Replikasi adalah salah satu cara paling umum untuk mencapai ketersediaan tinggi untuk MySQL dan MariaDB. Ini menjadi jauh lebih kuat dengan penambahan GTID, dan diuji secara menyeluruh oleh ribuan dan ribuan pengguna. Replikasi MySQL bukanlah properti 'atur dan lupakan', itu perlu dipantau untuk potensi masalah dan dipelihara agar tetap dalam kondisi yang baik. Dalam postingan blog ini, kami ingin berbagi beberapa tips dan trik tentang cara memelihara, memecahkan masalah, dan memperbaiki masalah replikasi MySQL.
Bagaimana Cara Menentukan apakah Replikasi MySQL dalam Bentuk yang Baik?
Ini adalah keterampilan paling penting yang harus dimiliki oleh siapa pun yang mengurus pengaturan replikasi MySQL. Mari kita lihat di mana mencari informasi tentang status replikasi. Ada sedikit perbedaan antara MySQL dan MariaDB dan kami akan membahasnya juga.
TAMPILKAN STATUS BUDAK
Ini adalah metode paling umum untuk memeriksa status replikasi pada host slave - ini selalu bersama kami dan biasanya ini adalah tempat pertama yang kami tuju jika kami memperkirakan ada masalah dengan replikasi.
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.101
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 767658564
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 767658564
Relay_Log_Space: 606
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-394233
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Beberapa detail mungkin berbeda antara MySQL dan MariaDB tetapi sebagian besar konten akan terlihat sama. Perubahan akan terlihat di bagian GTID karena MySQL dan MariaDB melakukannya dengan cara yang berbeda. Dari SHOW SLAVE STATUS, Anda dapat memperoleh beberapa informasi - master mana yang digunakan, pengguna mana dan port mana yang digunakan untuk terhubung ke master. Kami memiliki beberapa data tentang posisi log biner saat ini (tidak terlalu penting lagi karena kami dapat menggunakan GTID dan melupakan binlog) dan status utas replikasi SQL dan I/O. Kemudian Anda dapat melihat apakah dan bagaimana pemfilteran dikonfigurasi. Anda juga dapat menemukan beberapa informasi tentang kesalahan, jeda replikasi, pengaturan SSL, dan GTID. Contoh di atas berasal dari slave MySQL 5.7 yang dalam keadaan sehat. Mari kita lihat beberapa contoh di mana replikasi rusak.
MariaDB [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.104
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 636
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 765
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Skip_Counter: 0
Exec_Master_Log_Pos: 480
Relay_Log_Space: 1213
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-1-73243
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.00 sec)Contoh ini diambil dari MariaDB 10.1, Anda dapat melihat perubahan di bagian bawah output untuk membuatnya bekerja dengan MariaDB GTID. Yang penting bagi kami adalah kesalahannya - Anda dapat melihat ada yang tidak beres di utas SQL:
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609Kami akan membahas masalah khusus ini nanti, untuk saat ini cukup Anda melihat bagaimana Anda dapat memeriksa apakah ada kesalahan dalam replikasi menggunakan SHOW SLAVE STATUS.
Informasi penting lainnya yang berasal dari SHOW SLAVE STATUS adalah - seberapa parah kelambatan budak kita. Anda bisa mengeceknya di kolom “Seconds_Behind_Master”. Metrik ini sangat penting untuk dilacak jika Anda mengetahui bahwa aplikasi Anda sensitif dalam hal pembacaan yang basi.
