Saat ini, replikasi diberikan dalam ketersediaan tinggi dan lingkungan yang toleran terhadap kesalahan untuk hampir semua teknologi database yang Anda gunakan. Ini adalah topik yang telah kita lihat berulang kali, tetapi tidak pernah ketinggalan zaman.
Jika Anda menggunakan TimescaleDB, jenis replikasi yang paling umum adalah replikasi streaming, tetapi bagaimana cara kerjanya?
Di blog ini, kita akan meninjau beberapa konsep yang terkait dengan replikasi dan kita akan fokus pada replikasi streaming untuk TimescaleDB, yang merupakan fungsionalitas yang diwarisi dari mesin PostgreSQL yang mendasarinya. Kemudian, kita akan melihat bagaimana ClusterControl dapat membantu kita mengonfigurasinya.
Jadi, replikasi streaming didasarkan pada pengiriman catatan WAL dan menerapkannya ke server siaga. Jadi, pertama, mari kita lihat apa itu WAL.
WAL
Write Ahead Log (WAL) adalah metode standar untuk memastikan integritas data, secara otomatis diaktifkan secara default.
WAL adalah log REDO di TimescaleDB. Tapi, apa itu log REDO?
Log REDO berisi semua perubahan yang dibuat dalam database dan digunakan oleh replikasi, pemulihan, pencadangan online, dan pemulihan titik waktu (PITR). Setiap perubahan yang belum diterapkan pada halaman data dapat dilakukan kembali dari log REDO.
Menggunakan WAL menghasilkan pengurangan jumlah penulisan disk secara signifikan, karena hanya file log yang perlu di-flush ke disk untuk menjamin bahwa transaksi dilakukan, bukan setiap file data yang diubah oleh transaksi.
Catatan WAL akan menentukan, sedikit demi sedikit, perubahan yang dilakukan pada data. Setiap catatan WAL akan ditambahkan ke dalam file WAL. Posisi insert adalah Log Sequence Number (LSN) yang merupakan offset byte ke dalam log, meningkat dengan setiap record baru.
WAL disimpan di direktori pg_wal, di bawah direktori data. File-file ini memiliki ukuran default 16MB (ukurannya dapat diubah dengan mengubah opsi konfigurasi --with-wal-segsize saat membangun server). Mereka memiliki nama tambahan yang unik, dalam format berikut:"00000001 00000000 00000000".
Jumlah file WAL yang terdapat dalam pg_wal akan bergantung pada nilai yang ditetapkan untuk parameter min_wal_size dan max_wal_size dalam file konfigurasi postgresql.conf.
Salah satu parameter yang perlu kita siapkan saat mengonfigurasi semua instalasi TimescaleDB adalah wal_level. Ini menentukan berapa banyak informasi yang ditulis ke WAL. Nilai defaultnya minimal, yang hanya menulis informasi yang diperlukan untuk memulihkan dari crash atau shutdown langsung. Arsip menambahkan pencatatan yang diperlukan untuk pengarsipan WAL; hot_standby selanjutnya menambahkan informasi yang diperlukan untuk menjalankan kueri hanya-baca di server siaga; dan, akhirnya logis menambahkan informasi yang diperlukan untuk mendukung decoding logis. Parameter ini memerlukan restart, jadi, akan sulit untuk mengubah database produksi yang sedang berjalan jika kita lupa akan hal itu.
Replikasi Streaming
Replikasi streaming didasarkan pada metode pengiriman log. Catatan WAL langsung dipindahkan dari satu server database ke server lain untuk diterapkan. Kita dapat mengatakan bahwa itu adalah PITR berkelanjutan.
Transfer ini dilakukan dengan dua cara berbeda, dengan mentransfer catatan WAL satu file (segmen WAL) pada satu waktu (pengiriman log berbasis file) dan dengan mentransfer catatan WAL (file WAL terdiri dari catatan WAL) dengan cepat (berbasis catatan pengiriman log), antara server master dan satu atau beberapa server budak, tanpa menunggu file WAL diisi.
Dalam praktiknya, proses yang disebut penerima WAL, yang berjalan di server budak, akan terhubung ke server master menggunakan koneksi TCP/IP. Di server master, ada proses lain, bernama pengirim WAL, dan bertanggung jawab untuk mengirim pendaftar WAL ke server budak saat terjadi.
