Artikel ini membahas beberapa fitur dan batasan pengoptimal kueri yang kurang terkenal, dan menjelaskan alasan kinerja hash join yang sangat buruk dalam kasus tertentu.
Contoh Data
Contoh skrip pembuatan data berikut bergantung pada tabel angka yang sudah ada. Jika Anda belum memilikinya, skrip di bawah ini dapat digunakan untuk membuatnya secara efisien. Tabel yang dihasilkan akan berisi satu kolom bilangan bulat dengan angka dari satu hingga satu juta:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
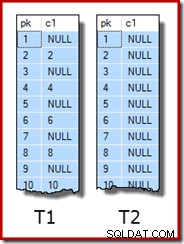
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Data sampel itu sendiri terdiri dari dua tabel, T1 dan T2. Keduanya memiliki kolom kunci primer bilangan bulat berurutan bernama pk, dan kolom nullable kedua bernama c1. Tabel T1 memiliki 600.000 baris di mana baris bernomor genap memiliki nilai yang sama untuk c1 sebagai kolom pk, dan baris bernomor ganjil adalah nol. Tabel c2 memiliki 32.000 baris di mana kolom c1 adalah NULL di setiap baris. Skrip berikut membuat dan mengisi tabel ini:
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; Sepuluh baris pertama data sampel di setiap tabel terlihat seperti ini:
Bergabung dengan dua tabel
Pengujian pertama ini melibatkan penggabungan dua tabel pada kolom c1 (bukan kolom pk), dan mengembalikan nilai pk dari tabel T1 untuk baris yang bergabung:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
Kueri sebenarnya tidak akan mengembalikan baris karena kolom c1 adalah NULL di semua baris tabel T2, jadi tidak ada baris yang cocok dengan predikat gabungan kesetaraan. Ini mungkin terdengar aneh untuk dilakukan, tetapi saya yakin ini didasarkan pada kueri produksi nyata (sangat disederhanakan untuk memudahkan diskusi).
Perhatikan bahwa hasil kosong ini tidak bergantung pada pengaturan ANSI_NULLS, karena itu hanya mengontrol bagaimana perbandingan dengan literal nol atau variabel ditangani. Untuk perbandingan kolom, predikat kesetaraan selalu menolak nol.
Rencana eksekusi untuk kueri gabungan sederhana ini memiliki beberapa fitur menarik. Pertama-tama kita akan melihat rencana pra-eksekusi ('perkiraan') di SQL Sentry Plan Explorer:
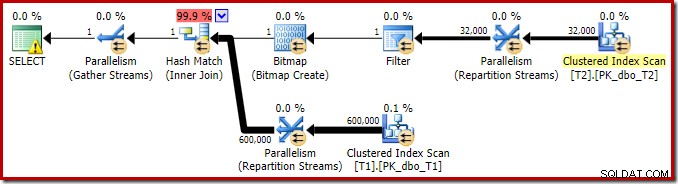
Peringatan pada ikon SELECT hanya mengeluh tentang indeks yang hilang pada tabel T1 untuk kolom c1 (dengan pk sebagai kolom yang disertakan). Saran indeks tidak relevan di sini.
Item pertama yang menarik dalam rencana ini adalah Filter:
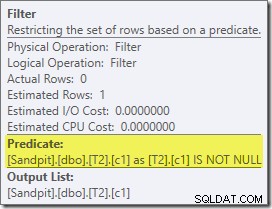
Predikat IS NOT NULL ini tidak muncul dalam kueri sumber, meskipun tersirat dalam predikat join seperti yang telah disebutkan sebelumnya. Sangat menarik bahwa itu telah dipecah sebagai operator ekstra eksplisit, dan ditempatkan sebelum operasi gabungan. Perhatikan bahwa bahkan tanpa Filter, kueri akan tetap menghasilkan hasil yang benar – gabungan itu sendiri akan tetap menolak nol.
Filter penasaran karena alasan lain juga. Ini memiliki perkiraan biaya persis nol (meskipun diharapkan untuk beroperasi pada 32.000 baris), dan belum didorong ke dalam Clustered Index Scan sebagai predikat residual. Pengoptimal biasanya sangat tertarik untuk melakukan ini.
