Kembali pada Januari 2015, teman baik saya dan sesama MVP SQL Server Rob Farley menulis tentang solusi baru untuk masalah menemukan median dalam versi SQL Server sebelum 2012. Selain menjadi bacaan yang menarik, ternyata menjadi contoh yang bagus untuk digunakan untuk mendemonstrasikan beberapa analisis rencana eksekusi lanjutan, dan untuk menyoroti beberapa perilaku halus dari pengoptimal kueri dan mesin eksekusi.
Median Tunggal
Meskipun artikel Rob secara khusus menargetkan kalkulasi median berkelompok, saya akan mulai dengan menerapkan metodenya pada masalah kalkulasi median tunggal yang besar, karena ini menyoroti isu-isu penting dengan paling jelas. Data sampel akan sekali lagi berasal dari artikel asli Aaron Bertrand:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Menerapkan teknik Rob Farley untuk masalah ini memberikan kode berikut:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
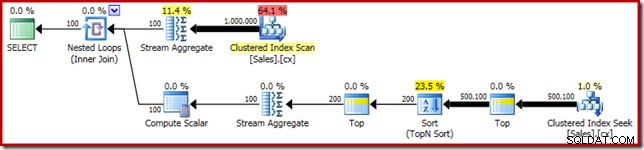
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Seperti biasa, saya berkomentar menghitung jumlah baris dalam tabel dan menggantinya dengan konstanta untuk menghindari sumber varian kinerja. Rencana eksekusi untuk kueri penting adalah sebagai berikut:

Kueri ini berjalan selama 5800 md di mesin uji saya.
Urutan Tumpahan
Penyebab utama kinerja yang buruk ini harus jelas dari melihat rencana eksekusi di atas:Peringatan pada operator Sortir menunjukkan bahwa pemberian memori ruang kerja yang tidak mencukupi menyebabkan tumpahan level 2 (multi-pass) ke tempdb disk:
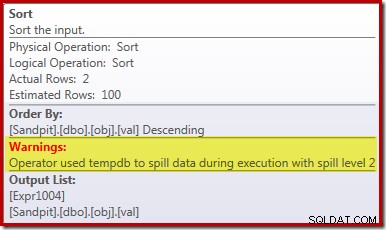
Dalam versi SQL Server sebelum 2012, Anda perlu memantau secara terpisah untuk peristiwa tumpahan sortir untuk melihat ini. Bagaimanapun, reservasi memori sortir yang tidak mencukupi disebabkan oleh kesalahan estimasi kardinalitas, seperti yang ditunjukkan oleh rencana pra-eksekusi (perkiraan):

Perkiraan kardinalitas 100 baris pada input Sortir adalah tebakan (sangat tidak akurat) oleh pengoptimal, karena ekspresi variabel lokal di operator Top sebelumnya:

Perhatikan bahwa kesalahan estimasi kardinalitas ini bukan masalah tujuan baris. Menerapkan bendera jejak 4138 akan menghapus efek sasaran baris di bawah Top pertama, tetapi perkiraan pasca-Top masih akan menjadi tebakan 100 baris (sehingga reservasi memori untuk Sort akan tetap terlalu kecil):

Menunjukkan nilai variabel lokal
Ada beberapa cara untuk menyelesaikan masalah estimasi kardinalitas ini. Salah satu opsi adalah menggunakan petunjuk untuk memberikan informasi kepada pengoptimal tentang nilai yang disimpan dalam variabel:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Menggunakan petunjuk meningkatkan kinerja menjadi 3250 md dari 5800 md. Rencana pasca-eksekusi menunjukkan bahwa jenis tidak lagi tumpah:

Ada beberapa kerugian untuk ini meskipun. Pertama, rencana eksekusi baru ini membutuhkan 388MB pemberian memori – memori yang dapat digunakan oleh server untuk menyimpan rencana, indeks, dan data:
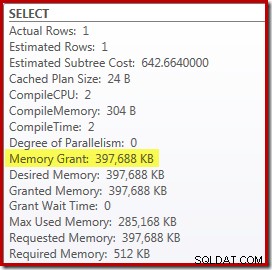
Kedua, mungkin sulit untuk memilih nomor yang bagus untuk petunjuk yang akan bekerja dengan baik untuk semua eksekusi di masa mendatang, tanpa perlu menyimpan memori.
Perhatikan juga bahwa kita harus menunjukkan nilai untuk variabel yang 10% lebih tinggi dari nilai sebenarnya dari variabel untuk menghilangkan tumpahan sepenuhnya. Ini tidak biasa, karena algoritma pengurutan umum agak lebih kompleks daripada pengurutan di tempat yang sederhana. Mencadangkan memori yang sama dengan ukuran set yang akan diurutkan tidak akan selalu (atau bahkan secara umum) cukup untuk menghindari tumpahan saat runtime.
Menyematkan dan Mengkompilasi Ulang
Opsi lainnya adalah memanfaatkan Pengoptimalan Penyematan Parameter yang diaktifkan dengan menambahkan petunjuk kompilasi ulang tingkat kueri pada SQL Server 2008 SP1 CU5 atau yang lebih baru. Tindakan ini akan memungkinkan pengoptimal melihat nilai waktu proses variabel, dan mengoptimalkannya:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Ini meningkatkan waktu eksekusi menjadi 3150 md – 100 ms lebih baik daripada menggunakan OPTIMIZE FOR petunjuk. Alasan untuk perbaikan kecil lebih lanjut ini dapat dilihat dari rencana pasca-eksekusi yang baru:

Ekspresi (2 – @Count % 2) – seperti yang terlihat sebelumnya di operator Top kedua – sekarang dapat dilipat menjadi satu nilai yang diketahui. Penulisan ulang pasca-optimasi kemudian dapat menggabungkan Top dengan Sort, menghasilkan satu Top N Sort. Penulisan ulang ini sebelumnya tidak mungkin karena menciutkan Top + Sort menjadi Top N Sort hanya berfungsi dengan nilai Top literal konstan (bukan variabel atau parameter).
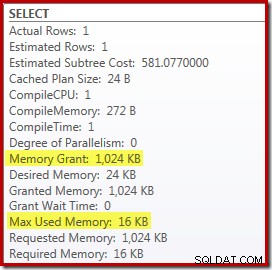
Mengganti Top dan Sort dengan Top N Sort memiliki efek menguntungkan kecil pada kinerja (100ms di sini), tetapi juga hampir seluruhnya menghilangkan kebutuhan memori, karena Top N Sort hanya harus melacak N tertinggi (atau terendah) baris, bukan seluruh rangkaian. Sebagai akibat dari perubahan algoritme ini, rencana pasca-eksekusi untuk kueri ini menunjukkan bahwa minimum 1MB memori dicadangkan untuk Top N Sort dalam paket ini, dan hanya 16KB digunakan saat runtime (ingat, paket full-sort membutuhkan 388MB):
Menghindari Kompilasi Ulang
Kelemahan (jelas) menggunakan petunjuk kueri kompilasi ulang adalah memerlukan kompilasi penuh pada setiap eksekusi. Dalam hal ini, overhead cukup kecil – sekitar 1ms waktu CPU dan memori 272KB. Meski begitu, ada cara untuk mengubah kueri sehingga kita mendapatkan manfaat dari Top N Sort tanpa menggunakan petunjuk apa pun, dan tanpa kompilasi ulang.
Idenya berasal dari pengakuan bahwa maksimum dari dua baris akan diperlukan untuk perhitungan median akhir. Mungkin satu baris, atau mungkin dua saat runtime, tetapi tidak akan pernah bisa lebih. Wawasan ini berarti kita dapat menambahkan langkah perantara Top (2) yang redundan secara logis ke kueri sebagai berikut:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Top baru (dengan literal konstan yang sangat penting) berarti rencana eksekusi akhir menampilkan operator Top N Sort yang diinginkan tanpa kompilasi ulang:

Performa rencana eksekusi ini tidak berubah dari versi petunjuk kompilasi ulang pada 3150 md dan kebutuhan memorinya sama. Perhatikan bahwa kurangnya penyematan parameter berarti perkiraan kardinalitas di bawah pengurutan adalah tebakan 100 baris (meskipun itu tidak memengaruhi kinerja di sini).
Kesimpulan utama pada tahap ini adalah jika Anda menginginkan Top N Sort dengan memori rendah, Anda harus menggunakan literal konstan, atau mengaktifkan pengoptimal untuk melihat literal melalui pengoptimalan penyematan parameter.
Skalar Hitung
Menghilangkan 388MB hibah memori (sambil juga membuat peningkatan kinerja 100ms) tentu saja bermanfaat, tetapi ada kemenangan kinerja yang jauh lebih besar yang tersedia. Target yang tidak mungkin dari peningkatan akhir ini adalah Compute Scalar tepat di atas Clustered Index Scan.
Skalar Hitung ini berhubungan dengan ekspresi (0E + f.val) terkandung dalam AVG agregat dalam kueri. Jika terlihat aneh bagi Anda, ini adalah trik penulisan kueri yang cukup umum (seperti mengalikan dengan 1,0) untuk menghindari aritmatika bilangan bulat dalam perhitungan rata-rata, tetapi ini memiliki beberapa efek samping yang sangat penting.
Ada urutan peristiwa tertentu di sini yang perlu kita ikuti langkah demi langkah.
Pertama, perhatikan bahwa 0E adalah nol literal konstan, dengan float tipe data. Untuk menambahkan ini ke val kolom integer, pemroses kueri harus mengonversi kolom dari integer ke float (sesuai dengan aturan prioritas tipe data). Jenis konversi serupa akan diperlukan jika kita memilih untuk mengalikan kolom dengan 1,0 (literal dengan tipe data numerik implisit). Poin pentingnya adalah trik rutin ini memperkenalkan ekspresi .
Sekarang, SQL Server biasanya mencoba mendorong ekspresi ke bawah pohon rencana sejauh mungkin selama kompilasi dan optimasi. Ini dilakukan karena beberapa alasan, termasuk untuk membuat pencocokan ekspresi dengan kolom yang dihitung lebih mudah, dan untuk memfasilitasi penyederhanaan menggunakan informasi kendala. Kebijakan push-down ini menjelaskan mengapa Compute Scalar muncul lebih dekat ke tingkat daun rencana daripada posisi tekstual asli dari ekspresi dalam kueri yang disarankan.
Risiko melakukan push-down ini adalah bahwa ekspresi mungkin akan dihitung lebih banyak dari yang diperlukan. Sebagian besar paket menampilkan pengurangan jumlah baris saat kami naik ke pohon rencana, karena efek gabungan, agregasi, dan filter. Oleh karena itu, mendorong ekspresi ke bawah pohon berisiko mengevaluasi ekspresi tersebut lebih sering (yaitu pada lebih banyak baris) daripada yang diperlukan.
Untuk mengurangi hal ini, SQL Server 2005 memperkenalkan pengoptimalan di mana Compute Scalars dapat dengan mudah mendefinisikan sebuah ekspresi, dengan pekerjaan sebenarnya mengevaluasi ekspresi ditangguhkan sampai operator selanjutnya dalam rencana membutuhkan hasilnya. Saat pengoptimalan ini berfungsi sebagaimana dimaksud, efeknya adalah mendapatkan semua manfaat dari mendorong ekspresi ke bawah pohon, sementara masih benar-benar mengevaluasi ekspresi sebanyak yang sebenarnya diperlukan.
Apa arti dari semua hal Hitung Skalar ini
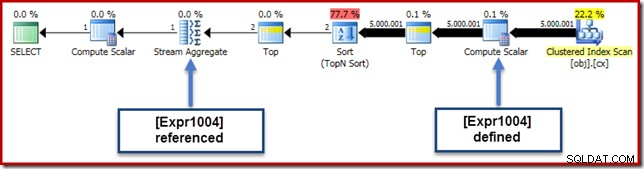
Dalam contoh kami yang sedang berjalan, 0E + val ekspresi awalnya dikaitkan dengan AVG agregat, jadi kami mungkin berharap untuk melihatnya di (atau sedikit setelah) Stream Agregate. Namun, ekspresi ini ditekan pohon menjadi Skalar Hitung baru setelah pemindaian, dengan ekspresi berlabel [Expr1004].
Melihat rencana eksekusi, kita dapat melihat bahwa [Expr1004] direferensikan oleh Stream Aggregate (ekstrak Tab Ekspresi Plan Explorer ditunjukkan di bawah):