Replikasi streaming dapat direpresentasikan sebagai berikut:
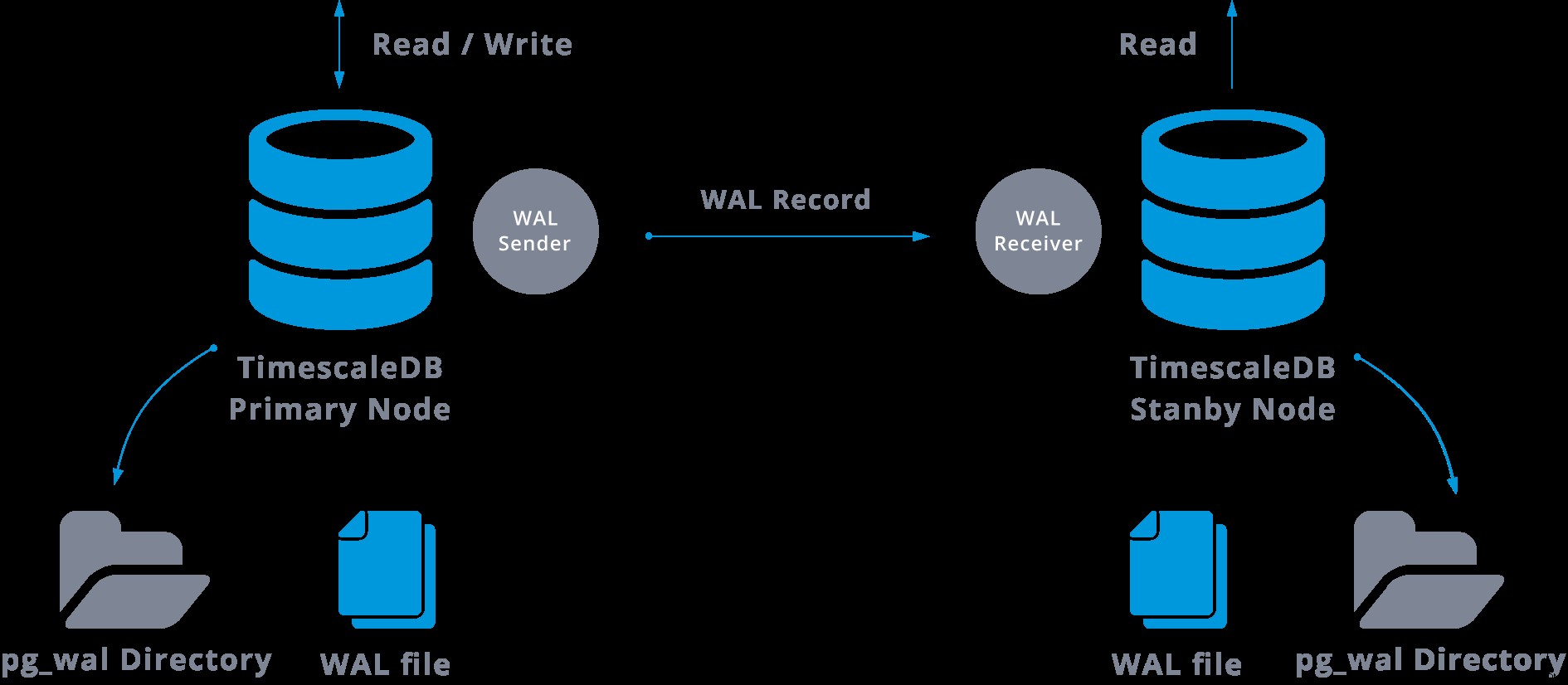
Dengan melihat diagram di atas kita dapat berpikir, apa yang terjadi ketika komunikasi antara pengirim WAL dan penerima WAL gagal?
Saat mengonfigurasi replikasi streaming, kami memiliki opsi untuk mengaktifkan pengarsipan WAL.
Langkah ini sebenarnya tidak wajib, tetapi sangat penting untuk pengaturan replikasi yang kuat, karena diperlukan untuk menghindari server utama mendaur ulang file WAL lama yang belum diterapkan ke slave. Jika ini terjadi, kita perlu membuat ulang replika dari awal.
