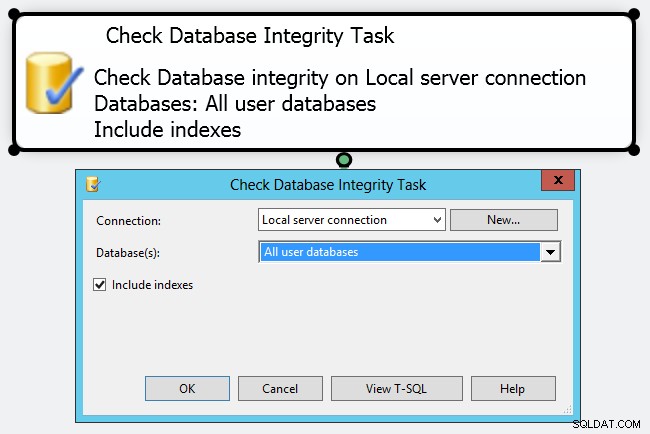
Tanggung jawab Anda sebagai DBA (atau DBCC CHECKDB . Anda bisa setengah jalan di sana dengan membuat rencana pemeliharaan sederhana dengan "Periksa Tugas Integritas Basis Data" – namun, menurut saya, ini hanya mencentang kotak.
Jika Anda melihat lebih dekat, sangat sedikit yang dapat Anda lakukan untuk mengontrol bagaimana tugas beroperasi. Bahkan panel Properties yang cukup luas memperlihatkan banyak pengaturan untuk subplan pemeliharaan, tetapi hampir tidak ada apa pun tentang DBCC perintah yang akan dijalankannya. Secara pribadi saya pikir Anda harus mengambil pendekatan yang jauh lebih proaktif dan terkontrol tentang bagaimana Anda melakukan CHECKDB Anda operasi di lingkungan produksi, dengan membuat pekerjaan Anda sendiri dan secara manual membuat DBCC . Anda perintah. Anda dapat menyesuaikan jadwal atau perintah Anda sendiri ke database yang berbeda – misalnya database keanggotaan ASP.NET mungkin tidak sepenting database penjualan Anda, dan dapat mentolerir pemeriksaan yang lebih jarang dan/atau kurang teliti.
Tetapi untuk basis data penting Anda, saya pikir saya akan menyusun posting untuk merinci beberapa hal yang akan saya selidiki untuk meminimalkan gangguan DBCC perintah dapat menyebabkan – dan mitos dan kehebohan pemasaran apa yang harus Anda waspadai. Dan saya ingin berterima kasih kepada Paul "Mr. DBCC" Randal (@PaulRandal) untuk memberikan masukan yang berharga – tidak hanya untuk posting khusus ini, tetapi juga saran tanpa akhir yang dia berikan di blognya, #sqlhelp dan dalam pelatihan SQLskills Immersion.
Harap ambil semua ide ini dengan sebutir garam, dan lakukan yang terbaik untuk melakukan pengujian yang memadai di lingkungan Anda – tidak semua saran ini akan menghasilkan kinerja yang lebih baik di semua lingkungan. Tetapi Anda berhutang kepada diri Anda sendiri, pengguna Anda, dan pemangku kepentingan Anda untuk setidaknya mempertimbangkan dampak yang CHECKDB Anda operasi mungkin, dan mengambil langkah-langkah untuk mengurangi efek tersebut jika memungkinkan – tanpa menimbulkan risiko yang tidak perlu dengan tidak memeriksa hal-hal yang benar.
Kurangi kebisingan dan habiskan semua kesalahan
Di mana pun Anda menjalankan CHECKDB , selalu gunakan WITH NO_INFOMSGS pilihan. Ini hanya menekan semua output yang tidak relevan yang hanya memberi tahu Anda berapa banyak baris di setiap tabel; jika Anda tertarik dengan informasi itu, Anda bisa mendapatkannya dari kueri sederhana terhadap DMV dan bukan saat DBCC sedang berlari. Menekan keluaran membuat kecil kemungkinan Anda akan melewatkan pesan penting yang terkubur dalam semua keluaran bahagia itu.
