Indeks adalah penguat kecepatan dalam database SQL. Mereka dapat berkerumun atau tidak berkerumun. Tapi apa artinya dan di mana Anda harus menerapkannya masing-masing?
Aku tahu perasaan ini. Aku pernah disana. Pemula sering bingung tentang indeks mana yang akan digunakan pada kolom mana. Namun, bahkan para ahli perlu memikirkan masalah ini sebelum membuat keputusan, dan situasi yang berbeda memerlukan keputusan yang berbeda. Seperti yang akan Anda lihat nanti, ada kueri di mana indeks berkerumun akan bersinar dibandingkan dengan indeks yang tidak berkerumun, dan sebaliknya.
Namun, pertama-tama, kita harus mengetahui masing-masing dari mereka. Jika Anda mencari info yang sama, hari ini adalah hari keberuntungan Anda.
Artikel ini akan memberi tahu Anda apa itu indeks dan kapan harus menggunakannya. Tentu saja, akan ada contoh kode untuk Anda coba dalam praktik. Jadi, ambil keripik atau pizza dan soda atau kopi Anda, dan bersiaplah untuk membenamkan diri dalam perjalanan yang penuh wawasan ini.
Siap?
Apa itu Indeks Berkelompok
Indeks berkerumun adalah indeks yang mendefinisikan urutan fisik baris dalam tabel atau tampilan.
Untuk melihat ini dalam bentuk sebenarnya, mari kita lihat Karyawan tabel di AdventureWorks2017 basis data.
Kunci utama juga merupakan indeks berkerumun, dan kuncinya didasarkan pada BusinessEntityID kolom. Saat Anda melakukan SELECT pada tabel ini tanpa ORDER BY, Anda akan melihat bahwa tabel tersebut diurutkan berdasarkan kunci utama.
Cobalah sendiri menggunakan kode di bawah ini:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Sekarang, lihat hasilnya pada Gambar 1:
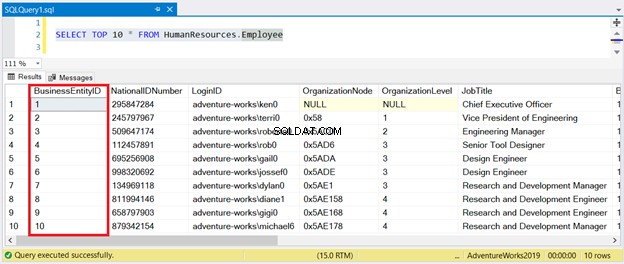
Seperti yang Anda lihat, Anda tidak perlu mengurutkan kumpulan hasil dengan BusinessEntityID . Indeks berkerumun menangani hal itu.
Tidak seperti indeks yang tidak berkerumun, Anda hanya dapat memiliki 1 indeks berkerumun per tabel. Bagaimana jika kita mencoba ini pada Karyawan meja?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
Kami memiliki kesalahan serupa di bawah ini:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
Kapan Menggunakan Indeks Berkelompok?
Kolom adalah kandidat terbaik untuk indeks berkerumun jika salah satu dari berikut ini benar:
- Ini digunakan dalam sejumlah besar kueri dalam klausa WHERE dan bergabung.
- Ini akan digunakan sebagai kunci asing ke tabel lain, dan, pada akhirnya, untuk bergabung.
- Nilai kolom unik.
- Nilainya cenderung tidak berubah.
- Kolom itu digunakan untuk mengkueri rentang nilai. Operator seperti>, <,>=, <=atau BETWEEN digunakan dengan kolom dalam klausa WHERE.
Tetapi indeks berkerumun tidak baik jika kolom atau kolom
- sering berubah
- adalah kunci lebar atau kombinasi kolom dengan ukuran kunci besar.
Contoh
Indeks berkerumun dapat dibuat menggunakan kode T-SQL atau alat GUI SQL Server apa pun. Anda dapat melakukannya di T-SQL saat pembuatan tabel, seperti ini:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
Atau, Anda dapat melakukannya menggunakan ALTER TABLE setelah membuat tabel tanpa indeks berkerumun:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Cara lain adalah menggunakan CREATE CLUSTERED INDEX:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
Satu lagi alternatif adalah menggunakan alat SQL Server seperti SQL Server Management Studio atau dbForge Studio untuk SQL Server.
