Paket Layanan 2 untuk SQL Server 2014 dirilis bulan lalu (baca catatan rilis di sini) dan menyertakan pernyataan DBCC baru:DBCC CLONEDATABASE . Saya sangat senang melihat perintah ini diperkenalkan, karena memberikan sangat mudah cara menyalin skema database, termasuk statistik , yang dapat digunakan untuk menguji kinerja kueri tanpa memerlukan semua ruang yang diperlukan untuk data dalam database. Saya akhirnya meluangkan waktu untuk menguji DBCC CLONEDATABASE dan memahami batasannya, dan saya harus mengatakan bahwa itu cukup menyenangkan.
Dasar-dasar
Saya memulai dengan membuat klon dari database AdventureWorks2014 dan menjalankan kueri terhadap database sumber dan kemudian database klon:
DBCC CLONEDATABASE (N'AdventureWorks2014', N'AdventureWorks2014_CLONE'); GO SET STATISTICS IO ON; GO SET STATISTICS TIME ON; GO SET STATISTICS XML ON; GO USE [AdventureWorks2014]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO USE [AdventureWorks2014_CLONE]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO SET STATISTICS IO OFF; GO SET STATISTICS TIME OFF; GO SET STATISTICS XML OFF; GO
Jika saya melihat output I/O dan TIME, saya dapat melihat bahwa query terhadap database sumber memakan waktu lebih lama dan menghasilkan lebih banyak I/O, keduanya diharapkan karena database clone tidak memiliki data di dalamnya:
/* Basis data SUMBER */
Waktu Eksekusi SQL Server:
Waktu CPU =0 md, waktu yang berlalu =0 md.
Waktu penguraian dan kompilasi SQL Server:
Waktu CPU =0 md, waktu yang berlalu =4 md.
(121317 baris terpengaruh)
Tabel 'SalesOrderHeader'. Hitungan pemindaian 0, pembacaan logis 371567, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan ke depan lob pembacaan 0.
Meja 'Meja Kerja'. Hitungan pemindaian 0, pembacaan logis 0, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan pembacaan ke depan lob 0.
Tabel 'Detail Pesanan Penjualan'. Hitungan pindai 5, pembacaan logis 1361, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan ke depan lob pembacaan 0.
Meja 'Meja Kerja'. Hitungan pemindaian 0, pembacaan logis 0, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan pembacaan ke depan lob 0.
(1 baris terpengaruh)
Waktu Eksekusi SQL Server:
Waktu CPU =686 md, waktu yang berlalu =2548 md.
/* Klon database */
Waktu Eksekusi SQL Server:
Waktu CPU =0 md, waktu yang berlalu =0 md.
Waktu penguraian dan kompilasi SQL Server:
Waktu CPU =12 md, waktu yang berlalu =12 md.
(0 baris terpengaruh)
Meja 'Meja Kerja'. Hitungan pemindaian 0, pembacaan logis 0, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan pembacaan ke depan lob 0.
Tabel 'SalesOrderHeader'. Hitungan pemindaian 0, pembacaan logis 0, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan pembacaan ke depan lob 0.
Tabel 'Detail Pesanan Penjualan'. Hitungan pemindaian 5, pembacaan logis 0, pembacaan fisik 0, pembacaan ke depan 0, pembacaan logika lob 0, pembacaan fisik lob 0, pembacaan ke depan lob pembacaan 0.
(1 baris terpengaruh)
Waktu Eksekusi SQL Server:
Waktu CPU =0 md, waktu yang berlalu =83 md.
Jika saya melihat rencana eksekusi, keduanya sama untuk kedua database kecuali untuk nilai aktual (jumlah data yang benar-benar dipindahkan melalui rencana):
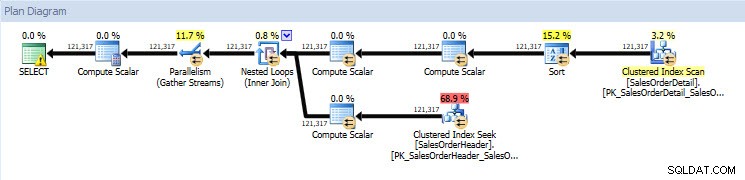 Rencana Kueri untuk database AdventureWorks2014
Rencana Kueri untuk database AdventureWorks2014
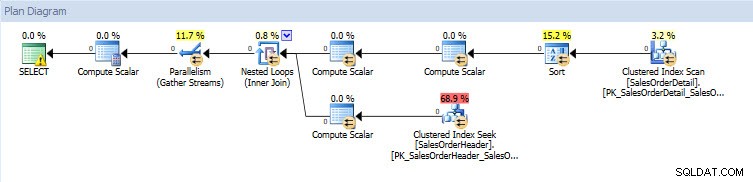 Rencana Kueri untuk database AdventureWorks2014_CLONE
Rencana Kueri untuk database AdventureWorks2014_CLONE
Di sinilah nilai DBCC CLONEDATABASE jelas – Saya bisa mendapatkan salinan kosong dari database kepada siapa pun (Dukungan Produk Microsoft, rekan DBA saya, dll.) dan meminta mereka membuat ulang dan menyelidiki masalah, dan mereka tidak perlu berpotensi ratusan GB ruang disk untuk melakukannya dia. Postingan Juli T-SQL Selasa Melissa memiliki informasi mendetail tentang apa yang terjadi selama proses kloning, jadi saya sarankan untuk membacanya untuk informasi lebih lanjut.
