Pertimbangkan kueri AdventureWorks berikut yang mengembalikan ID transaksi tabel riwayat untuk ID produk 421:
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
Pengoptimal kueri dengan cepat menemukan rencana eksekusi yang efisien dengan perkiraan kardinalitas (jumlah baris) yang benar-benar tepat, seperti yang ditunjukkan di SQL Sentry Plan Explorer:

Sekarang katakanlah kita ingin menemukan ID transaksi riwayat untuk produk AdventureWorks bernama "Metal Plate 2". Ada banyak cara untuk mengekspresikan kueri ini dalam T-SQL. Salah satu formulasi alami adalah:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Rencana eksekusi adalah sebagai berikut:
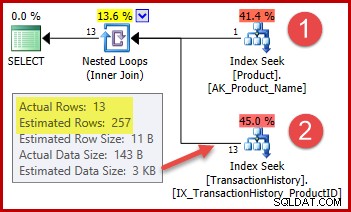
Strateginya adalah:
- Cari ID produk di tabel Produk dari nama yang diberikan
- Temukan baris untuk ID produk tersebut di tabel Riwayat
Perkiraan jumlah baris untuk langkah 1 sangat tepat karena indeks yang digunakan dinyatakan unik dan dikunci hanya pada nama produk. Oleh karena itu, uji kesetaraan pada "Pelat Logam 2" dijamin menghasilkan tepat satu baris (atau nol baris jika kami menetapkan nama produk yang tidak ada).
Perkiraan 257 baris yang disorot untuk langkah kedua kurang akurat:hanya 13 baris yang benar-benar ditemukan. Perbedaan ini muncul karena pengoptimal tidak mengetahui ID produk tertentu mana yang dikaitkan dengan produk bernama "Pelat Logam 2". Ini memperlakukan nilai sebagai tidak diketahui, menghasilkan perkiraan kardinalitas menggunakan informasi kepadatan rata-rata. Perhitungan menggunakan elemen dari objek statistik yang ditunjukkan di bawah ini:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
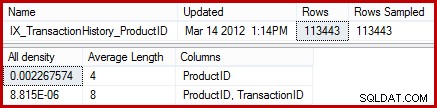
Statistik menunjukkan tabel berisi 113443 baris dengan 441 ID produk unik (1 / 0,002267574 =441). Dengan asumsi distribusi baris di seluruh ID produk seragam, estimasi kardinalitas mengharapkan ID produk cocok (113443 / 441) =rata-rata 257,24 baris. Ternyata, distribusinya tidak terlalu seragam; hanya ada 13 baris untuk produk "Pelat Logam 2".
Selain
Anda mungkin berpikir bahwa perkiraan 257 baris seharusnya lebih akurat. Misalnya, mengingat ID produk dan nama keduanya dibatasi untuk menjadi unik, SQL Server dapat secara otomatis mempertahankan informasi tentang hubungan satu-ke-satu ini. Kemudian akan diketahui bahwa "Pelat Logam 2" dikaitkan dengan ID produk 479, dan menggunakan wawasan itu untuk menghasilkan perkiraan yang lebih akurat menggunakan histogram ID Produk:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
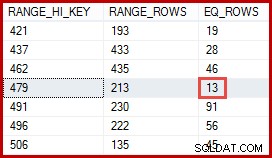
Perkiraan 13 baris yang diturunkan dengan cara ini akan benar-benar tepat. Namun demikian, perkiraan 257 baris bukanlah hal yang tidak masuk akal, mengingat informasi statistik yang tersedia dan asumsi penyederhanaan normal (seperti distribusi seragam) yang diterapkan oleh estimasi kardinalitas saat ini. Perkiraan yang tepat selalu bagus, tetapi perkiraan yang "masuk akal" juga dapat diterima.