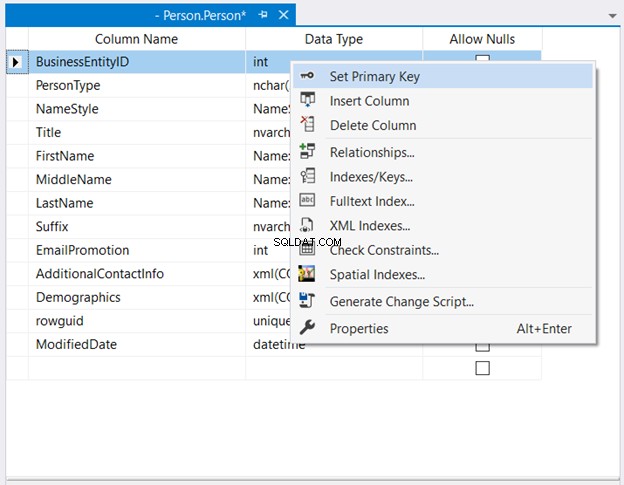
Di Penjelajah Objek , perluas database dan node tabel. Kemudian, klik kanan tabel yang diinginkan dan pilih Desain . Terakhir, klik kanan kolom yang ingin dijadikan kunci utama> Setel Kunci Utama > Simpan perubahan ke tabel.
Gambar 2 di bawah menunjukkan di mana BusinessEntityID ditetapkan sebagai kunci utama.
Selain membuat indeks berkerumun satu kolom, Anda dapat menggunakan beberapa kolom. Lihat contoh di T-SQL:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
Setelah membuat indeks berkerumun ini, Orang tabel akan diurutkan secara fisik berdasarkan Nama belakang , Nama Depan , dan MiddleName .
Salah satu keuntungan dari pendekatan ini adalah peningkatan kinerja kueri berdasarkan nama. Selain itu, ia mengurutkan hasil berdasarkan nama tanpa menentukan ORDER BY. Tetapi perhatikan bahwa jika namanya berubah, tabel harus diatur ulang. Meskipun ini tidak akan terjadi setiap hari, dampaknya bisa sangat besar jika tabelnya sangat besar.
Apa yang dimaksud dengan Indeks Non-cluster
Indeks non-clustered adalah indeks dengan kunci dan penunjuk ke baris atau kunci indeks berkerumun. Indeks ini dapat berlaku untuk tabel dan tampilan.
Tidak seperti indeks berkerumun, di sini strukturnya terpisah dari tabel. Karena terpisah, diperlukan penunjuk ke baris tabel yang juga disebut pencari baris. Dengan demikian, setiap entri dalam indeks non-cluster berisi locator dan nilai kunci.
Indeks non-clustered tidak secara fisik mengurutkan tabel berdasarkan kunci.
Kunci indeks untuk indeks non-cluster memiliki ukuran maksimum 1700 byte. Anda dapat melewati batas ini dengan menambahkan kolom yang disertakan. Metode ini bagus jika kueri Anda perlu mencakup lebih banyak kolom tanpa menambah ukuran kunci.
Anda juga dapat membuat indeks non-cluster yang difilter. Ini akan mengurangi biaya pemeliharaan indeks dan penyimpanan sekaligus meningkatkan kinerja kueri.
Kapan Menggunakan Indeks Non-cluster?
Kolom atau kolom adalah kandidat yang baik untuk indeks non-cluster jika berikut ini benar:
- Kolom atau kolom digunakan dalam klausa WHERE atau gabung.
- Kueri tidak akan mengembalikan kumpulan hasil yang besar.
- Pencocokan persis dalam klausa WHERE menggunakan operator kesetaraan diperlukan.
