Ini adalah bagian terakhir dari seri lima bagian yang mempelajari secara mendalam cara rencana paralel mode baris SQL Server mulai dijalankan. Bagian 1 menginisialisasi konteks eksekusi nol untuk tugas induk, dan bagian 2 membuat pohon pemindaian kueri. Bagian 3 memulai pemindaian kueri, melakukan beberapa fase awal pemrosesan, dan memulai tugas paralel tambahan pertama di cabang C. Bagian 4 menjelaskan sinkronisasi pertukaran, dan memulai cabang rencana paralel C &D.
Tugas Paralel Cabang B Dimulai
Pengingat akan cabang-cabang dalam denah paralel ini (klik untuk memperbesar):
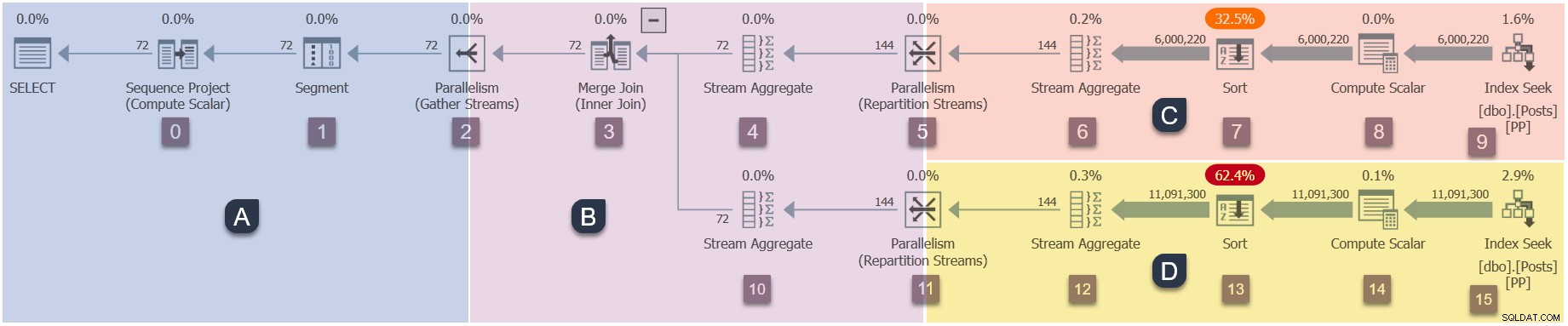
Ini adalah tahap keempat dalam urutan eksekusi:
- Cabang A (tugas induk).
- Cabang C (tugas paralel tambahan).
- Cabang D (tugas paralel tambahan).
- Cabang B (tugas paralel tambahan).
Satu-satunya utas yang aktif saat ini (tidak ditangguhkan di CXPACKET ) adalah tugas induk , yang berada di sisi konsumen dari pertukaran aliran partisi ulang di node 11 di Cabang B:
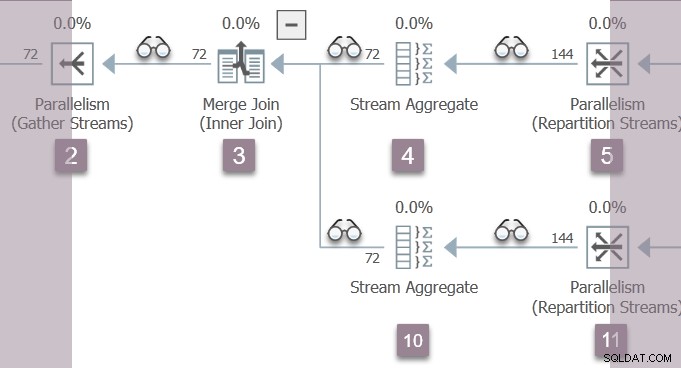
Tugas induk sekarang kembali dari fase awal bersarang panggilan, pengaturan waktu berlalu dan CPU di profiler saat berjalan. Waktu aktif pertama dan terakhir tidak diperbarui selama pemrosesan fase awal. Ingat angka-angka ini sedang direkam dengan konteks eksekusi nol — tugas paralel Cabang B belum ada.
