Salah satu dari banyak peningkatan rencana eksekusi di SQL Server 2012 adalah penambahan reservasi utas dan informasi penggunaan untuk rencana eksekusi paralel. Postingan ini melihat dengan tepat apa arti angka-angka ini, dan memberikan wawasan tambahan untuk memahami eksekusi paralel.
Pertimbangkan kueri berikut dijalankan terhadap versi database AdventureWorks yang diperbesar:
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
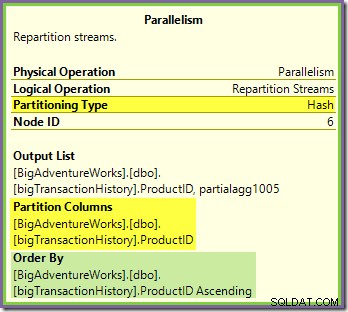
ORDER BY BP.ProductID; Pengoptimal kueri memilih rencana eksekusi paralel:
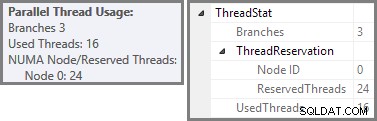
Plan Explorer menunjukkan detail penggunaan utas paralel di tooltip simpul akar. Untuk melihat informasi yang sama di SSMS, klik node root rencana, buka jendela Properties, dan luaskan ThreadStat simpul. Menggunakan mesin dengan delapan prosesor logis yang tersedia untuk digunakan SQL Server, informasi penggunaan utas dari menjalankan kueri ini secara umum ditampilkan di bawah, Plan Explorer di sebelah kiri, tampilan SSMS di sebelah kanan:
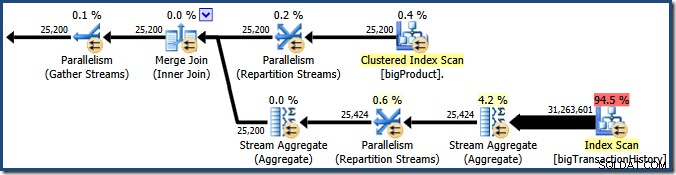
Tangkapan layar menunjukkan mesin eksekusi memesan 24 utas untuk kueri ini, dan akhirnya menggunakan 16 utas. Ini juga menunjukkan bahwa rencana kueri memiliki tiga cabang , meskipun tidak mengatakan dengan tepat apa itu cabang. Jika Anda telah membaca artikel Simple Talk saya tentang eksekusi kueri paralel, Anda akan tahu bahwa cabang adalah bagian dari rencana kueri paralel yang dibatasi oleh operator pertukaran. Diagram di bawah menggambarkan batas-batasnya, dan memberi nomor pada cabang-cabangnya (klik untuk memperbesar):

Cabang Dua (Oranye)
Mari kita lihat cabang dua lebih detail dulu:
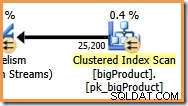
Pada derajat paralelisme (DOP) delapan, ada delapan utas yang menjalankan cabang rencana kueri ini. Penting untuk dipahami bahwa ini adalah keseluruhan rencana eksekusi sejauh menyangkut delapan utas ini – mereka tidak memiliki pengetahuan tentang rencana yang lebih luas.
Dalam rencana eksekusi serial, satu utas membaca data dari sumber data, memproses baris melalui sejumlah operator rencana, dan mengembalikan hasil ke tujuan (yang mungkin berupa jendela hasil kueri SSMS atau tabel database, misalnya).
Di cabang dari rencana eksekusi paralel, situasinya sangat mirip:setiap utas membaca data dari sumber, memproses baris melalui sejumlah operator rencana, dan mengembalikan hasil ke tujuan. Perbedaannya adalah tujuan adalah operator pertukaran (paralelisme), dan sumber data juga dapat menjadi pertukaran.
Di cabang oranye, sumber data adalah Pemindaian Indeks Cluster, dan tujuannya adalah sisi kanan pertukaran Repartition Streams. Sisi kanan bursa dikenal sebagai sisi produsen , karena terhubung ke cabang yang menambahkan data ke pertukaran.
Delapan utas di cabang oranye bekerja sama untuk memindai tabel dan menambahkan baris ke bursa. Pertukaran merakit baris menjadi paket berukuran halaman. Setelah paket penuh didorong melintasi pertukaran ke sisi lain. Jika pertukaran memiliki paket kosong lain yang tersedia untuk diisi, proses berlanjut hingga semua baris sumber data diproses (atau pertukaran kehabisan paket kosong).
Kita dapat melihat jumlah baris yang diproses pada setiap utas menggunakan tampilan Plan Tree di Plan Explorer:
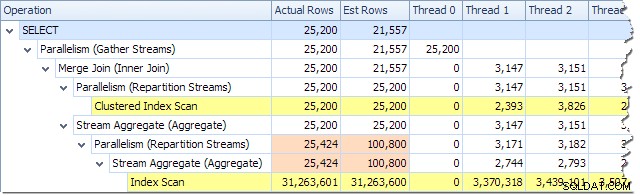
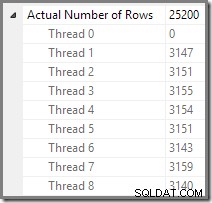
Plan Explorer memudahkan untuk melihat bagaimana baris didistribusikan di seluruh utas untuk semua operasi fisik dalam rencana. Di SSMS, Anda dibatasi untuk melihat distribusi baris untuk satu operator paket. Untuk melakukannya, klik ikon operator, buka jendela Properties, dan kemudian perluas node Actual Number of Rows. Grafik di bawah ini menunjukkan informasi SSMS untuk node Repartition Streams di perbatasan antara cabang oranye dan ungu:
Cabang Tiga (Hijau)
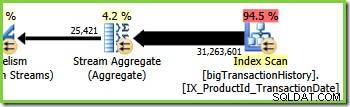
Cabang tiga mirip dengan cabang dua, tetapi berisi operator Stream Aggregate tambahan. Cabang hijau juga memiliki delapan utas, membuat total enam belas terlihat sejauh ini. Delapan thread green-branch membaca data dari Nonclustered Index Scan, melakukan semacam agregasi, dan meneruskan hasilnya ke sisi produsen dari pertukaran Repartition Streams lainnya.
Tooltip Plan Explorer untuk Stream Aggregate menunjukkan pengelompokan menurut ID produk dan menghitung ekspresi berlabel partialagg1005 :
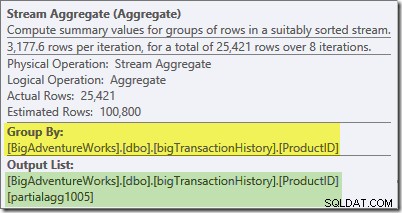
Tab Expressions menampilkan ekspresi yang merupakan hasil penghitungan baris dalam setiap grup:

Agregat Aliran sedang menghitung sebagian (juga dikenal sebagai agregat 'lokal'). Kualifikasi parsial (atau lokal) berarti bahwa setiap utas menghitung agregat pada baris yang dilihatnya. Baris dari Pemindaian Indeks didistribusikan di antara utas menggunakan skema berbasis permintaan:tidak ada distribusi baris yang tetap sebelumnya; utas menerima berbagai baris dari pemindaian saat mereka memintanya. Baris mana yang berakhir di utas mana yang pada dasarnya acak karena bergantung pada masalah waktu dan faktor lainnya.
Setiap utas melihat baris yang berbeda dari pemindaian, tetapi baris dengan ID produk yang sama dapat dilihat oleh lebih dari satu utas. Agregatnya 'sebagian' karena subtotal untuk grup ID produk tertentu dapat muncul di lebih dari satu utas; itu 'lokal' karena setiap utas menghitung hasilnya hanya berdasarkan baris yang diterimanya. Misalnya, ada 1.000 baris untuk ID produk #1 dalam tabel. Satu utas mungkin melihat 432 dari baris tersebut, sementara yang lain mungkin melihat 568. Kedua utas akan memiliki sebagian jumlah baris untuk ID produk #1 (432 di satu utas, 568 di utas lainnya).
Agregasi parsial adalah pengoptimalan kinerja karena mengurangi jumlah baris lebih awal daripada yang mungkin dilakukan. Di cabang hijau, agregasi awal menghasilkan lebih sedikit baris yang dirakit menjadi paket dan didorong melintasi pertukaran Repartition Stream.
Cabang 1 (Ungu)

Cabang ungu memiliki delapan utas lagi, membuat dua puluh empat sejauh ini. Setiap utas di cabang ini membaca baris dari dua pertukaran Aliran Repartisi, dan menulis baris ke pertukaran Aliran Pengumpulan. Cabang ini mungkin tampak rumit dan asing, tetapi ini hanya membaca baris dari sumber data dan mengirimkan hasil ke tujuan, seperti rencana kueri lainnya.
Sisi kanan paket menunjukkan data yang sedang dibaca dari sisi lain dari dua pertukaran Aliran Repartisi yang terlihat di cabang oranye dan hijau. Sisi pertukaran (kiri) ini dikenal sebagai konsumen samping, karena utas yang terpasang di sini membaca (memakan) baris. Delapan utas cabang ungu adalah konsumen data di dua pertukaran Aliran Repartisi.
Sisi kiri cabang ungu menunjukkan baris yang ditulis ke produser sisi pertukaran Gather Streams. delapan utas yang sama (yaitu konsumen di bursa Repartition Streams) melakukan produser peran di sini.
Setiap utas di cabang ungu menjalankan setiap operator di cabang, seperti halnya satu utas mengeksekusi setiap operasi dalam rencana eksekusi serial. Perbedaan utamanya adalah bahwa ada delapan utas yang berjalan secara bersamaan, masing-masing bekerja pada baris yang berbeda pada waktu tertentu, menggunakan instance yang berbeda. dari operator paket kueri.
Agregat Aliran di cabang ini adalah global agregat. Ini menggabungkan agregat parsial (lokal) yang dihitung di cabang hijau (ingat contoh hitungan 432 di satu utas dan 568 di utas lainnya) untuk menghasilkan total gabungan untuk setiap ID produk. Tooltip Plan Explorer menunjukkan ekspresi hasil global, berlabel Expr1004:
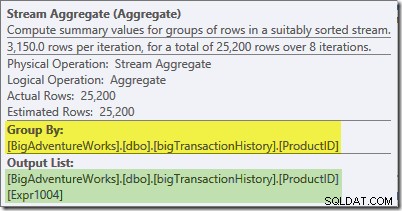
Hasil global yang benar per ID Produk dihitung dengan menjumlahkan agregat parsial, seperti yang diilustrasikan oleh tab Ekspresi:
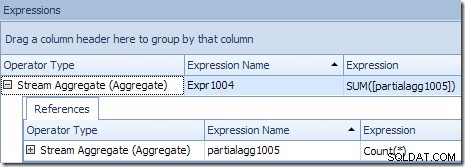
Untuk melanjutkan contoh (imajiner) kami, hasil yang benar dari 1.000 baris untuk ID produk #1 diperoleh dengan menjumlahkan dua subtotal 432 dan 568.
Masing-masing dari delapan utas cabang ungu membaca data dari sisi konsumen dari dua pertukaran Gather Streams, menghitung agregat global, melakukan Gabung Gabung pada ID produk, dan menambahkan baris ke pertukaran Gather Streams di paling kiri cabang ungu. Proses inti tidak jauh berbeda dari rencana serial biasa; perbedaannya adalah di mana baris dibaca, ke mana dikirim, dan bagaimana baris didistribusikan di antara utas…
Distribusi Baris Pertukaran
Pembaca yang waspada akan bertanya-tanya tentang beberapa detail pada saat ini. Bagaimana cabang ungu berhasil menghitung hasil yang benar per ID produk tetapi cabang hijau tidak bisa (hasil untuk ID produk yang sama tersebar di banyak utas)? Juga, jika ada delapan gabungan gabungan terpisah (satu per utas) bagaimana SQL Server menjamin bahwa baris yang akan bergabung berakhir di instance yang sama bergabung?