Saat mengonfigurasi replikasi dengan pengarsipan berkelanjutan, kami memulai dari pencadangan dan, untuk mencapai status sinkronisasi dengan master, kami perlu menerapkan semua perubahan yang dihosting di WAL yang terjadi setelah pencadangan. Selama proses ini, standby terlebih dahulu akan mengembalikan semua WAL yang tersedia di lokasi arsip (dilakukan dengan memanggil restore_command). Restore_command akan gagal ketika kita mencapai catatan WAL terakhir yang diarsipkan, jadi setelah itu, standby akan melihat pada direktori pg_wal untuk melihat apakah ada perubahan di sana (ini sebenarnya dibuat untuk menghindari kehilangan data ketika server master crash dan beberapa perubahan yang telah dipindahkan ke replika dan diterapkan di sana belum diarsipkan).
Jika gagal, dan catatan yang diminta tidak ada di sana, maka master akan mulai berkomunikasi dengan master melalui replikasi streaming.
Setiap kali streaming replikasi gagal, itu akan kembali ke langkah 1 dan mengembalikan catatan dari arsip lagi. Loop pengambilan dari arsip, pg_wal, dan melalui replikasi streaming berlangsung hingga server dihentikan atau failover dipicu oleh file pemicu.
Ini akan menjadi diagram konfigurasi seperti itu:
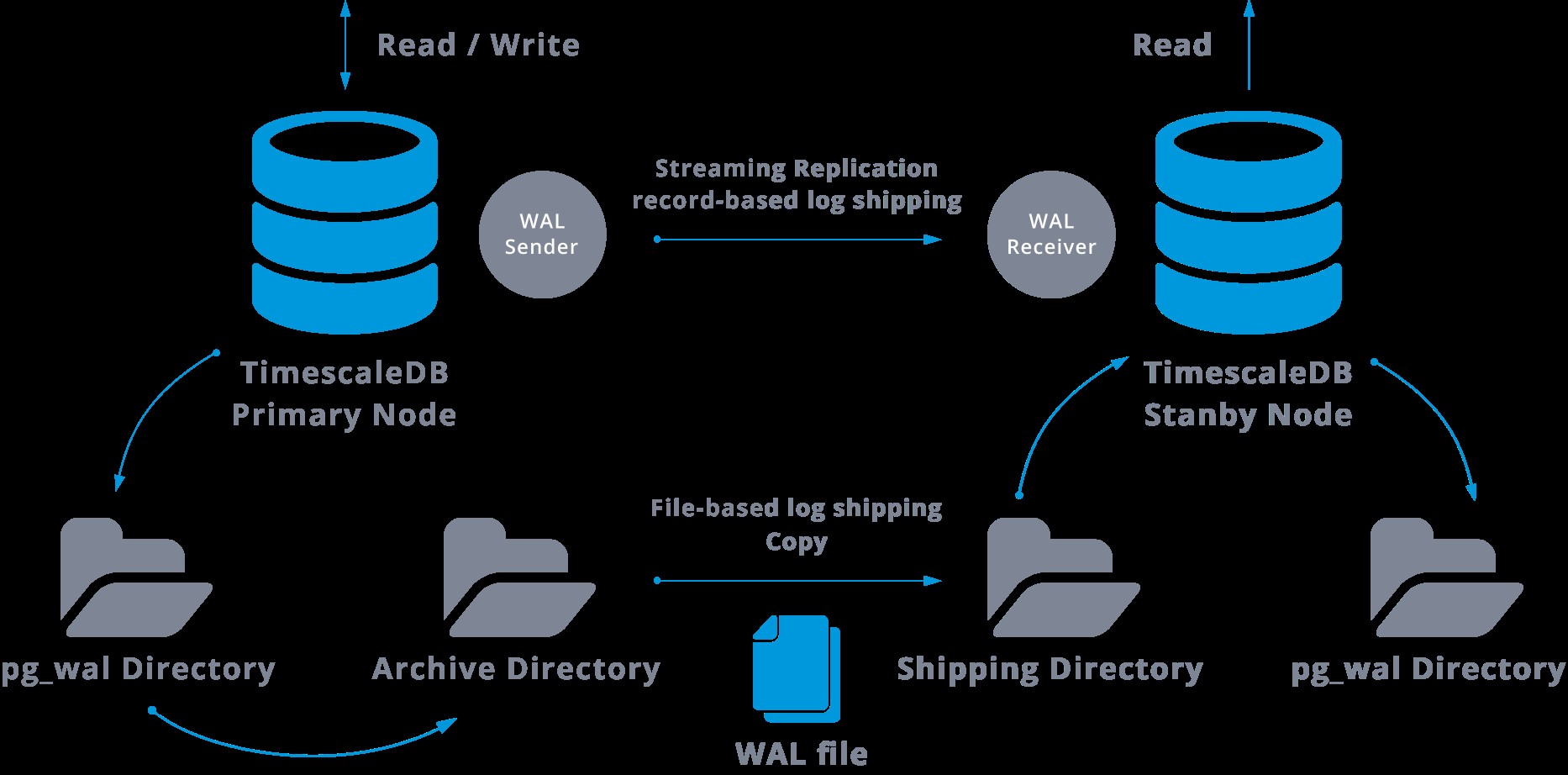
Replikasi streaming secara default tidak sinkron, jadi pada saat tertentu kita dapat memiliki beberapa transaksi yang dapat dilakukan di master dan belum direplikasi ke server siaga. Ini menyiratkan beberapa potensi kehilangan data.