Tugas induk naik pohon dari simpul 11, melalui aliran agregat di simpul 10 dan penggabungan bergabung di simpul 3, kembali ke kumpulan arus pertukaran di simpul 2.
Pemrosesan fase awal sekarang selesai .
Dengan EarlyPhases yang asli panggil di simpul 2 kumpulkan aliran tukar akhirnya selesai, tugas induk kembali untuk membuka pertukaran itu (Anda mungkin akan mengingat panggilan itu dari awal seri ini). Metode terbuka di simpul 2 sekarang memanggil CQScanExchangeNew::StartAllProducers untuk membuat tugas paralel untuk Cabang B.
Tugas induk sekarang menunggu di CXPACKET di konsumen sisi node 2 mengumpulkan aliran menukarkan. Penantian ini akan berlanjut hingga tugas Cabang B yang baru dibuat telah menyelesaikan Open . yang disarangkan menelepon dan kembali untuk menyelesaikan pembukaan sisi produser dari pertukaran aliran berkumpul.
Tugas paralel Cabang B terbuka
Dua tugas paralel baru di Cabang B dimulai dari produser sisi node 2 mengumpulkan aliran menukarkan. Mengikuti model eksekusi berulang mode baris biasa, mereka memanggil:
CQScanXProducerNew::Open(sisi produsen node 2 terbuka).CQScanProfileNew::Open(profiler untuk simpul 3).CQScanMergeJoinNew::Open(simpul 3 gabung gabung).CQScanProfileNew::Open(profiler untuk simpul 4).CQScanStreamAggregateNew::Open(agregat aliran simpul 4).CQScanProfileNew::Open(profiler untuk simpul 5).CQScanExchangeNew::Open(pertukaran aliran partisi ulang).
Kedua tugas paralel mengikuti input luar (atas) ke gabungan gabungan, seperti yang dilakukan pemrosesan fase awal.
Menyelesaikan pertukaran
Saat tugas Cabang B tiba di konsumen sisi pertukaran aliran partisi ulang di node 5, setiap tugas:
- Mendaftar dengan port pertukaran (
CXPort). - Membuat pipa (
CXPipe) yang menghubungkan tugas ini dengan satu atau lebih tugas sampingan produsen (tergantung pada jenis pertukaran). Pertukaran saat ini adalah aliran partisi ulang, sehingga setiap tugas konsumen memiliki dua pipa (pada DOP 2). Setiap konsumen dapat menerima baris dari salah satu dari dua produsen. - Menambahkan
CXPipeMergeuntuk menggabungkan baris dari beberapa pipa (karena ini adalah pertukaran yang mempertahankan pesanan). - Membuat paket baris (bingung bernama
CXPacket) digunakan untuk kontrol aliran dan untuk menyangga baris melintasi pipa pertukaran. Ini dialokasikan dari memori kueri yang diberikan sebelumnya.
Setelah kedua tugas paralel sisi konsumen menyelesaikan pekerjaan itu, pertukaran node 5 siap digunakan. Kedua konsumen (di Cabang B) dan dua produsen (di Cabang C) semuanya telah membuka port pertukaran, sehingga node 5 CXPACKET menunggu akhir .
Pos pemeriksaan
Seperti yang terjadi:
- Tugas induk di Cabang A sedang menunggu di
CXPACKETdi sisi konsumen node 2 mengumpulkan pertukaran aliran. Penantian ini akan berlanjut hingga kedua produsen node 2 kembali dan membuka bursa. - Dua tugas paralel di Cabang B dapat dijalankan . Mereka baru saja membuka sisi konsumen dari pertukaran aliran partisi ulang di node 5.
- Dua tugas paralel di Cabang C baru saja dirilis dari
CXPACKETmereka tunggu, dan sekarang dapat dijalankan . Dua aliran agregat pada node 6 (satu per tugas paralel) dapat mulai menggabungkan baris dari dua jenis pada node 7. Ingat indeks mencari pada node 9 ditutup beberapa waktu lalu, ketika jenis menyelesaikan fase input mereka. - Dua tugas paralel di Cabang D sedang menunggu di
CXPACKETdi sisi produsen pertukaran aliran partisi ulang di node 11. Mereka menunggu sisi konsumen dari node 11 dibuka oleh dua tugas paralel di Cabang B. Pencarian indeks telah ditutup, dan jenis siap untuk transisi ke fase keluaran mereka.
