Galera Cluster, dengan replikasi (hampir) sinkronnya, biasanya digunakan di berbagai jenis lingkungan. Menskalakannya dengan menambahkan node baru tidaklah sulit (atau hanya dengan beberapa klik saat Anda menggunakan ClusterControl).
Masalah utama dengan replikasi sinkron adalah, baik, bagian sinkron yang sering mengakibatkan bahwa seluruh cluster hanya secepat node paling lambat. Setiap penulisan yang dieksekusi pada sebuah cluster harus direplikasi ke semua node dan disertifikasi. Jika, karena alasan apa pun, proses ini melambat, ini dapat berdampak serius pada kemampuan cluster untuk mengakomodasi penulisan. Kontrol aliran kemudian akan masuk, ini untuk memastikan bahwa node paling lambat masih dapat mengikuti beban. Ini membuatnya cukup rumit untuk beberapa skenario umum yang terjadi di lingkungan dunia nyata.
Pertama, mari kita bahas pemulihan bencana yang didistribusikan secara geografis. Tentu, Anda dapat menjalankan kluster di seluruh Jaringan Area Luas, tetapi peningkatan latensi akan berdampak signifikan pada kinerja kluster. Ini sangat membatasi kemampuan menggunakan penyiapan seperti itu, terutama pada jarak yang lebih jauh saat latensi lebih tinggi.
Kasus penggunaan lain yang cukup umum - lingkungan pengujian untuk peningkatan versi utama. Bukan ide yang baik untuk mencampur versi yang berbeda dari node MariaDB Galera Cluster di cluster yang sama, bahkan jika memungkinkan. Di sisi lain, migrasi ke versi yang lebih baru memerlukan pengujian mendetail. Idealnya, baik membaca dan menulis akan diuji. Salah satu cara untuk mencapainya adalah dengan membuat kluster Galera terpisah dan menjalankan pengujian, tetapi Anda ingin menjalankan pengujian di lingkungan yang sedekat mungkin dengan produksi. Setelah disediakan, sebuah cluster dapat digunakan untuk pengujian dengan kueri dunia nyata tetapi akan sulit untuk menghasilkan beban kerja yang akan mendekati beban produksi. Anda tidak dapat memindahkan beberapa lalu lintas produksi ke sistem pengujian tersebut, karena datanya tidak terkini.
Terakhir, migrasi itu sendiri. Sekali lagi, apa yang kami katakan sebelumnya, bahkan jika mungkin untuk menggabungkan versi lama dan baru dari node Galera di cluster yang sama, itu bukan cara teraman untuk melakukannya.
Untungnya, solusi paling sederhana untuk ketiga masalah tersebut adalah menghubungkan kluster Galera yang terpisah dengan replikasi asinkron. Apa yang membuatnya menjadi solusi yang bagus? Nah, itu asynchronous yang membuatnya tidak mempengaruhi replikasi Galera. Tidak ada flow control, sehingga kinerja cluster “master” tidak akan terpengaruh oleh kinerja cluster “slave”. Seperti halnya setiap replikasi asinkron, lag mungkin muncul, tetapi selama itu tetap dalam batas yang dapat diterima, itu dapat bekerja dengan baik. Anda juga harus ingat bahwa saat ini replikasi asinkron dapat diparalelkan (beberapa utas dapat bekerja sama untuk meningkatkan bandwidth) dan mengurangi jeda replikasi lebih jauh.
Dalam posting blog ini kita akan membahas apa saja langkah-langkah untuk menerapkan replikasi asinkron antara cluster MariaDB Galera.
Bagaimana Mengonfigurasi Replikasi Asinkron Antara Cluster MariaDB Galera?
Pertama kita harus men-deploy sebuah cluster. Untuk tujuan kami, kami menyiapkan cluster tiga simpul. Kami akan menjaga pengaturan seminimal mungkin, sehingga kami tidak akan membahas kompleksitas aplikasi dan lapisan proxy. Lapisan proxy mungkin sangat berguna untuk menangani tugas-tugas yang ingin Anda gunakan replikasi asinkron - mengalihkan sebagian lalu lintas baca-saja ke kluster uji, membantu dalam situasi pemulihan bencana saat kluster "utama" tidak tersedia dengan mengarahkan ulang lalu lintas ke DR cluster. Ada banyak proxy yang dapat Anda coba, tergantung pada preferensi Anda - HAProxy, MaxScale, atau ProxySQL - semuanya dapat digunakan dalam penyiapan tersebut dan, bergantung pada kasusnya, beberapa di antaranya mungkin dapat membantu Anda mengelola lalu lintas.
Mengonfigurasi Cluster Sumber
Cluster kami terdiri dari tiga node MariaDB 10.3, kami juga menggunakan ProxySQL untuk melakukan pemisahan baca-tulis dan mendistribusikan lalu lintas ke semua node dalam cluster. Ini bukan penerapan tingkat produksi, untuk itu kami harus menerapkan lebih banyak node ProxySQL dan Keepalive di atasnya. Itu masih cukup untuk tujuan kita. Untuk menyiapkan replikasi asinkron, kita harus mengaktifkan log biner di kluster kita. Setidaknya satu node tetapi lebih baik untuk tetap mengaktifkannya di semua node jika satu-satunya node dengan binlog diaktifkan turun - maka Anda ingin memiliki node lain di cluster yang aktif dan berjalan yang dapat Anda gunakan.
Saat mengaktifkan log biner, pastikan Anda mengonfigurasi rotasi log biner sehingga log lama akan dihapus di beberapa titik. Anda akan menggunakan format log biner ROW. Anda juga harus memastikan bahwa Anda telah mengonfigurasi dan menggunakan GTID - ini akan sangat berguna ketika Anda harus mereslave cluster "slave" Anda atau jika Anda perlu mengaktifkan replikasi multi-utas. Karena ini adalah cluster Galera, Anda ingin 'wsrep_gtid_domain_id' dikonfigurasi dan 'wsrep_gtid_mode' diaktifkan. Pengaturan tersebut akan memastikan bahwa GTID akan dihasilkan untuk lalu lintas yang berasal dari kluster Galera. Informasi lebih lanjut dapat ditemukan di dokumentasi. Setelah semuanya selesai, Anda dapat melanjutkan dengan menyiapkan cluster kedua.
