Predikat Tunggal
Memperkirakan jumlah baris yang dikualifikasikan oleh satu predikat kueri seringkali mudah. Saat predikat membuat perbandingan sederhana antara kolom dan nilai skalar, kemungkinan besar penaksir kardinalitas akan dapat memperoleh perkiraan kualitas yang baik dari histogram statistik. Misalnya, kueri AdventureWorks berikut menghasilkan perkiraan yang benar-benar tepat dari 203 baris (dengan asumsi tidak ada perubahan yang dilakukan pada data sejak statistik dibuat):
SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.TransactionDate = '20070903';
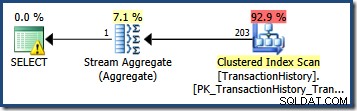
Melihat histogram statistik untuk TransactionDate kolom, jelas untuk melihat dari mana perkiraan ini berasal:
DBCC SHOW_STATISTICS (
'Production.TransactionHistory',
'TransactionDate')
WITH HISTOGRAM;
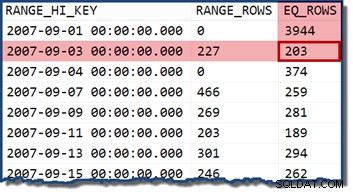
Jika kita mengubah kueri untuk menentukan tanggal yang termasuk dalam keranjang histogram, penaksir kardinalitas mengasumsikan nilai terdistribusi secara merata. Menggunakan tanggal 2007-09-02 menghasilkan perkiraan 227 baris (dari RANGE_ROWS masuk). Sebagai catatan tambahan yang menarik, perkiraan tetap pada 227 baris terlepas dari porsi waktu apa pun yang mungkin kami tambahkan ke nilai tanggal (TransactionDate kolom adalah datetime tipe data).
Jika kami mencoba kueri lagi dengan tanggal 2007-09-05 atau 2007-09-06 (keduanya berada di antara 2007-09-04 dan 2007-09-07 langkah histogram), penaksir kardinalitas mengasumsikan 466 RANGE_ROWS dibagi rata antara dua nilai, memperkirakan 233 baris dalam kedua kasus.
Ada banyak detail lain untuk estimasi kardinalitas untuk predikat sederhana, tetapi hal di atas akan dilakukan sebagai penyegaran untuk tujuan kita saat ini.
Masalah Banyak Predikat
Ketika kueri berisi lebih dari satu kolom predikat, estimasi kardinalitas menjadi lebih sulit. Pertimbangkan kueri berikut dengan dua predikat sederhana (masing-masing mudah diperkirakan sendiri):
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'; Rentang nilai tertentu dalam kueri sengaja dipilih sehingga kedua predikat mengidentifikasi baris yang sama persis. Kami dapat dengan mudah memodifikasi nilai kueri untuk menghasilkan jumlah tumpang tindih, termasuk tidak ada tumpang tindih sama sekali. Bayangkan sekarang bahwa Anda adalah penaksir kardinalitas:bagaimana Anda mendapatkan taksiran kardinalitas untuk kueri ini?
Masalahnya lebih sulit daripada yang mungkin terdengar pada awalnya. Secara default, SQL Server secara otomatis membuat statistik kolom tunggal pada kedua kolom predikat. Kami juga dapat membuat statistik multi-kolom secara manual. Apakah ini memberi kita informasi yang cukup untuk menghasilkan perkiraan yang baik untuk nilai-nilai spesifik ini? Bagaimana dengan kasus yang lebih umum di mana mungkin ada apa saja tingkat tumpang tindih?
Dengan menggunakan dua objek statistik kolom tunggal, kita dapat dengan mudah memperoleh perkiraan untuk setiap predikat menggunakan metode histogram yang dijelaskan di bagian sebelumnya. Untuk nilai spesifik dalam kueri di atas, histogram menunjukkan bahwa TransactionID kisaran diharapkan cocok dengan 68412.4 baris, dan TransactionDate kisaran diharapkan cocok dengan 68,413 baris. (Jika histogramnya sempurna, kedua angka ini akan sama persis.)
Apa yang histogram tidak bisa beri tahu kami berapa banyak dari dua set baris ini yang akan baris yang sama . Yang dapat kami katakan berdasarkan informasi histogram adalah bahwa perkiraan kami harus berada di antara nol (tanpa tumpang tindih sama sekali) dan 68412,4 baris (tumpang tindih sepenuhnya).