Beberapa cabang aktif
Ini adalah pertama kalinya kami memiliki banyak cabang (B dan C) yang aktif pada saat yang sama, yang mungkin sulit untuk didiskusikan. Untungnya, desain kueri demo sedemikian rupa sehingga agregat aliran di Cabang C hanya akan menghasilkan beberapa baris. Sejumlah kecil baris keluaran yang sempit akan dengan mudah masuk ke dalam paket baris buffer di node 5 partisi ulang aliran pertukaran. Oleh karena itu, tugas Cabang C dapat melanjutkan pekerjaannya (dan akhirnya ditutup) tanpa menunggu partisi ulang node 5 mengalirkan sisi konsumen untuk mengambil baris apa pun.
Dengan mudah, ini berarti kita dapat membiarkan dua tugas paralel Cabang C berjalan di latar belakang tanpa mengkhawatirkannya. Kita hanya perlu memperhatikan apa yang dilakukan oleh dua tugas paralel Cabang B.
Pembukaan Cabang B selesai
Pengingat untuk Cabang B:
Dua pekerja paralel di Cabang B kembali dari Open panggilan di node 5 partisi ulang aliran pertukaran. Ini membawa mereka kembali melalui agregat aliran di simpul 4, ke gabungan gabungan di simpul 3.
Karena kita naik pohon di Open metode, profiler di atas node 5 dan node 4 merekam terakhir aktif waktu, serta akumulasi waktu yang telah berlalu dan CPU (per tugas). Kami tidak menjalankan fase awal pada tugas induk sekarang, jadi angka yang direkam untuk konteks eksekusi nol tidak terpengaruh.
Saat penggabungan bergabung, dua tugas paralel Cabang B mulai turun input bagian dalam (bawah), membawanya melalui agregat aliran di node 10 (dan beberapa profiler) ke sisi konsumen dari pertukaran aliran partisi ulang di node 11.
Cabang D melanjutkan eksekusi
Pengulangan peristiwa Cabang C pada node 5 sekarang terjadi pada aliran partisi ulang node 11. Sisi konsumen dari pertukaran node 11 selesai dan dibuka. Kedua produser di Cabang D mengakhiri CXPACKET mereka menunggu, menjadi dapat dijalankan lagi. Kami akan membiarkan tugas Cabang D berjalan di latar belakang, menempatkan hasilnya di buffer pertukaran.
Sekarang ada enam tugas paralel (masing-masing dua di Cabang B, C, dan D) secara kooperatif berbagi waktu pada dua penjadwal yang ditugaskan untuk tugas paralel tambahan dalam kueri ini.
Pembukaan Cabang A Selesai
Dua tugas paralel di Cabang B kembali dari Open panggilan di node 11 partisi ulang aliran pertukaran, melewati node 10 agregat aliran, melalui gabungan bergabung di node 3, dan kembali ke sisi produsen dari mengumpulkan aliran di node 2. Profiler terakhir aktif dan akumulasi waktu berlalu &CPU diperbarui saat kami menaiki pohon di Open . yang disarangkan metode.
Di produser sisi pertukaran aliran berkumpul, dua tugas paralel Cabang B menyinkronkan pembukaan port pertukaran, lalu tunggu di CXPACKET untuk membuka sisi konsumen.
Tugas induk menunggu di sisi konsumen aliran berkumpul sekarang dirilis dari CXPACKET tunggu, yang memungkinkannya untuk menyelesaikan pembukaan port pertukaran di sisi konsumen. Ini pada gilirannya membebaskan produsen dari CXPACKET (singkat) mereka tunggu. Aliran pengumpulan node 2 sekarang telah dibuka oleh semua pemilik.
Menyelesaikan Pemindaian Kueri
Tugas induk sekarang naik ke pohon pemindaian kueri dari pertukaran aliran pengumpulan, kembali dari Open panggilan di bursa, segmen , dan proyek urutan operator di Cabang A.