Menggabungkan dua kueri
Katakanlah sekarang kita ingin melihat semua ID riwayat transaksi dengan ID produk 421 ATAU nama produknya adalah "Plat Logam 2". Cara alami untuk menggabungkan dua kueri sebelumnya adalah:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Rencana eksekusi sedikit lebih kompleks sekarang, tetapi masih mengandung elemen yang dapat dikenali dari rencana predikat tunggal:
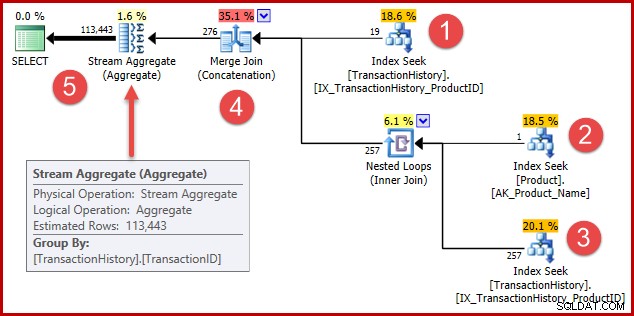
Strateginya adalah:
- Temukan catatan riwayat untuk produk 421
- Cari id produk untuk produk bernama "Metal Plate 2"
- Temukan catatan riwayat untuk id produk yang ditemukan di langkah 2
- Gabungkan baris dari langkah 1 &3
- Hapus duplikat apa pun (karena produk 421 mungkin juga yang bernama "Pelat Logam 2")
Langkah 1 sampai 3 sama persis seperti sebelumnya. Estimasi yang sama dihasilkan untuk alasan yang sama. Langkah 4 baru, tetapi sangat sederhana:langkah ini menggabungkan 19 baris yang diharapkan dengan 257 baris yang diharapkan, untuk memberikan perkiraan 276 baris.
Langkah 5 adalah yang menarik. Agregat Aliran yang menghapus duplikat memiliki perkiraan input 276 baris dan perkiraan output 113443 baris. Agregat yang menghasilkan lebih banyak baris daripada yang diterima tampaknya tidak mungkin, bukan?
* Anda akan melihat perkiraan 102099 baris di sini jika Anda menggunakan model perkiraan kardinalitas pra-2014.
Bug Estimasi Kardinalitas
Estimasi Agregat Aliran yang tidak mungkin dalam contoh kita disebabkan oleh bug dalam estimasi kardinalitas. Ini adalah contoh yang menarik sehingga kami akan menjelajahinya dengan sedikit detail.
Penghapusan Subkueri
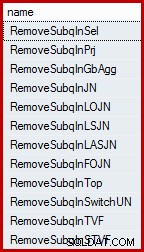
Anda mungkin terkejut mengetahui bahwa pengoptimal kueri SQL Server tidak bekerja dengan subkueri secara langsung. Mereka dihapus dari pohon kueri logis di awal proses kompilasi, dan diganti dengan konstruksi setara yang disiapkan oleh pengoptimal untuk bekerja dengan dan alasan. Pengoptimal memiliki sejumlah aturan yang menghapus subkueri. Ini dapat didaftar berdasarkan nama menggunakan kueri berikut (DMV yang direferensikan didokumentasikan secara minimal, tetapi tidak didukung):
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
Hasil (pada SQL Server 2014):
Kueri pengujian gabungan memiliki dua predikat ("pilihan" dalam istilah relasional) pada tabel riwayat, dihubungkan dengan OR . Salah satu predikat ini termasuk subquery. Seluruh subpohon (predikat dan subkueri) ditransformasikan oleh aturan pertama dalam daftar ("hapus subkueri dalam pilihan") menjadi semi-gabung atas penyatuan predikat individu. Meskipun tidak mungkin untuk merepresentasikan hasil transformasi internal ini dengan tepat menggunakan sintaks T-SQL, ini hampir sama dengan:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); Sangat disayangkan bahwa pendekatan T-SQL saya tentang pohon internal setelah penghapusan subquery berisi subquery, tetapi dalam bahasa prosesor kueri tidak (ini adalah semi join). Jika Anda lebih suka melihat formulir internal mentah daripada upaya saya pada T-SQL yang setara, yakinlah bahwa itu akan segera tersedia.
Petunjuk kueri tidak berdokumen yang termasuk dalam T-SQL di atas adalah untuk mencegah transformasi selanjutnya bagi Anda yang ingin melihat logika yang diubah dalam bentuk rencana eksekusi. Anotasi di bawah ini menunjukkan posisi dua predikat setelah transformasi:
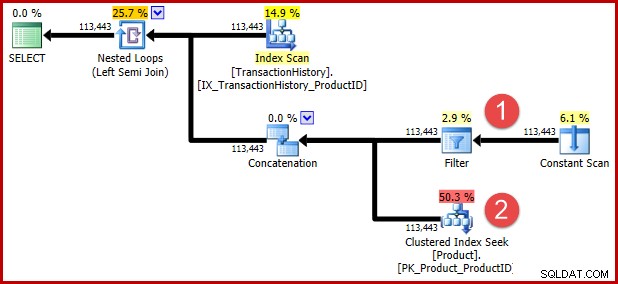
Intuisi di balik transformasi adalah bahwa baris riwayat memenuhi syarat jika salah satu predikat terpenuhi. Terlepas dari seberapa membantu Anda menemukan perkiraan ilustrasi T-SQL dan rencana eksekusi saya, saya harap setidaknya cukup jelas bahwa penulisan ulang mengungkapkan persyaratan yang sama dengan kueri asli.
Saya harus menekankan bahwa pengoptimal tidak benar-benar menghasilkan sintaks T-SQL alternatif atau menghasilkan rencana eksekusi lengkap pada tahap menengah. T-SQL dan representasi rencana eksekusi di atas dimaksudkan semata-mata untuk membantu pemahaman. Jika Anda tertarik dengan detail mentahnya, representasi internal yang dijanjikan dari pohon kueri yang diubah (sedikit diedit untuk kejelasan/ruang) adalah:
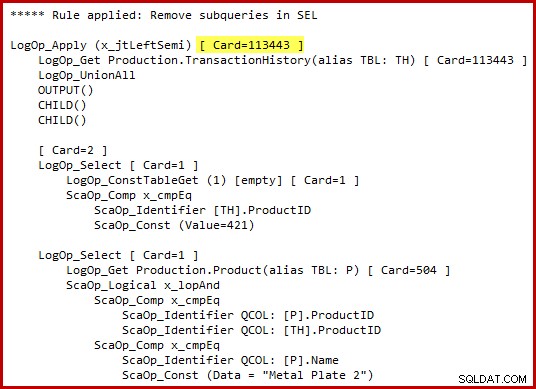
Perhatikan yang disorot, terapkan perkiraan kardinalitas semi gabung. Ini adalah 113443 baris saat menggunakan penaksir kardinalitas 2014 (102099 baris jika menggunakan CE lama). Ingatlah bahwa tabel riwayat AdventureWorks berisi total 113443 baris, jadi ini mewakili selektivitas 100% (90% untuk CE lama).
Kita telah melihat sebelumnya bahwa menerapkan salah satu dari predikat ini saja menghasilkan hanya sedikit kecocokan:19 baris untuk ID produk 421, dan 13 baris (diperkirakan 257) untuk "Pelat Logam 2". Memperkirakan bahwa disjungsi (OR) dari dua predikat akan mengembalikan semua baris di tabel dasar tampaknya sepenuhnya gila.
Detail Bug
Detail perhitungan selektivitas untuk semi join hanya terlihat di SQL Server 2014 saat menggunakan penaksir kardinalitas baru dengan bendera jejak (tidak terdokumentasi) 2363. Mungkin mungkin untuk melihat sesuatu yang mirip dengan Peristiwa yang Diperpanjang, tetapi keluaran bendera jejak lebih nyaman untuk digunakan di sini. Bagian output yang relevan ditunjukkan di bawah ini:
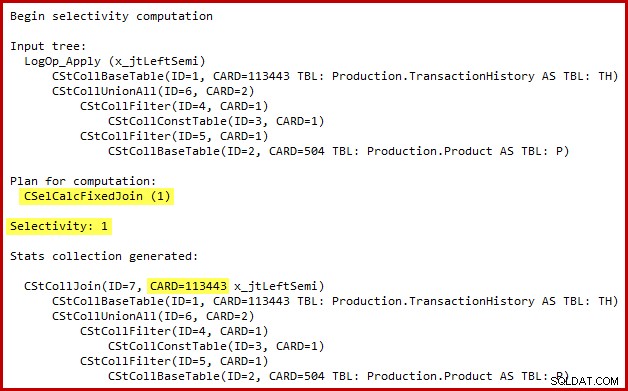
Penaksir kardinalitas menggunakan kalkulator Gabung Tetap dengan selektivitas 100%. Akibatnya, perkiraan kardinalitas keluaran dari semi join sama dengan masukannya, artinya semua 113443 baris dari tabel riwayat diharapkan memenuhi syarat.
Sifat yang tepat dari bug adalah bahwa perhitungan selektivitas semi-join melewatkan predikat apa pun yang diposisikan di luar gabungan semua di pohon input. Pada ilustrasi di bawah ini, kurangnya predikat pada semi join itu sendiri berarti setiap baris akan lolos; itu mengabaikan efek predikat di bawah rangkaian (serikat semua).
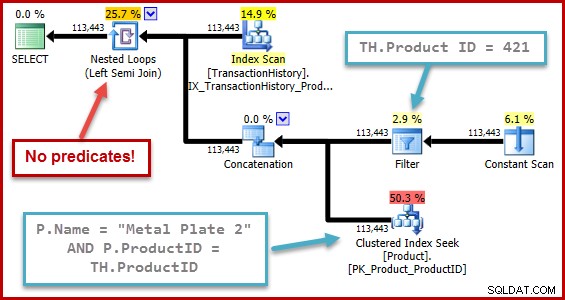
Perilaku ini semakin mengejutkan ketika Anda mempertimbangkan bahwa komputasi selektivitas beroperasi pada representasi pohon yang dihasilkan oleh pengoptimal itu sendiri (bentuk pohon dan pemosisian predikat adalah hasil dari penghapusan subkueri).
Masalah serupa terjadi dengan penaksir kardinalitas pra-2014, tetapi perkiraan akhir malah ditetapkan pada 90% dari perkiraan input semi-gabungan (untuk alasan menghibur terkait dengan perkiraan predikat 10% tetap terbalik yang terlalu banyak pengalihan untuk didapatkan ke dalam).
Contoh
Seperti disebutkan di atas, bug ini bermanifestasi ketika estimasi dilakukan untuk semi join dengan predikat terkait yang diposisikan di luar union all. Apakah pengaturan internal ini terjadi selama optimasi query tergantung pada sintaks T-SQL asli dan urutan yang tepat dari operasi optimasi internal. Contoh berikut menunjukkan beberapa kasus di mana bug terjadi dan tidak terjadi:
Contoh 1
Contoh pertama ini menggabungkan perubahan sepele pada kueri pengujian:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Perkiraan rencana eksekusi adalah:
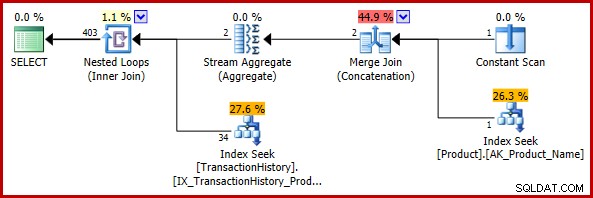
Estimasi akhir dari 403 baris tidak konsisten dengan estimasi input join loop bersarang, tetapi masih merupakan estimasi yang masuk akal (dalam pengertian yang dibahas sebelumnya). Jika bug ditemukan, perkiraan akhir adalah 113443 baris (atau 102099 baris saat menggunakan model CE pra-2014).