Demikian pula, Anda harus selalu menggunakan WITH ALL_ERRORMSGS opsi, tetapi terutama jika Anda menjalankan SQL Server 2008 RTM atau SQL Server 2005 (dalam kasus tersebut, Anda mungkin melihat daftar kesalahan per objek terpotong menjadi 200). Untuk CHECKDB operasi selain pemeriksaan ad-hoc cepat, Anda harus mempertimbangkan untuk mengarahkan output ke file. Management Studio dibatasi hingga 1000 baris output dari DBCC CHECKDB , jadi Anda mungkin kehilangan beberapa kesalahan jika melebihi angka ini.
Meskipun tidak sepenuhnya merupakan masalah kinerja, menggunakan opsi ini akan mencegah Anda menjalankan proses lagi. Ini sangat penting jika Anda berada di tengah pemulihan bencana.
Bongkar pemeriksaan logika jika memungkinkan
Dalam kebanyakan kasus, CHECKDB menghabiskan sebagian besar waktunya untuk melakukan pemeriksaan logis terhadap data. Jika Anda memiliki kemampuan untuk melakukan pemeriksaan ini pada salinan asli dari data, Anda dapat memfokuskan upaya Anda pada struktur fisik sistem produksi Anda, dan menggunakan server sekunder untuk menangani semua pemeriksaan logis dan mengurangi beban itu dari yang utama. Oleh server sekunder , maksud saya hanya sebagai berikut:
- Tempat Anda menguji pemulihan penuh – karena Anda menguji pemulihan, bukan?
Orang lain (terutama kekuatan pemasaran raksasa yaitu Microsoft) mungkin telah meyakinkan Anda bahwa bentuk lain dari server sekunder cocok untuk DBCC cek. Misalnya:
- sekunder yang dapat dibaca AlwaysOn Availability Group;
- snapshot dari database yang dicerminkan;
- sebuah log dikirimkan sekunder;
- pencerminan SAN;
- atau variasi lainnya…
Sayangnya, ini tidak terjadi, dan tidak satu pun dari sekunder ini adalah tempat yang valid dan andal untuk melakukan pemeriksaan Anda sebagai alternatif dari yang utama. Hanya cadangan satu-untuk-satu yang dapat berfungsi sebagai salinan yang sebenarnya; hal lain yang bergantung pada hal-hal seperti aplikasi pencadangan log untuk mencapai status yang konsisten tidak akan mencerminkan masalah integritas pada bagian utama dengan andal.
Jadi, daripada mencoba membongkar pemeriksaan logis Anda ke sekunder dan tidak pernah melakukannya di primer, inilah yang saya sarankan:
- Pastikan Anda sering menguji pemulihan cadangan lengkap Anda. Dan tidak, ini tidak termasuk
COPY_ONLYcadangan dari sekunder AG, untuk alasan yang sama seperti di atas – itu hanya berlaku jika Anda baru saja memulai sekunder dengan pemulihan penuh. - Jalankan
DBCC CHECKDBsering bertentangan dengan penuh pulihkan, sebelum melakukan hal lain. Sekali lagi, memutar ulang catatan log pada titik ini akan membuat database ini tidak valid sebagai salinan asli dari sumber. - Jalankan
DBCC CHECKDBmelawan utama Anda, mungkin dipecah dengan cara yang disarankan Paul Randal, dan/atau pada jadwal yang lebih jarang, dan/atau menggunakanPHYSICAL_ONLYlebih sering daripada tidak. Ini dapat bergantung pada seberapa sering dan andal kinerja Anda (2). - Jangan pernah berasumsi bahwa cek terhadap sekunder sudah cukup. Bahkan dengan replika yang tepat dari database utama Anda, masih ada masalah fisik yang dapat terjadi pada subsistem I/O primer Anda yang tidak akan pernah menyebar ke sekunder.
- Selalu analisis
DBCCkeluaran. Hanya menjalankannya dan mengabaikannya, untuk memeriksanya dari beberapa daftar, sama membantunya dengan menjalankan pencadangan dan mengklaim keberhasilan tanpa pernah menguji bahwa Anda benar-benar dapat memulihkan cadangan itu saat diperlukan.
