMPILAN
Ini sedikit tambahan, tetapi untuk mendapatkan paket yang sama pada Edisi Perusahaan, kita perlu menggunakan EXPAND VIEWS petunjuk kueri:
SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS);
Mungkin agak aneh menggunakan petunjuk ini ketika tidak ada referensi tampilan dalam kueri, tetapi begitulah cara kerjanya. EXPAND VIEWS petunjuk secara efektif menentukan bahwa pencocokan tampilan yang diindeks harus dinonaktifkan saat mengkompilasi dan mengoptimalkan kueri. Agar jelas:Tanpa petunjuk ini, Edisi Perusahaan mungkin akan mencocokkan (sebagian) kueri dengan satu atau beberapa tampilan yang diindeks.
Dengan Pencocokan Tampilan Otomatis Diaktifkan
Tanpa EXPAND VIEWS petunjuk, kompilasi kueri yang sama pada Edisi Pengembang (misalnya) menghasilkan rencana yang berbeda:
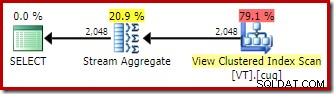
Penerapan pencocokan tampilan yang diindeks berarti rencana eksekusi menampilkan pemindaian indeks berkerumun tampilan alih-alih pemindaian tabel dasar.
Rencana yang sama dihasilkan dalam kasus ini jika kueri merujuk tampilan secara langsung (bukan tabel dasar):
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; Di semua edisi, referensi tampilan diperluas sebelum pengoptimalan kueri dimulai. Dalam edisi yang setara dengan Perusahaan, formulir yang diperluas dapat dicocokkan kembali dengan tampilan nanti. Ini adalah konsep kunci yang harus dipahami ketika memikirkan tentang bagaimana kompiler kueri dan pengoptimal menggunakan tampilan terindeks di SQL Server.
Agregat Aliran
Perbedaan paling menarik antara dua paket yang telah kita lihat sejauh ini adalah Agregat Aliran dalam paket tampilan yang cocok. Jika Anda melihat perkiraan biaya operator Table Scan dan View Scan, Anda akan melihat bahwa keduanya sama persis. Pengoptimal tidak memutuskan untuk menggunakan tampilan yang diindeks karena membuat pengaksesan data menjadi lebih murah. Sebaliknya, memindai indeks tampilan memungkinkan DISTINCT persyaratan untuk diimplementasikan sebagai Stream Aggregate, bukan Hash Aggregate atau Distinct Sort (seperti dalam rencana pertama).
Agregat Aliran memerlukan input yang diurutkan berdasarkan kolom pengelompokan. Dalam hal ini, perbedaan setara dengan pengelompokan berdasarkan kolom tunggal, dan indeks berkerumun unik tampilan memberikan jaminan pemesanan yang diperlukan. Model biaya pengoptimal mengidentifikasi Stream Aggregate sebagai opsi yang lebih murah daripada Distinct Sort atau Hash Aggregate untuk kueri ini. Ini adalah dasar untuk pengoptimal memilih untuk mengakses tampilan yang diindeks ketika pencocokan tampilan otomatis tersedia.
Dengan semua yang dikatakan dan dipahami, Agregat Aliran masih tidak terduga:Mengingat jaminan keunikan yang diberikan oleh indeks tampilan, tidak perlu melakukan operasi pengelompokan ini sama sekali. unik indeks berkerumun sudah memastikan kolom tidak berisi duplikat.
Singkatnya, inilah masalahnya. Saat pencocokan tampilan otomatis digunakan, pengoptimal mengenali jaminan pemesanan yang diberikan oleh indeks tampilan, tetapi bukan jaminan keunikan.