Namun, penundaan antara komit dan dampak perubahan pada replika ini seharusnya sangat kecil (beberapa milidetik), dengan asumsi tentu saja bahwa server replika cukup kuat untuk mengikuti beban.
Untuk kasus-kasus di mana bahkan risiko kehilangan data kecil tidak dapat ditoleransi, kita dapat menggunakan fitur replikasi sinkron.
Dalam replikasi sinkron, setiap komit dari transaksi tulis akan menunggu hingga konfirmasi diterima bahwa komit telah ditulis ke disk log tulis di depan server utama dan server siaga.
Metode ini meminimalkan kemungkinan kehilangan data, karena untuk itu kita memerlukan master dan standby untuk gagal secara bersamaan.
Kelemahan yang jelas dari konfigurasi ini adalah bahwa waktu respons untuk setiap transaksi tulis meningkat, karena kita harus menunggu sampai semua pihak merespons. Jadi waktu untuk komit adalah, minimal, perjalanan pulang pergi antara master dan replika. Transaksi read-only tidak akan terpengaruh oleh itu.
Untuk menyiapkan replikasi sinkron, setiap server siaga harus menetapkan nama_aplikasi di primary_conninfo file recovery.conf:primary_conninfo ='...aplication_name=slaveX' .
Kita juga perlu menentukan daftar server siaga yang akan mengambil bagian dalam replikasi sinkron:synchronous_standby_name ='slaveX,slaveY'.
Kami dapat menyiapkan satu atau beberapa server sinkron, dan parameter ini juga menentukan metode mana (PERTAMA dan APAPUN) untuk memilih siaga sinkron dari yang terdaftar.
Untuk menerapkan TimescaleDB dengan penyiapan replikasi streaming (sinkron atau asinkron), kita dapat menggunakan ClusterControl, seperti yang dapat kita lihat di sini.
Setelah kami mengonfigurasi replikasi kami, dan itu aktif dan berjalan, kami perlu memiliki beberapa fitur tambahan untuk pemantauan dan manajemen cadangan. ClusterControl memungkinkan kami untuk memantau dan mengelola pencadangan/retensi klaster TimescaleDB kami dari tempat yang sama tanpa alat eksternal apa pun.
Cara Mengonfigurasi Replikasi Streaming di TimescaleDB
Menyiapkan replikasi streaming adalah tugas yang memerlukan beberapa langkah yang harus diikuti secara menyeluruh. Jika Anda ingin mengkonfigurasinya secara manual, Anda dapat mengikuti blog kami tentang topik ini.
Namun, Anda dapat menerapkan atau mengimpor TimescaleDB Anda saat ini di ClusterControl, dan kemudian, Anda dapat mengonfigurasi replikasi streaming dengan beberapa klik. Mari kita lihat bagaimana kita bisa melakukannya.
Untuk tugas ini, kami akan menganggap Anda memiliki klaster TimescaleDB Anda yang dikelola oleh ClusterControl. Buka ClusterControl -> Pilih Cluster -> Cluster Actions -> Tambahkan Replication Slave.