Eksperimen dengan tanda jejak 2549, 2562, dan 2566
Saya telah melakukan beberapa pengujian menyeluruh dari dua tanda jejak (2549 dan 2562) dan telah menemukan bahwa mereka dapat menghasilkan peningkatan kinerja yang substansial, namun Lonny melaporkan bahwa mereka tidak lagi diperlukan atau berguna. Jika Anda menggunakan 2016 atau yang lebih baru, lewati seluruh bagian ini . Jika Anda menggunakan versi yang lebih lama, kedua tanda jejak ini dijelaskan lebih detail di KB #2634571, tetapi pada dasarnya:
- Bendera Jejak 2549
- Ini mengoptimalkan proses checkdb dengan memperlakukan setiap file database individu sebagai berada pada disk dasar yang unik. Ini boleh digunakan jika database Anda memiliki satu file data, atau jika Anda tahu bahwa setiap file database sebenarnya berada di drive yang terpisah. Jika database Anda memiliki banyak file dan mereka berbagi satu spindel yang terpasang langsung, Anda harus berhati-hati dengan tanda pelacakan ini, karena hal ini dapat lebih berbahaya daripada menguntungkan.
PENTING :sql.sasquatch melaporkan regresi dalam perilaku bendera pelacakan ini di SQL Server 2014.
- Ini mengoptimalkan proses checkdb dengan memperlakukan setiap file database individu sebagai berada pada disk dasar yang unik. Ini boleh digunakan jika database Anda memiliki satu file data, atau jika Anda tahu bahwa setiap file database sebenarnya berada di drive yang terpisah. Jika database Anda memiliki banyak file dan mereka berbagi satu spindel yang terpasang langsung, Anda harus berhati-hati dengan tanda pelacakan ini, karena hal ini dapat lebih berbahaya daripada menguntungkan.
- Tandai Bendera 2562
- Tanda ini memperlakukan seluruh proses checkdb sebagai satu batch, dengan biaya penggunaan tempdb yang lebih tinggi (hingga 5% dari ukuran database).
- Menggunakan algoritme yang lebih baik untuk menentukan cara membaca halaman dari database, mengurangi pertentangan kunci (khusus untuk
DBCC_MULTIOBJECT_SCANNER). Perhatikan bahwa peningkatan khusus ini ada di jalur kode SQL Server 2012, jadi Anda akan mendapat manfaat darinya bahkan tanpa tanda jejak. Hal ini dapat menghindari kesalahan seperti:
Terjadi timeout saat menunggu latch:class 'DBCC_MULTIOBJECT_SCANNER'.
- Dua tanda jejak di atas tersedia dalam versi berikut:
- SQL Server 2008 Service Pack 2 Pembaruan Kumulatif 9+
(10.00.4330 -> 10.00.5499)SQL Server 2008 Service Pack 3 Pembaruan Kumulatif 4+
(10.00.5775+)Pembaruan Kumulatif SQL Server 2008 R2 RTM 11+
(10.50.1809 -> 10.50.2424)SQL Server 2008 R2 Paket Layanan 1 Pembaruan Kumulatif 4+
(10.50.2796 -> 10.50.3999)SQL Server 2008 R2 Paket Layanan 2
(10.50.4000+)SQL Server 2012, semua versi
(11.00.2100+) - Bendera Jejak 2566
- Jika Anda masih menggunakan SQL Server 2005, bendera pelacakan ini, yang diperkenalkan pada 2005 SP2 CU#9 (9.00.3282) (meskipun tidak didokumentasikan dalam artikel Pangkalan Pengetahuan Pembaruan Kumulatif, KB #953752), berupaya untuk memperbaiki kinerja yang buruk dari
DATA_PURITYpemeriksaan pada sistem berbasis x64. Pada satu titik, Anda dapat melihat detail lebih lanjut di KB #945770, tetapi tampaknya artikel tersebut dihapus dari situs dukungan Microsoft dan mesin WayBack. Bendera pelacakan ini seharusnya tidak diperlukan dalam versi SQL Server yang lebih modern, karena masalah pada prosesor kueri telah diperbaiki.
- Jika Anda masih menggunakan SQL Server 2005, bendera pelacakan ini, yang diperkenalkan pada 2005 SP2 CU#9 (9.00.3282) (meskipun tidak didokumentasikan dalam artikel Pangkalan Pengetahuan Pembaruan Kumulatif, KB #953752), berupaya untuk memperbaiki kinerja yang buruk dari
Jika Anda akan menggunakan salah satu tanda pelacakan ini, saya sangat menyarankan untuk menyetelnya di tingkat sesi menggunakan DBCC TRACEON bukan sebagai tanda pelacakan startup. Ini tidak hanya memungkinkan Anda untuk mematikannya tanpa harus memutar SQL Server, tetapi juga memungkinkan Anda untuk mengimplementasikannya hanya saat melakukan CHECKDB tertentu perintah, berbeda dengan operasi yang menggunakan jenis perbaikan apa pun.
