Penyorotan hit adalah fitur yang banyak orang berharap Pencarian Teks Lengkap SQL Server akan mendukung secara asli. Di sinilah Anda dapat mengembalikan seluruh dokumen (atau kutipan) dan menunjukkan kata atau frasa yang membantu mencocokkan dokumen itu dengan pencarian. Melakukannya dengan cara yang efisien dan akurat bukanlah tugas yang mudah, seperti yang saya temukan secara langsung.
Sebagai contoh penyorotan hit:saat Anda melakukan penelusuran di Google atau Bing, Anda mendapatkan kata kunci yang dicetak tebal baik pada judul maupun kutipan (klik salah satu gambar untuk memperbesar):

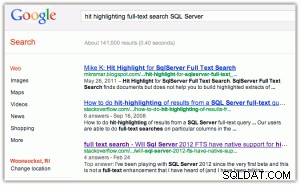
[Selain itu, saya menemukan dua hal yang lucu di sini:(1) bahwa Bing lebih menyukai properti Microsoft daripada Google, dan (2) bahwa Bing berusaha mengembalikan 2,2 juta hasil, banyak di antaranya mungkin tidak relevan.]
Kutipan ini biasanya disebut "cuplikan" atau "peringkasan yang bias kueri". Kami telah meminta fungsi ini di SQL Server untuk beberapa waktu, tetapi belum mendengar kabar baik dari Microsoft:
- Connect #295100 :Ringkasan pencarian teks lengkap (hit-highlighting)
- Hubungkan #722324 :Akan lebih baik jika Pencarian Teks Lengkap SQL menyediakan dukungan cuplikan / penyorotan
Pertanyaan juga muncul di Stack Overflow dari waktu ke waktu:
- Cara melakukan penyorotan hasil dari kueri teks lengkap SQL Server
- Apakah Sql Server 2012 FTS memiliki dukungan asli untuk penyorotan hit?
Ada beberapa solusi parsial. Skrip dari Mike Kramar ini, misalnya, akan menghasilkan ekstrak yang disorot, tetapi tidak menerapkan logika yang sama (seperti pemecah kata khusus bahasa) ke dokumen itu sendiri. Itu juga menggunakan jumlah karakter absolut, sehingga kutipan dapat dimulai dan diakhiri dengan kata-kata parsial (seperti yang akan saya tunjukkan segera). Yang terakhir ini cukup mudah untuk diperbaiki, tetapi masalah lainnya adalah ia memuat seluruh dokumen ke dalam memori, daripada melakukan streaming apa pun. Saya menduga bahwa dalam indeks teks lengkap dengan ukuran dokumen besar, ini akan menjadi hit kinerja yang nyata. Untuk saat ini saya akan fokus pada ukuran dokumen rata-rata yang relatif kecil (35 KB).
Contoh sederhana
Jadi katakanlah kita memiliki tabel yang sangat sederhana, dengan indeks teks lengkap yang ditentukan:
BUAT KATALOG FULLTEXT [FTSDemo];BUKA TABEL [dbo].[Document]( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Date] DATE NOT NULL , [Title] NVARCHAR(200) NOT NULL, [Content] NVARCHAR(MAX) NOT NULL, CONSTRAINT PK_DOCUMENT PRIMARY KEY(ID));GO CREATE FULLTEXT INDEX ON [dbo].[Document]( [Content] LANGUAGE [English] , [Title] LANGUAGE [English])KEY INDEX [PK_Document] ON ([FTSDemo]);
Tabel ini diisi dengan beberapa dokumen (khususnya, 7), seperti Deklarasi Kemerdekaan, dan pidato Nelson Mandela "Saya siap mati". Penelusuran teks lengkap yang khas terhadap tabel ini mungkin:
SELECT d.Title, d.[Content]FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID =t.[KEY] ORDER OLEH [PERINGKAT] DESC;
Hasilnya mengembalikan 4 baris dari 7:

Sekarang menggunakan fungsi UDF seperti Mike Kramar:
SELECT d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80)FROM dbo.[Document] AS dINNER JOIN CONTAINSTABLE(dbo.[Document] ], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;
Hasilnya menunjukkan cara kerja kutipan:a <SPAN> tag disuntikkan pada kata kunci pertama, dan kutipan diukir berdasarkan offset dari posisi itu (tanpa pertimbangan untuk menggunakan kata-kata lengkap):

(Sekali lagi, ini adalah sesuatu yang dapat diperbaiki, tetapi saya ingin memastikan bahwa saya mewakili dengan benar apa yang ada di luar sana sekarang.)
ThinkHighlight
Eran Meyuchas dari Interactive Thoughts telah mengembangkan komponen yang memecahkan banyak masalah ini. ThinkHighlight diimplementasikan sebagai CLR Assembly dengan dua fungsi bernilai skalar CLR:
(Anda juga akan melihat UDF Mike Kramar dalam daftar fungsi.)
Sekarang, tanpa masuk ke semua detail tentang menginstal dan mengaktifkan perakitan di sistem Anda, berikut adalah bagaimana kueri di atas akan diwakili dengan ThinkHighlight:
SELECT d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Document] SEBAGAI DINNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY t.[RANK] DESC; Hasilnya menunjukkan bagaimana kata kunci yang paling relevan disorot, dan kutipan diambil dari kata-kata tersebut berdasarkan kata-kata lengkap dan offset dari istilah yang disorot:

Beberapa keuntungan tambahan yang belum saya tunjukkan di sini termasuk kemampuan untuk memilih strategi peringkasan yang berbeda, mengendalikan presentasi setiap kata kunci (daripada semua) menggunakan CSS unik, serta dukungan untuk banyak bahasa dan bahkan dokumen dalam format biner (kebanyakan IFilter didukung).
Hasil kinerja
Awalnya saya menguji metrik runtime untuk tiga kueri menggunakan SQL Sentry Plan Explorer, terhadap tabel 7 baris. Hasilnya adalah:

Selanjutnya saya ingin melihat bagaimana mereka akan membandingkan pada ukuran data yang jauh lebih besar. Saya memasukkan tabel ke dalam dirinya sendiri sampai saya berada di 4.000 baris, lalu menjalankan kueri berikut:
SET STATISTICS TIME ON;GO SELECT /* FTS */ d.Title, d.[Content]FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;GO SELECT /* UDF */ d.Title, Excerpt =dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 100)FROM dbo.[Document] AS dINNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY [RANK] DESC;GO SELECT / * ThinkHighlight */ d.Title, Excerpt =dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1), 'top-fragment', 100, d.ID)FROM dbo. [Document] AS DINNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS tON d.ID =t.[KEY]ORDER BY t.[RANK] DESC;GO SET STATISTICS TIME OFF;PERGI
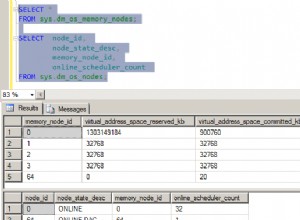
Saya juga memantau sys.dm_exec_memory_grants saat kueri sedang berjalan, untuk mengetahui perbedaan dalam pemberian memori. Hasil rata-rata lebih dari 10 kali:
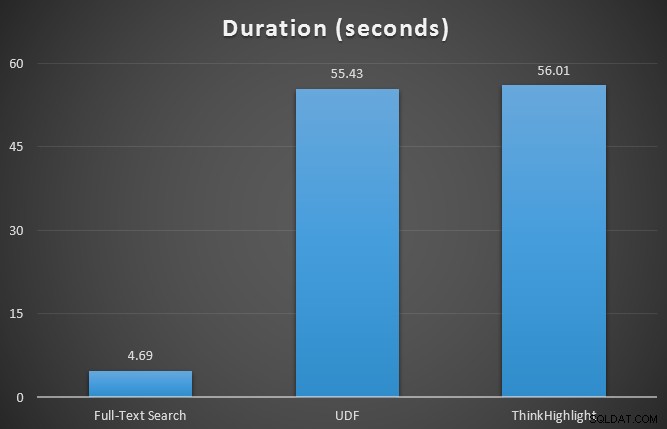
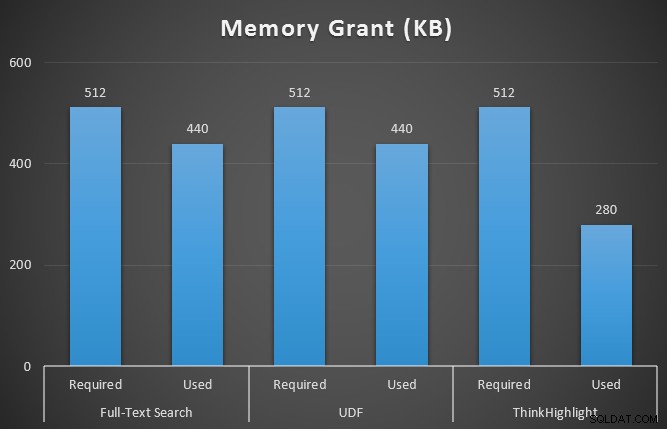
Sementara kedua opsi penyorotan hit menimbulkan penalti yang signifikan karena tidak menyorot sama sekali, solusi ThinkHighlight – dengan opsi yang lebih fleksibel – mewakili biaya tambahan yang sangat marjinal dalam hal durasi (~1%), sementara menggunakan memori yang jauh lebih sedikit (36%) daripada varian UDF.
Kesimpulan
Seharusnya tidak mengejutkan bahwa penyorotan hit adalah operasi yang mahal, dan berdasarkan kompleksitas dari apa yang harus didukung (pikirkan banyak bahasa), sangat sedikit solusi yang ada di luar sana. Saya pikir Mike Kramar telah melakukan pekerjaan yang sangat baik dalam menghasilkan UDF dasar yang memberi Anda cara yang baik untuk memecahkan masalah, tetapi saya terkejut menemukan penawaran komersial yang lebih kuat – dan ternyata sangat stabil, bahkan dalam bentuk beta. Saya memang berencana untuk melakukan tes yang lebih menyeluruh menggunakan ukuran dan jenis dokumen yang lebih luas. Sementara itu, jika penyorotan hit adalah bagian dari persyaratan aplikasi Anda, Anda harus mencoba UDF Mike Kramar dan mempertimbangkan untuk menggunakan ThinkHighlight untuk uji coba.