Di dunia yang sempurna, tidak masalah sintaks T-SQL mana yang kami pilih untuk mengekspresikan kueri. Setiap konstruksi yang identik secara semantik akan menghasilkan rencana eksekusi fisik yang persis sama, dengan karakteristik kinerja yang persis sama.
Untuk mencapai itu, pengoptimal kueri SQL Server perlu mengetahui setiap kesetaraan logis yang mungkin (dengan asumsi kita dapat mengetahui semuanya), dan diberi waktu dan sumber daya untuk menjelajahi semua opsi. Mengingat banyaknya kemungkinan cara kita dapat mengekspresikan persyaratan yang sama dalam T-SQL, dan banyaknya kemungkinan transformasi, kombinasi dengan cepat menjadi tidak dapat diatur untuk semua kecuali kasus yang paling sederhana.
Sebuah "dunia yang sempurna" dengan sintaks-independensi lengkap mungkin tidak tampak begitu sempurna bagi pengguna yang harus menunggu berhari-hari, berminggu-minggu, atau bahkan bertahun-tahun untuk mengkompilasi kueri yang cukup rumit. Jadi pengoptimal kueri berkompromi:ia mengeksplorasi beberapa kesetaraan umum dan berusaha keras untuk menghindari menghabiskan lebih banyak waktu untuk kompilasi dan pengoptimalan daripada menghemat waktu eksekusi. Tujuannya dapat diringkas sebagai upaya untuk menemukan rencana eksekusi yang masuk akal dalam waktu yang wajar, sambil menggunakan sumber daya yang wajar.
Salah satu akibat dari semua ini adalah bahwa rencana eksekusi seringkali sensitif terhadap bentuk tertulis dari kueri. Pengoptimal memang memiliki beberapa logika untuk dengan cepat mengubah beberapa konstruksi ekuivalen yang banyak digunakan ke bentuk umum, tetapi kemampuan ini tidak didokumentasikan dengan baik atau (di mana pun dekat) komprehensif.
Kami tentu saja dapat memaksimalkan peluang kami untuk mendapatkan rencana eksekusi yang baik dengan menulis kueri yang lebih sederhana, menyediakan indeks yang berguna, mempertahankan statistik yang baik, dan membatasi diri pada konsep yang lebih relasional (misalnya dengan menghindari kursor, loop eksplisit, dan fungsi non-inline) tetapi ini bukan solusi yang lengkap. Juga tidak mungkin untuk mengatakan bahwa satu konstruksi T-SQL akan selalu menghasilkan rencana eksekusi yang lebih baik daripada alternatif yang identik secara semantik.
Saran saya yang biasa adalah memulai dengan bentuk kueri relasional paling sederhana yang memenuhi kebutuhan Anda, menggunakan sintaks T-SQL apa pun yang menurut Anda lebih disukai. Jika kueri tidak memenuhi persyaratan setelah optimasi fisik (misalnya pengindeksan), ada baiknya mencoba mengekspresikan kueri dengan cara yang sedikit berbeda, sambil mempertahankan semantik asli. Ini adalah bagian yang sulit. Bagian kueri mana yang harus Anda coba tulis ulang? Penulisan ulang mana yang harus Anda coba? Tidak ada jawaban sederhana untuk semua pertanyaan ini. Beberapa di antaranya tergantung pada pengalaman, meskipun mengetahui sedikit tentang pengoptimalan kueri dan internal mesin eksekusi dapat menjadi panduan yang berguna juga.