Kurangi dampak I/O:optimalkan tempdb
DBCC CHECKDB dapat menggunakan tempdb secara berlebihan, jadi pastikan Anda merencanakan penggunaan sumber daya di sana. Ini biasanya merupakan hal yang baik untuk dilakukan dalam hal apapun. Untuk CHECKDB Anda ingin mengalokasikan ruang dengan benar ke tempdb; hal terakhir yang Anda inginkan adalah untuk CHECKDB kemajuan (dan operasi bersamaan lainnya) harus menunggu autogrow. Anda bisa mendapatkan ide untuk persyaratan menggunakan WITH ESTIMATEONLY , seperti yang dijelaskan Paulus di sini. Perlu diketahui bahwa perkiraannya bisa sangat rendah karena bug di SQL Server 2008 R2. Juga jika Anda menggunakan bendera jejak 2562 pastikan untuk mengakomodasi kebutuhan ruang tambahan.
Dan tentu saja, semua saran tipikal untuk mengoptimalkan tempdb di hampir semua sistem juga sesuai di sini:pastikan tempdb berada pada set cepat sendiri. spindel, pastikan ukurannya untuk mengakomodasi semua aktivitas bersamaan lainnya tanpa harus berkembang, pastikan Anda menggunakan jumlah file data yang optimal, dll. Beberapa sumber daya lain yang mungkin Anda pertimbangkan:
- Mengoptimalkan Kinerja tempdb (MSDN)
- Perencanaan Kapasitas untuk tempdb (MSDN)
- Mitos SQL Server DBA setiap hari:(12/30) tempdb harus selalu memiliki satu file data per inti prosesor
Kurangi dampak I/O:kendalikan snapshot
Untuk menjalankan CHECKDB , versi modern SQL Server akan mencoba membuat snapshot tersembunyi dari database Anda di drive yang sama (atau di semua drive jika file data Anda menjangkau beberapa drive). Anda tidak dapat mengontrol mekanisme ini, tetapi jika Anda ingin mengontrol di mana CHECKDB beroperasi, buat snapshot Anda sendiri terlebih dahulu (Edisi Perusahaan diperlukan) pada drive apa pun yang Anda suka, dan jalankan DBCC perintah terhadap snapshot. Dalam kedua kasus tersebut, Anda akan ingin menjalankan operasi ini selama waktu henti relatif, untuk meminimalkan aktivitas copy-on-write yang akan melalui snapshot. Dan Anda tidak ingin jadwal ini bentrok dengan operasi penulisan yang berat, seperti pemeliharaan indeks atau ETL.
Anda mungkin telah melihat saran untuk memaksa CHECKDB untuk dijalankan dalam mode offline menggunakan WITH TABLOCK pilihan. Saya sangat merekomendasikan menentang pendekatan ini. Jika database Anda digunakan secara aktif, memilih opsi ini hanya akan membuat pengguna frustrasi. Dan jika database tidak digunakan secara aktif, Anda tidak menghemat ruang disk dengan menghindari snapshot, karena tidak akan ada aktivitas copy-on-write untuk disimpan.
Kurangi dampak I/O:hindari kesalahan 665 / 1450 / 1452
Dalam beberapa kasus, Anda mungkin melihat salah satu kesalahan berikut:
Sistem operasi mengembalikan kesalahan 1450 (Sumber daya sistem tidak mencukupi untuk menyelesaikan layanan yang diminta.) ke SQL Server selama penulisan pada offset 0x[…] dalam file dengan pegangan 0x[…]. Ini biasanya kondisi sementara dan SQL Server akan terus mencoba ulang operasi. Jika kondisi terus berlanjut maka tindakan segera harus diambil untuk memperbaikinya.
Sistem operasi mengembalikan kesalahan 665(Operasi yang diminta tidak dapat diselesaikan karena keterbatasan sistem file) ke SQL Server selama penulisan pada offset 0x[…] dalam file '[file]'
Ada beberapa tips di sini untuk mengurangi risiko kesalahan ini selama CHECKDB operasi, dan mengurangi dampaknya secara umum – dengan beberapa perbaikan yang tersedia, tergantung pada sistem operasi Anda dan versi SQL Server:
- Kesalahan File Jarang:1450 atau 665 karena fragmentasi file:Perbaikan dan Solusi
- SQL Server melaporkan kesalahan sistem operasi 1450 atau 1452 atau 665 (mencoba lagi)
Mengurangi dampak CPU
DBCC CHECKDB multi-utas secara default (tetapi hanya di Edisi Perusahaan). Jika sistem Anda terikat CPU, atau Anda hanya ingin CHECKDB untuk menggunakan lebih sedikit CPU dengan biaya pengoperasian yang lebih lama, Anda dapat mempertimbangkan untuk mengurangi paralelisme dalam beberapa cara berbeda:
- Gunakan Resource Governor pada 2008 dan yang lebih baru, selama Anda menjalankan Edisi Perusahaan. Untuk menargetkan perintah DBCC saja untuk kumpulan sumber daya atau grup beban kerja tertentu, Anda harus menulis fungsi pengklasifikasi yang dapat mengidentifikasi sesi yang akan melakukan pekerjaan ini (mis. login tertentu atau job_id).
- Gunakan bendera Jejak 2528 untuk menonaktifkan paralelisme untuk
DBCC CHECKDB(sertaCHECKFILEGROUPdanCHECKTABLE). Bendera jejak 2528 dijelaskan di sini. Tentu saja ini hanya berlaku di Edisi Perusahaan, karena terlepas dari apa yang dikatakan Books Online saat ini, sebenarnyaCHECKDBtidak paralel dalam Edisi Standar. - Sementara
DBCCperintah itu sendiri tidak mendukungMAXDOP(setidaknya sebelum SQL Server 2014 SP2), itu menghormati pengaturan globalmax degree of parallelism. Mungkin bukan sesuatu yang akan saya lakukan dalam produksi kecuali saya tidak punya pilihan lain, tetapi ini adalah salah satu cara menyeluruh untuk mengontrolDBCCtertentu perintah jika Anda tidak dapat menargetkannya secara lebih eksplisit.
Kami telah meminta kontrol yang lebih baik atas jumlah CPU yang DBCC CHECKDB menggunakan, tetapi mereka telah berulang kali ditolak hingga SQL Server 2014 SP2. Jadi sekarang Anda dapat menambahkan WITH MAXDOP = n untuk perintah.
Temuan Saya
Saya ingin mendemonstrasikan beberapa teknik ini di lingkungan yang dapat saya kendalikan. Saya menginstal AdventureWorks2012, kemudian memperluasnya menggunakan skrip pembesar AW yang ditulis oleh Jonathan Kehayias (blog | @SQLPoolBoy), yang meningkatkan basis data hingga sekitar 7 GB. Kemudian saya menjalankan serangkaian CHECKDB perintah menentangnya, dan mengatur waktunya. Saya menggunakan DBCC CHECKDB vanilla biasa sendiri, maka semua perintah lain menggunakan WITH NO_INFOMSGS, ALL_ERRORMSGS . Kemudian empat pengujian dengan (a) tanpa tanda jejak, (b) 2549, (c) 2562, dan (d) keduanya 2549 dan 2562. Kemudian saya mengulangi keempat pengujian tersebut, tetapi menambahkan PHYSICAL_ONLY opsi, yang melewati semua pemeriksaan logis. Hasilnya (rata-rata lebih dari 10 uji coba) menunjukkan:
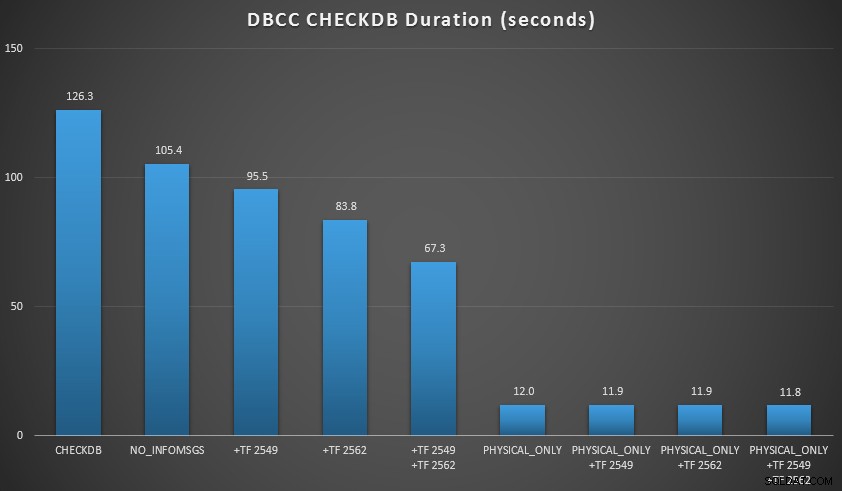
Hasil CHECKDB terhadap basis data 7 GB
Kemudian saya memperluas database lagi, membuat banyak salinan dari dua tabel yang diperbesar, yang mengarah ke ukuran database di utara 70 GB, dan menjalankan tes lagi. Hasilnya, sekali lagi rata-rata lebih dari 10 uji coba:
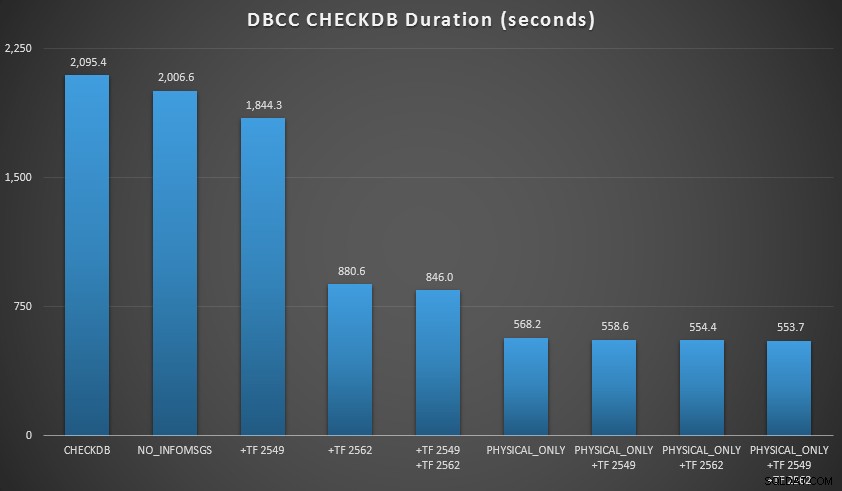
Hasil CHECKDB terhadap database 70 GB
Dalam dua skenario ini, saya telah mempelajari hal berikut (sekali lagi, ingatlah bahwa jarak tempuh Anda mungkin berbeda, dan bahwa Anda perlu melakukan pengujian sendiri untuk menarik kesimpulan yang berarti):
- Saat saya harus melakukan pemeriksaan logika:
- Pada ukuran database kecil,
NO_INFOMSGSopsi dapat memotong waktu pemrosesan secara signifikan ketika pemeriksaan dijalankan di SSMS. Namun, pada basis data yang lebih besar, manfaat ini berkurang, karena waktu dan pekerjaan yang dihabiskan untuk menyampaikan informasi menjadi bagian yang tidak signifikan dari keseluruhan durasi. 21 detik dari 2 menit sangat penting; 88 detik dari 35 menit, tidak terlalu banyak. - Dua tanda pelacakan yang saya uji memiliki dampak signifikan pada kinerja – menunjukkan pengurangan waktu proses sebesar 40-60% saat keduanya digunakan bersama.
- Pada ukuran database kecil,
- Ketika saya dapat mendorong pemeriksaan logis ke server sekunder (sekali lagi, dengan asumsi bahwa saya melakukan pemeriksaan logis di tempat lain terhadap salinan asli ):
- Saya dapat mengurangi waktu pemrosesan pada instans utama saya sebesar 70-90% dibandingkan dengan
CHECKDBstandar panggilan tanpa pilihan. - Dalam skenario saya, tanda pelacakan memiliki dampak yang sangat kecil pada durasi saat melakukan
PHYSICAL_ONLYcek.