Ini menyelesaikan pembukaan pohon pemindaian kueri, dimulai semua itu beberapa waktu lalu dengan panggilan ke CQueryScan::StartupQuery . Semua cabang dari rencana paralel sekarang telah mulai dijalankan.
Mengembalikan baris
Rencana eksekusi siap untuk mulai mengembalikan baris sebagai respons terhadap GetRow panggilan di root dari pohon pemindaian kueri, dimulai dengan panggilan ke CQueryScan::GetRow . Saya tidak akan menjelaskan secara rinci, karena ini benar-benar di luar cakupan artikel tentang bagaimana rencana paralel memulai .
Namun, urutan singkatnya adalah:
- Tugas induk memanggil
GetRowpada proyek urutan, yang memanggilGetRowpada segmen, yang memanggilGetRowpada konsumen sisi pertukaran arus berkumpul. - Jika belum ada baris yang tersedia di bursa, tugas induk menunggu di
CXCONSUMER. - Sementara itu, tugas paralel Cabang B yang berjalan secara independen telah memanggil
GetRowsecara rekursif mulai dari produsen sisi pertukaran arus berkumpul. - Baris dipasok ke Cabang B oleh sisi konsumen dari pertukaran aliran partisi ulang di node 5 dan 12.
- Cabang C dan D masih memproses baris dari jenisnya melalui agregat aliran masing-masing. Tugas Cabang B mungkin harus menunggu di
CXCONSUMERdi partisi ulang, streaming node 5 dan 12 agar paket baris lengkap tersedia. - Baris yang muncul dari
GetRowbersarang panggilan di Cabang B dirakit menjadi paket baris di produsen sisi pertukaran arus berkumpul. - Tugas induk
CXCONSUMERtunggu di sisi konsumen aliran pengumpulan berakhir saat paket tersedia. - Sebuah baris pada satu waktu kemudian diproses melalui operator induk di Cabang A, dan akhirnya ke klien.
- Akhirnya, baris habis, dan
Close. bersarang panggilan riak ke bawah pohon, melintasi bursa, dan eksekusi paralel berakhir.
Ringkasan dan Catatan Akhir
Pertama, ringkasan urutan eksekusi dari rencana eksekusi paralel khusus ini:
- Tugas orang tua membuka cabang A . Fase awal pemrosesan dimulai pada pertukaran aliran pengumpulan.
- Panggilan fase awal tugas induk menuruni pohon pindai ke pencarian indeks di node 9, lalu naik kembali ke pertukaran partisi ulang di node 5.
- Tugas induk memulai tugas paralel untuk Cabang C , lalu menunggu sementara mereka membaca semua baris yang tersedia ke operator sortir pemblokiran di node 7.
- Panggilan fase awal naik ke gabung gabungan, lalu turun ke input dalam ke pertukaran di node 11.
- Tugas untuk Cabang D dimulai sama seperti untuk Cabang C, sementara tugas induk menunggu di node 11.
- Panggilan fase awal kembali dari node 11 sejauh aliran pengumpulan. Fase awal berakhir di sini.
- Tugas induk membuat tugas paralel untuk Cabang B , dan menunggu sampai pembukaan cabang B selesai.
- Tugas Cabang B mencapai simpul 5 aliran partisi ulang, menyinkronkan, menyelesaikan pertukaran, dan melepaskan tugas Cabang C untuk mulai menggabungkan baris dari jenisnya.
- Saat tugas Cabang B mencapai aliran partisi ulang node 12, mereka menyinkronkan, menyelesaikan pertukaran, dan melepaskan tugas Cabang D untuk mulai menggabungkan baris dari pengurutan.
- Tugas Cabang B kembali ke aliran berkumpul, bertukar dan menyinkronkan, melepaskan tugas induk dari penantiannya. Tugas induk sekarang siap untuk memulai proses mengembalikan baris ke klien.
