Ada beberapa metode untuk melihat kueri berkinerja buruk di SQL Server, terutama Query Store, Extended Events, dan dynamic management views (DMVs). Setiap opsi memiliki pro dan kontra. Peristiwa yang Diperpanjang menyediakan data tentang eksekusi kueri individual, sementara Penyimpanan Kueri dan data kinerja agregat DMV. Untuk menggunakan Penyimpanan Kueri dan Peristiwa yang Diperpanjang, Anda harus mengonfigurasinya terlebih dahulu – baik mengaktifkan Penyimpanan Kueri untuk database Anda, atau menyiapkan sesi XE dan memulainya. Data DMV selalu tersedia, jadi sering kali ini adalah metode termudah untuk melihat performa kueri dengan cepat. Di sinilah kueri DMV Glenn berguna – dalam skripnya ia memiliki beberapa kueri yang dapat Anda gunakan untuk menemukan kueri teratas untuk instans berdasarkan CPU, I/O logis, dan durasi. Menargetkan kueri yang menghabiskan banyak sumber daya sering kali merupakan awal yang baik saat pemecahan masalah, tetapi kita tidak dapat melupakan skenario "mati dengan seribu luka" – kueri atau kumpulan kueri yang SANGAT sering dijalankan – mungkin ratusan atau ribuan kali dalam setahun. menit. Glenn memiliki kueri dalam kumpulannya yang mencantumkan kueri teratas untuk database berdasarkan jumlah eksekusi, tetapi menurut pengalaman saya, kueri tersebut tidak memberikan gambaran lengkap tentang beban kerja Anda.
DMV utama yang digunakan untuk melihat metrik kinerja kueri adalah sys.dm_exec_query_stats. Data tambahan khusus untuk prosedur tersimpan (sys.dm_exec_procedure_stats), fungsi (sys.dm_exec_function_stats), dan pemicu (sys.dm_exec_trigger_stats) juga tersedia, tetapi pertimbangkan beban kerja yang bukan murni prosedur, fungsi, dan pemicu yang disimpan. Pertimbangkan beban kerja campuran yang memiliki beberapa kueri ad hoc, atau mungkin seluruhnya ad hoc.
Contoh Skenario
Meminjam dan mengadaptasi kode dari posting sebelumnya, Meneliti Dampak Kinerja dari Beban Kerja Adhoc, pertama-tama kita akan membuat dua prosedur tersimpan. Yang pertama, dbo.RandomSelects, menghasilkan dan mengeksekusi pernyataan ad hoc, dan yang kedua, dbo.SPRandomSelects, menghasilkan dan mengeksekusi kueri berparameter.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Sekarang kita akan menjalankan kedua prosedur tersimpan 1000 kali, menggunakan metode yang sama yang diuraikan dalam posting saya sebelumnya dengan file .cmd memanggil file .sql dengan pernyataan berikut:
Isi file Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Isi file parameterized.sql:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Contoh sintaks dalam file .cmd yang memanggil file .sql:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Jika kami menggunakan variasi kueri Waktu Pekerja Teratas Glenn untuk melihat kueri teratas berdasarkan waktu pekerja (CPU):
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
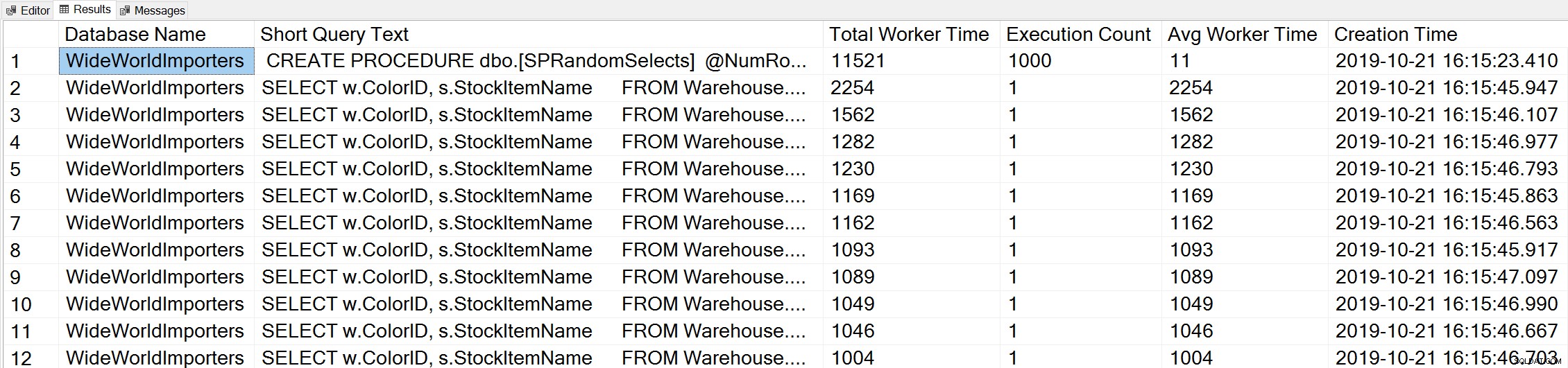
Kami melihat pernyataan dari prosedur tersimpan kami sebagai kueri yang dijalankan dengan jumlah CPU kumulatif tertinggi.