Kedua hal ini dijelaskan oleh fakta bahwa Filter ini diperkenalkan dalam penulisan ulang pasca-optimasi. Setelah pengoptimal kueri menyelesaikan pemrosesan berbasis biaya, ada sejumlah kecil penulisan ulang rencana tetap yang dipertimbangkan. Salah satunya bertanggung jawab untuk memperkenalkan Filter.
Kita dapat melihat output dari pemilihan paket berbasis biaya (sebelum penulisan ulang) menggunakan tanda jejak tidak berdokumen 8607 dan 3604 yang sudah dikenal untuk mengarahkan output tekstual ke konsol (tab pesan di SSMS):
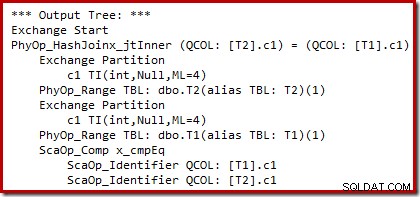
Pohon keluaran menunjukkan gabungan hash, dua pemindaian, dan beberapa operator paralelisme (pertukaran). Tidak ada Filter penolakan nol pada kolom c1 tabel T2.
Penulisan ulang pasca-optimasi khusus terlihat secara eksklusif pada input build dari hash join. Bergantung pada penilaian situasinya, mungkin menambahkan Filter eksplisit untuk menolak baris yang nol di kunci gabungan. Pengaruh Filter pada taksiran jumlah baris juga ditulis ke dalam rencana eksekusi, tetapi karena pengoptimalan berbasis biaya telah selesai, biaya untuk Filter tidak dihitung. Jika tidak jelas, biaya komputasi merupakan upaya yang sia-sia jika semua keputusan berbasis biaya telah dibuat.
Filter tetap langsung pada input build alih-alih didorong ke dalam Pemindaian Indeks Clustered karena aktivitas pengoptimalan utama telah selesai. Penulisan ulang pasca-pengoptimalan secara efektif merupakan penyesuaian menit terakhir untuk rencana eksekusi yang telah selesai.
Penulisan ulang pasca-optimasi kedua, dan cukup terpisah, bertanggung jawab atas operator Bitmap dalam rencana akhir (Anda mungkin telah memperhatikan bahwa itu juga hilang dari keluaran 8607):
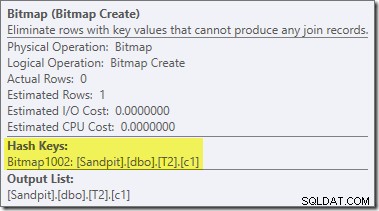
Operator ini juga memiliki perkiraan biaya nol untuk I/O dan CPU. Hal lain yang mengidentifikasinya sebagai operator yang diperkenalkan oleh tweak yang terlambat (bukan selama optimasi berbasis biaya) adalah bahwa namanya adalah Bitmap diikuti dengan angka. Ada jenis bitmap lain yang diperkenalkan selama pengoptimalan berbasis biaya seperti yang akan kita lihat nanti.
Untuk saat ini, hal penting tentang bitmap ini adalah ia mencatat nilai c1 yang terlihat selama fase pembuatan hash join. Bitmap yang telah selesai didorong ke sisi probe dari gabungan ketika transisi hash dari fase build ke fase probe. Bitmap digunakan untuk melakukan reduksi semi-join awal, menghilangkan baris dari sisi probe yang tidak mungkin bergabung. jika Anda memerlukan detail lebih lanjut tentang ini, silakan lihat artikel saya sebelumnya tentang masalah ini.
Efek kedua dari bitmap dapat dilihat pada Clustered Index Scan sisi probe:
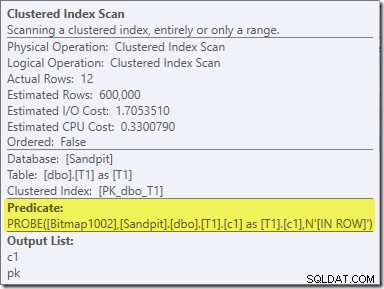
Tangkapan layar di atas menunjukkan bitmap yang telah selesai diperiksa sebagai bagian dari Clustered Index Scan pada tabel T1. Karena kolom sumber adalah bilangan bulat (biint juga akan berfungsi), pemeriksaan bitmap didorong sepenuhnya ke dalam mesin penyimpanan (seperti yang ditunjukkan oleh kualifikasi 'INROW') daripada diperiksa oleh prosesor kueri. Secara lebih umum, bitmap dapat diterapkan ke operator mana pun di sisi probe, mulai dari pertukaran ke bawah. Seberapa jauh pemroses kueri dapat mendorong bitmap bergantung pada jenis kolom dan versi SQL Server.
Untuk melengkapi analisis fitur utama dari rencana eksekusi ini, kita perlu melihat rencana pasca-eksekusi ('aktual'):
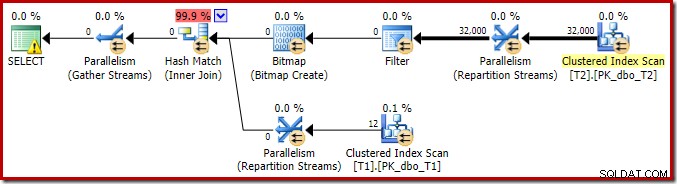
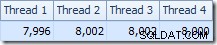
Hal pertama yang harus diperhatikan adalah distribusi baris melintasi utas antara pemindaian T2 dan pertukaran Repartition Streams tepat di atasnya. Pada satu uji coba, saya melihat distribusi berikut pada sistem dengan empat prosesor logis:
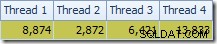
Distribusinya tidak terlalu merata, seperti yang sering terjadi pada pemindaian paralel pada jumlah baris yang relatif kecil, tetapi setidaknya semua utas menerima beberapa pekerjaan. Distribusi utas antara pertukaran Aliran Partisi Ulang yang sama dan Filter sangat berbeda:
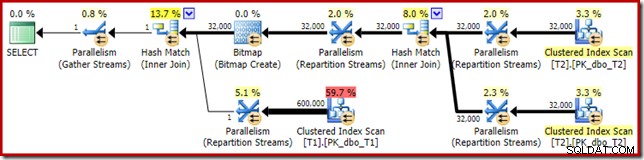
Ini menunjukkan bahwa semua 32.000 baris dari tabel T2 diproses oleh satu utas. Untuk mengetahui alasannya, kita perlu melihat properti pertukaran:

Pertukaran ini, seperti yang ada di sisi probe dari hash join, perlu memastikan bahwa baris dengan nilai kunci join yang sama berakhir pada instance hash join yang sama. Di DOP 4, ada empat hash join, masing-masing dengan tabel hashnya sendiri. Untuk hasil yang benar, baris build-side dan baris probe-side dengan kunci gabungan yang sama harus sampai pada hash join yang sama; jika tidak, kami mungkin memeriksa baris sisi-penyelidikan terhadap tabel hash yang salah.
Dalam rencana paralel mode baris, SQL Server mencapai ini dengan mempartisi ulang kedua input menggunakan fungsi hash yang sama pada kolom gabungan. Dalam kasus ini, gabungan ada di kolom c1, jadi input didistribusikan di seluruh utas dengan menerapkan fungsi hash (tipe partisi:hash) ke kolom kunci gabungan (c1). Masalahnya di sini adalah bahwa kolom c1 hanya berisi satu nilai – null – dalam tabel T2, jadi semua 32.000 baris diberi nilai hash yang sama, sehingga semua berakhir di thread yang sama.
Berita baiknya adalah tidak ada yang benar-benar penting untuk kueri ini. Filter penulisan ulang pasca-optimasi menghilangkan semua baris sebelum banyak pekerjaan selesai. Di laptop saya, kueri di atas dijalankan (tidak memberikan hasil, seperti yang diharapkan) dalam waktu sekitar 70 md .
Bergabung dengan tiga tabel
Untuk pengujian kedua, kami menambahkan gabungan tambahan dari tabel T2 ke dirinya sendiri pada kunci utamanya:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
Ini tidak mengubah hasil logis kueri, tetapi mengubah rencana eksekusi:
Seperti yang diharapkan, self-join tabel T2 pada kunci utamanya tidak berpengaruh pada jumlah baris yang memenuhi syarat dari tabel itu:
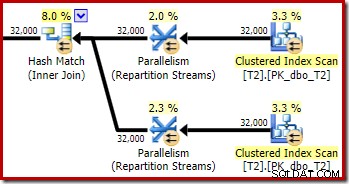
Distribusi baris melintasi utas juga bagus di bagian rencana ini. Untuk pemindaian, ini mirip dengan sebelumnya karena pemindaian paralel mendistribusikan baris ke utas sesuai permintaan. Partisi ulang pertukaran berdasarkan hash dari kunci gabung, yang merupakan kolom pk kali ini. Mengingat rentang nilai pk yang berbeda, distribusi utas yang dihasilkan juga sangat merata:
Beralih ke bagian yang lebih menarik dari perkiraan rencana, ada beberapa perbedaan dari pengujian dua tabel:

Sekali lagi, pertukaran sisi build akhirnya mengarahkan semua baris ke utas yang sama karena c1 adalah kunci gabungan, dan karenanya kolom partisi untuk pertukaran Aliran Ulang (ingat, c1 adalah nol untuk semua baris dalam tabel T2).
Ada dua perbedaan penting lainnya di bagian rencana ini dibandingkan dengan tes sebelumnya. Pertama, tidak ada Filter untuk menghapus baris null-c1 dari sisi build dari hash join. Penjelasannya terkait dengan perbedaan kedua – Bitmap telah berubah, meskipun tidak terlihat jelas dari gambar di atas:
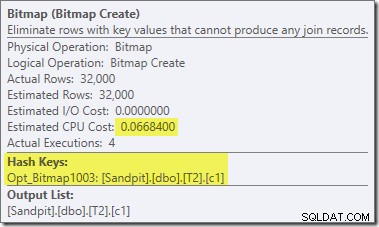
Ini adalah Opt_Bitmap, bukan Bitmap. Perbedaannya adalah bahwa bitmap ini diperkenalkan selama pengoptimalan berbasis biaya, bukan dengan penulisan ulang menit terakhir. Mekanisme yang mempertimbangkan bitmap yang dioptimalkan dikaitkan dengan pemrosesan kueri star-join. Logika star-join membutuhkan setidaknya tiga tabel gabungan, jadi ini menjelaskan mengapa dioptimalkan bitmap tidak dipertimbangkan dalam contoh penggabungan dua tabel.
Bitmap yang dioptimalkan ini memiliki perkiraan biaya CPU yang tidak nol, dan secara langsung memengaruhi keseluruhan paket yang dipilih oleh pengoptimal. Efeknya pada perkiraan kardinalitas sisi probe dapat dilihat di operator Repartition Streams:
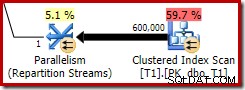
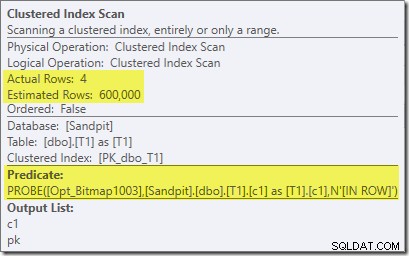
Perhatikan bahwa efek kardinalitas terlihat pada pertukaran, meskipun bitmap akhirnya didorong sepenuhnya ke dalam mesin penyimpanan ('INROW') seperti yang kita lihat pada pengujian pertama (tetapi perhatikan referensi Opt_Bitmap sekarang):
Rencana pasca-eksekusi ('aktual') adalah sebagai berikut:
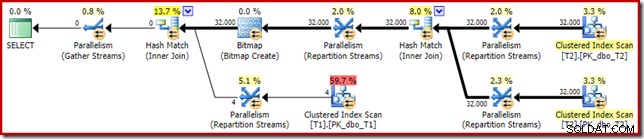
Keefektifan yang diprediksi dari bitmap yang dioptimalkan berarti penulisan ulang pasca-pengoptimalan yang terpisah untuk Filter nol tidak diterapkan. Secara pribadi, saya pikir ini sangat disayangkan karena menghilangkan nol lebih awal dengan Filter akan meniadakan kebutuhan untuk membangun bitmap, mengisi tabel hash, dan melakukan pemindaian tabel T1 yang ditingkatkan bitmap. Namun demikian, pengoptimal memutuskan sebaliknya dan tidak ada perdebatan dengannya dalam hal ini.