Kedua pertanyaan ini dapat dijawab dengan melihat cara kedua Aliran Repartisi bertukar baris rute dari sisi produsen (di cabang hijau dan oranye) ke sisi konsumen (di cabang ungu). Kami akan melihat pertukaran Repartition Streams yang berbatasan dengan cabang oranye dan ungu terlebih dahulu:
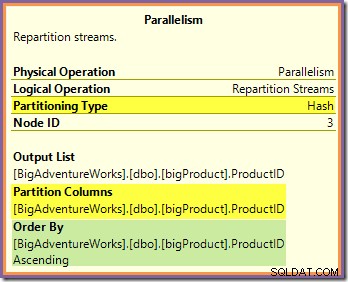
Pertukaran ini merutekan baris masuk (dari cabang oranye) menggunakan fungsi hash yang diterapkan ke kolom ID produk. Efeknya adalah semua baris untuk ID produk tertentu dijamin untuk diarahkan ke utas cabang ungu yang sama. Benang oranye dan ungu tidak tahu apa-apa tentang perutean ini; semua ini ditangani secara internal oleh bursa.
Yang diketahui oleh semua utas oranye adalah bahwa mereka mengembalikan baris ke iterator induk yang memintanya (sisi produsen pertukaran). Sama halnya, semua utas ungu 'tahu' bahwa mereka membaca baris dari sumber data. Pertukaran menentukan paket mana yang akan masuk ke baris utas oranye yang masuk, dan itu bisa menjadi salah satu dari delapan paket kandidat. Demikian pula, pertukaran menentukan paket mana yang akan membaca baris untuk memenuhi permintaan baca dari utas ungu.
Berhati-hatilah untuk tidak memperoleh gambaran mental tentang utas oranye (produsen) tertentu yang ditautkan langsung ke utas ungu (konsumen) tertentu. Itu bukan cara kerja rencana kueri ini. Produsen jeruk mungkin akhirnya mengirim baris ke semua konsumen ungu – perutean sepenuhnya bergantung pada nilai kolom ID produk di setiap baris yang diprosesnya.
Perhatikan juga bahwa paket baris di bursa hanya ditransfer saat sudah penuh (atau saat pihak produsen kehabisan data). Bayangkan pertukaran mengisi paket berturut-turut, di mana baris untuk paket tertentu mungkin berasal dari salah satu utas sisi produsen (oranye). Setelah paket penuh, paket tersebut akan diteruskan ke sisi konsumen, di mana utas konsumen (ungu) tertentu dapat mulai membaca darinya.
Pertukaran Repartition Streams yang membatasi cabang hijau dan ungu bekerja dengan cara yang sangat mirip:
Baris dirutekan ke paket dalam pertukaran ini menggunakan fungsi hash yang sama pada kolom partisi yang sama seperti untuk pertukaran oranye-ungu yang terlihat sebelumnya. Ini berarti keduanya Aliran Partisi Ulang menukar baris rute dengan ID produk yang sama ke utas cabang ungu yang sama.
Ini menjelaskan bagaimana Agregat Aliran di cabang ungu dapat menghitung agregat global – jika satu baris dengan ID produk tertentu terlihat pada utas cabang ungu tertentu, utas tersebut dijamin akan melihat semua baris untuk ID produk tersebut (dan tidak ada utas lainnya akan).
Kolom partisi pertukaran umum juga merupakan kunci gabung untuk gabung gabungan, sehingga semua baris yang mungkin dapat bergabung dijamin akan diproses oleh utas (ungu) yang sama.
Hal terakhir yang perlu diperhatikan adalah bahwa kedua bursa tersebut menjaga pesanan (alias 'penggabungan') pertukaran, seperti yang ditunjukkan pada atribut Order By di tooltips. Ini memenuhi persyaratan gabungan gabungan bahwa baris input diurutkan pada kunci gabungan. Perhatikan bahwa pertukaran tidak pernah mengurutkan baris sendiri, mereka hanya dapat dikonfigurasi untuk mempertahankan pesanan yang ada.