Jika kami menjalankan variasi kueri Jumlah Eksekusi Kueri Glenn terhadap database WideWorldImporters:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
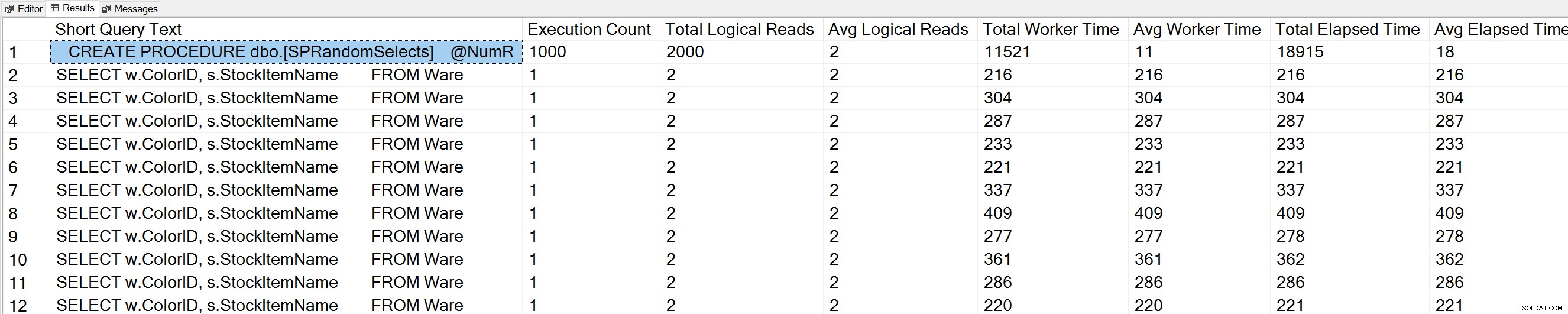
Kami juga melihat pernyataan prosedur tersimpan kami di bagian atas daftar.
Tetapi kueri ad hoc yang kami jalankan, meskipun memiliki nilai literal yang berbeda, pada dasarnya sama pernyataan dieksekusi berulang kali, seperti yang dapat kita lihat dengan melihat query_hash:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
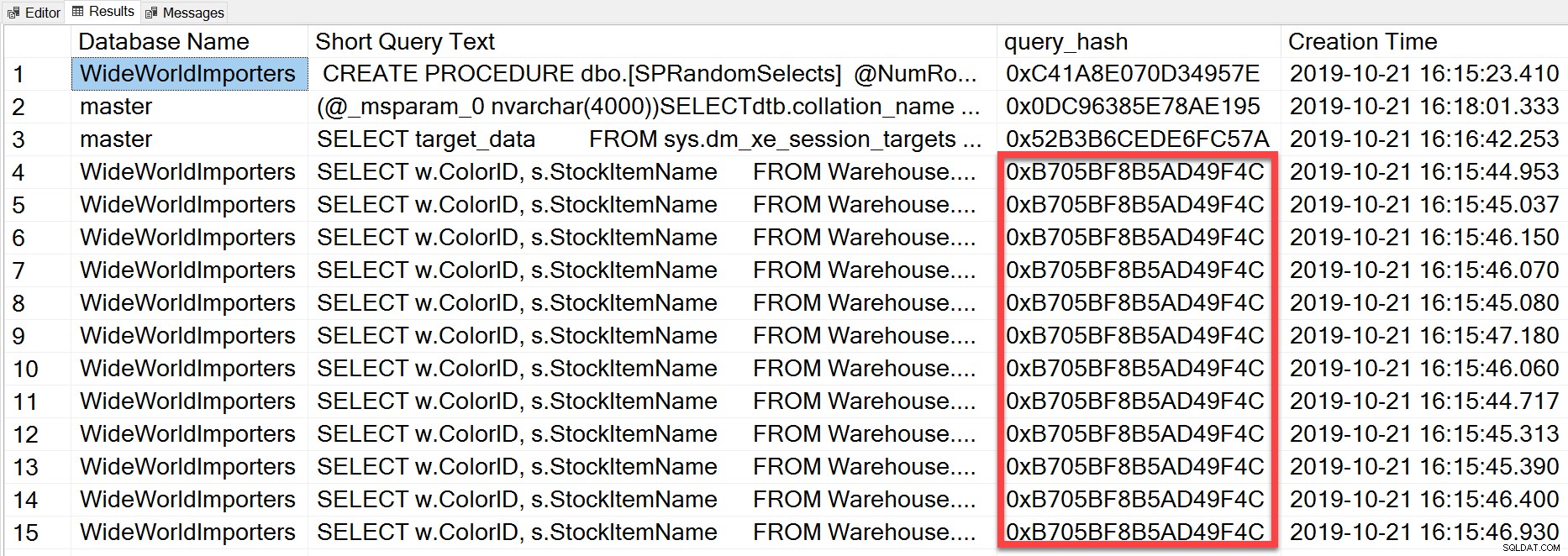
Query_hash telah ditambahkan di SQL Server 2008, dan didasarkan pada pohon operator logika yang dihasilkan oleh Pengoptimal Kueri untuk teks pernyataan. Kueri yang memiliki teks pernyataan serupa yang menghasilkan pohon operator logika yang sama akan memiliki query_hash yang sama, meskipun nilai literal dalam predikat kueri berbeda. Meskipun nilai literalnya bisa berbeda, objek dan aliasnya harus sama, serta petunjuk kueri dan kemungkinan opsi SET. Prosedur tersimpan RandomSelects menghasilkan kueri dengan nilai literal yang berbeda:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Tetapi setiap eksekusi memiliki nilai yang sama persis untuk query_hash, 0xB705BF8B5AD49F4C. Untuk memahami seberapa sering kueri ad hoc – dan kueri yang sama dalam hal query_hash – dieksekusi, kita harus mengelompokkan menurut urutan query_hash pada hitungan itu, daripada melihat execution_count di sys.dm_exec_query_stats (yang sering menunjukkan nilai 1).
Jika kita mengubah konteks ke database WideWorldImporters dan mencari kueri teratas berdasarkan jumlah eksekusi, tempat kita mengelompokkan pada query_hash, sekarang kita dapat melihat prosedur tersimpan dan permintaan ad hoc kami:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

Catatan:DMV sys.dm_exec_function_stats telah ditambahkan di SQL Server 2016. Menjalankan kueri ini di SQL Server 2014 dan sebelumnya memerlukan penghapusan referensi ke DMV ini.