Menyiapkan Kelompok Target
Mengingat saat ini belum ada cluster target, kita harus mulai dengan men-deploy-nya. Kami tidak akan membahas langkah-langkah tersebut secara detail, Anda dapat menemukan petunjuknya di dokumentasi. Secara umum prosesnya terdiri dari beberapa langkah:
- Mengonfigurasi repositori MariaDB
- Instal paket MariaDB 10.3
- Konfigurasikan node untuk membentuk cluster
Pada awalnya kita akan mulai dengan hanya satu node. Anda dapat mengatur semuanya untuk membentuk sebuah cluster tetapi kemudian Anda harus menghentikannya dan menggunakan hanya satu untuk langkah berikutnya. Satu node itu akan menjadi budak dari cluster asli. Kami akan menggunakan mariabackup untuk menyediakannya. Kemudian kita akan mengkonfigurasi replikasi.
Pertama, kita harus membuat direktori tempat kita akan menyimpan cadangan:
mkdir /mnt/mariabackupKemudian kami menjalankan cadangan dan membuatnya di direktori yang disiapkan pada langkah di atas. Pastikan Anda menggunakan pengguna dan kata sandi yang benar untuk terhubung ke database:
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/Selanjutnya, kita harus menyalin file cadangan ke node pertama di cluster kedua. Kami menggunakan scp untuk itu, Anda dapat menggunakan apa pun yang Anda suka - rsync, netcat, apa pun yang akan berfungsi.
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/Setelah cadangan disalin, kita harus menyiapkannya dengan menerapkan file log:
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!Jika terjadi kesalahan, Anda mungkin harus menjalankan kembali pencadangan. Jika semuanya berjalan baik, kami dapat menghapus data lama dan menggantinya dengan informasi cadangan
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!Kami juga ingin mengatur pemilik file yang benar:
chown -R mysql.mysql /var/lib/mysql/Kami akan mengandalkan GTID untuk menjaga agar replikasi tetap konsisten sehingga kami perlu melihat GTID apa yang terakhir diterapkan dalam cadangan ini. Informasi tersebut dapat ditemukan di file xtrabackup_info yang merupakan bagian dari backup:
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'Kami juga harus memastikan bahwa node budak memiliki log biner yang diaktifkan bersama dengan 'log_slave_updates'. Idealnya, ini akan diaktifkan pada semua node di cluster kedua - untuk berjaga-jaga jika node “slave” gagal dan Anda harus menyiapkan replikasi menggunakan node lain di cluster slave.
Hal terakhir yang perlu kita lakukan sebelum kita dapat mengatur replikasi adalah membuat pengguna yang akan kita gunakan untuk menjalankan replikasi:
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)Itu saja yang kami butuhkan. Sekarang, kita dapat memulai node pertama di cluster kedua, calon budak kita:
galera_new_clusterSetelah dimulai, kita dapat masuk ke MySQL CLI dan mengkonfigurasinya menjadi budak, menggunakan posisi GITD yang kita temukan beberapa langkah sebelumnya:
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)Setelah selesai, kita akhirnya dapat mengatur replikasi dan memulainya:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Pada titik ini kita memiliki Galera Cluster yang terdiri dari satu node. Node tersebut juga merupakan budak dari cluster asli (khususnya, masternya adalah node 10.0.0.101). Untuk bergabung dengan node lain kita akan menggunakan SST tetapi untuk membuatnya bekerja terlebih dahulu kita harus memastikan bahwa konfigurasi SST sudah benar - perlu diingat bahwa kita baru saja mengganti semua pengguna di cluster kedua kita dengan isi dari cluster sumber. Yang harus Anda lakukan sekarang adalah memastikan bahwa konfigurasi 'wsrep_sst_auth' dari cluster kedua cocok dengan salah satu cluster pertama. Setelah selesai, Anda dapat memulai node yang tersisa satu per satu dan node tersebut harus bergabung dengan node yang ada (10.0.0.104), mendapatkan data melalui SST dan membentuk cluster Galera. Akhirnya, Anda harus berakhir dengan dua cluster, masing-masing tiga node, dengan tautan replikasi asinkron di antara mereka (dari 10.0.0.101 hingga 10.0.0.104 dalam contoh kami). Anda dapat mengonfirmasi bahwa replikasi berfungsi dengan memeriksa nilai:
MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)Bagaimana Mengonfigurasi Replikasi Asinkron Antara Cluster MariaDB Galera Menggunakan ClusterControl?
Pada saat blog ini dibuat, ClusterControl tidak memiliki fungsi untuk mengonfigurasi replikasi asinkron di beberapa cluster, kami sedang mengerjakannya saat saya mengetik ini. Meskipun demikian ClusterControl dapat sangat membantu dalam proses ini - kami akan menunjukkan kepada Anda bagaimana Anda dapat mempercepat langkah-langkah manual yang melelahkan menggunakan otomatisasi yang disediakan oleh ClusterControl.
Dari apa yang kami tunjukkan sebelumnya, kami dapat menyimpulkan bahwa itu adalah langkah-langkah umum yang harus diambil ketika mengatur replikasi antara dua cluster Galera:
- Menerapkan kluster Galera baru
- Menyediakan cluster baru menggunakan data dari yang lama
- Konfigurasikan cluster baru (konfigurasi SST, log biner)
- Menyiapkan replikasi antara cluster lama dan baru
Tiga poin pertama adalah sesuatu yang dapat Anda lakukan dengan mudah menggunakan ClusterControl bahkan sekarang. Kami akan menunjukkan cara melakukannya.
