Diposting oleh Dan Holmes, yang menulis blog di sql.dnhlms.com.
SQL Server Books Online (BOL), whitepaper, dan banyak sumber lainnya akan menunjukkan kepada Anda bagaimana dan mengapa Anda mungkin ingin memperbarui statistik pada tabel atau indeks. Namun, Anda hanya mendapatkan satu cara untuk membentuk nilai-nilai tersebut. Saya akan menunjukkan kepada Anda bagaimana Anda dapat membuat statistik persis seperti yang Anda inginkan dalam batas 200 langkah yang tersedia.
Penafian :Ini berfungsi untuk saya karena saya tahu aplikasi saya, database saya, dan alur kerja reguler pengguna saya dan pola penggunaan aplikasi. Namun, ia menggunakan perintah yang tidak terdokumentasi dan, jika digunakan secara tidak benar, dapat membuat aplikasi Anda berkinerja lebih buruk secara signifikan.Dalam aplikasi kami, pengguna Penjadwalan secara teratur membaca dan menulis data yang mewakili acara untuk besok dan beberapa hari ke depan. Data untuk hari ini dan sebelumnya tidak digunakan oleh Penjadwal. Hal pertama di pagi hari, kumpulan data untuk besok dimulai dari beberapa ratus baris dan pada tengah hari bisa menjadi 1400 dan lebih tinggi. Bagan berikut akan menggambarkan jumlah baris. Data ini dikumpulkan pada pagi hari Rabu 18 November 2015. Secara historis, Anda dapat melihat bahwa jumlah baris reguler sekitar 1.400 kecuali untuk hari akhir pekan dan hari berikutnya.
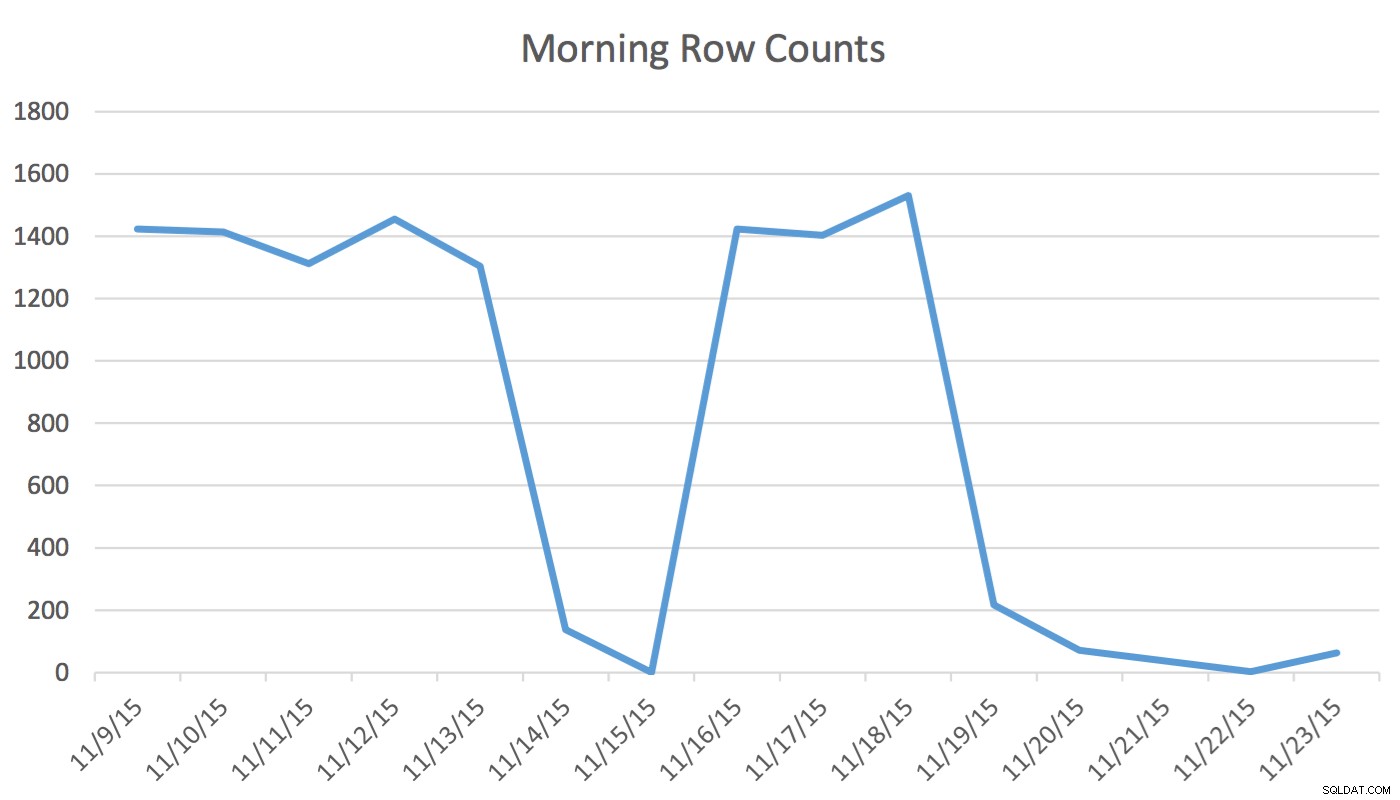