Membuat statistik multi-kolom tidak memberikan bantuan untuk kueri ini (atau untuk kueri rentang secara umum). Statistik multi-kolom masih hanya membuat histogram di atas kolom bernama pertama, yang pada dasarnya menduplikasi histogram yang terkait dengan salah satu statistik yang dibuat secara otomatis. Kepadatan tambahan informasi yang diberikan oleh statistik multi-kolom dapat berguna untuk memberikan informasi kasus rata-rata untuk kueri yang berisi beberapa predikat kesetaraan, tetapi informasi tersebut tidak membantu kami di sini.
Untuk menghasilkan perkiraan dengan tingkat kepercayaan yang tinggi, kita memerlukan SQL Server untuk memberikan informasi yang lebih baik tentang distribusi data – sesuatu seperti multi-dimensi histogram statistik. Sejauh yang saya tahu, saat ini tidak ada mesin database komersial yang menawarkan fasilitas seperti ini, meskipun beberapa makalah teknis telah diterbitkan tentang masalah ini (termasuk Microsoft Research yang menggunakan pengembangan internal SQL Server 2000).
Tanpa mengetahui apa pun tentang korelasi data dan tumpang tindih untuk rentang nilai tertentu, tidak jelas bagaimana kami harus melanjutkan untuk menghasilkan perkiraan yang baik untuk kueri kami. Jadi, apa yang dilakukan SQL Server di sini?
SQL Server 7 – 2012
Penaksir kardinalitas dalam versi SQL Server ini umumnya mengasumsikan bahwa nilai atribut yang berbeda dalam tabel didistribusikan sepenuhnya secara independen satu sama lain. asumsi kemerdekaan . ini jarang merupakan pencerminan akurat dari data nyata, tetapi memiliki keuntungan membuat perhitungan yang lebih sederhana.
DAN Selektivitas
Menggunakan asumsi independensi, dua predikat dihubungkan oleh AND (dikenal sebagai konjungsi ) dengan selektivitas S1 dan S2 , menghasilkan selektivitas gabungan:
(S1 * S2)
Jika istilah tersebut asing bagi Anda, selektivitas adalah angka antara 0 dan 1, yang mewakili pecahan baris dalam tabel yang melewati predikat. Misalnya, jika predikat memilih 12 baris dari tabel 100 baris, selektivitasnya adalah (12/100) =0,12.
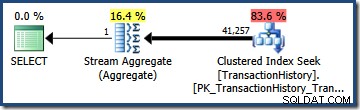
Dalam contoh kita, TransactionHistory tabel berisi total 113.443 baris. Predikat pada TransactionID diperkirakan (dari histogram) memenuhi syarat 68.412,4 baris, jadi selektivitasnya adalah (68.412,4 / 113,443) atau kira-kira 0,603055 . Predikat pada TransactionDate sama diperkirakan memiliki selektivitas (68.413 / 113.443) =kira-kira 0,603061 .
Mengalikan dua selektivitas (menggunakan rumus di atas) memberikan perkiraan selektivitas gabungan 0,363679 . Mengalikan selektivitas ini dengan kardinalitas tabel (113.443) memberikan perkiraan akhir 41.256.8 baris:
ATAU Selektivitas
Dua predikat dihubungkan oleh OR (sebuah pemisahan ) dengan selektivitas S1 dan S2 , menghasilkan selektivitas gabungan:
(S1 + S2) – (S1 * S2)
Intuisi di balik rumus tersebut adalah dengan menjumlahkan kedua selektivitas, lalu mengurangi taksiran untuk konjungsinya (menggunakan rumus sebelumnya). Jelas kita bisa memiliki dua predikat, masing-masing selektivitas 0,8, tetapi hanya menambahkan mereka bersama-sama akan menghasilkan selektivitas gabungan yang mustahil dari 1,6. Terlepas dari asumsi independensi, kita harus mengakui bahwa dua predikat mungkin memiliki tumpang tindih, sehingga untuk menghindari penghitungan ganda, estimasi selektivitas konjungsi dikurangi.
Kita dapat dengan mudah memodifikasi contoh yang sedang berjalan untuk menggunakan OR :
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
OR TH.TransactionDate BETWEEN '20070901' AND '20080313';
Mengganti selektivitas predikat ke dalam OR rumus memberikan selektivitas gabungan:
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
Dikalikan dengan jumlah baris dalam tabel, selektivitas ini memberi kita perkiraan kardinalitas akhir 95.568.6 :
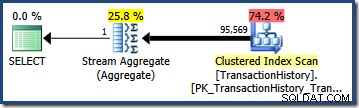
Tidak ada perkiraan (41.257 untuk AND pertanyaan; 95.569 untuk OR query) sangat baik karena keduanya didasarkan pada asumsi pemodelan yang tidak cocok dengan distribusi data dengan baik. Kedua kueri sebenarnya mengembalikan 68,413 baris (karena predikat mengidentifikasi baris yang sama persis).