Di ClusterControl Anda dapat melacak data ini di bagian "Ringkasan":
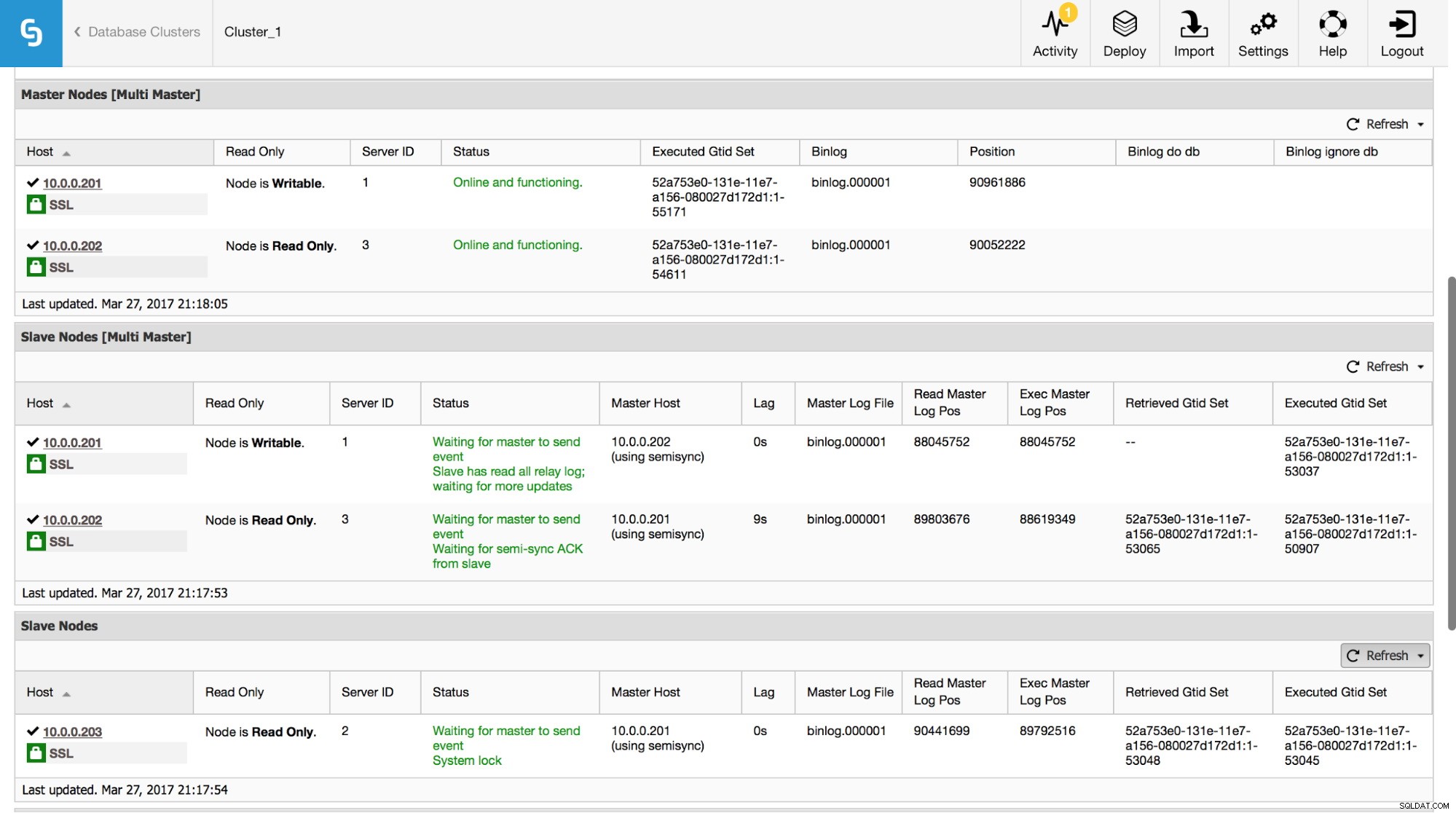
Kami menampilkan semua informasi terpenting dari perintah SHOW SLAVE STATUS. Anda dapat memeriksa status replikasi, siapa yang master, apakah ada lag replikasi atau tidak, posisi log biner. Anda juga dapat menemukan GTID yang diambil dan dijalankan.