Untuk Penjadwal, satu-satunya data terkait adalah beberapa hari ke depan. Apa yang terjadi hari ini dan yang terjadi kemarin tidak relevan dengan aktivitasnya. Jadi bagaimana ini menyebabkan masalah? Tabel ini memiliki 2.259.205 baris yang berarti perubahan jumlah baris dari pagi hingga siang tidak akan cukup untuk memicu pembaruan statistik yang dimulai SQL Server. Selanjutnya, pekerjaan yang dijadwalkan secara manual yang membuat statistik menggunakan UPDATE STATISTICS mengisi histogram dengan sampel semua data dalam tabel tetapi mungkin tidak menyertakan informasi yang relevan. Delta jumlah baris ini cukup untuk mengubah rencana. Namun, tanpa pembaruan statistik dan histogram yang akurat, rencana tidak akan berubah menjadi lebih baik seiring perubahan data.
Pilihan histogram yang relevan untuk tabel ini dari cadangan tertanggal 4/11/2015 mungkin terlihat seperti ini:
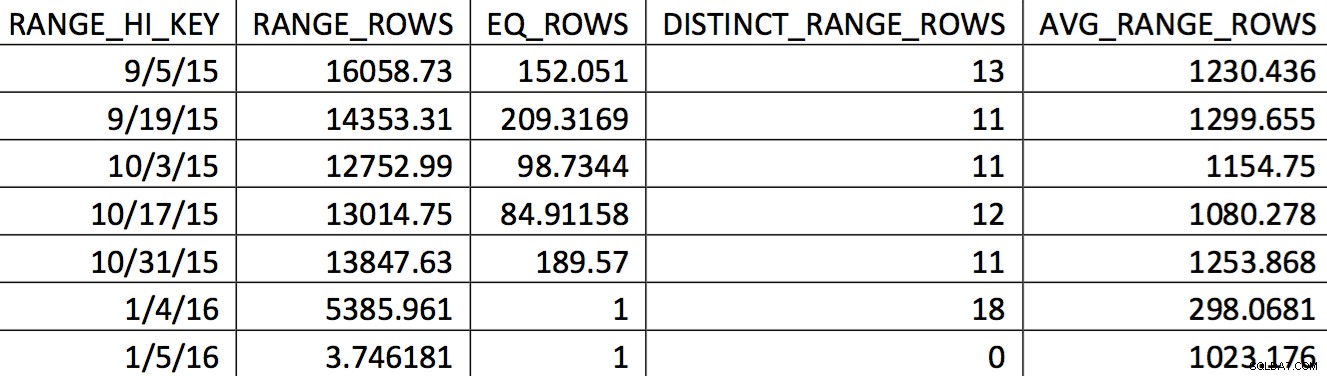
Nilai-nilai yang menarik tidak tercermin secara akurat dalam histogram. Apa yang akan digunakan untuk tanggal 11/5/2015 adalah nilai tinggi 1/4/2016. Berdasarkan grafik, histogram ini jelas bukan sumber informasi yang baik untuk pengoptimal untuk tanggal yang diinginkan. Memaksakan nilai penggunaan ke dalam histogram tidak dapat diandalkan, jadi bagaimana Anda bisa melakukannya? Upaya pertama saya adalah berulang kali menggunakan WITH SAMPLE pilihan UPDATE STATISTICS dan kueri histogram hingga nilai yang saya butuhkan ada di histogram (upaya dirinci di sini). Pada akhirnya, pendekatan itu terbukti tidak dapat diandalkan.