Contoh
Perintah ini akan membuat indeks unik yang tidak berkerumun di Karyawan tabel:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Selain tabel, Anda dapat membuat indeks non-cluster untuk tampilan:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Pertanyaan Umum Lainnya dan Jawaban Memuaskan
Apa Perbedaan Antara Indeks Clustered dan Non-clustered?
Dari apa yang Anda lihat sebelumnya, Anda sudah dapat membentuk ide tentang betapa berbedanya indeks berkerumun dan tidak berkerumun. Tapi mari kita letakkan di atas meja untuk referensi mudah.
| Info | Indeks Tergugus | Indeks Non-cluster |
| Berlaku untuk | Tabel dan tampilan | Tabel dan tampilan |
| Diizinkan per Tabel | 1 | 999 |
| Ukuran kunci | 900 byte | 1700 byte |
| Kolom per kunci indeks | 32 | 32 |
| Bagus untuk | Kueri rentang (>,<,>=, <=, ANTARA) | Kecocokan sama persis (=) |
| Kolom yang disertakan bukan kunci | Tidak diperbolehkan | Diizinkan |
| Filter dengan kondisi | Tidak diperbolehkan | Diizinkan |
Haruskah Kunci Utama Dikelompokkan atau Indeks Tidak Dikelompokkan?
Kunci utama adalah kendala. Setelah Anda menjadikan kolom sebagai kunci utama, indeks berkerumun secara otomatis dibuat darinya, kecuali jika indeks berkerumun yang ada sudah ada.
Jangan bingung antara kunci utama dengan indeks berkerumun! Kunci utama juga bisa menjadi kunci indeks berkerumun. Tapi kunci indeks berkerumun bisa menjadi kolom lain selain kunci utama.
Mari kita ambil contoh lain. Dalam Orang tabel AdventureWorks201 7, kami memiliki BusinessEntityID kunci utama. Ini juga merupakan kunci indeks berkerumun. Anda dapat menjatuhkan indeks berkerumun itu. Kemudian, buat indeks berkerumun berdasarkan Nama Belakang , Nama Depan , dan Nama Tengah . Kunci utama masih BusinessEntityID kolom.
Tetapi apakah kunci utama Anda harus selalu dikelompokkan?
Tergantung. Tinjau kembali pertanyaan tentang kapan harus menggunakan indeks berkerumun.
Jika kolom atau kolom muncul di klausa WHERE Anda dalam banyak kueri, ini adalah kandidat untuk indeks berkerumun. Tetapi pertimbangan lain adalah seberapa lebar kunci indeks berkerumun. Terlalu lebar – dan ukuran setiap indeks yang tidak berkerumun akan bertambah jika ada. Ingat bahwa indeks yang tidak berkerumun juga menggunakan kunci indeks berkerumun sebagai penunjuk. Jadi, jaga agar kunci indeks terklaster Anda sesempit mungkin.
Jika sejumlah besar kueri menggunakan kunci utama dalam klausa WHERE, biarkan juga sebagai kunci indeks berkerumun. Jika tidak, buat kunci utama Anda sebagai indeks non-cluster.
Tapi bagaimana jika Anda masih ragu? Kemudian, Anda dapat menilai manfaat kinerja kolom saat dikelompokkan atau tidak dikelompokkan. Jadi, simak bagian selanjutnya tentang ini.
Mana yang Lebih Cepat:Indeks Clustered atau Non-clustered?
Pertanyaan bagus. Tidak ada aturan umum. Anda perlu memeriksa pembacaan logis dan rencana eksekusi kueri Anda.
Eksperimen singkat kami akan menyertakan salinan tabel berikut dari AdventureWorks2017 basis data:
- Orang
- Alamat Badan Usaha
- Alamat
- Jenis Alamat
Berikut scriptnya:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
Dengan menggunakan struktur di atas, kami akan membandingkan kecepatan kueri untuk indeks berkerumun dan tidak berkerumun.
Kami memiliki 2 salinan Orang meja. Yang pertama akan menggunakan BusinessEntityID sebagai kunci indeks utama dan berkerumun. Yang kedua masih menggunakan BusinessEntityID sebagai kunci utama. Indeks berkerumun didasarkan pada Nama Belakang , Nama Depan , Nama tengah , dan Sufiks .