- Saya dapat mengurangi waktu pemrosesan pada instans utama saya sebesar 70-90% dibandingkan dengan
Tentu saja, dan saya tidak bisa cukup menekankan hal ini, ini adalah basis data yang relatif kecil dan hanya digunakan agar saya dapat melakukan pengujian berulang dan terukur dalam waktu yang wajar. Server ini memiliki 80 CPU logis dan RAM 128 GB, dan saya adalah satu-satunya pengguna. Durasi dan interaksi dengan beban kerja lain pada sistem mungkin sedikit memengaruhi hasil ini. Berikut ini sekilas tentang penggunaan CPU pada umumnya, menggunakan SQL Sentry, selama salah satu CHECKDB operasi (dan tidak ada opsi yang benar-benar mengubah dampak keseluruhan pada CPU, hanya durasi):
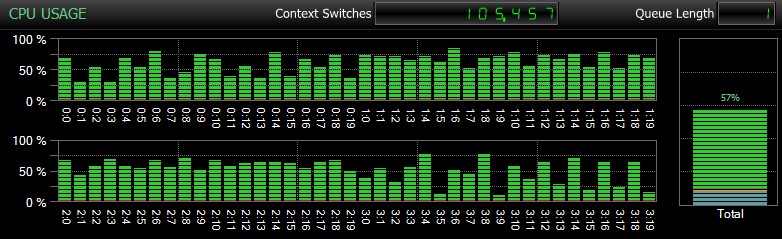
Dampak CPU selama CHECKDB – mode sampel
Dan ini adalah tampilan lain, menunjukkan profil CPU yang serupa untuk tiga contoh CHECKDB yang berbeda operasi dalam mode historis (saya telah melapisi deskripsi dari tiga sampel pengujian dalam rentang ini):
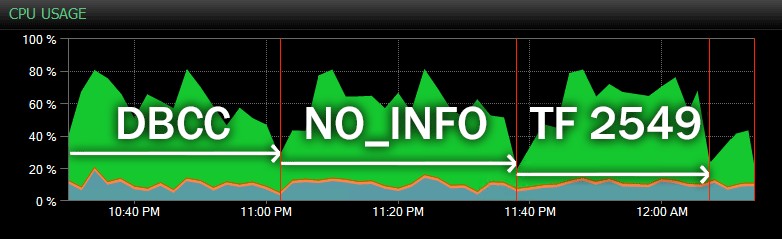
Dampak CPU selama CHECKDB – mode historis
Bahkan pada basis data yang lebih besar, yang dihosting di server yang lebih sibuk, Anda mungkin melihat efek yang berbeda, dan jarak tempuh Anda kemungkinan besar akan bervariasi. Jadi, lakukan uji tuntas Anda dan uji opsi ini dan lacak tanda selama beban kerja bersamaan yang umum sebelum memutuskan bagaimana Anda ingin mendekati CHECKDB .
Kesimpulan
DBCC CHECKDB adalah bagian yang sangat penting tetapi sering diremehkan dari tanggung jawab Anda sebagai DBA atau arsitek, dan penting untuk perlindungan data perusahaan Anda. Jangan anggap enteng tanggung jawab ini, dan lakukan yang terbaik untuk memastikan bahwa Anda tidak mengorbankan apa pun demi mengurangi dampak pada instans produksi Anda. Yang paling penting:lihat di luar lembar data pemasaran untuk memastikan Anda sepenuhnya memahami seberapa valid janji-janji itu dan apakah Anda bersedia mempertaruhkan data perusahaan Anda untuk itu. Melewatkan beberapa cek atau memindahkannya ke lokasi sekunder yang tidak valid bisa menjadi bencana yang menunggu untuk terjadi.
Anda juga harus mempertimbangkan untuk membaca artikel PSS ini:
- CHECKDB yang lebih cepat – Bagian I
- CHECKDB yang lebih cepat – Bagian II
- CHECKDB yang lebih cepat – Bagian III
- CHECKDB yang lebih cepat – Bagian IV (SQL CLR UDTs)
Dan postingan ini dari Brent Ozar:
- 3 Cara Menjalankan DBCC CHECKDB Lebih Cepat
Terakhir, jika Anda memiliki pertanyaan yang belum terselesaikan tentang DBCC CHECKDB , posting ke tag hash #sqlhelp di twitter. Paul sering memeriksa tag itu dan, karena fotonya akan muncul di artikel utama Books Online, kemungkinan jika ada yang bisa menjawabnya, dia bisa. Jika terlalu rumit untuk 140 karakter, Anda dapat bertanya di sini (dan saya akan memastikan Paul melihatnya di beberapa titik), atau memposting ke situs forum seperti Database Administrators Stack Exchange.