Trace Flag 4137 – Selektivitas Minimum
Untuk SQL Server 2008 (R1) hingga 2012, Microsoft merilis perbaikan yang mengubah cara selektivitas dihitung untuk AND case (predikat kata penghubung) saja. Artikel Basis Pengetahuan di tautan itu tidak memuat banyak detail, tetapi ternyata perbaikannya mengubah rumus selektivitas yang digunakan. Alih-alih mengalikan selektivitas individu, estimasi kardinalitas untuk predikat konjungtif sekarang menggunakan selektivitas terendah saja.
Untuk mengaktifkan perilaku yang diubah, diperlukan tanda pelacakan yang didukung 4137. Artikel Basis Pengetahuan terpisah mendokumentasikan bahwa tanda pelacakan ini juga didukung untuk penggunaan per kueri melalui QUERYTRACEON petunjuk:
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'
OPTION (QUERYTRACEON 4137); Dengan flag ini aktif, estimasi kardinalitas menggunakan selektivitas minimum dari dua predikat, menghasilkan estimasi 68,412.4 baris:
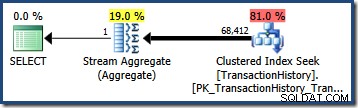
Ini hampir sempurna untuk kueri kami karena predikat pengujian kami benar-benar berkorelasi (dan perkiraan yang diturunkan dari histogram dasar juga sangat baik).
Cukup jarang predikat berkorelasi sempurna seperti ini dengan data nyata, tetapi tanda jejak dapat membantu dalam beberapa kasus. Perhatikan bahwa perilaku selektivitas minimum akan berlaku untuk semua kata penghubung (AND ) predikat dalam kueri; tidak ada cara untuk menentukan perilaku pada tingkat yang lebih terperinci.
Tidak ada tanda jejak yang sesuai untuk memperkirakan disjungtif (OR ) predikat menggunakan selektivitas minimum.
SQL Server 2014
Komputasi selektivitas di SQL Server 2014 berperilaku sama seperti versi sebelumnya (dan bendera pelacakan 4137 berfungsi seperti sebelumnya) jika tingkat kompatibilitas database diatur lebih rendah dari 120, atau jika bendera pelacakan 9481 aktif. Menyetel tingkat kompatibilitas basis data adalah resmi cara menggunakan penaksir kardinalitas pra-2014 di SQL Server 2014. Trace flag 9481 efektif untuk melakukan hal yang sama seperti pada saat penulisan, dan juga bekerja dengan QUERYTRACEON , meskipun tidak didokumentasikan untuk melakukannya. Tidak ada cara untuk mengetahui perilaku RTM dari flag ini nantinya.
Jika penaksir kardinalitas baru aktif, SQL Server 2014 menggunakan rumus default yang berbeda untuk menggabungkan predikat konjungtif dan disjungtif. Meskipun tidak didokumentasikan, formula selektivitas untuk konjungsi telah ditemukan dan didokumentasikan beberapa kali sekarang. Yang pertama saya ingat pernah melihatnya di posting blog Portugis ini dan bagian dua lanjutannya diterbitkan beberapa minggu kemudian. Untuk meringkas, pendekatan 2014 untuk predikat konjungtif adalah dengan menggunakan backoff eksponensial: diberikan tabel dengan kardinalitas C, dan selektivitas predikat S1 , S2 , S3 … Sn , di mana S1 adalah yang paling selektif dan Sn paling sedikit:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …
Estimasi dihitung predikat paling selektif dikalikan dengan kardinalitas tabel, dikalikan dengan akar kuadrat dari predikat paling selektif berikutnya, dan seterusnya dengan setiap selektivitas baru memperoleh akar kuadrat tambahan.
Mengingat selektivitas adalah angka antara 0 dan 1, jelas bahwa menerapkan akar kuadrat memindahkan angka lebih dekat ke 1. Efeknya adalah memperhitungkan semua predikat dalam perkiraan akhir, tetapi untuk mengurangi dampak dari predikat yang kurang selektif secara eksponensial. Bisa dibilang ada lebih banyak logika untuk ide ini daripada di bawah asumsi kemerdekaan , tetapi ini masih merupakan formula tetap – tidak berubah berdasarkan tingkat korelasi data yang sebenarnya.