Menerapkan dan Menyediakan Cluster MariaDB Galera Baru Menggunakan ClusterControl
Situasi awalnya serupa - kami memiliki satu cluster dan berjalan. Kita harus mengatur yang kedua. Salah satu fitur terbaru dari ClusterControl adalah opsi untuk menyebarkan cluster baru dan menyediakannya menggunakan data dari cadangan. Ini sangat berguna untuk membuat lingkungan pengujian, ini juga merupakan opsi yang akan kami gunakan untuk menyediakan cluster baru kami untuk pengaturan replikasi. Oleh karena itu langkah pertama yang akan kita lakukan adalah membuat backup menggunakan mariabackup:
Tiga langkah di mana kami memilih node untuk mengambil cadangannya. Node ini (10.0.0.101) akan menjadi master. Itu harus mengaktifkan log biner. Dalam kasus kami, semua node telah mengaktifkan binlog tetapi jika belum, sangat mudah untuk mengaktifkannya dari ClusterControl - kami akan menunjukkan langkah-langkahnya nanti, ketika kami akan melakukannya untuk cluster kedua.
Setelah pencadangan selesai, itu akan terlihat di daftar. Kami kemudian dapat melanjutkan dan memulihkannya:

Jika kita menginginkannya, kita bahkan dapat melakukan Pemulihan Point-In-Time, tetapi dalam kasus kita itu tidak terlalu penting:setelah replikasi dikonfigurasi, semua transaksi yang diperlukan dari binlog akan diterapkan pada cluster baru.

Kemudian kami memilih opsi untuk membuat cluster dari cadangan. Ini membuka dialog lain:
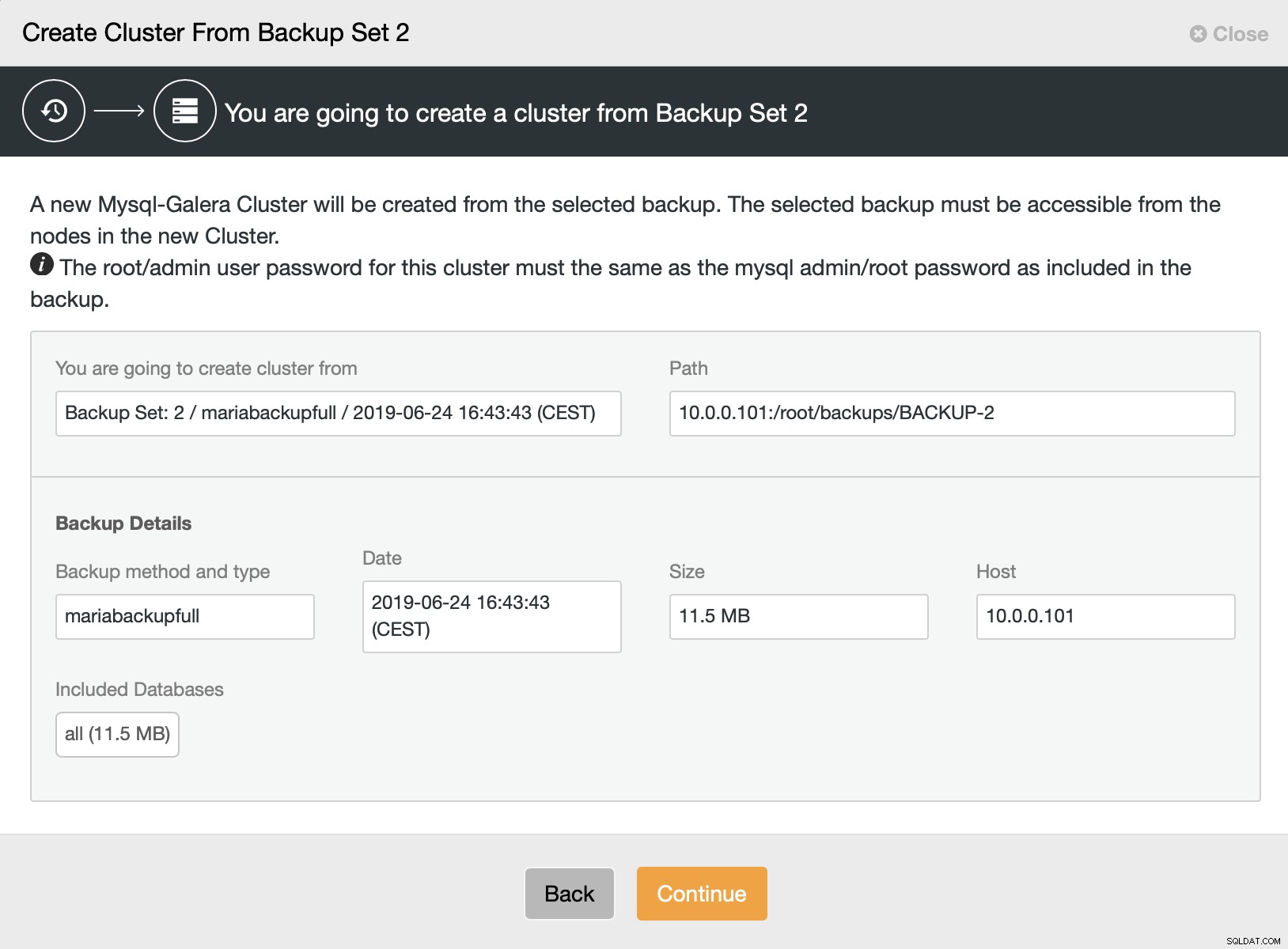
Ini adalah konfirmasi cadangan mana yang akan digunakan, dari host mana cadangan diambil, metode apa yang digunakan untuk membuatnya, dan beberapa metadata untuk membantu memverifikasi apakah cadangan terlihat baik.