Semua hal dianggap sama, evaluasi ekspresi [Expr1004] akan ditangguhkan sampai agregat membutuhkan nilai-nilai tersebut untuk jumlah bagian dari perhitungan rata-rata. Karena agregat hanya mungkin menemukan satu atau dua baris, ini akan mengakibatkan [Expr1004] dievaluasi hanya sekali atau dua kali:
Sayangnya, ini bukan cara kerjanya di sini. Masalahnya adalah pemblokiran operator Sort:
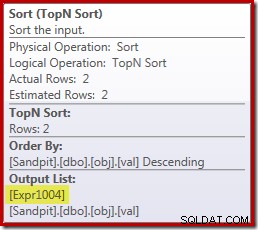
Ini memaksa evaluasi [Expr1004], jadi alih-alih dievaluasi hanya sekali atau dua kali di Stream Aggregate, Sort berarti kita akhirnya mengonversi val kolom ke float dan menambahkan nol padanya 5.000.001 kali!
Solusi
Idealnya, SQL Server akan sedikit lebih pintar tentang semua ini, tetapi bukan itu cara kerjanya hari ini. Tidak ada petunjuk kueri untuk mencegah ekspresi didorong ke bawah pohon rencana, dan kami juga tidak dapat memaksa Hitung Skalar dengan Panduan Rencana. Ada, mau tidak mau, tanda jejak yang tidak berdokumen, tetapi itu bukan yang dapat saya bicarakan secara bertanggung jawab dalam konteks saat ini.
Jadi, baik atau buruk, ini membuat kita mencoba menemukan penulisan ulang kueri yang terjadi untuk mencegah SQL Server memisahkan ekspresi dari agregat dan mendorongnya melewati Sort, tanpa mengubah hasil kueri. Ini tidak semudah yang Anda bayangkan, tetapi modifikasi (diakui sedikit aneh) di bawah ini mencapai ini menggunakan CASE ekspresi pada fungsi intrinsik non-deterministik:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Rencana eksekusi untuk bentuk akhir kueri ini ditunjukkan di bawah ini:

Perhatikan bahwa Compute Scalar tidak lagi muncul di antara Clustered Index Scan dan Top. 0E + val ekspresi sekarang dihitung di Agregat Aliran pada maksimum dua baris (bukan lima juta!) dan kinerja meningkat lebih lanjut 32% dari 3150 md hingga 2150 md sebagai hasilnya.
Ini masih tidak sebanding dengan kinerja sub-detik dari OFFSET dan solusi kalkulasi median kursor dinamis, namun tetap menunjukkan peningkatan yang sangat signifikan dibandingkan 5800 md asli untuk metode ini pada kumpulan masalah median tunggal yang besar.
Trik CASE tidak dijamin akan berhasil di masa depan, tentu saja. Kesimpulannya bukan tentang menggunakan trik ekspresi kasus yang aneh, tetapi tentang implikasi kinerja potensial dari Skalar Hitung. Setelah mengetahui hal semacam ini, Anda mungkin berpikir dua kali sebelum mengalikan dengan 1,0 atau menambahkan float nol dalam perhitungan rata-rata.
Pembaruan: silakan lihat komentar pertama untuk solusi yang bagus oleh Robert Heinig yang tidak memerlukan tipu daya yang tidak berdokumen. Sesuatu yang perlu diingat ketika Anda selanjutnya tergoda untuk mengalikan bilangan bulat dengan desimal (atau float) satu dalam agregat rata-rata.
Median yang Dikelompokkan
Untuk kelengkapan, dan untuk mengaitkan analisis ini lebih dekat dengan artikel asli Rob, kami akan menyelesaikannya dengan menerapkan peningkatan yang sama pada kalkulasi median yang dikelompokkan. Ukuran set yang lebih kecil (per grup) berarti efeknya akan lebih kecil, tentu saja.
Data sampel median yang dikelompokkan (sekali lagi seperti yang awalnya dibuat oleh Aaron Bertrand) terdiri dari sepuluh ribu baris untuk masing-masing dari seratus tenaga penjualan imajiner:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); Menerapkan solusi Rob Farley secara langsung memberikan kode berikut, yang dieksekusi dalam 560 md di mesin saya.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Rencana eksekusi memiliki kesamaan yang jelas dengan median tunggal:
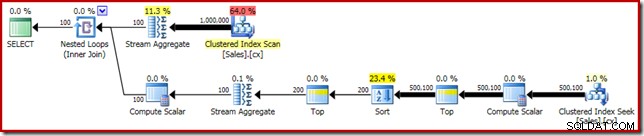
Perbaikan pertama kami adalah mengganti Sort dengan Top N Sort, dengan menambahkan Top secara eksplisit (2). Ini sedikit meningkatkan waktu eksekusi dari 560 md menjadi 550 md .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Rencana eksekusi menunjukkan Top N Sort seperti yang diharapkan:
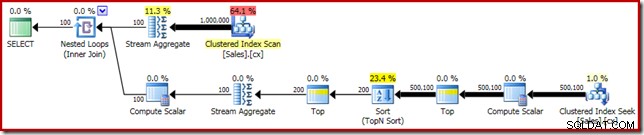
Terakhir, kami menerapkan ekspresi CASE yang tampak aneh untuk menghapus ekspresi Compute Scalar yang didorong. Ini semakin meningkatkan kinerja menjadi 450 md (peningkatan 20% dari yang asli):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Rencana eksekusi yang telah selesai adalah sebagai berikut: