ANY agregat bukanlah sesuatu yang bisa kita tulis langsung di Transact SQL. Ini adalah satu-satunya fitur internal yang digunakan oleh pengoptimal kueri dan mesin eksekusi.
Saya pribadi sangat menyukai ANY agregat, jadi agak mengecewakan mengetahui bahwa itu rusak dengan cara yang cukup mendasar. Rasa khusus dari 'patah' yang saya maksud di sini adalah variasi hasil yang salah.
Dalam posting ini, saya melihat dua tempat tertentu di mana ANY agregat biasanya muncul, menunjukkan masalah hasil yang salah, dan menyarankan solusi jika perlu.
Untuk latar belakang pada ANY agregat, silakan lihat posting saya sebelumnya Rencana Kueri Tidak Berdokumen:Agregat APAPUN.
1. Satu baris per kueri grup
Ini harus menjadi salah satu persyaratan kueri paling umum hari ini, dengan solusi yang sangat terkenal. Anda mungkin menulis kueri semacam ini setiap hari, secara otomatis mengikuti pola, tanpa benar-benar memikirkannya.
Idenya adalah untuk memberi nomor pada set input baris menggunakan ROW_NUMBER fungsi jendela, dipartisi dengan pengelompokan kolom atau kolom. Itu dibungkus dalam Ekspresi Tabel Umum atau tabel turunan , dan disaring ke baris di mana nomor baris yang dihitung sama dengan satu. Sejak ROW_NUMBER restart pada satu untuk setiap grup, ini memberi kita satu baris yang diperlukan per grup.
Tidak ada masalah dengan pola umum itu. Jenis satu baris per kueri grup yang tunduk pada ANY masalah agregat adalah masalah di mana kita tidak peduli baris mana yang dipilih dari setiap grup.
Dalam hal ini, tidak jelas kolom mana yang harus digunakan dalam perintah ORDER BY klausa dari ROW_NUMBER fungsi jendela. Lagi pula, kami secara eksplisit tidak peduli baris mana yang dipilih. Salah satu pendekatan umum adalah menggunakan kembali PARTITION BY kolom di ORDER BY ayat. Di sinilah masalah mungkin terjadi.
Contoh
Mari kita lihat contoh menggunakan kumpulan data mainan:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
Persyaratannya adalah mengembalikan satu baris data lengkap dari setiap grup, di mana keanggotaan grup ditentukan oleh nilai di kolom c1 .

Mengikuti ROW_NUMBER pola, kita mungkin menulis kueri seperti berikut (perhatikan ORDER BY klausa dari ROW_NUMBER fungsi jendela cocok dengan PARTITION BY klausa):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Seperti yang disajikan, kueri ini berhasil dijalankan, dengan hasil yang benar. Hasilnya secara teknis non-deterministik karena SQL Server dapat secara valid mengembalikan salah satu baris di setiap grup. Namun demikian, jika Anda menjalankan kueri ini sendiri, kemungkinan besar Anda akan melihat hasil yang sama seperti yang saya lakukan:
Rencana eksekusi bergantung pada versi SQL Server yang digunakan, dan tidak bergantung pada tingkat kompatibilitas database.
Pada SQL Server 2014 dan sebelumnya, rencananya adalah:

Untuk SQL Server 2016 atau yang lebih baru, Anda akan melihat:

Kedua paket tersebut aman, tetapi untuk alasan yang berbeda. Urutan Berbeda paket berisi ANY agregat, tetapi Urutan Berbeda implementasi operator tidak memanifestasikan bug.
Paket SQL Server 2016+ yang lebih kompleks tidak menggunakan ANY agregat sama sekali. Urutkan menempatkan baris ke dalam urutan yang diperlukan untuk operasi penomoran baris. Segmen operator menetapkan bendera di awal setiap grup baru. Proyek Urutan menghitung nomor baris. Terakhir, Filter operator hanya meneruskan baris yang memiliki nomor baris terhitung satu.
Bug
Untuk mendapatkan hasil yang salah dengan kumpulan data ini, kita harus menggunakan SQL Server 2014 atau yang lebih lama, dan kode ANY agregat perlu diimplementasikan dalam Stream Aggregate atau Hash Aggregate operator (Alur Agregat Pencocokan Hash Berbeda tidak menghasilkan bug).
Salah satu cara untuk mendorong pengoptimal memilih Stream Aggregate bukannya Urutan Berbeda adalah menambahkan indeks berkerumun untuk menyediakan pemesanan menurut kolom c1 :
CREATE CLUSTERED INDEX c ON #Data (c1);
Setelah perubahan itu, rencana eksekusi menjadi:

ANY agregat terlihat di Properti jendela ketika Stream Aggregate operator dipilih:

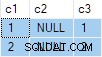
Hasil querynya adalah:
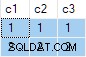
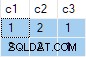
Ini salah . SQL Server telah mengembalikan baris yang tidak ada dalam sumber data. Tidak ada baris sumber di mana c2 = 1 dan c3 = 1 Misalnya. Sebagai pengingat, sumber datanya adalah:
Rencana eksekusi salah menghitung terpisah ANY agregat untuk c2 dan c3 kolom, mengabaikan nol. Setiap agregat secara independen mengembalikan non-null . pertama nilai yang ditemuinya, memberikan hasil di mana nilai untuk c2 dan c3 berasal dari baris sumber berbeda . Ini bukan yang diminta oleh spesifikasi kueri SQL asli.
Hasil salah yang sama dapat dihasilkan dengan atau tanpa indeks berkerumun dengan menambahkan OPTION (HASH GROUP) petunjuk untuk membuat rencana dengan Eager Hash Aggregate alih-alih Stream Aggregate .
Kondisi
Masalah ini hanya dapat terjadi jika beberapa ANY agregat hadir, dan data agregat berisi nol. Seperti yang disebutkan, masalah hanya memengaruhi Stream Aggregate dan Hash Aggregate operator; Urutan Berbeda dan Aliran Berbeda tidak terpengaruh.
SQL Server 2016 dan seterusnya berusaha untuk menghindari pengenalan beberapa ANY agregat untuk pola kueri penomoran satu baris per baris grup mana pun saat kolom sumber tidak dapat dibatalkan. Ketika ini terjadi, rencana eksekusi akan berisi Segmen , Proyek Urutan , dan Filter operator bukan agregat. Bentuk denah ini selalu aman, karena tidak ada ANY agregat digunakan.
Mereproduksi bug di SQL Server 2016+
Pengoptimal SQL Server tidak sempurna dalam mendeteksi ketika kolom awalnya dibatasi menjadi NOT NULL mungkin masih menghasilkan nilai antara nol melalui manipulasi data.
Untuk mereproduksi ini, kita akan mulai dengan tabel di mana semua kolom dideklarasikan sebagai NOT NULL :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
Kami dapat menghasilkan null dari kumpulan data ini dengan banyak cara, yang sebagian besar berhasil dideteksi oleh pengoptimal, jadi hindari memasukkan ANY agregat selama pengoptimalan.
Salah satu cara untuk menambahkan null yang kebetulan tidak terdeteksi ditunjukkan di bawah ini:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; Permintaan itu menghasilkan output berikut:
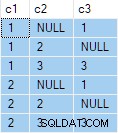
Langkah selanjutnya adalah menggunakan spesifikasi kueri tersebut sebagai data sumber untuk kueri standar “setiap satu baris per grup”:
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Di versi apa pun SQL Server, yang menghasilkan rencana berikut:
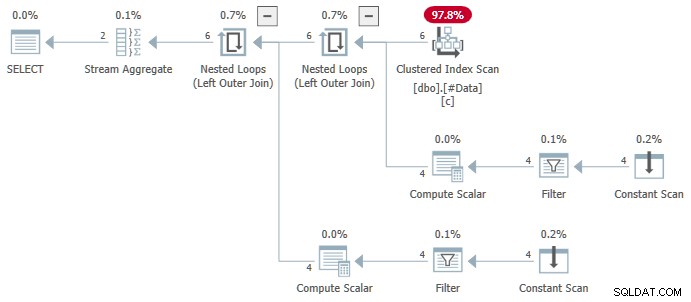
Agregat Aliran berisi beberapa ANY agregat, dan hasilnya salah . Tak satu pun dari baris yang dikembalikan muncul di kumpulan data sumber:
db<>demo online biola
Solusi
Satu-satunya solusi yang sepenuhnya dapat diandalkan hingga bug ini diperbaiki adalah dengan menghindari pola di mana ROW_NUMBER memiliki kolom yang sama di ORDER BY klausa seperti dalam PARTITION BY klausa.
Saat kita tidak peduli yang mana satu baris dipilih dari setiap grup, sayangnya ORDER BY klausa diperlukan sama sekali. Salah satu cara untuk menghindari masalah ini adalah dengan menggunakan konstanta waktu proses seperti ORDER BY @@SPID di fungsi jendela.
2. Pembaruan non-deterministik
Masalah dengan beberapa ANY agregat pada input nullable tidak terbatas pada satu baris per pola kueri grup. Pengoptimal kueri dapat memperkenalkan ANY internal internal agregat dalam beberapa keadaan. Salah satunya adalah pembaruan non-deterministik.
Sebuah non-deterministik update adalah di mana pernyataan tidak menjamin bahwa setiap baris target akan diperbarui paling banyak satu kali. Dengan kata lain, ada beberapa baris sumber untuk setidaknya satu baris target. Dokumentasi secara eksplisit memperingatkan tentang ini:
Berhati-hatilah saat menentukan klausa FROM untuk memberikan kriteria bagi operasi pembaruan.Hasil dari pernyataan UPDATE tidak terdefinisi jika pernyataan tersebut menyertakan klausa FROM yang tidak ditentukan sedemikian rupa sehingga hanya satu nilai yang tersedia untuk setiap kemunculan kolom yang diperbarui, yang adalah jika pernyataan UPDATE tidak deterministik.
Untuk menangani pembaruan non-deterministik, pengoptimal mengelompokkan baris menurut kunci (indeks atau RID) dan menerapkan ANY agregat ke kolom yang tersisa. Ide dasarnya adalah memilih satu baris dari beberapa kandidat, dan menggunakan nilai dari baris itu untuk melakukan pembaruan. Ada persamaan yang jelas dengan ROW_NUMBER sebelumnya masalah, jadi tidak mengherankan bahwa cukup mudah untuk mendemonstrasikan pembaruan yang salah.
Tidak seperti edisi sebelumnya, SQL Server saat ini tidak mengambil langkah khusus untuk menghindari beberapa ANY agregat pada kolom nullable saat melakukan pembaruan non-deterministik. Oleh karena itu, berikut ini terkait dengan semua versi SQL Server , termasuk SQL Server 2019 CTP 3.0.
Contoh
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>demo online biola
Logikanya, pembaruan ini harus selalu menghasilkan kesalahan:Tabel target tidak mengizinkan nol di kolom mana pun. Baris mana pun yang cocok dipilih dari tabel sumber, upaya untuk memperbarui kolom c2 atau c3 ke nol harus terjadi.
Sayangnya, pembaruan berhasil, dan status akhir tabel target tidak konsisten dengan data yang diberikan:
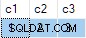
Saya telah melaporkan ini sebagai bug. Solusinya adalah menghindari penulisan UPDATE yang tidak deterministik pernyataan, jadi ANY agregat tidak diperlukan untuk menyelesaikan ambiguitas.
Seperti disebutkan, SQL Server dapat memperkenalkan ANY agregat dalam keadaan lebih dari dua contoh yang diberikan di sini. Jika ini terjadi saat kolom gabungan berisi nol, ada potensi hasil yang salah.