Beberapa minggu yang lalu tim SQLskills berada di Tampa untuk Performance Tuning Immersion Event (IE2) kami dan saya sedang meliput baseline. Baseline adalah topik yang dekat dan dekat dengan hati saya, karena sangat berharga karena berbagai alasan. Dua dari alasan tersebut, yang selalu saya kemukakan baik mengajar atau bekerja dengan klien, adalah menggunakan baseline untuk memecahkan masalah kinerja, dan kemudian juga tren penggunaan dan memberikan perkiraan perencanaan kapasitas. Namun mereka juga penting saat Anda melakukan penyetelan atau pengujian kinerja – baik menurut Anda metrik kinerja yang ada sebagai dasar atau tidak.
Selama modul, saya meninjau berbagai sumber data seperti Monitor Kinerja, DMV, dan data lacak atau XE, dan muncul pertanyaan terkait dengan pemuatan data. Secara khusus, pertanyaannya adalah apakah lebih baik memuat data ke dalam tabel tanpa indeks, dan kemudian membuatnya setelah selesai, dibandingkan memiliki indeks selama pemuatan data. Tanggapan saya adalah, “Biasanya, ya". Pengalaman pribadi saya adalah bahwa hal ini selalu terjadi, tetapi Anda tidak pernah tahu peringatan atau skenario satu kali yang mungkin dialami seseorang di mana perubahan kinerja tidak seperti yang diharapkan, dan seperti semua pertanyaan kinerja, Anda tidak akan tahu pasti sampai Anda mengujinya. Sampai Anda menetapkan dasar untuk satu metode dan kemudian melihat apakah metode lain meningkatkan pada dasar itu, Anda hanya menebak. Saya pikir akan menyenangkan untuk menguji skenario ini, tidak hanya untuk membuktikan apa yang saya harapkan menjadi kenyataan, tetapi juga untuk menunjukkan metrik apa yang akan saya periksa, mengapa, dan bagaimana menangkapnya. Jika Anda telah melakukan pengujian kinerja sebelumnya, ini mungkin cara lama. Tetapi bagi mereka Anda yang baru berlatih, saya akan mengikuti proses yang saya ikuti untuk membantu Anda memulai. Sadarilah bahwa ada banyak cara untuk mendapatkan jawaban atas, “Metode mana yang lebih baik?” Saya berharap Anda akan mengambil proses ini, mengubahnya, dan menjadikannya milik Anda seiring waktu.
Apa yang Anda Coba Buktikan?
Langkah pertama adalah memutuskan dengan tepat apa yang Anda uji. Dalam kasus kami ini lurus ke depan:apakah lebih cepat memuat data ke tabel kosong, lalu menambahkan indeks, atau lebih cepat memiliki indeks di atas meja selama pemuatan data? Tapi, kita bisa menambahkan beberapa variasi di sini jika kita mau. Pertimbangkan waktu yang diperlukan untuk memuat data ke dalam heap, lalu buat indeks berkerumun dan tidak berkerumun, versus waktu yang diperlukan untuk memuat data ke dalam indeks berkerumun, lalu buat indeks yang tidak berkerumun. Apakah ada perbedaan kinerja? Apakah kunci pengelompokan menjadi faktor? Saya berharap bahwa pemuatan data akan menyebabkan indeks nonclustered yang ada menjadi terfragmentasi, jadi mungkin saya ingin melihat apa dampak membangun kembali indeks setelah pemuatan terhadap total durasi. Sangat penting untuk melingkupi langkah ini sebanyak mungkin, dan sangat spesifik tentang apa yang ingin Anda ukur, karena ini akan menentukan data apa yang Anda ambil. Untuk contoh kami, empat pengujian kami adalah:
Uji 1: Muat data ke dalam heap, buat indeks berkerumun, buat indeks tidak berkerumun
Uji 2: Muat data ke dalam indeks berkerumun, buat indeks yang tidak berkerumun
Uji 3: Buat clustered index dan nonclustered index, load data
Uji 4: Membuat indeks berkerumun dan indeks tidak berkerumun, memuat data, membangun kembali indeks tidak berkerumun
Apa yang Perlu Anda Ketahui?
Dalam skenario kami, pertanyaan utama kami adalah "metode apa yang tercepat"? Oleh karena itu, kami ingin mengukur durasi dan untuk melakukannya kami perlu menangkap waktu mulai dan waktu berakhir. Kita bisa membiarkannya begitu saja, tetapi kita mungkin ingin memahami seperti apa pemanfaatan sumber daya untuk setiap metode, atau mungkin kita ingin mengetahui waktu tunggu tertinggi, atau jumlah transaksi, atau jumlah kebuntuan. Data yang paling menarik dan relevan akan bergantung pada proses apa yang Anda bandingkan. Menangkap jumlah transaksi tidak begitu menarik untuk beban data kami; tetapi untuk perubahan kode mungkin saja. Karena kami membuat indeks dan membangunnya kembali, saya tertarik pada berapa banyak IO yang dihasilkan setiap metode. Meskipun durasi keseluruhan mungkin merupakan faktor penentu pada akhirnya, melihat IO mungkin berguna untuk tidak hanya memahami opsi apa yang menghasilkan IO paling banyak, tetapi juga apakah penyimpanan database berkinerja seperti yang diharapkan.
Di Mana Data yang Anda Butuhkan?
Setelah Anda menentukan data apa yang Anda butuhkan, putuskan dari mana akan diambil. Kami tertarik dengan durasi, jadi kami ingin mencatat waktu setiap pengujian beban data dimulai, dan kapan berakhir. Kami juga tertarik dengan IO, dan kami dapat menarik data ini dari beberapa lokasi – penghitung Monitor Kinerja dan sys.dm_io_virtual_file_stats DMV muncul di benak.
Pahami bahwa kita bisa mendapatkan data ini secara manual. Sebelum kita menjalankan tes, kita dapat memilih terhadap sys.dm_io_virtual_file_stats dan menyimpan nilai saat ini ke file. Kami dapat mencatat waktu, dan kemudian memulai tes. Setelah selesai, kami mencatat waktu lagi, menanyakan sys.dm_io_virtual_file_stats lagi dan menghitung perbedaan antara nilai untuk mengukur IO.
Ada banyak kekurangan dalam metodologi ini, yaitu meninggalkan ruang yang signifikan untuk kesalahan; bagaimana jika Anda lupa mencatat waktu mulai, atau lupa merekam statistik file sebelum memulai? Solusi yang jauh lebih baik adalah mengotomatiskan tidak hanya eksekusi skrip, tetapi juga pengambilan data. Misalnya, kita dapat membuat tabel yang menyimpan informasi pengujian kita – deskripsi tentang apa itu pengujian, jam berapa dimulai, dan jam berapa selesai. Kami dapat memasukkan statistik file dalam tabel yang sama. Jika kami mengumpulkan metrik lain, kami dapat menambahkannya ke tabel. Atau, mungkin lebih mudah untuk membuat tabel terpisah untuk setiap kumpulan data yang kami ambil. Misalnya, jika kita menyimpan data statistik file dalam tabel yang berbeda, kita perlu memberikan setiap tes id unik, sehingga kita dapat mencocokkan pengujian kita dengan data statistik file yang tepat. Saat menangkap statistik file, kita harus menangkap nilai untuk database kita sebelum kita mulai, dan kemudian setelahnya, dan menghitung perbedaannya. Kami kemudian dapat menyimpan informasi tersebut ke dalam tabelnya sendiri, bersama dengan ID pengujian unik.
Contoh Latihan
Untuk pengujian ini saya membuat salinan kosong tabel Sales.SalesOrderHeader bernama Sales.Big_SalesOrderHeader, dan saya menggunakan variasi skrip yang saya gunakan dalam posting partisi saya untuk memuat data ke dalam tabel dalam kumpulan sekitar 25.000 baris. Anda dapat mengunduh skrip untuk memuat data di sini. Saya menjalankannya empat kali untuk setiap variasi, dan saya juga memvariasikan jumlah baris yang dimasukkan. Untuk set tes pertama saya memasukkan 20 juta baris, dan untuk set kedua saya memasukkan 60 juta baris. Data durasi tidak mengejutkan:
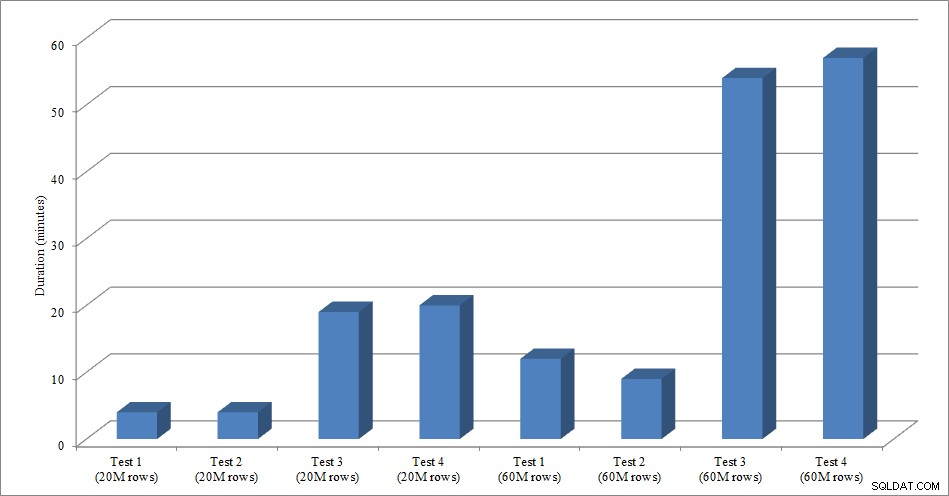
Durasi Muat Data
Memuat data, tanpa indeks nonclustered, jauh lebih cepat daripada memuatnya dengan indeks nonclustered yang sudah ada. Apa yang saya temukan menarik adalah bahwa untuk memuat 20 juta baris, total durasinya hampir sama antara Tes 1 dan Tes 2, tetapi Tes 2 lebih cepat saat memuat 60 juta baris. Dalam pengujian kami, kunci pengelompokan kami adalah SalesOrderID, yang merupakan identitas dan oleh karena itu kunci pengelompokan yang baik untuk beban kami karena sedang naik. Jika kami memiliki kunci pengelompokan yang merupakan GUID, waktu buka mungkin lebih tinggi karena penyisipan acak dan pemisahan halaman (variasi lain yang dapat kami uji).
Apakah data IO meniru tren dalam data durasi? Ya, dengan perbedaan memiliki indeks yang sudah ada, atau tidak, bahkan lebih dibesar-besarkan:
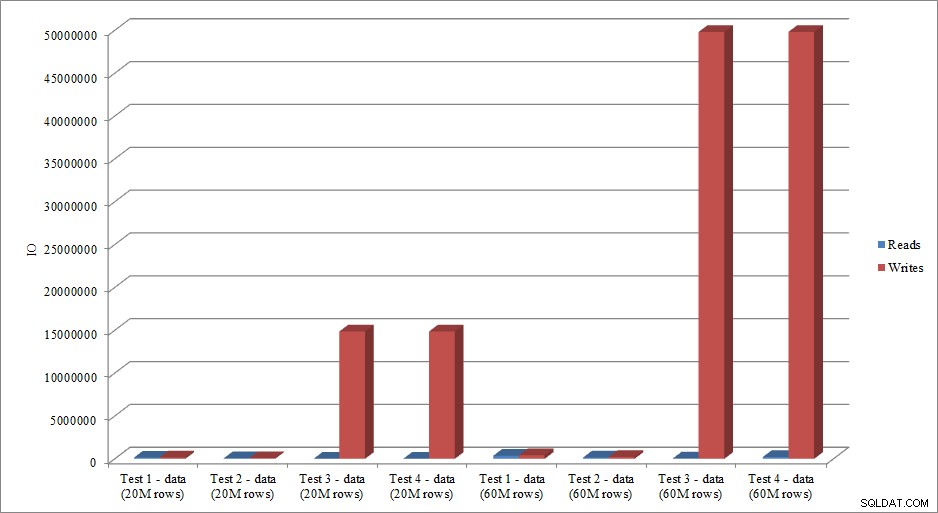
Memuat Data Baca dan Tulis
Metode yang saya sajikan di sini untuk pengujian kinerja, atau mengukur perubahan kinerja berdasarkan modifikasi kode, desain, dll., hanyalah salah satu opsi untuk menangkap informasi dasar. Dalam beberapa skenario, ini mungkin berlebihan. Jika Anda memiliki satu kueri yang Anda coba sesuaikan, menyiapkan proses ini untuk menangkap data mungkin membutuhkan waktu lebih lama daripada membuat penyesuaian pada kueri! Jika Anda telah melakukan sejumlah penyetelan kueri, Anda mungkin terbiasa menangkap data STATISTICS IO dan STATISTICS TIME, bersama dengan rencana kueri, lalu membandingkan hasilnya saat Anda membuat perubahan. Saya telah melakukan ini selama bertahun-tahun, tetapi baru-baru ini saya menemukan cara yang lebih baik… SQL Sentry Plan Explorer PRO. Faktanya, setelah saya menyelesaikan semua pengujian beban yang saya jelaskan di atas, saya menjalani dan menjalankan ulang pengujian saya melalui PE, dan ternyata saya dapat menangkap informasi yang saya inginkan, tanpa harus menyiapkan tabel pengumpulan data saya.
Di dalam Plan Explorer PRO, Anda memiliki opsi untuk mendapatkan paket aktual – PE akan menjalankan kueri terhadap instans dan database yang dipilih, dan mengembalikan paket tersebut. Dan dengan itu, Anda mendapatkan semua data hebat lainnya yang disediakan PE (statistik waktu, membaca dan menulis, IO menurut tabel), serta statistik menunggu, yang merupakan manfaat bagus. Menggunakan contoh kami, saya mulai dengan tes pertama – membuat heap, memuat data dan kemudian menambahkan indeks berkerumun dan indeks noncluster – dan kemudian menjalankan opsi Dapatkan Paket Aktual. Ketika selesai, saya memodifikasi tes skrip 2 saya, menjalankan opsi Dapatkan Paket Aktual lagi. Saya mengulangi ini untuk tes ketiga dan keempat, dan ketika saya selesai, saya mendapatkan ini:
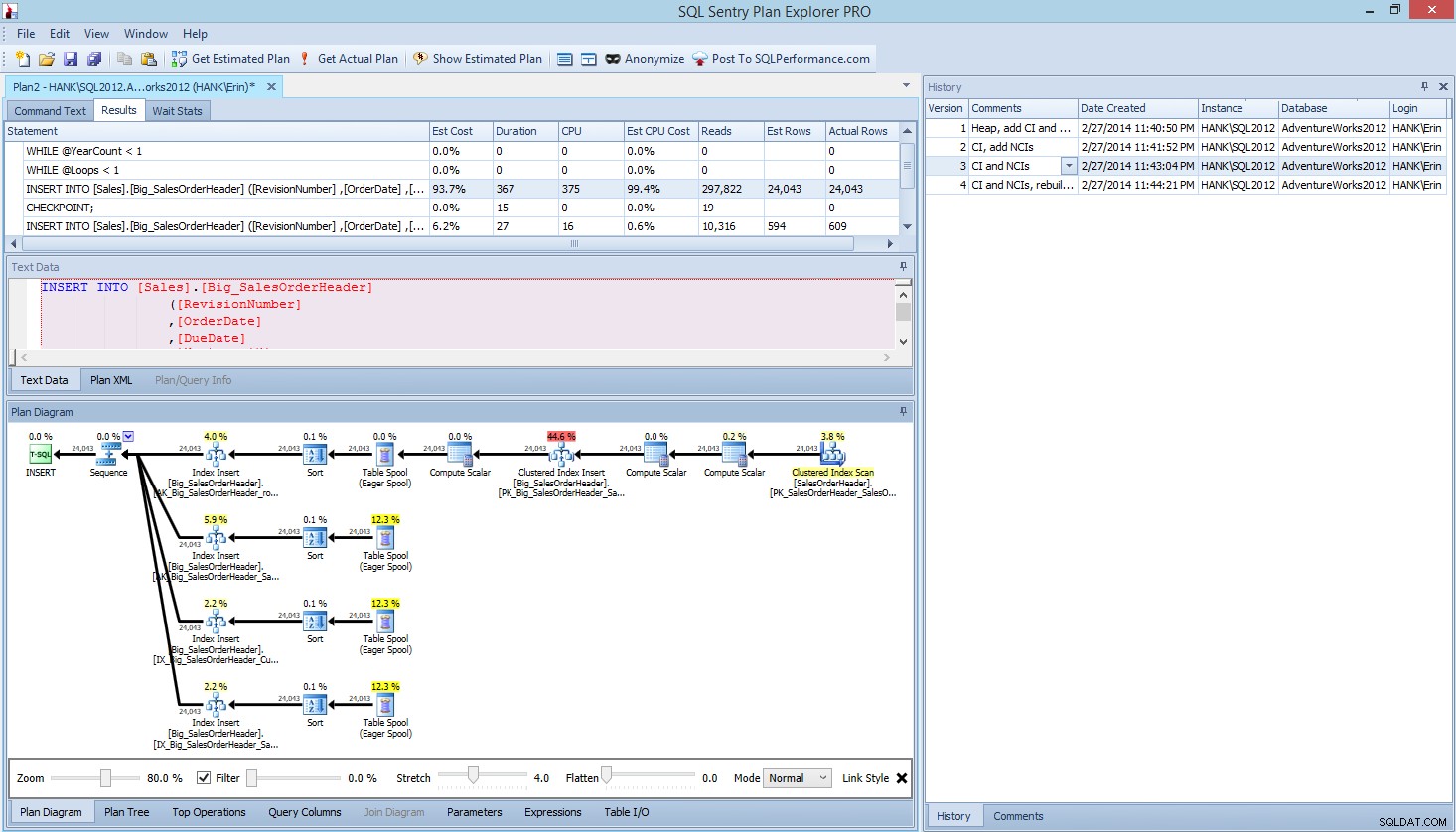
Rencanakan tampilan PRO Explorer setelah menjalankan 4 pengujian
Perhatikan panel riwayat di sisi kanan? Setiap kali saya memodifikasi kode saya dan mendapatkan kembali rencana yang sebenarnya, itu menyimpan satu set informasi baru. Saya memiliki kemampuan untuk menyimpan data ini sebagai file .pesession untuk dibagikan dengan anggota tim saya yang lain, atau kembali lagi nanti dan menelusuri tes yang berbeda, dan menelusuri pernyataan yang berbeda dalam kumpulan yang diperlukan, melihat metrik yang berbeda seperti seperti durasi, CPU, dan IO. Pada tangkapan layar di atas, saya telah menyoroti INSERT dari Test 3, dan rencana kueri menunjukkan pembaruan untuk keempat indeks nonclustered.
Ringkasan
Seperti banyak tugas di SQL Server, ada banyak cara untuk menangkap dan meninjau data saat Anda menjalankan tes kinerja atau melakukan penyetelan. Semakin sedikit upaya manual yang harus Anda lakukan, semakin baik, karena menyisakan lebih banyak waktu untuk benar-benar membuat perubahan, memahami dampaknya, dan kemudian beralih ke tugas Anda berikutnya. Baik Anda menyesuaikan skrip untuk mengambil data, atau membiarkan utilitas pihak ketiga melakukannya untuk Anda, langkah-langkah yang saya uraikan tetap valid:
- Tentukan apa yang ingin Anda tingkatkan
- Cakupan pengujian Anda
- Menentukan data apa yang dapat digunakan untuk mengukur peningkatan
- Tentukan cara mengambil data
- Siapkan metode otomatis, bila memungkinkan, untuk pengujian dan pengambilan
- Uji, evaluasi, dan ulangi jika perlu
Selamat menguji!