Penaksir kardinalitas 2014 menggunakan rumus backoff eksponensial untuk keduanya predikat konjungtif dan disjungtif, meskipun rumus yang digunakan dalam predikat disjungtif (OR ) kasus belum didokumentasikan (secara resmi atau sebaliknya).
Tanda Pelacakan Selektivitas SQL Server 2014
Bendera pelacakan 4137 (untuk menggunakan selektivitas minimum) tidak bekerja di SQL Server 2014, jika penaksir kardinalitas baru digunakan saat menyusun kueri. Sebagai gantinya, ada tanda jejak baru 9471 . Saat tanda ini aktif, selektivitas minimum digunakan untuk memperkirakan beberapa konjungtif dan disjungtif predikat. Ini adalah perubahan dari perilaku 4137, yang hanya memengaruhi predikat kata penghubung.
Demikian pula, lacak bendera 9472 dapat ditentukan untuk mengasumsikan kemerdekaan untuk beberapa predikat, seperti yang dilakukan versi sebelumnya. Bendera ini berbeda dengan 9481 (menggunakan penduga kardinalitas pra-2014) karena di bawah 9472 penaksir kardinalitas baru akan tetap digunakan, hanya rumus selektivitas untuk beberapa predikat yang terpengaruh.
Baik 9471 maupun 9472 tidak didokumentasikan pada saat penulisan (meskipun mungkin ada di RTM).
Cara mudah untuk melihat asumsi selektivitas mana yang digunakan di SQL Server 2014 (dengan estimator kardinalitas baru yang aktif) adalah dengan memeriksa keluaran debug komputasi selektivitas yang dihasilkan saat melacak flag 2363 dan 3604 aktif. Bagian yang harus dicari berkaitan dengan kalkulator selektivitas yang menggabungkan filter, di mana Anda akan melihat salah satu dari berikut ini, tergantung pada asumsi yang digunakan:
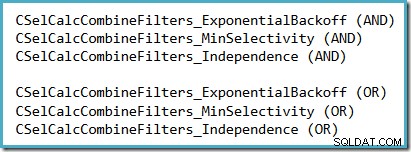
Tidak ada prospek realistis bahwa 2363 akan didokumentasikan atau didukung.
Pemikiran Terakhir
Tidak ada yang ajaib tentang backoff eksponensial, selektivitas minimum, atau independensi. Setiap pendekatan mewakili asumsi penyederhanaan (sangat) yang mungkin atau mungkin tidak menghasilkan perkiraan yang dapat diterima untuk kueri atau distribusi data tertentu.
Dalam beberapa hal, backoff eksponensial mewakili kompromi antara dua ekstrem kemerdekaan dan selektivitas minimum . Meski begitu, penting untuk tidak memiliki harapan yang tidak masuk akal terhadapnya. Sampai cara yang lebih akurat ditemukan untuk memperkirakan selektivitas untuk beberapa predikat (dengan karakteristik kinerja yang wajar), tetap penting untuk menyadari keterbatasan model dan berhati-hati terhadap kesalahan estimasi (potensial).
Berbagai tanda jejak memberikan beberapa kendali atas asumsi mana yang digunakan, tetapi situasinya jauh dari sempurna. Untuk satu hal, granularitas terbaik di mana flag dapat diterapkan adalah kueri tunggal – perilaku estimasi tidak dapat ditentukan pada tingkat predikat. Jika Anda memiliki kueri di mana beberapa predikat berkorelasi dan lainnya independen, tanda pelacakan mungkin tidak banyak membantu Anda tanpa memfaktorkan ulang kueri dalam satu atau lain cara. Demikian pula, kueri yang bermasalah mungkin memiliki korelasi predikat yang tidak dimodelkan dengan baik oleh salah satu opsi yang tersedia.
Penggunaan tanda pelacakan secara ad-hoc memerlukan izin yang sama seperti DBCC TRACEON – yaitu sysadmin . Itu mungkin baik untuk pengujian pribadi, tetapi untuk produksi gunakan panduan rencana menggunakan QUERYTRACEON petunjuk adalah pilihan yang lebih baik. Dengan panduan rencana, tidak ada izin tambahan yang diperlukan untuk menjalankan kueri (meskipun izin yang lebih tinggi diperlukan untuk membuat panduan rencana, tentu saja).