Contoh
Contoh ini menggunakan tabel AdventureWorks TransactionHistory. Script di bawah ini membuat salinan tabel dan membuat indeks berkerumun dan tidak berkerumun. Kami tidak akan mengubah data sama sekali; langkah ini hanya untuk memperjelas pengindeksan (dan memberi nama yang lebih pendek pada tabel):
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Tugasnya adalah membuat daftar ID produk dan riwayat untuk enam produk tertentu. Salah satu cara untuk mengekspresikan kueri adalah:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
Kueri ini mengembalikan 764 baris menggunakan rencana eksekusi berikut (ditampilkan di SentryOne Plan Explorer):

Kueri sederhana ini memenuhi syarat untuk kompilasi paket TRIVIAL. Rencana eksekusi menampilkan enam operasi pencarian indeks terpisah dalam satu:
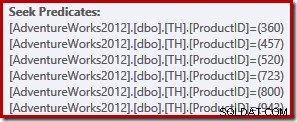
Pembaca bermata elang akan memperhatikan bahwa enam pencarian terdaftar di naik urutan ID produk, bukan dalam urutan (sewenang-wenang) yang ditentukan dalam daftar IN kueri asli. Memang, jika Anda menjalankan kueri sendiri, kemungkinan besar Anda akan mengamati hasil yang dikembalikan dalam urutan ID produk menaik. Kueri tidak dijamin untuk mengembalikan hasil dalam urutan itu tentu saja, karena kami tidak menentukan klausa ORDER BY tingkat atas. Namun kita dapat menambahkan klausa ORDER BY tersebut, tanpa mengubah rencana eksekusi yang dihasilkan dalam kasus ini:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
Saya tidak akan mengulangi grafik rencana eksekusi, karena persis sama:kueri masih memenuhi syarat untuk rencana sepele, operasi pencarian persis sama, dan kedua rencana memiliki perkiraan biaya yang persis sama. Menambahkan klausa ORDER BY sama sekali tidak merugikan kami, tetapi memberi kami jaminan pemesanan set hasil.
Kami sekarang memiliki jaminan bahwa hasil akan dikembalikan dalam urutan ID produk, tetapi kueri kami saat ini tidak menentukan bagaimana baris dengan sama ID produk akan dipesan. Melihat hasilnya, Anda mungkin mengamati bahwa baris untuk ID produk yang sama tampaknya diurutkan berdasarkan ID transaksi, menaik.
Tanpa ORDER BY eksplisit, ini hanyalah pengamatan lain (yaitu kami tidak dapat mengandalkan pemesanan ini), tetapi kami dapat memodifikasi kueri untuk memastikan baris diurutkan berdasarkan ID transaksi dalam setiap ID produk:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Sekali lagi, rencana eksekusi untuk kueri ini sama persis seperti sebelumnya; rencana sepele yang sama dengan perkiraan biaya yang sama diproduksi. Bedanya sekarang hasilnya dijamin untuk dipesan terlebih dahulu dengan ID produk dan kemudian dengan ID transaksi.
Beberapa orang mungkin tergoda untuk menyimpulkan bahwa dua kueri sebelumnya juga akan selalu mengembalikan baris dalam urutan ini, karena rencana eksekusinya sama. Ini bukan implikasi yang aman, karena tidak semua detail mesin eksekusi diekspos dalam rencana eksekusi (bahkan dalam bentuk XML). Tanpa urutan per klausa yang eksplisit, SQL Server bebas mengembalikan baris dalam urutan apa pun, bahkan jika rencananya terlihat sama bagi kita (bisa, misalnya, melakukan pencarian dalam urutan yang ditentukan dalam teks kueri). Intinya adalah pengoptimal kueri mengetahui, dan dapat menerapkan, perilaku tertentu di dalam mesin yang tidak terlihat oleh pengguna.