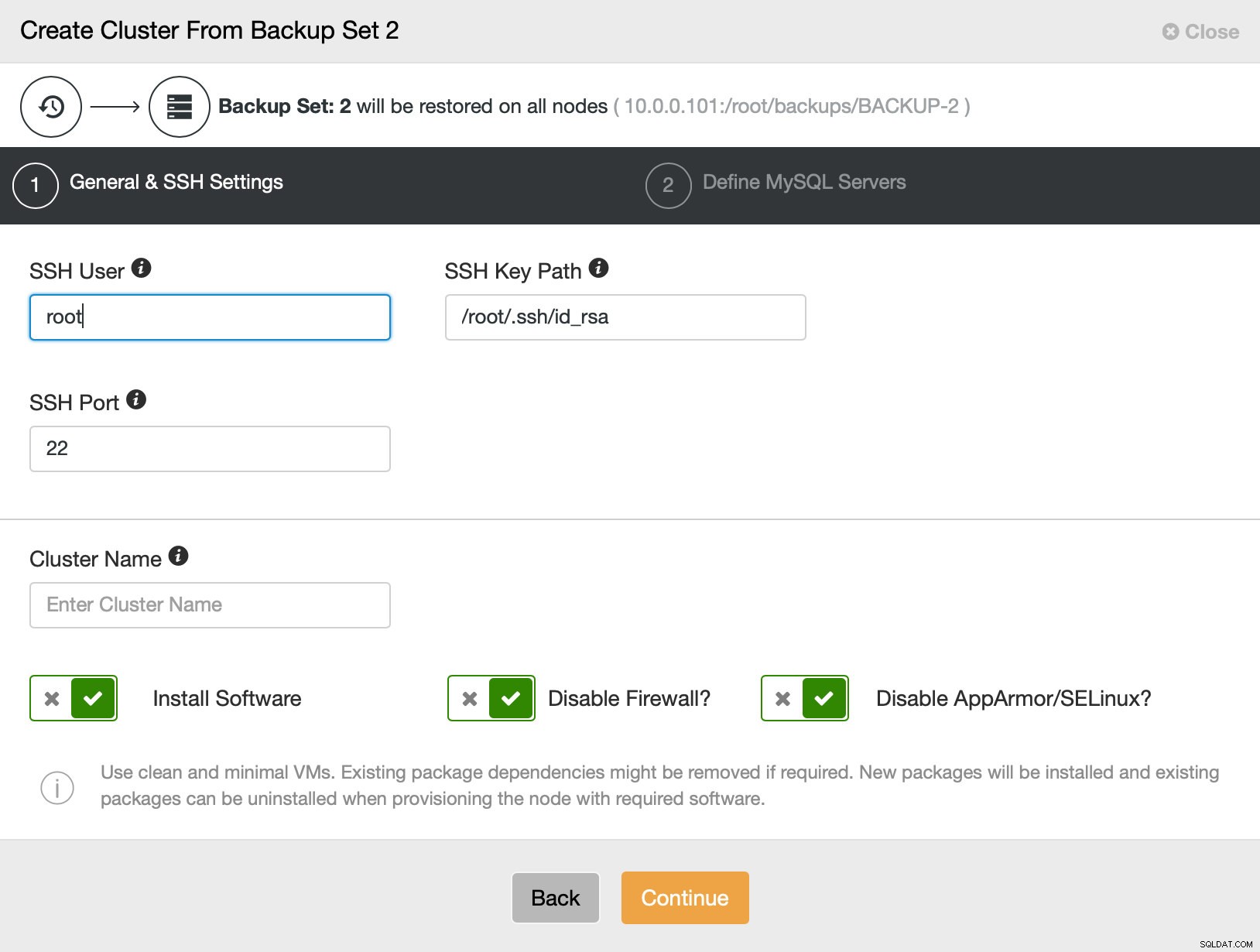
Kemudian pada dasarnya kita pergi ke wizard penyebaran reguler di mana kita harus mendefinisikan konektivitas SSH antara host ClusterControl dan node untuk menyebarkan cluster (persyaratan untuk ClusterControl) dan, pada langkah kedua, vendor, versi, kata sandi dan node untuk digunakan pada:
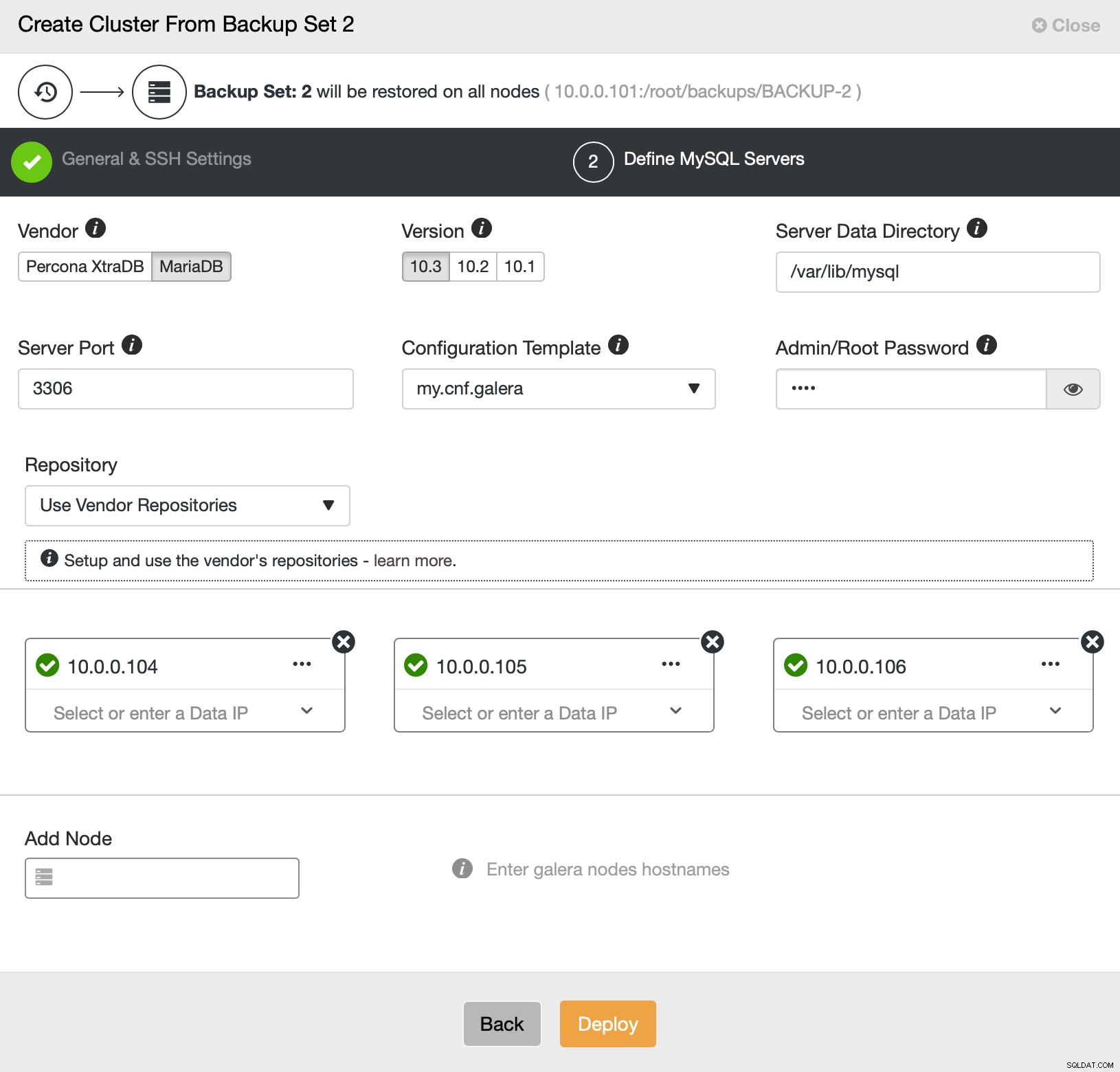
Itu saja tentang penerapan dan penyediaan. ClusterControl akan menyiapkan cluster baru dan menyediakannya menggunakan data dari yang lama.
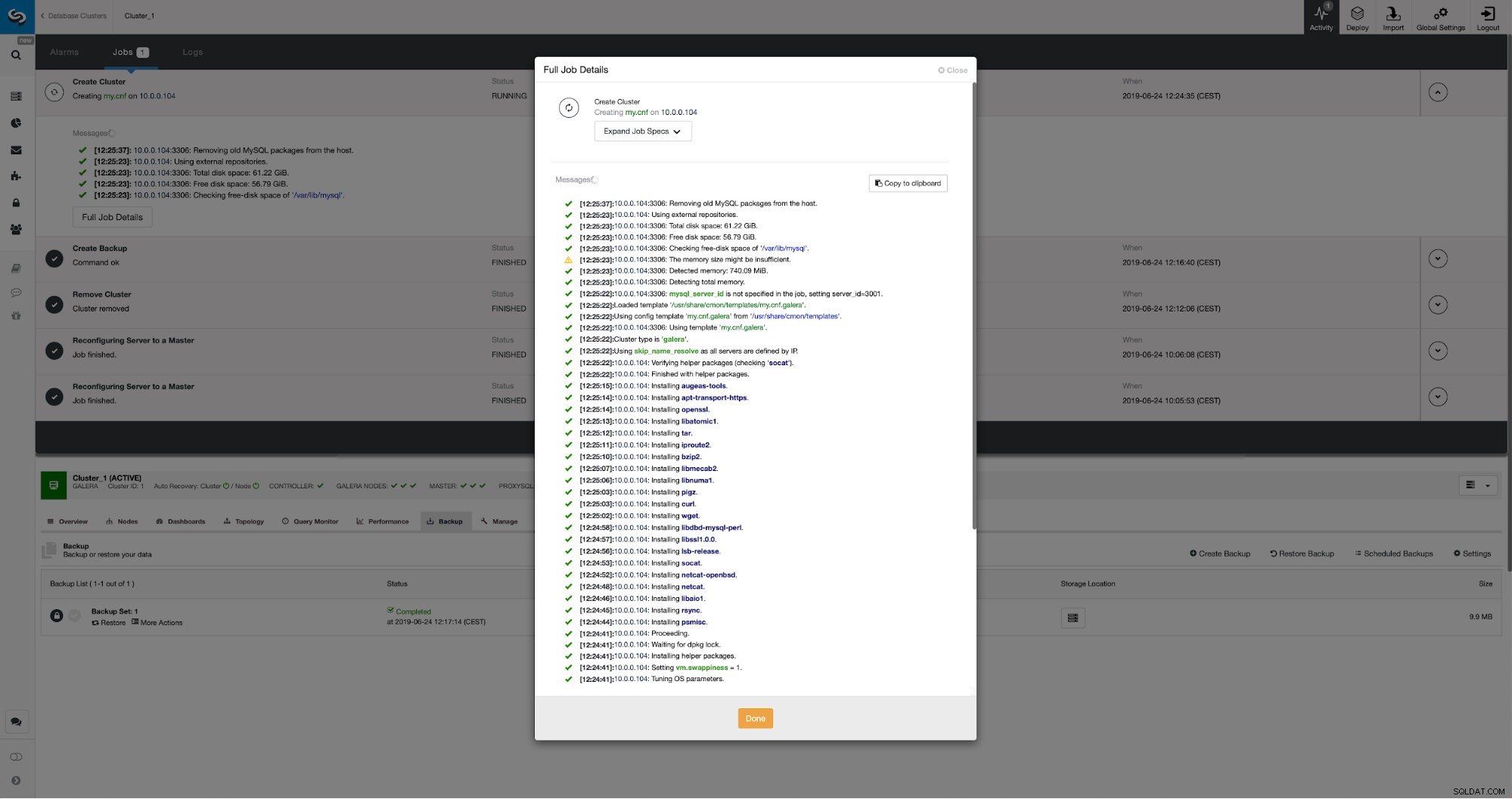
Kami dapat memantau kemajuan di tab aktivitas. Setelah selesai, cluster kedua akan muncul di daftar cluster di ClusterControl.