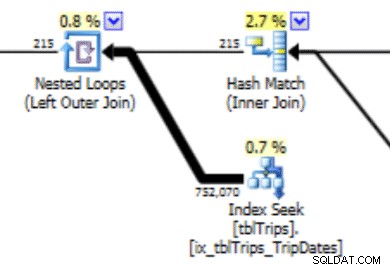
Histogram ini dapat mengarah pada rencana dengan jenis perilaku ini. Meremehkan baris menghasilkan gabungan Nested Loop dan pencarian indeks. Pembacaan selanjutnya lebih tinggi dari yang seharusnya karena pilihan paket ini. Ini juga akan berpengaruh pada durasi pernyataan.
Cara yang lebih baik adalah membuat data persis seperti yang Anda inginkan, dan berikut cara melakukannya.
Ada opsi UPDATE STATISTICS yang tidak didukung :STATS_STREAM . Ini digunakan oleh Dukungan Pelanggan Microsoft untuk mengekspor dan mengimpor statistik sehingga mereka bisa mendapatkan pengoptimalan yang dibuat ulang tanpa memiliki semua data dalam tabel. Kita bisa menggunakan fitur itu. Idenya adalah untuk membuat tabel yang meniru DDL dari statistik yang ingin kita sesuaikan. Data yang relevan ditambahkan ke tabel. Statistik diekspor dan diimpor ke tabel asli.
Dalam hal ini, ini adalah tabel dengan 200 baris tanggal bukan NULL dan 1 baris yang menyertakan nilai NULL. Selain itu, ada indeks pada tabel tersebut yang cocok dengan indeks yang memiliki nilai histogram yang buruk.
Nama tabelnya adalah tblTripsScheduled . Ini memiliki indeks non-cluster pada (id, TheTripDate) dan indeks berkerumun di TheTripDate . Ada beberapa kolom lain, tetapi hanya kolom yang terlibat dalam indeks yang penting.
Buat tabel (tabel temp jika Anda mau) yang meniru tabel dan index. Tabel dan indeks terlihat seperti ini:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate);
Selanjutnya, tabel perlu diisi dengan 200 baris data yang menjadi dasar statistik. Untuk situasi saya, ini adalah hari melalui enam puluh hari ke depan. 60 hari yang lalu dan setelah 60 hari diisi dengan pilihan "acak" setiap 10 hari. (cnt nilai dalam CTE adalah nilai debug. Itu tidak berperan dalam hasil akhir.) Urutan menurun untuk rn kolom memastikan bahwa 60 hari disertakan, dan kemudian sebanyak mungkin dari masa lalu.
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
Tabel kami sekarang diisi dengan setiap baris yang berharga bagi pengguna saat ini dan pilihan baris historis. Jika kolom TheTripdate tidak dapat dibatalkan, sisipan juga akan menyertakan yang berikut:
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
Selanjutnya, kami memperbarui statistik pada indeks tabel sementara kami.
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
Sekarang, ekspor statistik tersebut ke tabel sementara. Meja itu terlihat seperti ini. Ini cocok dengan output DBCC SHOW_STATISTICS WITH HISTOGRAM .