Anda mungkin ingin melihat eksekusi rencana ini di Sentry One Plan Explorer. Pastikan untuk mengaktifkan opsi "Dengan Profil Kueri Langsung" dari kumpulan Paket Aktual. Hal yang menyenangkan tentang menjalankan kueri secara langsung di dalam Plan Explorer adalah Anda akan dapat melewati beberapa tangkapan dengan kecepatan Anda sendiri, dan bahkan memundurkannya. Ini juga akan menampilkan ringkasan grafis dari I/O, CPU, dan waktu tunggu yang disinkronkan dengan data profil kueri langsung.
Catatan tambahan
Menaikkan pohon pemindaian kueri selama pemrosesan fase awal menetapkan waktu aktif pertama dan terakhir di setiap iterator pembuatan profil untuk tugas induk, tetapi tidak mengakumulasi waktu yang telah berlalu atau waktu CPU. Menaikkan pohon selama Open dan GetRow panggilan pada tugas paralel menetapkan waktu aktif terakhir, dan mengakumulasi waktu yang telah berlalu dan waktu CPU di setiap iterator pembuatan profil per tugas.
Pemrosesan fase awal khusus untuk rencana paralel mode baris. Penting untuk memastikan pertukaran diinisialisasi dalam urutan yang benar, dan semua mesin paralel bekerja dengan benar.
Tugas induk tidak selalu melakukan seluruh pemrosesan fase awal. Fase awal dimulai pada pertukaran root, tetapi bagaimana panggilan tersebut menavigasi pohon tergantung pada iterator yang ditemui. Saya memilih gabungan gabungan untuk demo ini karena kebetulan memerlukan pemrosesan fase awal untuk kedua input.
Fase awal pada (misalnya) gabungan hash paralel merambat ke input build saja. Ketika hash bergabung dengan transisi ke fase penyelidikannya, itu terbuka iterator pada input itu, termasuk pertukaran apa pun. Putaran lain dari pemrosesan fase awal dimulai, ditangani oleh (tepatnya) salah satu tugas paralel, memainkan peran tugas induk.
Ketika pemrosesan fase awal menemukan cabang paralel yang berisi iterator pemblokiran, itu memulai tugas paralel tambahan untuk cabang itu, dan menunggu produsen tersebut menyelesaikan fase pembukaannya. Cabang tersebut mungkin juga memiliki cabang anak, yang ditangani dengan cara yang sama, secara rekursif.
Beberapa cabang dalam rencana paralel mode baris mungkin diperlukan untuk berjalan pada satu utas (misalnya karena agregat global atau atas). 'Zona serial' ini juga berjalan pada tugas 'paralel' tambahan, satu-satunya perbedaan adalah hanya ada satu tugas, konteks eksekusi, dan pekerja untuk cabang itu. Pemrosesan fase awal bekerja sama terlepas dari jumlah tugas yang diberikan ke cabang. Misalnya, 'zona serial' melaporkan pengaturan waktu untuk tugas induk (atau tugas paralel yang memainkan peran itu) serta tugas tambahan tunggal. Ini bermanifestasi dalam showplan sebagai data untuk "utas 0" (fase awal) serta "utas 1" (tugas tambahan).
Pemikiran penutup
Semua ini tentu saja mewakili lapisan kerumitan ekstra. Pengembalian investasi tersebut dalam penggunaan sumber daya waktu proses (terutama utas dan memori), pengurangan waktu tunggu sinkronisasi, peningkatan throughput, metrik kinerja yang berpotensi akurat, dan kemungkinan kebuntuan paralel intra-kueri yang diminimalkan.
Meskipun paralelisme mode baris sebagian besar telah dikalahkan oleh mesin eksekusi paralel mode batch yang lebih modern, desain mode baris masih memiliki keindahan tertentu. Sebagian besar iterator berpura-pura masih berjalan dalam rencana serial, dengan hampir semua sinkronisasi, kontrol aliran, dan penjadwalan ditangani oleh pertukaran. Perhatian dan perhatian yang nyata dalam detail implementasi seperti pemrosesan fase awal memungkinkan bahkan rencana paralel terbesar untuk dieksekusi dengan sukses tanpa perancang kueri terlalu memikirkan kesulitan praktis.