Konfigurasi Ulang Cluster Baru Menggunakan ClusterControl
Sekarang, kita harus mengkonfigurasi ulang cluster - kita akan mengaktifkan log biner. Dalam proses manual kami harus membuat perubahan di konfigurasi wsrep_sst_auth dan juga entri konfigurasi di bagian [mysqldump] dan [xtrabackup] dari konfigurasi. Pengaturan tersebut dapat ditemukan di file secret-backup.cnf. Kali ini tidak diperlukan karena ClusterControl menghasilkan kata sandi baru untuk cluster dan mengonfigurasi file dengan benar. Namun, yang penting untuk diingat, jika Anda mengubah kata sandi pengguna 'backupuser'@'127.0.0.1' di cluster asli, Anda harus membuat perubahan konfigurasi di cluster kedua juga untuk mencerminkannya sebagai perubahan dalam cluster pertama akan direplikasi ke cluster kedua.
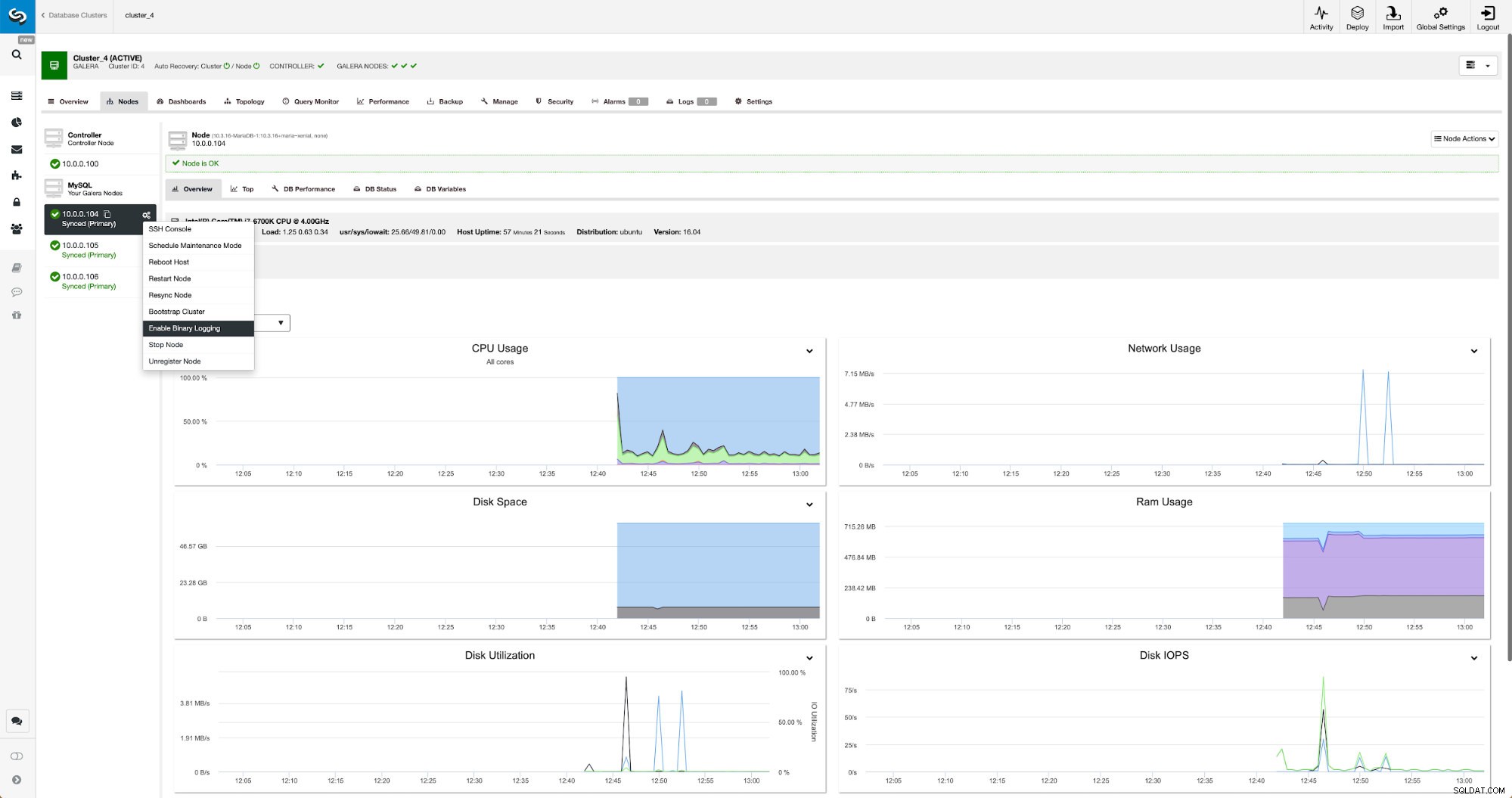
Log biner dapat diaktifkan dari bagian Node. Anda harus memilih node demi node dan menjalankan pekerjaan “Enable Binary Logging”. Anda akan disajikan dengan dialog:
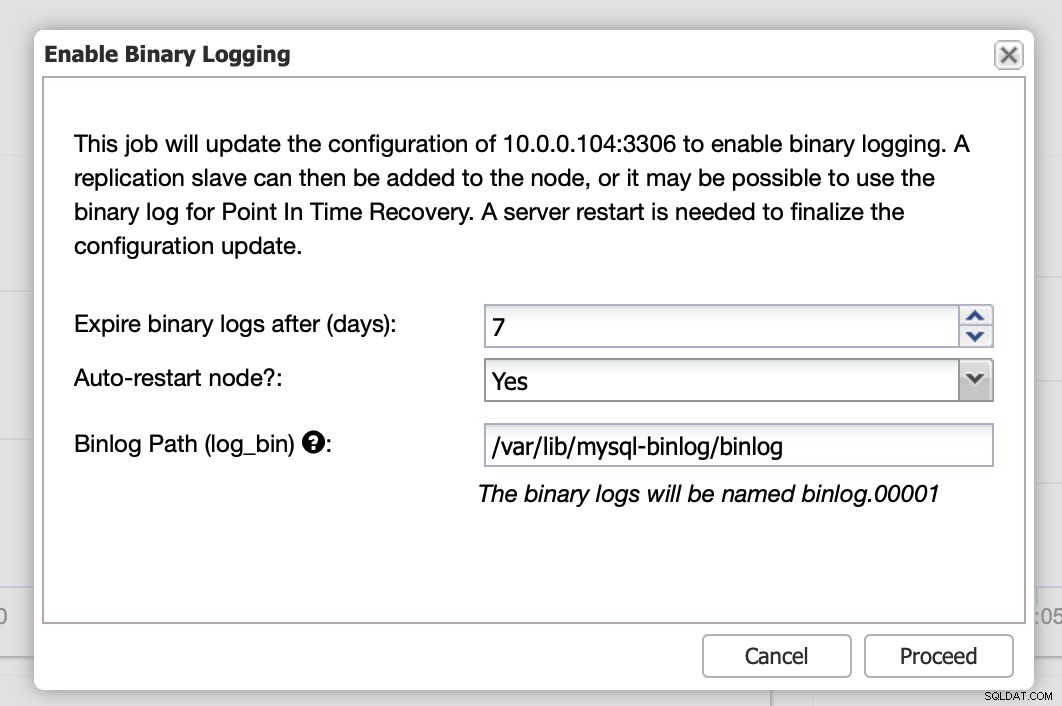