Mari kita mulai.
KECOCOKAN PERSIS QUERY BERDASARKAN NAMA TERAKHIR
Pertama, mari kita buat kueri sederhana. Juga, perlu mengaktifkan STATISTICS IO. Kemudian, kami menempelkan hasilnya di statistikparser.com untuk presentasi tabel.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
Harapannya adalah SELECT pertama akan lebih lambat karena klausa WHERE tidak cocok dengan kunci indeks berkerumun. Tapi mari kita periksa pembacaan logisnya.
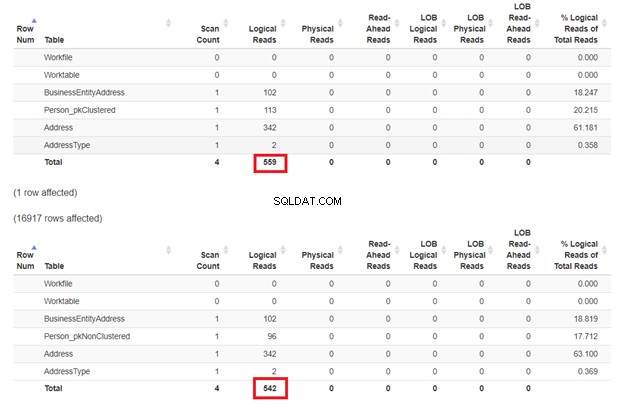
Seperti yang diharapkan pada Gambar 3, Person_pkClustered memiliki bacaan yang lebih logis. Oleh karena itu, kueri membutuhkan lebih banyak I/O. Alasannya? Tabel diurutkan berdasarkan BusinessEntityID . Namun, tabel kedua memiliki indeks berkerumun berdasarkan namanya. Karena kueri menginginkan hasil berdasarkan nama, Person_pkNonClustered menang. Pembacaan yang kurang logis, semakin cepat kuerinya.
Apa hal lain yang sedang terjadi? Lihat Gambar 4.
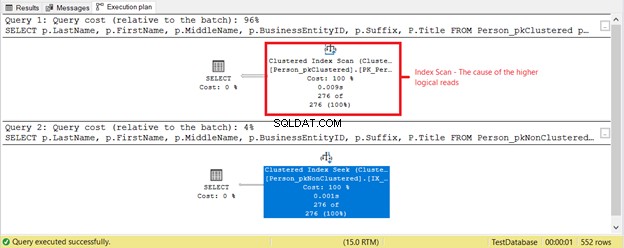
Hal lain terjadi berdasarkan rencana eksekusi pada Gambar 4. Mengapa Pemindaian Indeks Berkelompok ada di SELECT pertama, bukan Pencarian Indeks? Pelakunya adalah Judul kolom di SELECT. Itu tidak tercakup oleh indeks yang ada. Pengoptimal SQL Server menganggap lebih cepat menggunakan indeks berkerumun berdasarkan BusinessEntityID. Kemudian, SQL Server memindainya untuk nama belakang yang tepat dan mendapatkan nama depan, nama tengah, dan gelar.
Hapus Judul kolom, dan operator yang digunakan adalah Index Seek . Mengapa? Karena sisa bidang dicakup oleh indeks non-cluster berdasarkan Nama Belakang , Nama Depan , Nama tengah , dan Sufiks . Ini juga mencakup BusinessEntityID sebagai pencari kunci indeks berkerumun.
RANGE QUERY BERDASARKAN ID BISNIS ENTITAS
Indeks berkerumun bisa bagus untuk kueri rentang. Apakah selalu demikian? Mari kita cari tahu dengan menggunakan kode di bawah ini.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
Cantuman membutuhkan baris berdasarkan rentang BusinessEntityIDs dari 285 hingga 290. Sekali lagi, indeks berkerumun dan tidak berkerumun dari 2 tabel masih utuh. Sekarang, mari kita baca logikanya pada Gambar 5. Pemenang yang diharapkan adalah Person_pkClustered karena kunci utama juga merupakan kunci indeks berkerumun.