Meskipun self-join ekstra dari tabel T2, dan pekerjaan ekstra yang terkait dengan Filter yang hilang, rencana eksekusi ini masih menghasilkan hasil yang diharapkan (tidak ada baris) dalam waktu cepat. Eksekusi biasa di laptop saya membutuhkan waktu sekitar 200 md .
Mengubah tipe data
Untuk pengujian ketiga ini, kita akan mengubah tipe data kolom c1 pada kedua tabel dari integer menjadi desimal. Tidak ada yang istimewa dari pilihan ini; efek yang sama dapat dilihat dengan tipe numerik apa pun yang bukan integer atau bigint.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
Menggunakan kembali kueri bergabung tiga-gabung:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
Perkiraan rencana eksekusi terlihat sangat familiar:
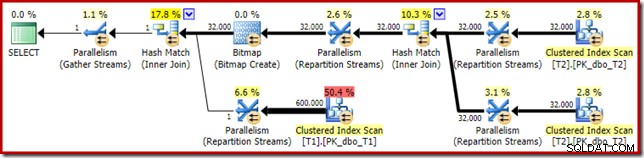
Selain fakta bahwa bitmap yang dioptimalkan tidak dapat lagi diterapkan 'INROW' oleh mesin penyimpanan karena perubahan tipe data, rencana eksekusi pada dasarnya identik. Tangkapan di bawah ini menunjukkan perubahan properti pemindaian:
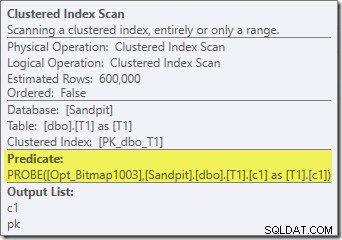
Sayangnya, kinerja agak terpengaruh secara dramatis. Kueri ini tidak dijalankan dalam 70 md atau 200 md, tetapi dalam waktu sekitar 20 menit . Dalam pengujian yang menghasilkan rencana pasca-eksekusi berikut, runtime sebenarnya adalah 22 menit 29 detik:

Perbedaan yang paling jelas adalah bahwa Clustered Index Scan pada tabel T1 mengembalikan 300.000 baris bahkan setelah filter bitmap yang dioptimalkan diterapkan. Ini masuk akal, karena bitmap dibangun di atas baris yang hanya berisi nol di kolom c1. Bitmap menghapus baris non-null dari pemindaian T1, hanya menyisakan 300.000 baris dengan nilai nol untuk c1. Ingat, setengah baris di T1 adalah nol.
Meski begitu, rasanya aneh bahwa menggabungkan 32.000 baris dengan 300.000 baris membutuhkan waktu lebih dari 20 menit. Jika Anda bertanya-tanya, satu inti CPU dipatok pada 100% untuk seluruh eksekusi. Penjelasan untuk kinerja yang buruk dan penggunaan sumber daya yang ekstrem ini didasarkan pada beberapa ide yang telah kami jelajahi sebelumnya:
Kita sudah tahu, misalnya, bahwa meskipun ikon eksekusi paralel, semua baris dari T2 berakhir di utas yang sama. Sebagai pengingat, gabungan hash paralel mode baris memerlukan partisi ulang pada kolom gabungan (c1). Semua baris dari T2 memiliki nilai yang sama – nol – di kolom c1, jadi semua baris berakhir di utas yang sama. Demikian pula, semua baris dari T1 yang lolos dari filter bitmap juga memiliki null di kolom c1, jadi baris tersebut juga dipartisi ulang ke utas yang sama. Ini menjelaskan mengapa satu inti melakukan semua pekerjaan.