Apakah itu?
Tapi… dapatkah saya berbuat lebih banyak dengan DBCC CLONEDATABASE ? Maksud saya, ini bagus, tetapi saya pikir ada banyak hal lain yang dapat saya lakukan dengan salinan database yang kosong. Jika Anda membaca dokumentasi untuk DBCC CLONEDATABASE , Anda akan melihat baris ini:
Pikiran pertama saya adalah, “pengoptimal kueri – hmm… dapatkah saya menggunakan ini sebagai opsi untuk menguji peningkatan versi ?”
Yah, basis data yang dikloning adalah hanya-baca, tetapi saya pikir saya akan mencoba mengubah beberapa opsi. Misalnya, jika saya dapat mengubah mode kompatibilitas, itu akan sangat keren, karena saya dapat menguji perubahan CE di SQL Server 2014 dan SQL Server 2016.
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 110;
Saya mendapatkan kesalahan:
Msg 3906, Level 16, Status 1Gagal memperbarui database "AdventureWorks2014_CLONE" karena database hanya-baca.
Msg 5069, Level 16, Status 1
Pernyataan ALTER DATABASE gagal.
Hm. Dapatkah saya mengubah model pemulihan?
ALTER DATABASE [AdventureWorks2014_CLONE] SET RECOVERY SIMPLE WITH NO_WAIT;
Saya bisa. Itu tidak adil. Ya, ini hanya-baca, bisakah saya mengubahnya?
ALTER DATABASE [AdventureWorks2014_CLONE] SET READ_WRITE WITH NO_WAIT;
YA! Sebelum Anda terlalu bersemangat, izinkan saya meninggalkan catatan ini dari dokumentasi di sini:
Catatan Basis data yang baru dibuat yang dihasilkan dari DBCC CLONEDATABASE tidak didukung untuk digunakan sebagai basis data produksi dan terutama ditujukan untuk pemecahan masalah dan tujuan diagnostik. Sebaiknya lepaskan database kloning setelah database dibuat.Saya akan mengulangi baris ini dari dokumentasi, dan tebalkan dan beri warna merah sebagai tanda ramah tetapi sangat penting pengingat:
Basis data yang baru dibuat yang dihasilkan dari DBCC CLOENDATABASE tidak didukung untuk digunakan sebagai basis data produksi dan terutama ditujukan untuk pemecahan masalah dan tujuan diagnostik.Tidak masalah bagi saya, saya pasti tidak akan menggunakan ini untuk produksi, tetapi sekarang saya dapat menggunakannya untuk pengujian! SEKARANG saya dapat mengubah mode kompatibilitas, dan SEKARANG saya dapat mencadangkan dan memulihkannya pada contoh lain untuk pengujian!
USE [master]; GO BACKUP DATABASE [AdventureWorks2014_CLONE] TO DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH INIT, NOFORMAT, STATS = 10, NAME = N'AW2014_CLONE_full'; GO /* restore on SQL Server 2016 */ RESTORE DATABASE [AdventureWorks2014_CLONE] FROM DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH MOVE N'AdventureWorks2014_Data' TO N'C:\Databases\AdventureWorks2014_Data_2684624044.mdf', MOVE N'AdventureWorks2014_Log' TO N'C:\Databases\AdventureWorks2014_Log_3195542593.ldf', NOUNLOAD, REPLACE, STATS = 5; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 130; GO
INI BESAR.
Dalam posting terakhir saya, saya berbicara tentang jejak bendera 2389 dan pengujian dengan Penaksir Kardinalitas baru karena, teman-teman, Anda membutuhkan untuk menguji dengan CE baru sebelum Anda meningkatkan. Jika Anda tidak menguji, dan jika Anda mengubah mode kompatibilitas ke 120 (SQL Server 2014) atau 130 (SQL Server 2016) sebagai bagian dari pemutakhiran Anda, maka Anda berisiko bekerja dalam mode pemadam kebakaran jika Anda mengalami regresi dengan CE baru. Sekarang, Anda bisa baik-baik saja, dan kinerja mungkin lebih baik setelah Anda meningkatkan. Tapi… tidakkah Anda ingin memastikan?