Output ini memberikan pemahaman yang jauh lebih komprehensif tentang kueri apa yang paling sering dieksekusi, karena dikumpulkan berdasarkan query_hash, bukan hanya dengan melihat execution_count di sys.dm_exec_query_stats, yang dapat memiliki banyak entri untuk query_hash yang sama ketika nilai literal yang berbeda digunakan. Keluaran kueri juga menyertakan query_plan_hash, yang dapat berbeda untuk kueri dengan query_hash yang sama. Informasi tambahan ini berguna saat mengevaluasi kinerja rencana untuk kueri. Dalam contoh di atas, setiap kueri memiliki query_plan_hash yang sama, 0x299275DD475C4B17, yang menunjukkan bahwa meskipun dengan nilai input yang berbeda, Pengoptimal Kueri menghasilkan paket yang sama – stabil. Ketika beberapa nilai query_plan_hash ada untuk query_hash yang sama, variabilitas paket ada. Dalam skenario di mana kueri yang sama, berdasarkan query_hash, dieksekusi ribuan kali, rekomendasi umum adalah membuat parameter kueri. Jika Anda dapat memverifikasi bahwa tidak ada variabilitas paket, maka membuat parameter kueri menghapus waktu pengoptimalan dan kompilasi untuk setiap eksekusi, dan dapat mengurangi keseluruhan CPU. Dalam beberapa skenario, membuat parameter lima hingga 10 kueri ad hoc dapat meningkatkan kinerja sistem secara keseluruhan.
Ringkasan
Untuk lingkungan apa pun, penting untuk memahami kueri apa yang paling mahal dalam hal penggunaan sumber daya, dan kueri apa yang paling sering dijalankan. Kumpulan kueri yang sama dapat muncul untuk kedua jenis analisis saat menggunakan skrip DMV Glenn, yang dapat menyesatkan. Karena itu, penting untuk menentukan apakah beban kerja sebagian besar bersifat prosedural, sebagian besar ad hoc, atau campuran. Meskipun ada banyak didokumentasikan tentang manfaat prosedur tersimpan, saya menemukan bahwa beban kerja campuran atau sangat ad hoc sangat umum, terutama dengan solusi yang menggunakan pemetaan objek-relasional (ORM) seperti Entity Framework, NHibernate, dan LINQ ke SQL. Jika Anda tidak jelas tentang jenis beban kerja untuk server, menjalankan kueri di atas untuk melihat kueri yang paling banyak dijalankan berdasarkan query_hash adalah awal yang baik. Saat Anda mulai memahami beban kerja dan apa yang ada untuk kueri pemukul berat dan kematian karena seribu pemotongan, Anda dapat beralih ke pemahaman yang benar-benar tentang penggunaan sumber daya dan dampak kueri ini terhadap kinerja sistem, dan menargetkan upaya Anda untuk penyetelan.