Tampaknya masih tidak masuk akal bahwa hash yang menggabungkan 32.000 baris dengan 300.000 baris harus memakan waktu 20 menit, terutama karena kolom gabungan di kedua sisi adalah nol, dan tetap tidak akan bergabung. Untuk memahami ini, kita perlu memikirkan cara kerja hash join ini.
Input build (32.000 baris) membuat tabel hash menggunakan kolom gabungan, c1. Karena setiap baris sisi build berisi nilai yang sama (null) untuk bergabung dengan kolom c1, ini berarti semua 32.000 baris berakhir di keranjang hash yang sama. Ketika hash join beralih ke probing untuk kecocokan, setiap baris sisi probe dengan kolom c1 nol juga di-hash ke bucket yang sama. Gabungan hash kemudian harus memeriksa semua 32.000 entri dalam ember itu untuk kecocokan.
Memeriksa 300.000 baris probe menghasilkan 32.000 perbandingan yang dibuat 300.000 kali. Ini adalah kasus terburuk untuk hash join:Semua build side rows hash ke bucket yang sama, menghasilkan apa yang pada dasarnya adalah produk Cartesian. Ini menjelaskan waktu eksekusi yang lama dan penggunaan prosesor 100% yang konstan karena hash mengikuti rantai bucket hash yang panjang.
Performa yang buruk ini membantu menjelaskan mengapa penulisan ulang pasca-optimasi untuk menghilangkan null pada input build ke hash join ada. Sayangnya Filter tidak diterapkan dalam kasus ini.
Solusi
Pengoptimal memilih bentuk rencana ini karena salah memperkirakan bahwa bitmap yang dioptimalkan akan menyaring semua baris dari tabel T1. Meskipun perkiraan ini ditampilkan di Aliran Repartisi alih-alih Pemindaian Indeks Clustered, ini masih menjadi dasar keputusan. Sebagai pengingat di sini adalah bagian yang relevan dari rencana pra-eksekusi lagi:
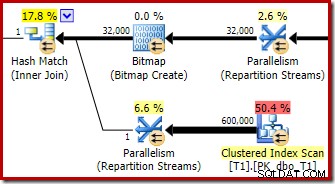
Jika ini adalah perkiraan yang benar, tidak akan memakan waktu sama sekali untuk memproses hash join. Sangat disayangkan bahwa estimasi selektivitas untuk bitmap yang dioptimalkan sangat salah ketika tipe datanya bukan integer atau bigint sederhana. Tampaknya bitmap yang dibangun di atas kunci integer atau bigint juga dapat memfilter baris nol yang tidak dapat bergabung. Jika memang demikian, ini adalah alasan utama untuk memilih kolom gabungan integer atau bigint.
Solusi berikut sebagian besar didasarkan pada gagasan untuk menghilangkan bitmap yang dioptimalkan dan bermasalah.
Eksekusi Serial
Salah satu cara untuk mencegah bitmap yang dioptimalkan dipertimbangkan adalah dengan memerlukan rencana non-paralel. Operator Bitmap mode baris (dioptimalkan atau sebaliknya) hanya terlihat dalam paket paralel:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); Kueri tersebut diekspresikan menggunakan sintaks yang sedikit berbeda dengan petunjuk FORCE ORDER untuk menghasilkan bentuk denah yang lebih mudah dibandingkan dengan denah paralel sebelumnya. Fitur penting adalah petunjuk MAXDOP 1.