Sangat sering ketika saya menyebutkan pengujian sebelum peningkatan, saya diberitahu bahwa tidak ada lingkungan untuk melakukan pengujian. Saya tahu beberapa dari Anda memiliki lingkungan Test. Beberapa dari Anda memiliki Test, Dev, QA, UAT dan entah apa lagi. Anda beruntung.
Bagi Anda yang menyatakan bahwa Anda tidak memiliki lingkungan pengujian sama sekali untuk diuji, saya memberi Anda DBCC CLONEDATABASE . Dengan perintah ini, Anda tidak memiliki alasan untuk tidak menjalankan kueri yang paling sering dijalankan dan yang paling banyak digunakan terhadap tiruan database Anda. Bahkan jika Anda tidak memiliki lingkungan pengujian, Anda memiliki mesin Anda sendiri. Cadangkan database klon dari produksi, jatuhkan klon, pulihkan cadangan ke instans lokal Anda, lalu uji. Basis data klon membutuhkan ruang yang sangat sedikit pada disk dan Anda tidak akan mengeluarkan memori atau pertentangan I/O karena tidak ada data. Anda akan dapat memvalidasi rencana kueri dari klon terhadap yang dari database produksi Anda. Selanjutnya, jika Anda memulihkan pada SQL Server 2016 Anda dapat memasukkan Query Store ke dalam pengujian Anda! Aktifkan Penyimpanan Kueri, jalankan pengujian Anda dalam mode kompatibilitas asli, lalu tingkatkan mode kompatibilitas dan uji lagi. Anda dapat menggunakan Toko Kueri untuk membandingkan kueri secara berdampingan! (Bisakah Anda memberi tahu saya bahwa saya sedang menari di kursi saya sekarang?)
Pertimbangan
Sekali lagi, ini seharusnya tidak menjadi apa pun yang akan Anda gunakan dalam produksi, dan saya tahu Anda tidak akan melakukannya, tetapi ini harus diulang karena dalam kondisi saat ini, DBCC CLONEDATABASE belum sepenuhnya selesai . Ini dicatat dalam artikel KB di bawah objek yang didukung; objek seperti tabel yang dioptimalkan memori dan tabel file tidak disalin, Teks lengkap tidak didukung, dll.
Sekarang, database kloning bukan tanpa kekurangan. Jika Anda secara tidak sengaja menjalankan pembangunan kembali indeks atau pembaruan statistik di database itu, Anda baru saja menghapus data pengujian Anda. Anda akan kehilangan statistik asli yang mungkin benar-benar Anda inginkan sejak awal. Misalnya, jika saya memeriksa statistik untuk indeks berkerumun di SalesOrderHeader sekarang, saya mendapatkan ini:
USE [AdventureWorks2014_CLONE]; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Statistik asli untuk SalesOrderHeader
Statistik asli untuk SalesOrderHeader
Sekarang, jika saya memperbarui statistik terhadap tabel itu, saya mendapatkan ini:
UPDATE STATISTICS [Sales].[SalesOrderHeader] WITH FULLSCAN; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Statistik (kosong) yang diperbarui untuk SalesOrderHeader
Statistik (kosong) yang diperbarui untuk SalesOrderHeader
Sebagai keamanan tambahan, sebaiknya nonaktifkan pembaruan otomatis pada statistik:
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET AUTO_UPDATE_STATISTICS OFF WITH NO_WAIT;
Jika Anda tidak sengaja memperbarui statistik, menjalankan DBCC CLONEDATABASE dan melalui proses pencadangan dan pemulihan tidak terlalu sulit, dan Anda akan mengotomatiskannya dalam waktu singkat.
Anda dapat menambahkan data ke database. Ini bisa berguna jika Anda ingin bereksperimen dengan statistik (misalnya, tingkat sampel yang berbeda, statistik yang difilter) dan Anda memiliki penyimpanan yang cukup untuk menyimpan salinan data tabel.
Tanpa data dalam database, Anda jelas tidak akan mendapatkan durasi yang representatif dan data I/O yang andal. Tidak apa-apa. Jika Anda memerlukan data tentang penggunaan sumber daya yang sebenarnya, maka Anda memerlukan salinan database Anda dengan semua data di dalamnya. DBCC CLONEDATABASE benar-benar tentang menguji kinerja kueri; itu dia. Ini bukan pengganti untuk pengujian pemutakhiran tradisional dengan cara apa pun – tetapi ini adalah opsi baru untuk memvalidasi bagaimana SQL Server mengoptimalkan kueri dengan versi dan mode kompatibilitas yang berbeda. Selamat menguji!