Menggunakan petunjuk NOEXPAND
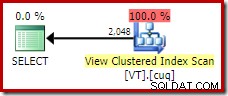
Untuk mendapatkan rencana eksekusi yang ideal untuk kueri ini, kita perlu merujuk tampilan secara langsung dan menggunakan NOEXPAND petunjuk tabel:
SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); Ini memberi kita rencana yang diharapkan oleh orang database yang berpengalaman; salah satu yang dengan benar mengenali bahwa operasi yang berbeda itu berlebihan dan dapat dihapus:
Contoh Kedua
Gagal memanfaatkan jaminan keunikan yang disediakan oleh indeks tampilan dapat memiliki efek lain pada rencana eksekusi akhir. Pertimbangkan sekarang penggabungan diri dari tampilan yang diindeks (sekali lagi, hanya untuk mengilustrasikan sebuah konsep – ini tidak dimaksudkan untuk menjadi kueri yang realistis):
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1; Menggunakan Edisi Pengembang, rencana eksekusi yang dipilih tidak mengakses tampilan yang diindeks sama sekali, dan menampilkan hash join (terkadang merupakan indikasi bahwa indeks yang berguna tidak ada):
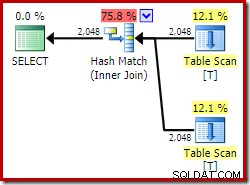
Sekarang mari kita coba kueri yang sama persis, tetapi dengan NOEXPAND petunjuk pada setiap referensi tampilan:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
ON V2.col1 = V1.col1; Rencana eksekusi sekarang menampilkan dua akses tampilan yang diindeks dan gabungan gabungan:
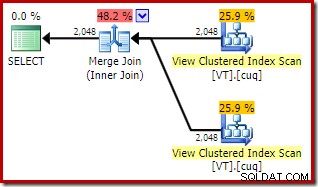
Paket baru ini memiliki perkiraan biaya yang jauh lebih rendah daripada paket hash join, jadi mengapa pengoptimal tidak memilih opsi ini sebelumnya? Kita dapat mengetahui alasannya dengan menambahkan petunjuk penggabungan gabungan ke kueri asli:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN);
Ini memberikan tampak serupa paket yang memilih untuk mengakses tampilan meskipun NOEXPAND tidak ditentukan:
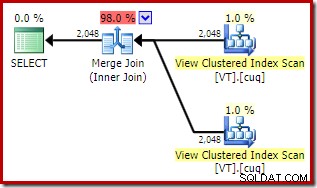
Perkiraan biaya keseluruhan dari rencana ini lebih tinggi dari kedua contoh sebelumnya. Gabung Gabung dalam rencana ini juga menyumbang proporsi yang lebih tinggi dari total perkiraan biaya daripada sebelumnya (98% versus 48,2%).
Alasan untuk ini dapat dilihat dengan melihat properti dari gabungan gabungan. Dalam NOEXPAND rencana, itu adalah penggabungan satu-ke-banyak. Dalam rencana langsung di atas, ini adalah penggabungan banyak-ke-banyak. Model biaya pengoptimal menetapkan biaya yang lebih tinggi untuk penggabungan banyak ke banyak karena tabel kerja tempdb diperlukan untuk menangani duplikat apa pun.
Kesimpulan
Jaminan yang diberikan oleh indeks unik dapat menjadi alat pengoptimalan yang kuat, jadi sayang sekali bahwa pencocokan indeks otomatis saat ini tidak dapat memanfaatkannya. Manfaat potensial melampaui menghilangkan agregasi yang tidak perlu atau memungkinkan penggabungan satu-ke-banyak seperti yang terlihat pada contoh sederhana sebelumnya. Secara umum, sulit untuk mengetahui bahwa rencana eksekusi kurang optimal karena pengoptimal gagal memanfaatkan jaminan keunikan.
Batasan pengoptimal ini tidak hanya berlaku untuk indeks berkerumun unik yang harus dimiliki tampilan agar terwujud. Dalam skenario yang lebih kompleks, indeks nonclustered tambahan mungkin juga ada pada tampilan; mungkin untuk mencerminkan hubungan tabel silang yang sulit untuk ditegakkan atau dinyatakan sebaliknya. Jika indeks nonclustered ini didefinisikan sebagai unik, pengoptimal akan mengabaikan jaminan ini juga, jika pencocokan indeks otomatis digunakan.
Menambahkan ini ke batasan seputar pembuatan dan penggunaan informasi statistik, tampaknya mengandalkan pencocokan tampilan otomatis dapat menghasilkan rencana eksekusi yang lebih rendah. Opsi teraman mungkin adalah dengan mereferensikan tampilan yang diindeks secara eksplisit, dan menggunakan NOEXPAND petunjuk setiap saat – setidaknya sampai masalah ini diatasi dalam produk.
Faktor yang Mengurangi
Saya harus menekankan bahwa masalah yang dijelaskan dalam artikel ini hanya berlaku untuk jaminan keunikan yang diberikan oleh indeks tampilan unik. Jika pengoptimal bisa mendapatkan informasi keunikan yang diperlukan cara lain , kemungkinan besar masalah pengoptimalan akan dihindari.
Misalnya, mungkin ada indeks unik yang sesuai pada tabel dasar yang dirujuk oleh tampilan. Atau, dalam kasus tampilan yang berisi agregasi, pengoptimal sudah dapat menyimpulkan jaminan keunikan yang berguna dari GROUP BY tampilan ayat. Praktik umum menambahkan indeks pengelompokan tampilan ke kunci pengelompokan tidak menambahkan informasi keunikan tambahan dalam kasus tersebut.
Namun demikian, ada kalanya "pengawasan keunikan" ini dapat berarti Anda akan mendapatkan rencana eksekusi berkualitas lebih baik dengan menggunakan referensi tampilan eksplisit dan NOEXPAND petunjuk, bahkan dalam Edisi Perusahaan.