Di sini Anda dapat menentukan berapa lama Anda ingin menyimpan log, di mana mereka harus disimpan dan jika ClusterControl harus memulai ulang node agar Anda dapat menerapkan perubahan - konfigurasi log biner tidak dinamis dan MariaDB harus dimulai ulang untuk menerapkan perubahan tersebut.
Saat perubahan selesai, Anda akan melihat semua node ditandai sebagai “master”, yang berarti bahwa node tersebut mengaktifkan log biner dan dapat bertindak sebagai master.
Jika kita belum membuat pengguna replikasi, kita harus melakukannya. Di cluster pertama kita harus pergi ke Manage -> Schemas and Users:
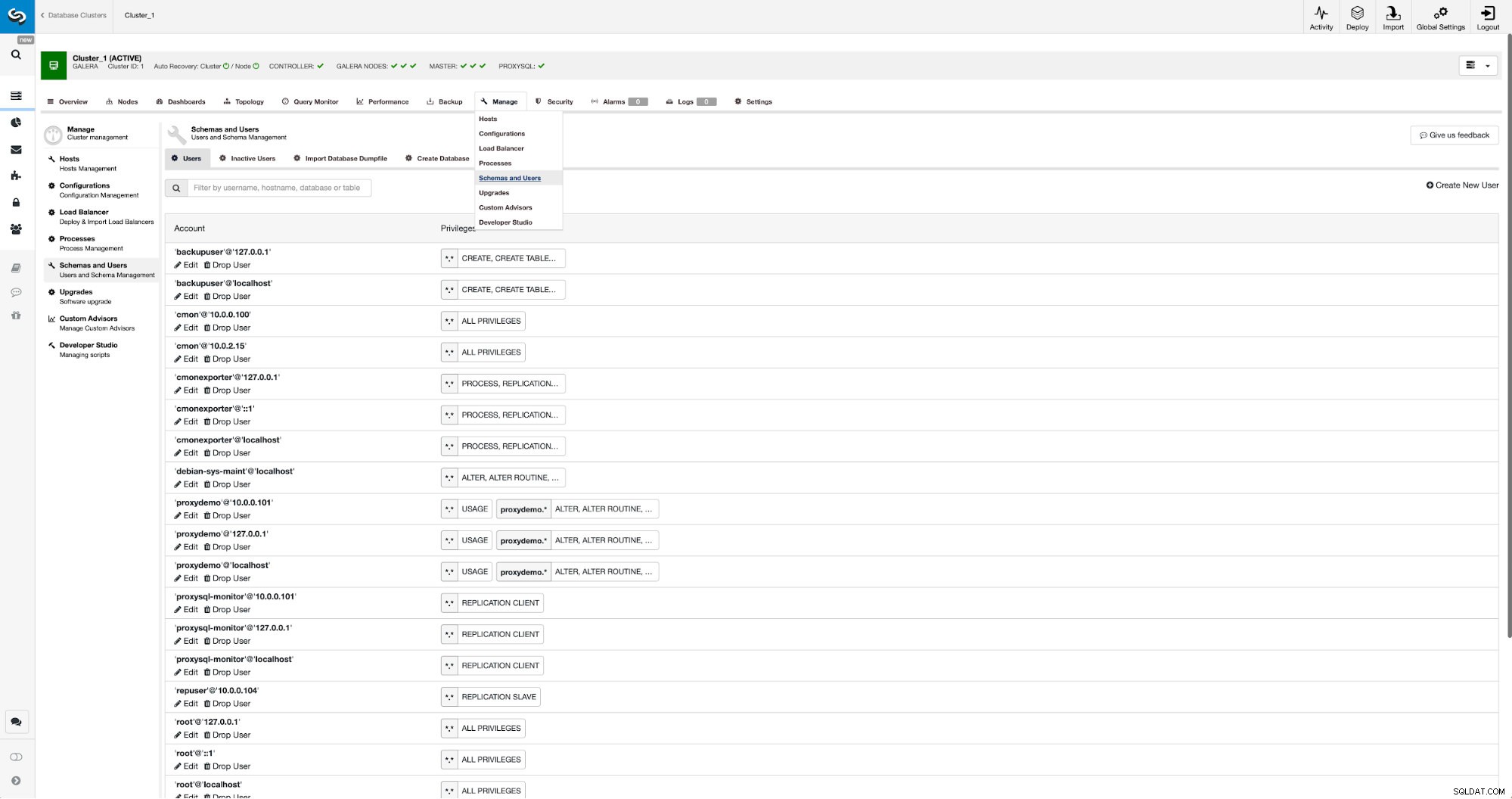
Di sisi kanan kami memiliki opsi untuk membuat pengguna baru:
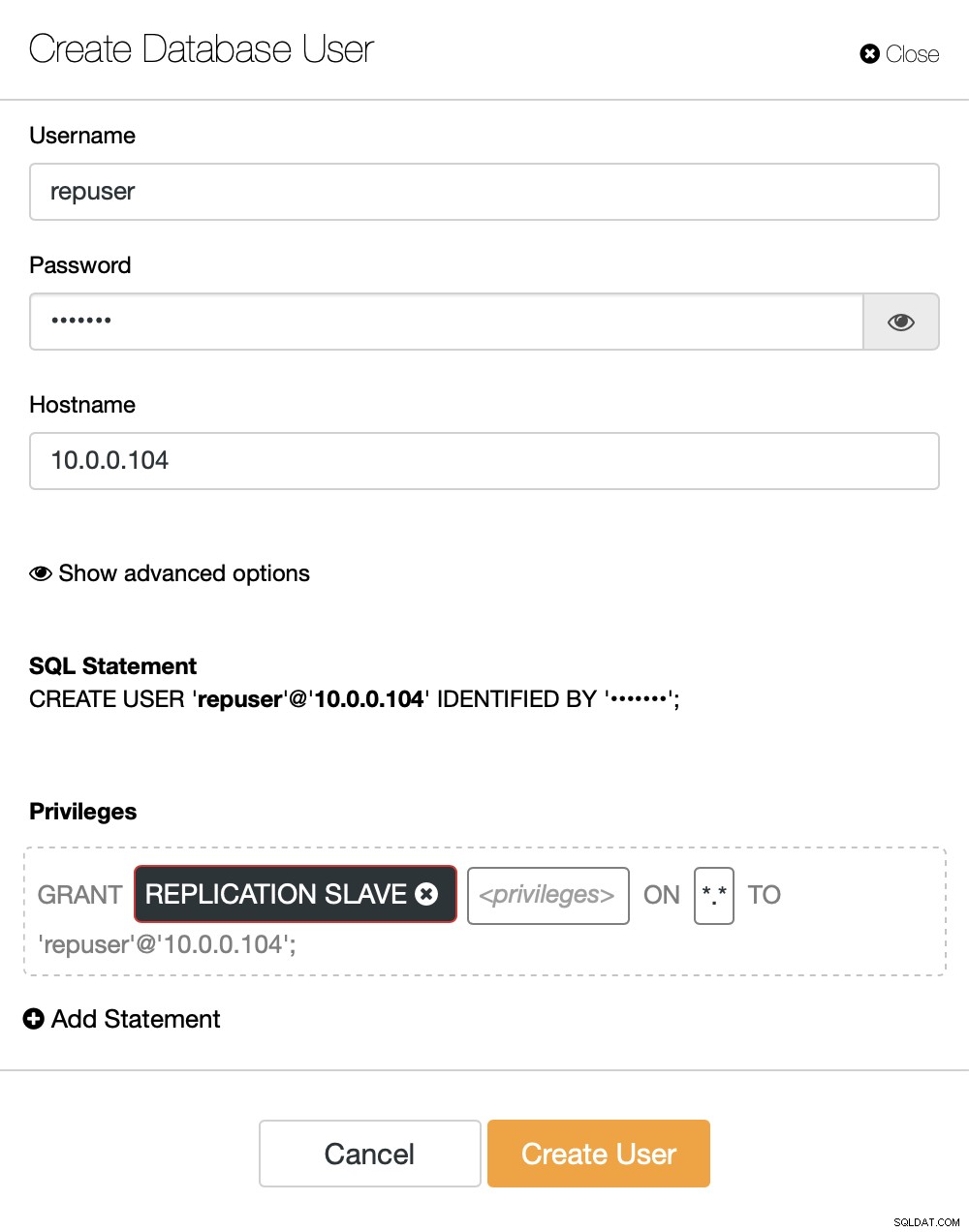
Ini menyimpulkan konfigurasi yang diperlukan untuk menyiapkan replikasi.
Menyiapkan replikasi antar cluster menggunakan ClusterControl
Seperti yang kami nyatakan, kami sedang bekerja untuk mengotomatisasi bagian ini. Saat ini harus dilakukan secara manual. Seperti yang mungkin Anda ingat, kami membutuhkan posisi GITD dari cadangan kami dan kemudian menjalankan beberapa perintah menggunakan MySQL CLI. Data GTID tersedia di cadangan. ClusterControl membuat cadangan menggunakan xbstream/mbstream dan mengompresnya setelahnya. Cadangan kami disimpan di host ClusterControl di mana kami tidak memiliki akses ke biner mbstream. Anda dapat mencoba menginstalnya atau Anda dapat menyalin file cadangan ke lokasi, di mana biner tersebut tersedia:
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/Setelah selesai, pada 10.0.0.104 kami ingin memeriksa isi file xtrabackup_info:
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'Terakhir, kami mengonfigurasi replikasi dan memulainya:
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Ini dia - kami baru saja mengonfigurasi replikasi asinkron antara dua klaster MariaDB Galera menggunakan ClusterControl. Seperti yang Anda lihat, ClusterControl mampu mengotomatiskan sebagian besar langkah yang harus kami ambil untuk menyiapkan lingkungan ini.