Contoh 2
Jika Anda akan terburu-buru dan menulis ulang semua perbandingan konstan Anda sebagai subquery sepele untuk menghindari bug ini, lihat apa yang terjadi jika kita membuat perubahan sepele lainnya, kali ini mengganti uji kesetaraan di predikat kedua dengan IN. Arti dari kueri tetap tidak berubah:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Bug kembali:
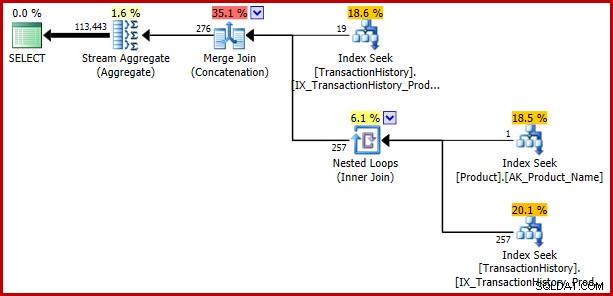
Contoh 3
Meskipun artikel ini sejauh ini berkonsentrasi pada predikat disjungtif yang berisi subkueri, contoh berikut menunjukkan bahwa spesifikasi kueri yang sama yang diekspresikan menggunakan EXISTS dan UNION ALL juga rentan:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); Rencana eksekusi:
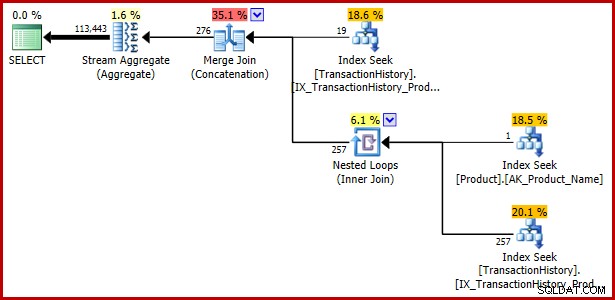
Contoh 4
Berikut adalah dua cara lagi untuk mengekspresikan kueri logis yang sama di T-SQL:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; Tidak ada kueri yang menemukan bug, dan keduanya menghasilkan rencana eksekusi yang sama:
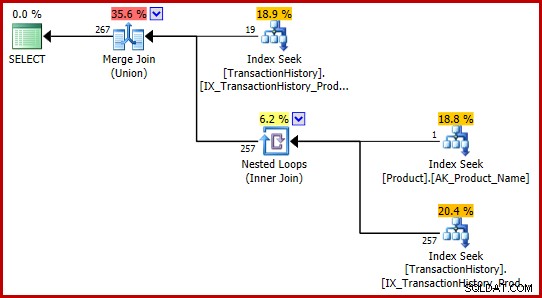
Formulasi T-SQL ini menghasilkan rencana eksekusi dengan perkiraan yang sepenuhnya konsisten (dan masuk akal).
