Apakah SQL DISTINCT baik (atau buruk) ketika Anda perlu menghapus duplikat dalam hasil?
Beberapa mengatakan itu bagus dan menambahkan DISTINCT ketika duplikat muncul. Beberapa mengatakan itu buruk dan menyarankan menggunakan GROUP BY tanpa fungsi agregat. Yang lain mengatakan DISTINCT dan GROUP BY sama ketika Anda perlu menghapus duplikat.
Posting ini akan menyelami detailnya untuk mendapatkan jawaban yang benar. Jadi, pada akhirnya, Anda akan menggunakan kata kunci terbaik berdasarkan kebutuhan. Mari kita mulai.
Pengingat singkat tentang dasar-dasar pernyataan SQL SELECT DISTINCT
Sebelum kita menyelam lebih dalam, mari kita ingat apa pernyataan SQL SELECT DISTINCT itu. Tabel database dapat menyertakan nilai duplikat karena berbagai alasan, tetapi kita mungkin ingin mendapatkan nilai unik saja. Dalam hal ini, SELECT DISTINCT berguna. Klausa DISTINCT ini membuat pernyataan SELECT hanya mengambil record unik.
Sintaks pernyataannya sederhana:
SELECT DISTINCT column
FROM table_name
WHERE [condition];Di sini, kondisi WHERE adalah opsional.
Pernyataan tersebut berlaku untuk satu kolom dan beberapa kolom. Sintaks dari pernyataan ini diterapkan ke beberapa kolom adalah sebagai berikut:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Perhatikan bahwa skenario kueri beberapa kolom akan menyarankan penggunaan kombinasi nilai di semua kolom yang ditentukan oleh pernyataan untuk menentukan keunikan.
Dan sekarang, mari kita jelajahi penggunaan praktis dan tangkapan dari penerapan pernyataan SELECT DISTINCT.
Cara Kerja SQL DISTINCT untuk Menghapus Duplikat
Mendapatkan jawaban tidak begitu sulit untuk ditemukan. SQL Server memberi kami rencana eksekusi untuk melihat bagaimana kueri akan diproses untuk memberi kami hasil yang dibutuhkan.
Bagian berikut berfokus pada rencana eksekusi saat menggunakan DISTINCT. Anda perlu menekan Ctrl-M di SQL Server Management Studio sebelum menjalankan kueri di bawah ini. Atau, klik Sertakan Rencana Eksekusi Aktual dari bilah alat.
Paket Kueri dalam SQL DISTINCT
Mari kita mulai dengan membandingkan 2 kueri. Yang pertama tidak akan menggunakan DISTINCT, dan kueri kedua akan.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Berikut rencana eksekusinya:
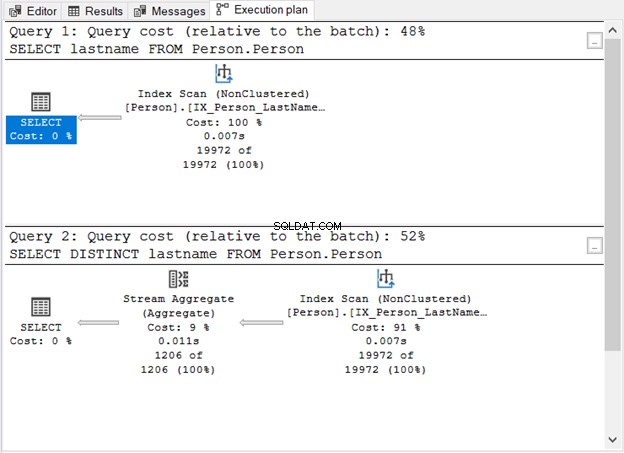
Apa yang ditunjukkan Gambar 1 kepada kita?
- Tanpa kata kunci DISTINCT, kuerinya sederhana.
- Langkah tambahan muncul setelah menambahkan DISTINCT.
- Biaya kueri menggunakan DISTINCT lebih tinggi daripada tanpanya.
- Keduanya memiliki operator Pemindaian Indeks. Hal ini dapat dimengerti karena tidak ada klausa WHERE khusus dalam kueri kami.
- Langkah ekstra, operator Stream Aggregate, digunakan untuk menghapus duplikat.
Jumlah pembacaan logis adalah sama (107) jika Anda memeriksa STATISTICS IO. Namun, jumlah catatan sangat berbeda. 19.972 baris dikembalikan oleh kueri pertama. Sementara itu, 1.206 baris dikembalikan oleh kueri kedua.
Karenanya, Anda tidak dapat menambahkan DISTINCT kapan pun Anda mau. Tetapi jika Anda membutuhkan nilai unik, ini adalah biaya tambahan yang diperlukan.
Ada operator yang digunakan untuk menampilkan nilai unik. Mari kita periksa beberapa di antaranya.
STREAM AGGREGATE
Ini adalah operator yang Anda lihat pada Gambar 1. Ia menerima satu input dan mengeluarkan hasil gabungan. Pada Gambar 1, input berasal dari operator Index Scan. Namun, Stream Aggregate membutuhkan input yang diurutkan.
Seperti yang Anda lihat pada Gambar 1, ia menggunakan IX_Person_LastName_FirstName_MiddleName , indeks non-unik pada nama. Karena indeks sudah mengurutkan catatan berdasarkan nama, Stream Aggregate menerima input. Tanpa indeks, pengoptimal kueri dapat memilih untuk menggunakan operator Sortir tambahan dalam paket. Dan itu akan lebih mahal. Atau, bisa menggunakan Hash Match.
HASH MATCH (AGGREGATE)
Operator lain yang digunakan oleh DISTINCT adalah Hash Match. Operator ini digunakan untuk bergabung dan agregasi.
Saat menggunakan DISTINCT, Hash Match menggabungkan hasil untuk menghasilkan nilai unik. Ini salah satu contohnya.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
Dan inilah rencana eksekusinya:
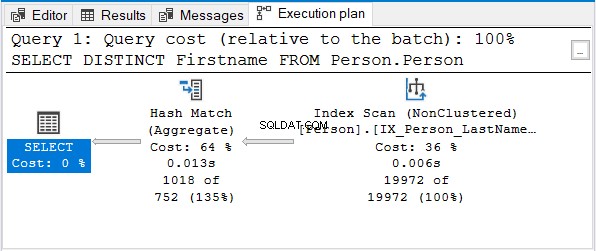
Tapi mengapa tidak Streaming Agregat?
Perhatikan bahwa indeks nama yang sama digunakan. Indeks itu diurutkan dengan Nama Belakang pertama. Jadi, Nama Depan hanya kueri yang tidak disortir.
Hash Match (Aggregate) adalah pilihan logis berikutnya untuk menghapus duplikat.
HASH MATCH (FLOW BERBEDA)
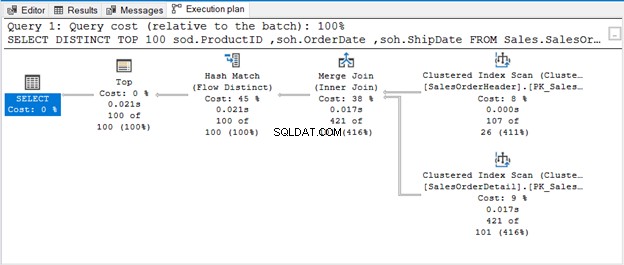
Hash Match (Aggregate) adalah operator pemblokiran. Dengan demikian, itu tidak akan menghasilkan output yang telah diproses seluruh aliran input. Jika kita membatasi jumlah baris (seperti menggunakan TOP dengan DISTINCT), itu akan menghasilkan output unik segera setelah baris tersebut tersedia. Itulah yang dimaksud dengan Hash Match (Flow Distinct).
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
Kueri menggunakan TOP 100 bersama dengan DISTINCT. Berikut rencana eksekusinya:
KETIKA TIDAK ADA OPERATOR UNTUK MENGHAPUS DUPLIKAT
Ya. Ini bisa terjadi. Perhatikan contoh di bawah ini.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Kemudian, periksa rencana eksekusi:
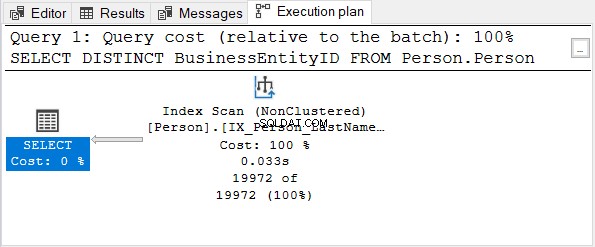
BusinessEntityID kolom adalah kunci utama. Karena kolom itu sudah unik, tidak ada gunanya menerapkan DISTINCT. Coba hapus DISTINCT dari pernyataan SELECT – rencana eksekusi sama seperti pada Gambar 4.
Hal yang sama berlaku saat menggunakan DISTINCT pada kolom dengan indeks unik.
SQL DISTINCT Bekerja pada SEMUA Kolom dalam Daftar SELECT
Sejauh ini, kami hanya menggunakan 1 kolom dalam contoh kami. Namun, DISTINCT berfungsi pada SEMUA kolom yang Anda tentukan dalam daftar SELECT.
Berikut ini contohnya. Kueri ini akan memastikan bahwa nilai dari ketiga kolom akan unik.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Perhatikan beberapa baris pertama dalam hasil yang ditetapkan pada Gambar 5.
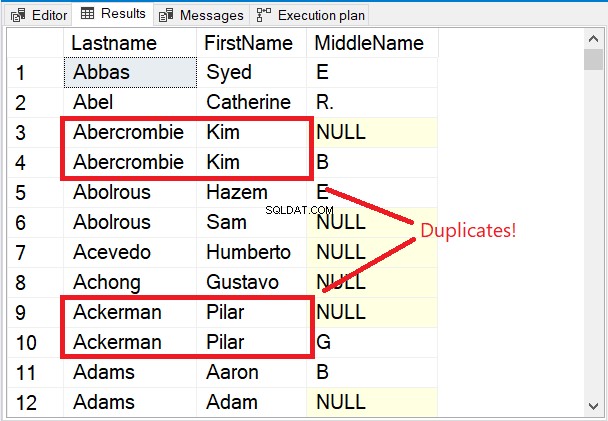
Beberapa baris pertama semuanya unik. Kata kunci DISTINCT memastikan bahwa Nama Tengah kolom juga dipertimbangkan. Perhatikan 2 nama yang dikotak merah. Mengingat Nama Belakang dan Nama Depan hanya akan membuat mereka duplikat. Tapi menambahkan Nama Tengah ke campuran mengubah segalanya.
Bagaimana jika Anda ingin mendapatkan nama depan dan belakang yang unik tetapi menyertakan nama tengah di hasil?
Anda memiliki 2 opsi:
- Tambahkan klausa WHERE untuk menghapus nama tengah NULL. Ini akan menghapus semua nama dengan nama tengah NULL.
- Atau, tambahkan klausa GROUP BY pada Nama Belakang dan Nama Depan kolom. Kemudian, gunakan fungsi agregat MIN pada Nama Tengah kolom. Ini akan mendapatkan 1 nama tengah dengan nama belakang dan nama depan yang sama.
SQL DISTINCT vs. GROUP BY
Saat menggunakan GROUP BY tanpa fungsi agregat, ia bertindak seperti DISTINCT. Bagaimana kami bisa tahu? Salah satu cara untuk mengetahuinya adalah dengan menggunakan contoh.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Jalankan dan periksa rencana eksekusi. Apakah seperti screenshot di bawah ini?
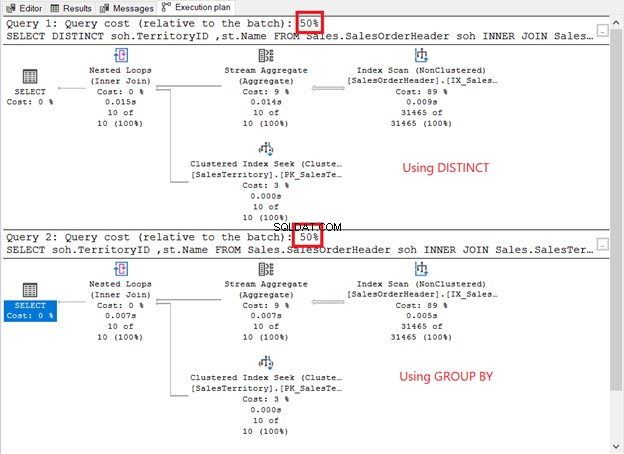
Bagaimana perbandingannya?
- Mereka memiliki operator dan urutan paket yang sama.
- Biaya operator masing-masing dan biaya kueri adalah sama.
Jika Anda memeriksa QueryPlanHash properti dari 2 operator SELECT, mereka adalah sama. Oleh karena itu, pengoptimal kueri menggunakan proses yang sama untuk mengembalikan hasil yang sama.
