Catatan:Posting ini awalnya diterbitkan hanya di eBook kami, High Performance Techniques for SQL Server, Volume 3. Anda dapat mengetahui tentang eBook kami di sini.
Salah satu persyaratan yang kadang-kadang saya lihat adalah agar kueri dikembalikan dengan pesanan yang dikelompokkan berdasarkan pelanggan, menunjukkan total jatuh tempo maksimum yang terlihat untuk setiap pesanan hingga saat ini ("maks berjalan"). Jadi bayangkan contoh baris berikut:
| SalesOrderID | ID Pelanggan | Tanggal Pemesanan | Total Jatuh Tempo |
|---|---|---|---|
| 12 | 2 | 01-01-2014 | 37,55 |
| 23 | 1 | 02-01-2014 | 45.29 |
| 31 | 2 | 03-01-2014 | 24,56 |
| 32 | 2 | 04-01-2014 | 89,84 |
| 37 | 1 | 05-01-2014 | 32,56 |
| 44 | 2 | 06-01-2014 | 45,54 |
| 55 | 1 | 07-01-2014 | 99,24 |
| 62 | 2 | 08-01-2014 | 12,55 |
Beberapa baris data sampel
Hasil yang diinginkan dari persyaratan yang disebutkan adalah sebagai berikut – secara sederhana, urutkan setiap pesanan pelanggan berdasarkan tanggal, dan buat daftar setiap pesanan. Jika itu adalah nilai TotalDue tertinggi untuk semua pesanan yang terlihat hingga tanggal tersebut, cetak total pesanan tersebut, jika tidak, cetak nilai TotalDue tertinggi dari semua pesanan sebelumnya:
| SalesOrderID | ID Pelanggan | Tanggal Pemesanan | Total Jatuh Tempo | MaxTotalDue |
|---|---|---|---|---|
| 12 | 1 | 02-01-2014 | 45.29 | 45.29 |
| 23 | 1 | 05-01-2014 | 32,56 | 45.29 |
| 31 | 1 | 07-01-2014 | 99,24 | 99,24 |
| 32 | 2 | 01-01-2014 | 37,55 | 37,55 |
| 37 | 2 | 03-01-2014 | 24.56 | 37,55 |
| 44 | 2 | 04-01-2014 | 89,84 | 89,84 |
| 55 | 2 | 06-01-2014 | 45.54 | 89,84 |
| 62 | 2 | 08-01-2014 | 12,55 | 89,84 |
Contoh hasil yang diinginkan
Banyak orang secara naluriah ingin menggunakan kursor atau loop while untuk melakukannya, tetapi ada beberapa pendekatan yang tidak melibatkan konstruksi ini.
Subkueri Berkorelasi
Pendekatan ini tampaknya merupakan pendekatan paling sederhana dan paling mudah untuk masalah ini, tetapi telah terbukti berkali-kali untuk tidak menskalakan, karena pembacaan tumbuh secara eksponensial saat tabel semakin besar:
SELECT /* Correlated Subquery */ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =(SELECT MAX(TotalDue) FROM Sales.SalesOrderHeader WHERE CustomerID =h.CustomerID AND SalesOrderID <=h.SalesOrderID) FROM Sales.SalesOrderHeader AS PESAN OLEH CustomerID, SalesOrderID;
Berikut adalah rencana melawan AdventureWorks2014, menggunakan SQL Sentry Plan Explorer:
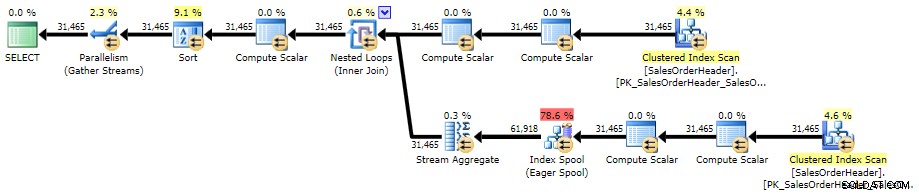 Rencana eksekusi untuk subkueri terkait (klik untuk memperbesar)
Rencana eksekusi untuk subkueri terkait (klik untuk memperbesar)
Referensi mandiri BERLAKU LINTAS
Pendekatan ini hampir identik dengan pendekatan Subquery Berkorelasi, dalam hal sintaks, bentuk rencana dan kinerja pada skala.