Jika Anda bertanya-tanya bagaimana indeks non-clustered non-unik kami pada ID Produk dapat mengembalikan baris di Produk dan Urutan ID Transaksi, jawabannya adalah bahwa kunci indeks nonclustered menggabungkan ID Transaksi (kunci indeks berkerumun unik). Faktanya, fisik struktur indeks nonclustered kami tepat sama, di semua level, seolah-olah kita telah membuat indeks dengan definisi berikut:
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
Kami bahkan dapat menulis kueri dengan DISTINCT atau GROUP BY eksplisit dan tetap mendapatkan rencana eksekusi yang sama persis:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Agar jelas, ini tidak memerlukan perubahan indeks nonclustered asli dengan cara apa pun. Sebagai contoh terakhir, perhatikan bahwa kami juga dapat meminta hasil dalam urutan menurun:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
Properti rencana eksekusi sekarang menunjukkan bahwa indeks dipindai mundur:

Selain itu, rencana tersebut sama – diproduksi pada tahap optimasi rencana trivial, dan masih memiliki perkiraan biaya yang sama.
Menulis ulang kueri
Tidak ada yang salah dengan kueri atau rencana eksekusi sebelumnya, tetapi kami mungkin memilih untuk mengekspresikan kueri secara berbeda:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
Jelas formulir ini menentukan hasil yang persis sama dengan aslinya, dan memang kueri baru menghasilkan rencana eksekusi yang sama (rencana sepele, banyak pencarian dalam satu, perkiraan biaya yang sama). Bentuk ATAU mungkin membuatnya sedikit lebih jelas bahwa hasilnya adalah kombinasi dari hasil untuk enam ID produk individual, yang mungkin mengarahkan kami untuk mencoba variasi lain yang membuat ide ini lebih eksplisit:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
Rencana eksekusi untuk kueri UNION ALL sangat berbeda:
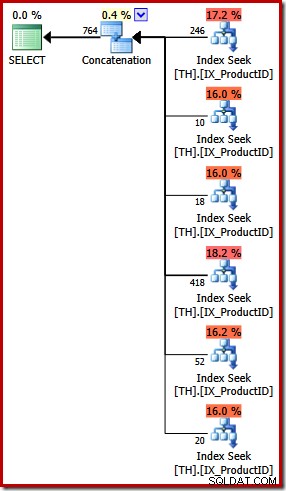
Selain perbedaan visual yang jelas, paket ini memerlukan pengoptimalan berbasis biaya (LENGKAP) (tidak memenuhi syarat untuk paket sepele), dan perkiraan biayanya (secara relatif) sedikit lebih tinggi, sekitar 0,02 unit versus sekitar 0,005 unit sebelumnya.
Ini kembali ke sambutan pembukaan saya:pengoptimal kueri tidak tahu tentang setiap kesetaraan logis, dan tidak selalu dapat mengenali kueri alternatif sebagai menentukan hasil yang sama. Poin yang saya buat pada tahap ini adalah bahwa mengekspresikan kueri khusus ini menggunakan UNION ALL daripada IN menghasilkan rencana eksekusi yang kurang optimal.
Contoh kedua
Contoh ini memilih kumpulan enam ID produk yang berbeda dan permintaan menghasilkan urutan ID transaksi:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Indeks nonclustered kami tidak dapat menyediakan baris dalam urutan yang diminta, sehingga pengoptimal kueri memiliki pilihan untuk membuat antara mencari di indeks nonclustered dan menyortir, atau memindai indeks clustered (yang dikunci pada ID transaksi saja) dan menerapkan predikat ID produk sebagai sebuah sisa. ID produk yang terdaftar kebetulan memiliki selektivitas yang lebih rendah daripada rangkaian sebelumnya, sehingga pengoptimal memilih pemindaian indeks berkerumun dalam kasus ini:
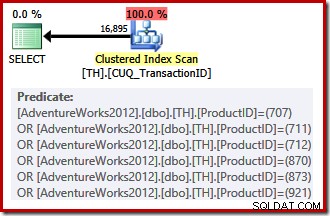
Karena ada pilihan berdasarkan biaya yang harus dibuat, rencana eksekusi ini tidak memenuhi syarat untuk rencana sepele. Perkiraan biaya rencana akhir adalah sekitar 0,714 unit. Memindai indeks berkerumun membutuhkan 797 pembacaan logis pada waktu eksekusi.