Benang Nol
Bagian terakhir dari rencana eksekusi terletak di sebelah kiri pertukaran Gather Streams. Itu selalu berjalan pada satu utas - utas yang sama digunakan untuk menjalankan seluruh rencana serial biasa. Utas ini selalu diberi label 'Utas 0' dalam rencana pelaksanaan dan terkadang disebut utas 'koordinator' (sebutan yang menurut saya tidak terlalu membantu).
Thread zero membaca baris dari sisi konsumen (kiri) dari pertukaran Gather Streams dan mengembalikannya ke klien. Tidak ada iterator utas nol selain dari pertukaran dalam contoh ini, tetapi jika ada, mereka semua akan berjalan pada utas tunggal yang sama. Perhatikan bahwa Gather Streams juga merupakan pertukaran gabungan (memiliki atribut Order By):

Paket paralel yang lebih kompleks dapat mencakup zona eksekusi serial selain yang ada di sebelah kiri pertukaran Gather Streams terakhir. Zona serial ini tidak dijalankan di utas nol, tetapi itu adalah detail untuk dijelajahi di lain waktu.
Utas yang dicadangkan dan digunakan ditinjau kembali
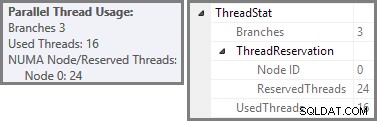
Kita telah melihat bahwa rencana paralel ini berisi tiga cabang. Ini menjelaskan mengapa SQL Server dipesan 24 utas (tiga cabang di DOP 8). Pertanyaannya adalah mengapa hanya 16 utas yang dilaporkan sebagai 'digunakan' pada tangkapan layar di atas.
Ada dua bagian untuk jawabannya. Bagian pertama tidak berlaku untuk rencana ini, tetapi tetap penting untuk diketahui. Jumlah cabang yang dilaporkan adalah jumlah maksimum yang dapat dijalankan bersamaan .
Seperti yang Anda ketahui, operator paket tertentu 'memblokir' – artinya mereka harus menggunakan semua baris input mereka sebelum mereka dapat menghasilkan baris output pertama. Contoh paling jelas dari operator pemblokiran (juga dikenal sebagai stop-and-go) adalah Sortir. Sortir tidak dapat mengembalikan baris pertama dalam urutan terurut sebelum ia melihat setiap baris input karena baris input terakhir mungkin mengurutkan terlebih dahulu.
Operator dengan banyak input (bergabung dan serikat, misalnya) dapat memblokir sehubungan dengan satu input, tetapi non-pemblokiran ('berpipa') sehubungan dengan yang lain. Contohnya adalah hash join – input build memblokir, tetapi input probe disalurkan. Input build memblokir karena membuat tabel hash yang digunakan untuk menguji baris probe.
Kehadiran operator pemblokiran berarti bahwa satu atau lebih cabang paralel mungkin dijamin selesai sebelum orang lain dapat memulai. Jika ini terjadi, SQL Server dapat menggunakan kembali utas yang digunakan untuk memproses cabang yang telah selesai untuk cabang selanjutnya dalam urutan. SQL Server sangat konservatif tentang reservasi utas, jadi hanya cabang yang dijamin untuk menyelesaikan sebelum yang lain dimulai, manfaatkan pengoptimalan pemesanan utas ini. Paket kueri kami tidak mengandung operator pemblokiran, jadi jumlah cabang yang dilaporkan hanyalah jumlah total cabang.
Bagian kedua dari jawabannya adalah bahwa utas masih dapat digunakan kembali jika terjadi untuk diselesaikan sebelum utas di cabang lain dimulai. Jumlah utas lengkap masih dicadangkan dalam kasus ini, tetapi penggunaan sebenarnya mungkin lebih rendah. Berapa banyak utas yang sebenarnya digunakan oleh rencana paralel bergantung pada masalah waktu antara lain, dan dapat bervariasi di antara eksekusi.