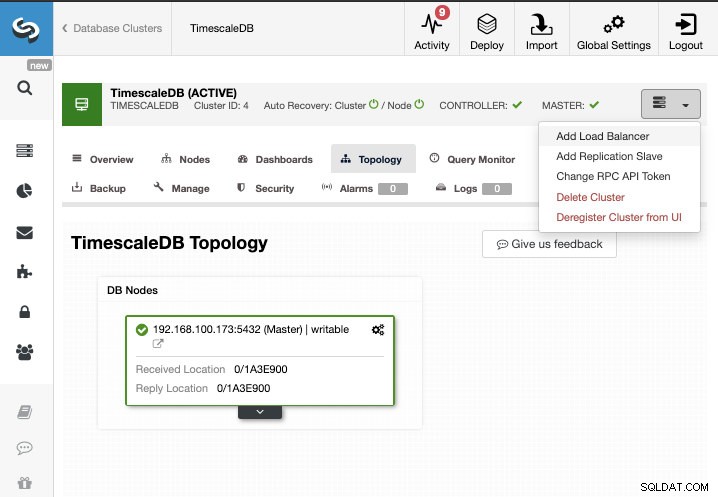
Kita dapat membuat slave replikasi baru (standby) atau kita dapat mengimpor yang sudah ada. Dalam hal ini, kami akan membuat yang baru.
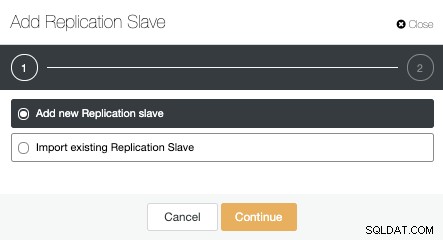
Sekarang, kita harus memilih node Master, menambahkan IP Address atau hostname untuk server standby yang baru, dan port database. Kami juga dapat menentukan apakah kami ingin ClusterControl menginstal perangkat lunak dan jika kami ingin mengonfigurasi replikasi streaming sinkron atau asinkron.
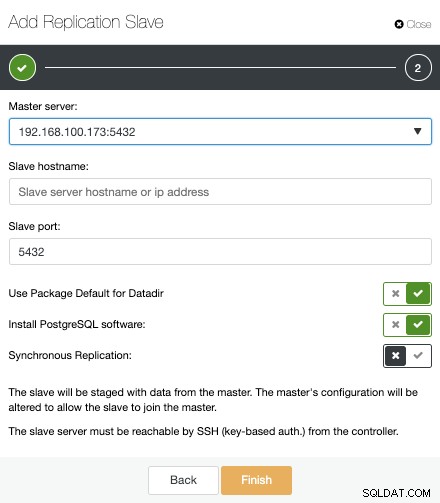
Itu saja. Kita hanya perlu menunggu sampai ClusterControl menyelesaikan pekerjaan. Kami dapat memantau status dari bagian Aktivitas.
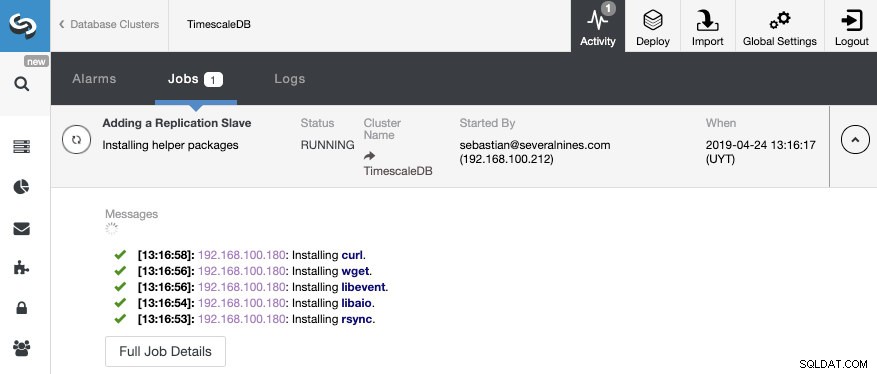
Setelah pekerjaan selesai, kita harus mengkonfigurasi replikasi streaming dan kita dapat memeriksa topologi baru di bagian Tampilan Topologi ClusterControl.