SELECT /* CROSS APPLY */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDueFROM Sales.SalesOrderHeader AS hCROSS APPLY( SELECT MaxTotalDue =MAX(TotalDue) FROM Sales.Sales i.CustomerID =h.CustomerID DAN i.SalesOrderID <=h.SalesOrderID) SEBAGAI xORDER BY h.CustomerID, h.SalesOrderID;
Rencananya sangat mirip dengan rencana subquery yang berkorelasi, satu-satunya perbedaan adalah lokasi semacam:
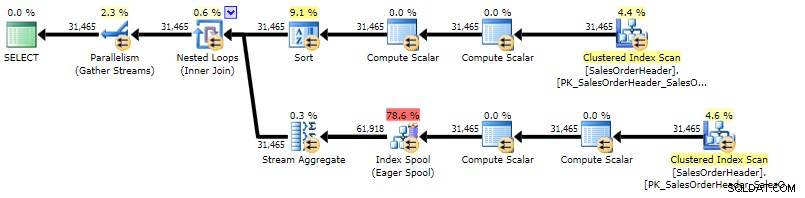 Rencana eksekusi untuk CROSS APPLY (klik untuk memperbesar)
Rencana eksekusi untuk CROSS APPLY (klik untuk memperbesar)
CTE Rekursif
Di balik layar, ini menggunakan loop, tetapi sampai kita benar-benar menjalankannya, kita dapat berpura-pura tidak melakukannya (meskipun ini adalah bagian kode paling rumit yang ingin saya tulis untuk memecahkan masalah khusus ini):
;DENGAN /* Recursive CTE */ cte AS ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue FROM ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =TotalDue, rn =ROW_NUMBER() OVER (PARTISI BY CustomerID ORDER OLEH SalesOrderID) FROM Sales.SalesOrderHeader ) AS x WHERE rn =1 UNION ALL SELECT r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue, MaxTotalDue =CASE WHEN r.TotalDue> cte.MaxTotalDue THEN .MaxTotalDue AKHIR DARI cte CROSS APPLY ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, rn =ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID) FROM Sales.SalesOrderHeader AS h WHERE h.CustomerID AND h.CustomerID =cte. cte.SalesOrderID ) AS r WHERE r.rn =1)PILIH SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDueFROM cteORDER BY CustomerID, SalesOrderIDOPTION (MAXRECURSION 0);
Anda dapat langsung melihat bahwa rencana tersebut lebih kompleks dari dua sebelumnya, yang tidak mengherankan mengingat permintaan yang lebih kompleks:
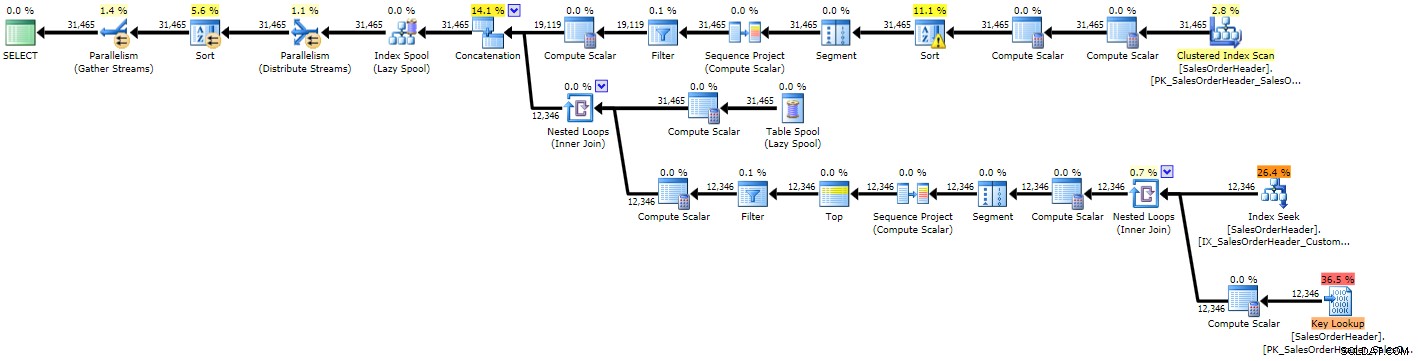 Rencana eksekusi untuk CTE rekursif (klik untuk memperbesar)
Rencana eksekusi untuk CTE rekursif (klik untuk memperbesar)
Karena beberapa perkiraan yang buruk, kami melihat pencarian indeks dengan pencarian kunci yang menyertainya yang mungkin seharusnya keduanya diganti dengan satu pemindaian, dan kami juga mendapatkan operasi pengurutan yang pada akhirnya perlu tumpah ke tempdb (Anda dapat melihat ini di tooltip jika Anda mengarahkan kursor ke operator sortir dengan ikon peringatan):