Utas paralel tidak semuanya mulai dieksekusi pada saat yang sama, tetapi sekali lagi detailnya harus menunggu kesempatan lain. Mari kita lihat kembali rencana kueri untuk melihat bagaimana utas dapat digunakan kembali, meskipun tidak ada operator pemblokiran:
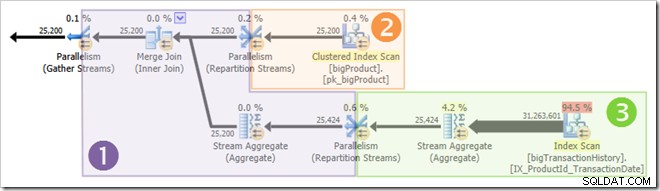
Jelas bahwa utas di cabang satu tidak dapat diselesaikan sebelum utas di cabang dua atau tiga dimulai, jadi tidak ada kemungkinan utas digunakan kembali di sana. Cabang tiga juga tidak mungkin untuk diselesaikan sebelum cabang satu atau cabang dua dimulai karena memiliki begitu banyak pekerjaan yang harus dilakukan (hampir 32 juta baris untuk digabungkan).
Cabang dua adalah masalah yang berbeda. Ukuran tabel produk yang relatif kecil berarti ada peluang yang layak bahwa cabang dapat menyelesaikan pekerjaannya sebelum cabang tiga dimulai. Jika membaca tabel produk tidak menghasilkan I/O fisik apa pun, delapan utas tidak akan membutuhkan waktu lama untuk membaca 25.200 baris dan mengirimkannya ke pertukaran Repartition Streams batas oranye-ungu.
Inilah yang terjadi dalam uji coba yang digunakan untuk tangkapan layar yang terlihat sejauh ini di pos ini:delapan utas cabang oranye selesai dengan cukup cepat sehingga dapat digunakan kembali untuk cabang hijau. Secara total, enam belas utas unik digunakan, jadi itulah yang dilaporkan dalam rencana eksekusi.
Jika kueri dijalankan kembali dengan cache dingin, penundaan yang diperkenalkan oleh I/O fisik sudah cukup untuk memastikan bahwa utas cabang hijau dimulai sebelum utas cabang oranye selesai. Tidak ada utas yang digunakan kembali, sehingga rencana eksekusi melaporkan bahwa semua 24 utas yang dicadangkan sebenarnya telah digunakan:
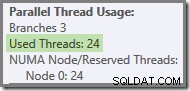
Lebih umum, sejumlah 'utas yang digunakan' antara dua ekstrem (16 dan 24 untuk rencana kueri ini) dimungkinkan:
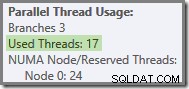
Terakhir, perhatikan bahwa utas yang menjalankan bagian serial dari rencana di sebelah kiri Aliran Pengumpulan terakhir tidak dihitung dalam total utas paralel. Ini bukan utas tambahan yang ditambahkan untuk mengakomodasi eksekusi paralel.
Pemikiran Akhir
Keindahan model pertukaran yang digunakan oleh SQL Server untuk mengimplementasikan eksekusi paralel adalah bahwa semua kerumitan buffering dan pemindahan baris antar utas disembunyikan di dalam operator pertukaran (Paralelisme). Sisa rencana dibagi menjadi 'cabang' yang rapi, dibatasi oleh pertukaran. Dalam sebuah cabang, setiap operator berperilaku sama seperti dalam rencana serial – di hampir semua kasus, operator cabang tidak mengetahui bahwa rencana yang lebih luas menggunakan eksekusi paralel sama sekali.
Kunci untuk memahami eksekusi paralel adalah (secara mental) memecah rencana paralel di batas pertukaran, dan membayangkan setiap cabang sebagai serial yang terpisah DOP rencana, semua menjalankan konkurensi pada subset baris yang berbeda. Ingat khususnya bahwa setiap paket serial tersebut menjalankan semua operator di cabang itu – SQL Server tidak jalankan setiap operator di utasnya sendiri!
Memahami perilaku yang paling mendetail memang membutuhkan sedikit pemikiran, terutama tentang bagaimana baris diarahkan dalam pertukaran, dan bagaimana mesin menjamin hasil yang benar, tetapi sebagian besar hal yang perlu diketahui memerlukan sedikit pemikiran, bukan?