Pada akhirnya, kami tidak dapat mengatakan bahwa menggunakan GROUP BY lebih baik daripada DISTINCT dalam mengembalikan nilai unik. Anda dapat membuktikannya dengan menggunakan contoh di atas untuk mengganti DISTINCT dengan GROUP BY.
Sekarang tinggal masalah preferensi mana yang akan Anda gunakan. Saya lebih suka BERBEDA. Ini secara eksplisit memberi tahu maksud dalam kueri – untuk menghasilkan hasil yang unik. Dan bagi saya, GROUP BY adalah untuk mengelompokkan hasil menggunakan fungsi agregat. Niat itu juga jelas dan konsisten dengan kata kunci itu sendiri. Saya tidak tahu apakah orang lain akan mempertahankan pertanyaan saya suatu hari nanti. Jadi, kodenya harus jelas.
Tapi itu bukan akhir dari cerita.
Bila SQL DISTINCT Tidak Sama dengan GROUP BY
Saya baru saja mengungkapkan pendapat saya, lalu ini?
Itu benar. Mereka tidak akan sama sepanjang waktu. Perhatikan contoh ini.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Meskipun kumpulan hasil tidak disortir, barisnya sama seperti pada contoh sebelumnya. Satu-satunya perbedaan adalah penggunaan subquery:
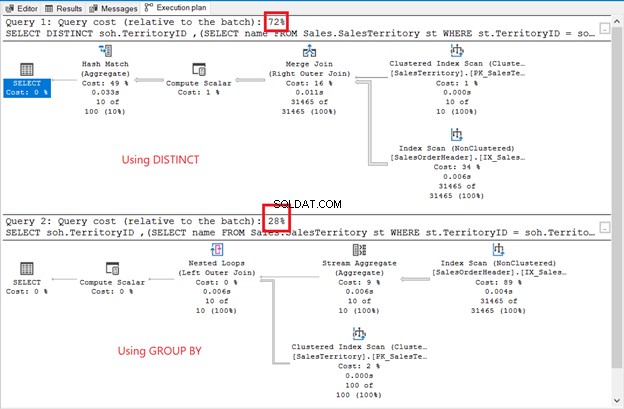
Perbedaannya jelas:operator, biaya kueri, paket keseluruhan. Kali ini, GROUP BY menang dengan hanya 28% biaya kueri. Tapi inilah masalahnya.
Tujuannya adalah untuk menunjukkan kepada Anda bahwa mereka bisa berbeda. Itu saja. Ini sama sekali bukan rekomendasi. Menggunakan join memiliki rencana eksekusi yang lebih baik (lihat Gambar 6 lagi).
Intinya
Inilah yang telah kita pelajari sejauh ini:
- DISTINCT menambahkan operator paket untuk menghapus duplikat.
- DISTINCT dan GROUP BY tanpa fungsi agregat menghasilkan rencana yang sama. Singkatnya, mereka hampir selalu sama.
- Terkadang, DISTINCT dan GROUP BY dapat memiliki rencana yang berbeda saat subkueri terlibat dalam daftar SELECT.
Jadi, apakah SQL DISTINCT baik atau buruk dalam menghapus duplikat dalam hasil?
Hasilnya mengatakan bahwa itu bagus. Ini tidak lebih baik atau lebih buruk daripada GROUP BY karena rencananya sama. Tapi itu kebiasaan yang baik untuk memeriksa rencana eksekusi. Pikirkan optimasi dari awal. Dengan begitu, jika Anda menemukan perbedaan dalam DISTINCT dan GROUP BY, Anda akan menemukannya.
Selain itu, alat-alat modern membuat tugas ini lebih sederhana. Misalnya, produk populer dbForge SQL Complete dari Devart memiliki fitur khusus yang menghitung nilai dalam fungsi agregat dalam kumpulan hasil siap dari kisi hasil SSMS. Nilai DISTINCT juga ada di sana.
Suka postingannya? Kemudian, sebarkan berita dengan membagikannya di platform media sosial favorit Anda.
Artikel Terkait untuk Informasi Lebih Lanjut
- SQL GROUP BY:3 Tips Mudah untuk Mengelompokkan Hasil Seperti Profesional
- SQL INSERT INTO SELECT:5 Cara Mudah Menangani Duplikat
- Apa itu Fungsi Agregat SQL? (Kiat Mudah untuk Pemula)
- Optimalisasi Kueri SQL:5 Fakta Inti untuk Meningkatkan Kueri