Skema Kinerja
Tempat lain Anda dapat mencari informasi tentang replikasi adalah performance_schema. Ini hanya berlaku untuk MySQL 5.7 Oracle - versi sebelumnya dan MariaDB tidak mengumpulkan data ini.
mysql> SHOW TABLES FROM performance_schema LIKE 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)Di bawah ini Anda dapat menemukan beberapa contoh data yang tersedia di beberapa tabel tersebut.
mysql> select * from replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
THREAD_ID: 32
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 1
LAST_HEARTBEAT_TIMESTAMP: 2017-03-17 19:41:34
RECEIVED_TRANSACTION_SET: 5d1e2227-07c6-11e7-8123-080027495a77:715599-724966
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)mysql> select * from replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION: 5d1e2227-07c6-11e7-8123-080027495a77:726086
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)Seperti yang Anda lihat, kami dapat memverifikasi status replikasi, kesalahan terakhir, set transaksi yang diterima, dan beberapa data lainnya. Yang penting - jika Anda mengaktifkan replikasi multi-utas, di tabel replica_applier_status_by_worker, Anda akan melihat status setiap pekerja - ini membantu Anda memahami status replikasi untuk setiap rangkaian pekerja.
Keterlambatan Replikasi
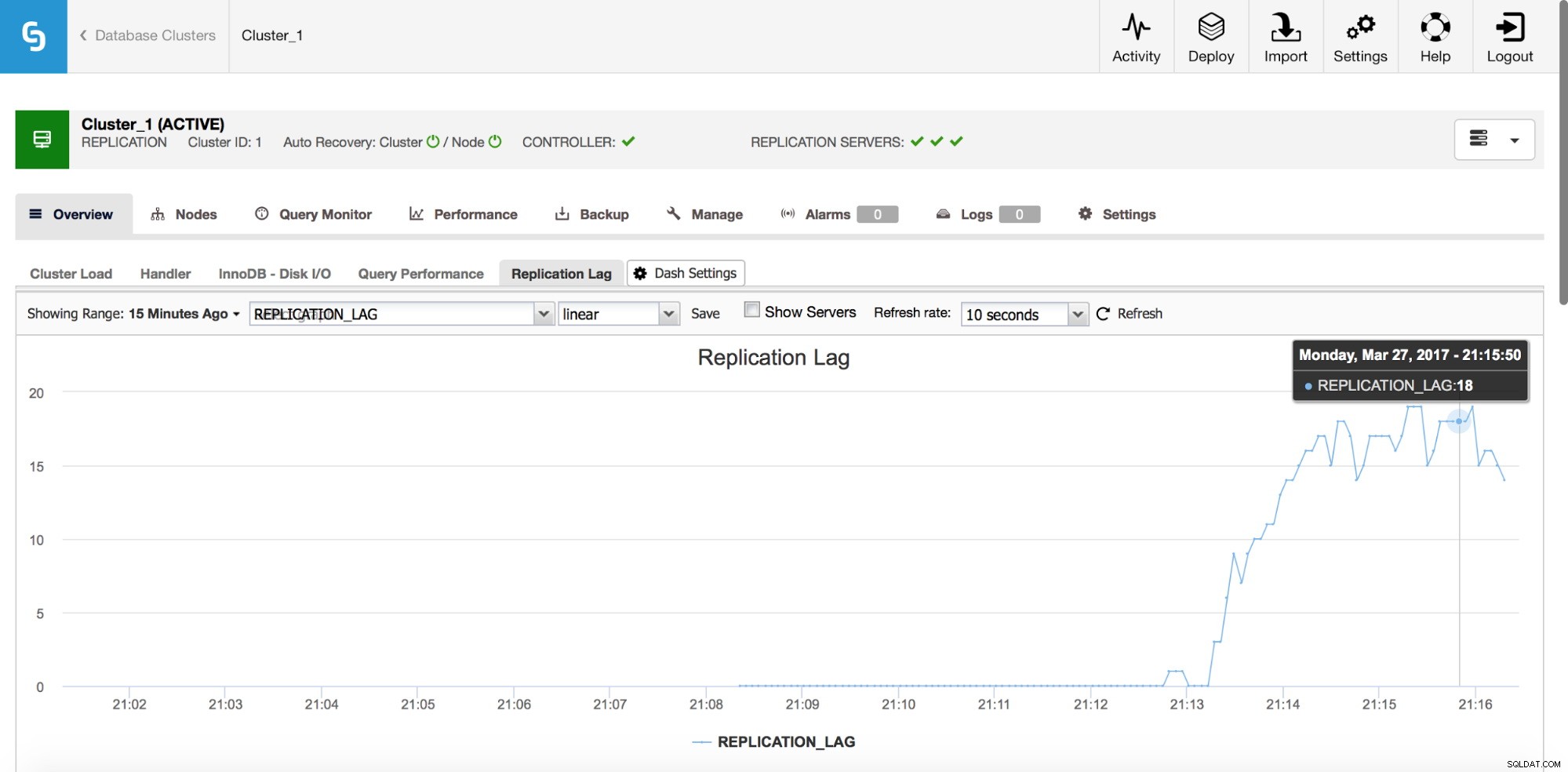
Lag jelas merupakan salah satu masalah paling umum yang akan Anda hadapi saat bekerja dengan replikasi MySQL. Replikasi lag muncul ketika salah satu budak tidak dapat mengikuti jumlah operasi tulis yang dilakukan oleh master. Alasannya bisa berbeda - konfigurasi perangkat keras yang berbeda, beban yang lebih berat pada slave, paralelisasi tulis tingkat tinggi pada master yang harus diserialisasi (ketika Anda menggunakan utas tunggal untuk replikasi) atau penulisan tidak dapat diparalelkan pada tingkat yang sama seperti sebelumnya berada di master (saat Anda menggunakan replikasi multi-utas).
Bagaimana Cara Mendeteksinya?