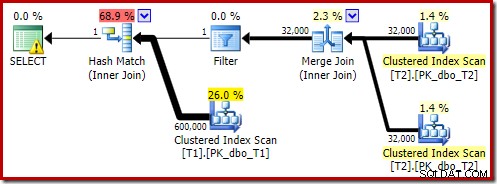
Perkiraan rencana tersebut menunjukkan Filter penulisan ulang pasca-pengoptimalan diaktifkan kembali:
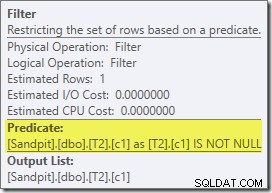
Versi rencana pasca-eksekusi menunjukkan bahwa ia memfilter semua baris dari input build, yang berarti pemindaian sisi probe dapat dilewati sama sekali:
Seperti yang Anda harapkan, versi kueri ini dijalankan dengan sangat cepat – rata-rata sekitar 20 md untuk saya. Kami dapat mencapai efek serupa tanpa petunjuk FORCE ORDER dan penulisan ulang kueri:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
Pengoptimal memilih bentuk rencana yang berbeda dalam kasus ini, dengan Filter ditempatkan langsung di atas pemindaian T2:
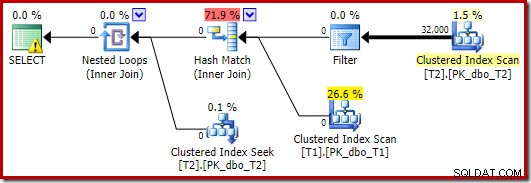
Ini dieksekusi lebih cepat – dalam waktu sekitar 10 ms – seperti yang diharapkan. Tentu, ini bukan pilihan yang baik jika jumlah baris yang ada (dan dapat digabungkan) jauh lebih besar.
Menonaktifkan Bitmap yang Dioptimalkan
Tidak ada petunjuk kueri untuk mematikan bitmap yang dioptimalkan, tetapi kita dapat mencapai efek yang sama menggunakan beberapa tanda jejak yang tidak terdokumentasi. Seperti biasa, ini hanya untuk nilai bunga; Anda tidak ingin menggunakan ini dalam sistem atau aplikasi nyata:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);
Rencana eksekusi yang dihasilkan adalah:
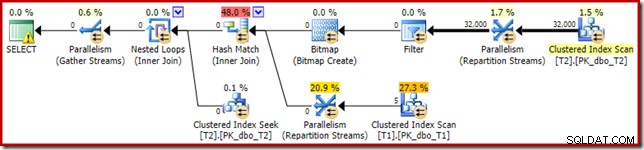
Bitmap ada bitmap penulisan ulang pasca-optimasi, bukan bitmap yang dioptimalkan:
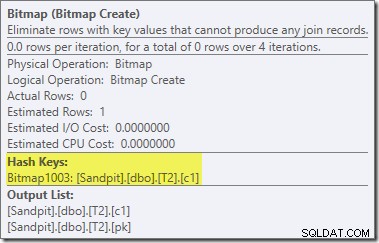
Perhatikan perkiraan biaya nol dan nama Bitmap (bukan Opt_Bitmap). tanpa bitmap yang dioptimalkan untuk mengubah perkiraan biaya, penulisan ulang pasca-optimasi untuk menyertakan Filter penolak nol diaktifkan. Rencana eksekusi ini berjalan dalam waktu sekitar 70 md .
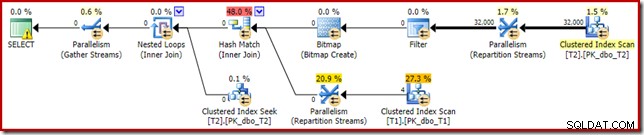
Rencana eksekusi yang sama (dengan Filter dan Bitmap yang tidak dioptimalkan) juga dapat dibuat dengan menonaktifkan aturan pengoptimal yang bertanggung jawab untuk menghasilkan rencana bitmap gabungan bintang (sekali lagi, tidak didokumentasikan secara ketat dan bukan untuk penggunaan di dunia nyata):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
Termasuk filter eksplisit
Ini adalah pilihan paling sederhana, tetapi orang hanya akan berpikir untuk melakukannya jika mengetahui masalah yang dibahas sejauh ini. Sekarang kita tahu bahwa kita perlu menghilangkan null dari T2.c1, kita dapat menambahkan ini ke kueri secara langsung:
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
T2.c1 IS NOT NULL; -- New! Perkiraan rencana eksekusi yang dihasilkan mungkin tidak seperti yang Anda harapkan:
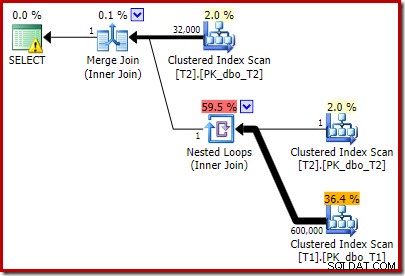
Predikat ekstra yang kami tambahkan telah didorong ke tengah Clustered Index Scan dari T2:
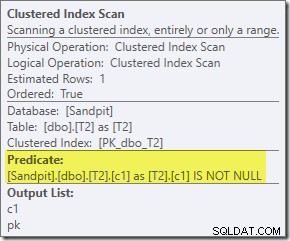
Rencana pasca-eksekusi adalah:
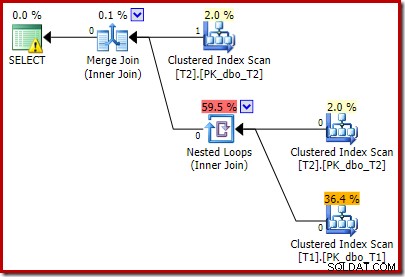