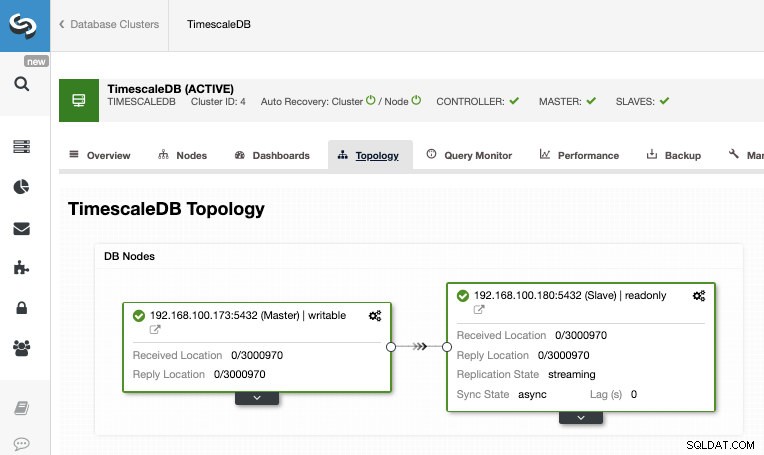
Dengan menggunakan ClusterControl, Anda juga dapat melakukan beberapa tugas manajemen pada TimescaleDB Anda seperti pencadangan, pemantauan dan peringatan, failover otomatis, menambahkan node, menambahkan penyeimbang beban, dan banyak lagi.
Kegagalan
Seperti yang bisa kita lihat, TimescaleDB menggunakan aliran catatan write-ahead log (WAL) untuk menjaga sinkronisasi database siaga. Jika server utama gagal, standby berisi hampir semua data dari server utama dan dapat dengan cepat membuat server database master baru. Ini bisa sinkron atau asinkron dan hanya dapat dilakukan untuk seluruh server database.
Untuk memastikan ketersediaan tinggi secara efektif, tidak cukup hanya memiliki arsitektur master-standby. Kami juga perlu mengaktifkan beberapa bentuk failover otomatis, jadi jika ada yang gagal, kami dapat memiliki penundaan sekecil mungkin dalam melanjutkan fungsi normal.
TimescaleDB tidak menyertakan mekanisme failover otomatis untuk mengidentifikasi kegagalan pada database master dan memberi tahu slave untuk mengambil kepemilikan, sehingga akan memerlukan sedikit kerja di sisi DBA. Anda juga hanya akan memiliki satu server yang berfungsi, jadi pembuatan ulang arsitektur master-standby perlu dilakukan, sehingga kita kembali ke situasi normal yang sama seperti sebelum masalah.
ClusterControl menyertakan fitur failover otomatis untuk TimescaleDB guna meningkatkan mean time to repair (MTTR) di lingkungan ketersediaan tinggi Anda. Jika terjadi kegagalan, ClusterControl akan mempromosikan slave paling canggih ke master, dan akan mengkonfigurasi ulang slave yang tersisa untuk terhubung ke master baru. HAProxy juga dapat digunakan secara otomatis untuk menawarkan titik akhir basis data tunggal ke aplikasi, sehingga tidak terpengaruh oleh perubahan server master.
Batasan
Referensi terkait ClusterControl untuk TimescaleDB Cara Mudah Menerapkan Replikasi Streaming TimescaleDB PostgreSQL - Penyelaman MendalamKami memiliki beberapa batasan yang terkenal saat menggunakan Replikasi Streaming:
- Kami tidak dapat mereplikasi ke versi atau arsitektur yang berbeda
- Kami tidak dapat mengubah apa pun di server siaga
- Kami tidak memiliki banyak perincian tentang apa yang dapat kami tiru
Jadi, untuk mengatasi keterbatasan ini, kami memiliki fitur replikasi logis. Untuk mengetahui lebih lanjut tentang jenis replikasi ini, Anda dapat memeriksa blog berikut.
Kesimpulan
Topologi master-standby memiliki banyak kegunaan yang berbeda seperti analytics, backup, high availability, failover. Bagaimanapun, penting untuk memahami cara kerja replikasi streaming di TimescaleDB. Ini juga berguna untuk memiliki sistem untuk mengelola semua cluster dan memberi Anda kemungkinan untuk membuat topologi ini dengan cara yang mudah. Di blog ini, kami melihat cara mencapainya dengan menggunakan ClusterControl, dan kami meninjau beberapa konsep dasar tentang replikasi streaming.