Mungkin karena terkejut bahwa kueri tidak menggunakan indeks produk, kami mungkin mencoba memaksa pencarian indeks nonclustered menggunakan petunjuk indeks, atau dengan menentukan FORCESEEK:
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
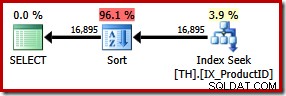
Ini menghasilkan pengurutan eksplisit berdasarkan ID transaksi. Jenis baru diperkirakan mencapai 96% dari 1,15 plan paket baru biaya satuan. Perkiraan biaya yang lebih tinggi ini menjelaskan mengapa pengoptimal memilih pemindaian indeks berkerumun yang tampaknya lebih murah ketika diserahkan ke perangkatnya sendiri. Biaya I/O dari kueri baru lebih rendah:saat dijalankan, pencarian indeks hanya menggunakan 49 pembacaan logis (turun dari 797).
Kami mungkin juga telah memilih untuk mengekspresikan kueri ini menggunakan (yang sebelumnya tidak berhasil) ide UNION ALL:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Ini menghasilkan rencana eksekusi berikut (klik gambar untuk memperbesar di jendela baru):

Paket ini mungkin tampak lebih rumit, tetapi perkiraan biayanya hanya 0,099 unit, yang jauh lebih rendah daripada pemindaian indeks berkerumun (0,714 unit) atau cari plus sort (1,15 unit). Selain itu, paket baru hanya menggunakan 49 pembacaan logis pada waktu eksekusi – sama dengan rencana pencarian + pengurutan, dan jauh lebih rendah dari 797 yang diperlukan untuk pemindaian indeks berkerumun.
Kali ini, mengekspresikan kueri menggunakan UNION ALL menghasilkan rencana yang jauh lebih baik, baik dalam hal perkiraan biaya dan pembacaan logis. Kumpulan data sumber agak terlalu kecil untuk membuat perbandingan yang benar-benar bermakna antara durasi kueri atau penggunaan CPU, tetapi pemindaian indeks berkerumun membutuhkan waktu dua kali lebih lama (26 md) dibandingkan dua lainnya di sistem saya.
Penyortiran ekstra dalam rencana yang diisyaratkan mungkin tidak berbahaya dalam contoh sederhana ini karena tidak mungkin tumpah ke disk, tetapi banyak orang akan tetap memilih rencana UNION ALL karena tidak memblokir, menghindari pemberian memori, dan tidak memerlukan petunjuk kueri.
Kesimpulan
Kita telah melihat bahwa sintaks kueri dapat memengaruhi rencana eksekusi yang dipilih oleh pengoptimal, meskipun kueri secara logis menentukan kumpulan hasil yang sama persis. Penulisan ulang yang sama (misalnya UNION ALL) terkadang menghasilkan peningkatan, dan terkadang menyebabkan rencana yang lebih buruk dipilih.
Menulis ulang kueri dan mencoba sintaks alternatif adalah teknik penyetelan yang valid, tetapi beberapa kehati-hatian diperlukan. Salah satu risikonya adalah bahwa perubahan produk di masa mendatang dapat menyebabkan formulir kueri yang berbeda tiba-tiba berhenti menghasilkan rencana yang lebih baik, tetapi orang dapat berargumen bahwa itu selalu merupakan risiko, dan dimitigasi dengan pengujian pra-peningkatan versi atau penggunaan panduan rencana.
Ada juga risiko terbawa oleh teknik ini: menggunakan konstruksi kueri 'aneh' atau 'tidak biasa' untuk mendapatkan rencana yang berkinerja lebih baik sering kali merupakan tanda bahwa garis telah dilewati. Tepat di mana perbedaan terletak antara sintaks alternatif yang valid dan 'tidak biasa/aneh' mungkin cukup subjektif; panduan pribadi saya adalah bekerja dengan formulir kueri relasional yang setara, dan menjaga hal-hal sesederhana mungkin.