Perhatikan bahwa Merge Join dimatikan setelah membaca satu baris dari input teratasnya, kemudian gagal menemukan baris pada input yang lebih rendah, karena efek dari predikat yang kami tambahkan. Pemindaian Indeks Clustered dari tabel T1 tidak pernah dieksekusi sama sekali, karena gabungan Nested Loops tidak pernah mendapat baris pada input penggeraknya. Formulir kueri terakhir ini dieksekusi dalam satu atau dua milidetik.
Pemikiran terakhir
Artikel ini telah membahas cukup banyak dasar untuk mengeksplorasi beberapa perilaku pengoptimal kueri yang kurang terkenal, dan menjelaskan alasan kinerja hash join yang sangat buruk dalam kasus tertentu.
Mungkin tergoda untuk bertanya mengapa pengoptimal tidak secara rutin menambahkan filter penolakan nol sebelum kesetaraan bergabung. Orang hanya bisa mengira bahwa ini tidak akan bermanfaat dalam kasus-kasus umum yang cukup. Sebagian besar gabungan tidak diharapkan untuk menghadapi banyak penolakan null =null, dan penambahan predikat secara rutin dapat dengan cepat menjadi kontra-produktif, terutama jika ada banyak kolom gabungan. Untuk sebagian besar gabungan, menolak null di dalam operator gabungan mungkin merupakan opsi yang lebih baik (dari perspektif model biaya) daripada memperkenalkan Filter eksplisit.
Tampaknya ada upaya untuk mencegah kasus terburuk bermanifestasi melalui penulisan ulang pasca-optimasi yang dirancang untuk menolak baris gabungan nol sebelum mencapai input build dari hash join. Tampaknya ada interaksi yang tidak menguntungkan antara efek filter bitmap yang dioptimalkan dan penerapan penulisan ulang ini. Sangat disayangkan juga bahwa ketika masalah kinerja ini benar-benar terjadi, sangat sulit untuk mendiagnosis dari rencana eksekusi saja.
Untuk saat ini, opsi terbaik tampaknya menyadari potensi masalah kinerja ini dengan gabungan hash pada kolom yang dapat dibatalkan, dan untuk menambahkan predikat penolakan nol eksplisit (dengan komentar!) untuk memastikan rencana eksekusi yang efisien dihasilkan, jika perlu. Menggunakan petunjuk MAXDOP 1 juga dapat mengungkapkan rencana alternatif dengan Filter yang memberi tahu.
Sebagai aturan umum, kueri yang bergabung pada kolom tipe integer dan mencari data yang ada cenderung lebih cocok dengan model pengoptimal dan kemampuan mesin eksekusi daripada alternatifnya.
Penghargaan
Saya ingin berterima kasih kepada SQL_Sasquatch (@sqL_handLe) atas izinnya untuk menanggapi artikel aslinya dengan analisis teknis. Data sampel yang digunakan di sini sangat didasarkan pada artikel tersebut.
Saya juga ingin berterima kasih kepada Rob Farley (blog | twitter) untuk diskusi teknis kami selama bertahun-tahun, dan terutama pada Januari 2015 di mana kami mendiskusikan implikasi dari predikat penolakan nol ekstra untuk equi-join. Rob telah menulis tentang topik terkait beberapa kali, termasuk di Predikat Terbalik – lihat dua arah sebelum Anda menyeberang.