Apakah Anda melihat pembacaan logis yang lebih rendah di Person_pkClustered ? Indeks berkerumun membuktikan nilainya pada kueri rentang dalam skenario ini. Mari kita lihat apa lagi yang akan terungkap dari rencana eksekusi pada Gambar 6.
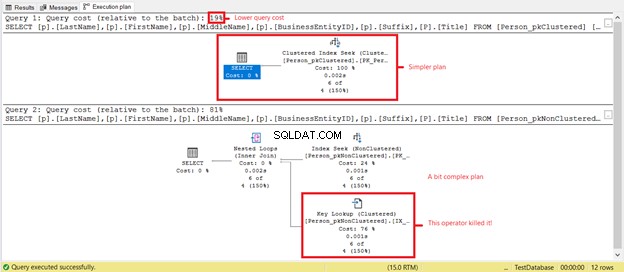
SELECT pertama memiliki rencana yang lebih sederhana dan biaya kueri yang lebih rendah berdasarkan Gambar 7. Ini juga mendukung pembacaan logis yang lebih rendah. Sementara itu, SELECT kedua memiliki operator Pencarian Kunci yang memperlambat kueri. Pelakunya? Sekali lagi, ini adalah Judul kolom. Hapus kolom dalam kueri atau tambahkan sebagai kolom yang disertakan dalam indeks yang tidak berkerumun. Kemudian, Anda akan memiliki rencana yang lebih baik dan pembacaan logis yang lebih rendah.
QUERY PERSIS SAMA DENGAN GABUNG
Banyak pernyataan SELECT menyertakan gabungan. Mari kita lakukan beberapa tes. Di sini kita mulai dengan pencocokan persis:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
Kami berharap SELECT kedua dari Person_pkNonClustered dengan indeks berkerumun pada nama akan memiliki pembacaan yang kurang logis. Tapi apakah itu? Lihat Gambar 7.
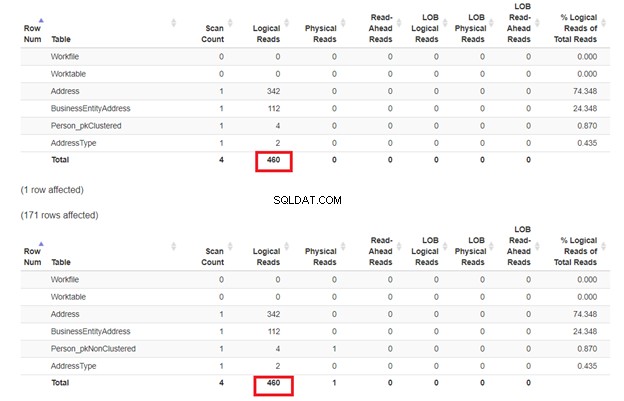
Sepertinya indeks non-cluster pada nama itu baik-baik saja. Pembacaan logisnya sama. Jika Anda memeriksa rencana eksekusi, perbedaan operator adalah Pencarian Indeks Cluster di Person_pkNonClustered , dan Pencarian Indeks di Person_pkClustered .
Jadi, kita perlu memeriksa pembacaan logis dan rencana eksekusi untuk memastikannya.
Rentang PERMINTAAN DENGAN GABUNG
Karena harapan kita bisa berbeda dari kenyataan, mari kita coba dengan berbagai kueri. Indeks berkerumun umumnya baik dengan itu. Tapi bagaimana jika Anda menyertakan join?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
Sekarang, periksa pembacaan logis dari 2 kueri ini pada Gambar 8:
Apa yang terjadi? Pada Gambar 9, kenyataan menggigit Person_pkClustered . Lebih banyak biaya I/O diamati di dalamnya dibandingkan dengan Person_pkNonClustered . Itu berbeda dari yang kita harapkan. Tetapi berdasarkan jawaban forum ini, pencarian indeks yang tidak berkerumun bisa lebih cepat daripada pencarian indeks berkerumun ketika semua kolom dalam kueri 100% tercakup dalam indeks. Dalam kasus kami, kueri untuk Person_pkNonClustered menutupi kolom menggunakan indeks non-cluster (BusinessEntityID – kunci; Nama belakang , Nama Depan , Nama tengah , Sufiks – penunjuk ke kunci indeks berkerumun).