Contoh 5
Anda mungkin bertanya-tanya apakah estimasi yang tidak akurat itu penting. Dalam kasus-kasus yang disajikan sejauh ini, tidak, setidaknya tidak secara langsung. Masalah muncul ketika bug terjadi dalam kueri yang lebih besar, dan perkiraan yang salah memengaruhi keputusan pengoptimal di tempat lain. Sebagai contoh yang diperluas secara minimal, pertimbangkan untuk mengembalikan hasil kueri pengujian kami dalam urutan acak:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New Rencana eksekusi menunjukkan perkiraan yang salah mempengaruhi operasi selanjutnya. Misalnya, ini adalah dasar untuk pemberian memori yang disediakan untuk jenis:
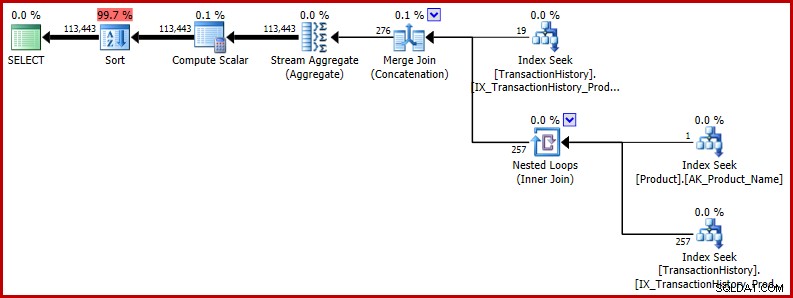
Jika Anda ingin melihat contoh nyata dari potensi dampak bug ini, lihat pertanyaan terbaru dari Richard Mansell di situs Tanya Jawab SQLPerformance.com, answer.SQLPerformance.com.
Ringkasan dan Pemikiran Akhir
Bug ini dipicu ketika pengoptimal melakukan estimasi kardinalitas untuk semi join, dalam keadaan tertentu. Ini adalah bug yang menantang untuk ditemukan dan diatasi karena sejumlah alasan:
- Tidak ada sintaks T-SQL eksplisit untuk menentukan semi join, jadi sulit untuk mengetahui sebelumnya apakah kueri tertentu akan rentan terhadap bug ini.
- Pengoptimal dapat memperkenalkan semi-gabung dalam berbagai keadaan, tidak semuanya jelas merupakan kandidat semi-gabung.
- Semi join yang bermasalah sering diubah menjadi sesuatu yang lain oleh aktivitas pengoptimal selanjutnya, jadi kami bahkan tidak dapat mengandalkan adanya operasi semi join dalam rencana eksekusi akhir.
- Tidak semua perkiraan kardinalitas yang tampak aneh disebabkan oleh bug ini. Memang, banyak contoh jenis ini merupakan efek samping yang diharapkan dan tidak berbahaya dari operasi pengoptimal normal.
- Estimasi selektivitas semi-gabungan yang salah akan selalu 90% atau 100% dari inputnya, tetapi ini biasanya tidak sesuai dengan kardinalitas tabel yang digunakan dalam rencana. Selanjutnya, kardinalitas input semi join yang digunakan dalam perhitungan bahkan mungkin tidak terlihat dalam rencana eksekusi akhir.
- Biasanya ada banyak cara untuk mengekspresikan kueri logis yang sama di T-SQL. Beberapa di antaranya akan memicu bug, sementara yang lain tidak.
Pertimbangan ini membuat sulit untuk menawarkan saran praktis untuk menemukan atau mengatasi bug ini. Tentu saja bermanfaat memeriksa rencana eksekusi untuk perkiraan "keterlaluan", dan menyelidiki kueri dengan kinerja yang jauh lebih buruk dari yang diharapkan, tetapi keduanya mungkin memiliki penyebab yang tidak terkait dengan bug ini. Yang mengatakan, ada baiknya memeriksa kueri yang menyertakan pemisahan predikat dan subkueri. Seperti yang ditunjukkan contoh dalam artikel ini, ini bukan satu-satunya cara untuk menemukan bug, tetapi saya berharap ini adalah bug yang umum.
Jika Anda cukup beruntung untuk menjalankan SQL Server 2014, dengan estimator kardinalitas baru diaktifkan, Anda mungkin dapat mengonfirmasi bug dengan memeriksa secara manual trace flag 2363 output untuk estimasi selektivitas 100% tetap pada semi join, tapi ini hampir tidak nyaman. Anda tidak akan ingin menggunakan tanda jejak tidak berdokumen pada sistem produksi, tentu saja.
Laporan bug Suara Pengguna untuk masalah ini dapat ditemukan di sini. Silakan pilih dan beri komentar jika Anda ingin masalah ini diselidiki (dan mungkin diperbaiki).