Ada beberapa metode untuk mendeteksi jeda replikasi. Pertama-tama, Anda dapat memeriksa "Seconds_Behind_Master" di output SHOW SLAVE STATUS - ini akan memberi tahu Anda apakah slave tertinggal atau tidak. Ini bekerja dengan baik di sebagian besar kasus tetapi dalam topologi yang lebih kompleks, ketika Anda menggunakan master perantara, pada host di suatu tempat rendah dalam rantai replikasi, itu mungkin tidak tepat. Solusi lain yang lebih baik adalah dengan mengandalkan alat eksternal seperti pt-heartbeat. Idenya sederhana - sebuah tabel dibuat dengan, antara lain, kolom stempel waktu. Kolom ini diperbarui pada master secara berkala. Pada slave, Anda kemudian dapat membandingkan stempel waktu dari kolom tersebut dengan waktu saat ini - ini akan memberi tahu Anda seberapa jauh di belakang slave.
Terlepas dari cara Anda menghitung lag, pastikan host Anda sinkron dari waktu ke waktu. Gunakan ntpd atau cara lain untuk menyinkronkan waktu - jika ada penyimpangan waktu, Anda akan melihat jeda "salah" pada slave Anda.
Bagaimana Mengurangi Lag?
Ini bukan pertanyaan yang mudah untuk dijawab. Singkatnya, itu tergantung pada apa yang menyebabkan kelambatan, dan apa yang menjadi hambatan. Ada dua pola khas - slave terikat I/O, yang berarti bahwa subsistem I/O-nya tidak dapat mengatasi jumlah operasi tulis dan baca. Kedua - slave terikat pada CPU, yang berarti bahwa utas replikasi menggunakan semua CPU yang dapat digunakan (satu utas hanya dapat menggunakan satu inti CPU) dan itu masih belum cukup untuk menangani semua operasi penulisan.
Ketika CPU mengalami hambatan, solusinya bisa sesederhana menggunakan replikasi multi-utas. Tingkatkan jumlah utas yang berfungsi untuk memungkinkan paralelisasi yang lebih tinggi. Itu tidak selalu mungkin - dalam kasus seperti itu Anda mungkin ingin bermain sedikit dengan variabel komit grup (untuk MySQL dan MariaDB) untuk menunda komit untuk jangka waktu yang sedikit (kita berbicara tentang milidetik di sini) dan, dengan cara ini , meningkatkan paralelisasi komit.