MAX() LEBIH (ROWS UNBOUNDED)
Ini adalah solusi yang hanya tersedia di SQL Server 2012 dan yang lebih tinggi, karena menggunakan ekstensi yang baru diperkenalkan untuk fungsi jendela.
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =MAX(TotalDue) OVER ( PARTITION BY CustomerID ORDER BY SalesOrderID BARIS UNBOUNDED SEBELUMNYA )FROM Sales.SalesOrderHeaderORDER BY CustomerID;Rencana tersebut menunjukkan dengan tepat mengapa skalanya lebih baik daripada yang lainnya; itu hanya memiliki satu operasi pemindaian indeks berkerumun, sebagai lawan dari dua (atau pilihan pemindaian yang buruk dan pencarian + pencarian dalam kasus CTE rekursif):
Rencana eksekusi untuk MAX() OVER() (klik untuk memperbesar)
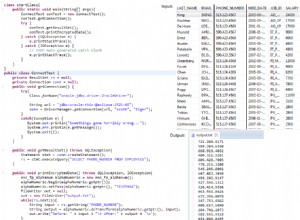
Perbandingan Kinerja
Rencana tersebut tentu membuat kami percaya bahwa
MAX() OVER()yang baru kapabilitas di SQL Server 2012 adalah pemenang sejati, tetapi bagaimana dengan metrik runtime yang nyata? Berikut perbandingan eksekusinya:
Dua pertanyaan pertama hampir identik; sedangkan dalam hal ini
CROSS APPLYlebih baik dalam hal durasi keseluruhan dengan margin kecil, subquery yang berkorelasi terkadang mengalahkannya sedikit. CTE rekursif secara substansial lebih lambat setiap saat, dan Anda dapat melihat faktor-faktor yang berkontribusi terhadap hal itu – yaitu, perkiraan buruk, jumlah besar pembacaan, pencarian kunci, dan operasi pengurutan tambahan. Dan seperti yang telah saya tunjukkan sebelumnya dengan menjalankan total, solusi SQL Server 2012 lebih baik di hampir semua aspek.Kesimpulan
Jika Anda menggunakan SQL Server 2012 atau lebih tinggi, Anda pasti ingin mengenal semua ekstensi ke fungsi windowing yang pertama kali diperkenalkan di SQL Server 2005 - mereka mungkin memberi Anda beberapa peningkatan kinerja yang cukup serius saat meninjau kembali kode yang masih berjalan " cara lama." Jika Anda ingin mempelajari lebih lanjut tentang beberapa kemampuan baru ini, saya sangat merekomendasikan buku Itzik Ben-Gan, Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions.
Jika Anda belum menggunakan SQL Server 2012, setidaknya dalam pengujian ini, Anda dapat memilih antara
CROSS APPLYdan subquery yang berkorelasi. Seperti biasa, Anda harus menguji berbagai metode terhadap data di perangkat keras Anda.