MASUKKAN KINERJA
Kemudian, coba uji kinerja INSERT pada tabel yang sama.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
Gambar 9 menunjukkan pembacaan logika INSERT:

Keduanya menghasilkan I/O yang sama. Jadi, keduanya melakukan hal yang sama.
HAPUS KINERJA
Tes terakhir kami melibatkan DELETE:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
Gambar 10 menunjukkan pembacaan logis. Perhatikan perbedaannya.

Mengapa kita memiliki pembacaan logis yang lebih tinggi di Person_pkClustered ? Masalahnya, kondisi pernyataan DELETE didasarkan pada nama yang sama persis. Pengoptimal harus menggunakan indeks non-cluster terlebih dahulu. Ini berarti lebih banyak I/O. Mari konfirmasi menggunakan rencana eksekusi pada Gambar 11.
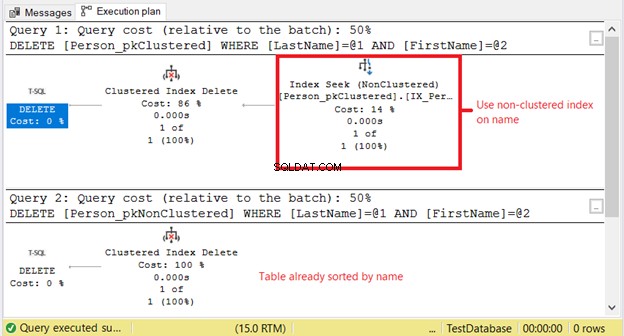
SELECT pertama membutuhkan Pencarian Indeks pada indeks yang tidak berkerumun. Alasannya adalah klausa WHERE pada Nama Belakang dan Nama Depan . Sementara itu, Person_pkNonClustered sudah secara fisik diurutkan berdasarkan nama karena indeks berkerumun.
Bawa Pulang
Membentuk kueri berkinerja tinggi bukanlah tentang keberuntungan. Anda tidak bisa hanya menempatkan indeks berkerumun dan tidak berkerumun dan kemudian tiba-tiba, kueri Anda memiliki kekuatan kecepatan. Anda harus tetap menggunakan alat sebagai lensa untuk fokus pada detail kecil selain kumpulan hasil.
Tetapi terkadang Anda tidak punya waktu untuk melakukan semua ini. Saya pikir itu normal. Tetapi selama Anda tidak terlalu mengacau, Anda memiliki pekerjaan Anda pada hari berikutnya, dan Anda dapat menyelesaikannya. Ini tidak akan mudah pada awalnya. Malah akan membingungkan. Anda juga akan memiliki banyak pertanyaan. Tetapi dengan latihan terus-menerus, Anda dapat mencapainya. Jadi, tetap semangat.
Ingat, indeks berkerumun dan tidak berkerumun adalah untuk meningkatkan kueri. Mengetahui perbedaan utama, skenario penggunaan, dan alat akan membantu Anda dalam pencarian Anda untuk mengkodekan kueri berkinerja tinggi.
Saya harap posting ini menjawab pertanyaan Anda yang paling mendesak tentang indeks berkerumun dan tidak berkerumun. Apakah Anda memiliki sesuatu yang lain untuk ditambahkan untuk pembaca kami? Bagian Komentar terbuka.
Dan jika menurut Anda postingan ini mencerahkan, silakan bagikan di platform media sosial favorit Anda.
Informasi lebih lanjut tentang indeks dan kinerja kueri ada di artikel di bawah ini:
- 22 Contoh Indeks SQL yang Bagus untuk Mempercepat Kueri Anda
- Optimalisasi Kueri SQL:5 Fakta Inti untuk Meningkatkan Kueri Anda