Jika masalahnya ada di I/O, masalahnya sedikit lebih sulit untuk dipecahkan. Tentu saja, Anda harus meninjau pengaturan I/O InnoDB Anda - mungkin ada ruang untuk perbaikan. Jika penyetelan my.cnf tidak membantu, Anda tidak memiliki terlalu banyak opsi - tingkatkan kueri Anda (bila memungkinkan) atau tingkatkan subsistem I/O Anda ke sesuatu yang lebih mampu.
Sebagian besar proxy (misalnya, semua proxy yang dapat digunakan dari ClusterControl:ProxySQL, HAProxy, dan MaxScale) memberi Anda kemungkinan untuk menghapus slave dari rotasi jika lag replikasi melewati beberapa ambang batas yang telah ditentukan. Ini sama sekali bukan metode untuk mengurangi kelambatan, tetapi dapat membantu untuk menghindari pembacaan yang basi dan, sebagai efek samping, mengurangi beban pada slave yang akan membantunya mengejar ketinggalan.
Tentu saja, penyetelan kueri dapat menjadi solusi dalam kedua kasus - selalu baik untuk meningkatkan kueri yang berat CPU atau I/O.
Transaksi Salah
Transaksi yang salah adalah transaksi yang dilakukan hanya pada budak, bukan pada master. Singkatnya, mereka membuat seorang budak tidak konsisten dengan tuannya. Saat menggunakan replikasi berbasis GTID, ini dapat menyebabkan masalah serius jika budak dipromosikan menjadi master. Kami memiliki posting mendalam tentang topik ini dan kami mendorong Anda untuk melihat ke dalamnya dan membiasakan diri dengan cara mendeteksi dan memperbaiki masalah dengan transaksi yang salah. Kami juga menyertakan informasi di sana bagaimana ClusterControl mendeteksi dan menangani transaksi yang salah.
Tidak Ada File Binlog di Master
Bagaimana cara mengidentifikasi masalah?
Dalam beberapa keadaan, mungkin terjadi bahwa seorang budak terhubung ke master dan meminta file log biner yang tidak ada. Salah satu alasan untuk ini bisa jadi adalah transaksi yang salah - di beberapa titik waktu, transaksi telah dijalankan pada budak dan kemudian budak ini menjadi master. Host lain, yang dikonfigurasi untuk menjadi budak dari master itu, akan meminta transaksi yang hilang itu. Jika dijalankan sejak lama, ada kemungkinan file log biner telah dihapus.
Contoh lain yang lebih umum - Anda ingin menyediakan budak menggunakan xtrabackup. Anda menyalin cadangan pada host, menerapkan log, mengubah pemilik direktori data MySQL - operasi khas yang Anda lakukan untuk memulihkan cadangan. Anda mengeksekusi
SET GLOBAL gtid_purged=berdasarkan data dari xtrabackup_binlog_info dan Anda menjalankan CHANGE MASTER TO … MASTER_AUTO_POSITION=1 (ini di MySQL, MariaDB memiliki proses yang sedikit berbeda), mulai slave dan kemudian Anda berakhir dengan kesalahan seperti:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'di MySQL atau:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'di MariaDB.
Ini pada dasarnya berarti bahwa master tidak memiliki semua log biner yang diperlukan untuk mengeksekusi semua transaksi yang hilang. Kemungkinan besar, cadangan terlalu lama dan master telah menghapus beberapa log biner yang dibuat antara saat cadangan dibuat dan saat slave disediakan.
Bagaimana cara mengatasi masalah ini?
Sayangnya, tidak banyak yang dapat Anda lakukan dalam kasus khusus ini. Jika Anda memiliki beberapa host MySQL yang menyimpan log biner lebih lama daripada master, Anda dapat mencoba menggunakan log tersebut untuk memutar ulang transaksi yang hilang pada slave. Mari kita lihat bagaimana hal itu dapat dilakukan.