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS memiliki opsi untuk mengekspor statistik sebagai aliran. Aliran itulah yang kita inginkan. Aliran itu juga aliran yang sama dengan UPDATE STATISTICS penggunaan opsi aliran. Untuk melakukannya:
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); Langkah terakhir adalah membuat SQL yang memperbarui statistik tabel target kita, lalu menjalankannya.
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); Pada titik ini, kami telah mengganti histogram dengan yang dibuat khusus. Anda dapat memverifikasi dengan memeriksa histogram:
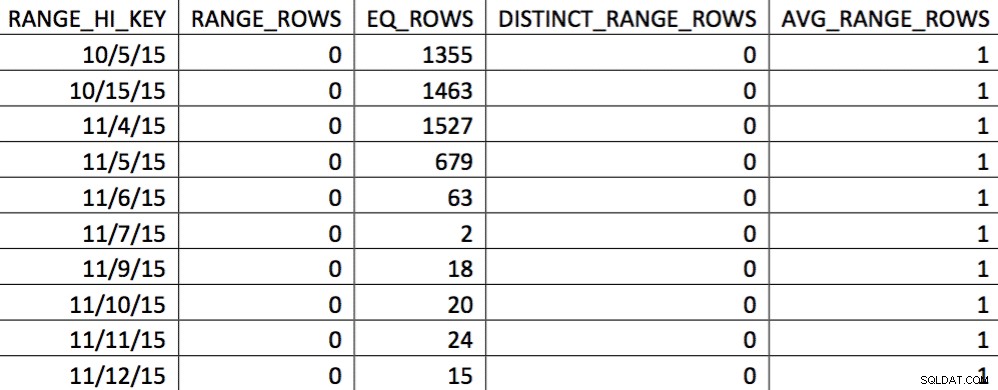
Dalam pemilihan data tanggal 11/4 ini, semua hari dari tanggal 11/4 dan seterusnya terwakili, dan data historis terwakili dan akurat. Meninjau kembali bagian dari rencana kueri yang ditampilkan sebelumnya, Anda dapat melihat pengoptimal membuat pilihan yang lebih baik berdasarkan statistik yang dikoreksi:
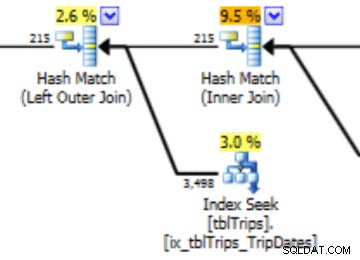
Ada manfaat kinerja untuk statistik yang diimpor. Biaya untuk menghitung statistik ada di tabel "offline". Satu-satunya waktu henti untuk tabel produksi adalah durasi impor aliran.
Proses ini memang menggunakan fitur yang tidak terdokumentasi dan sepertinya bisa berbahaya, tetapi ingat ada cara mudah untuk membatalkannya:pernyataan statistik pembaruan. Jika terjadi kesalahan, statistik selalu dapat diperbarui menggunakan T-SQL standar.
Menjadwalkan kode ini untuk berjalan secara teratur dapat sangat membantu pengoptimal menghasilkan rencana yang lebih baik mengingat kumpulan data yang berubah pada titik kritis tetapi tidak cukup untuk memicu pembaruan statistik.
Ketika saya menyelesaikan draf pertama artikel ini, jumlah baris pada tabel di grafik pertama berubah dari 217 menjadi 717. Itu adalah perubahan 300%. Itu cukup untuk mengubah perilaku pengoptimal tetapi tidak cukup untuk memicu pembaruan statistik. Perubahan data ini akan meninggalkan rencana yang buruk. Dengan proses yang dijelaskan di sini, masalah ini terpecahkan.
Referensi:
- Statistik PEMBARUAN (Buku Daring)
- Buku Putih Statistik SQL 2008
- Penelusuran Titik Tipis