Pertama-tama, mari kita lihat GTID tertua di log biner master:
mysql> SHOW BINARY LOGS\G
*************************** 1. row ***************************
Log_name: binlog.000021
File_size: 463
1 row in set (0.00 sec)Jadi, 'binlog.000021' adalah file terbaru (dan satu-satunya). Mari kita periksa apa entri GTID pertama di file ini:
example@sqldat.com:~# mysqlbinlog /var/lib/mysql/binlog.000021
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170320 10:39:51 server id 1 end_log_pos 123 CRC32 0x5644fc9b Start: binlog v 4, server v 5.7.17-11-log created 170320 10:39:51
# Warning: this binlog is either in use or was not closed properly.
BINLOG '
d7HPWA8BAAAAdwAAAHsAAAABAAQANS43LjE3LTExLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA
AZv8RFY=
'/*!*/;
# at 123
#170320 10:39:51 server id 1 end_log_pos 194 CRC32 0x5c096d62 Previous-GTIDs
# 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668
# at 194
#170320 11:21:26 server id 1 end_log_pos 259 CRC32 0xde21b300 GTID last_committed=0 sequence_number=1
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106669'/*!*/;
# at 259Seperti yang kita lihat, entri log biner tertua yang tersedia adalah:5d1e2227-07c6-11e7-8123-080027495a77:1106669
Kami juga perlu memeriksa apa saja GTID terakhir yang tercakup dalam cadangan:
example@sqldat.com:~# cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000017 194 5d1e2227-07c6-11e7-8123-080027495a77:1-1106666
Ini adalah:5d1e2227-07c6-11e7-8123-080027495a77:1-1106666 jadi kita kekurangan dua peristiwa:
5d1e2227-07c6-11e7-8123-080027495a77:1106667-1106668
Mari kita lihat apakah kita dapat menemukan transaksi tersebut pada budak lain.
mysql> SHOW BINARY LOGS;
+---------------+------------+
| Log_name | File_size |
+---------------+------------+
| binlog.000001 | 1074130062 |
| binlog.000002 | 764366611 |
| binlog.000003 | 382576490 |
+---------------+------------+
3 rows in set (0.00 sec)Tampaknya 'binlog.000003' adalah log biner terbaru. Kami perlu memeriksa apakah GTID kami yang hilang dapat ditemukan di dalamnya:
slave2:~# mysqlbinlog /var/lib/mysql/binlog.000003 | grep "5d1e2227-07c6-11e7-8123-080027495a77:110666[78]"
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106667'/*!*/;
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106668'/*!*/;Harap diingat bahwa Anda mungkin ingin menyalin file binlog di luar server produksi karena memprosesnya dapat menambah beban. Saat kami memverifikasi bahwa GTID itu ada, kami dapat mengekstraknya:
slave2:~# mysqlbinlog --exclude-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1-1106666,5d1e2227-07c6-11e7-8123-080027495a77:1106669' /var/lib/mysql/binlog.000003 > to_apply_on_slave1.sqlSetelah scp cepat, kita dapat menerapkan event tersebut pada slave
slave1:~# mysql -ppass < to_apply_on_slave1.sqlSetelah selesai, kami dapat memverifikasi apakah GTID tersebut telah diterapkan dengan melihat output dari SHOW SLAVE STATUS:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 170320 10:45:04
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668Executed_GTID_set terlihat bagus karena itu kita dapat memulai utas budak:
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)Mari kita periksa apakah itu berfungsi dengan baik. Kami akan, sekali lagi, menggunakan output SHOW SLAVE STATUS:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106669
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106669Terlihat bagus, aktif dan berjalan!
Metode lain untuk memecahkan masalah ini adalah mengambil cadangan sekali lagi dan menyediakan budak lagi, menggunakan data baru. Ini kemungkinan besar akan lebih cepat dan pasti lebih dapat diandalkan. Jarang sekali Anda memiliki kebijakan pembersihan binlog yang berbeda pada master dan slave)
Kami akan terus membahas jenis masalah replikasi lainnya di entri blog berikutnya.