Orang bertanya-tanya apakah mereka harus melakukan yang terbaik untuk mencegah pengecualian, atau membiarkan sistem menanganinya. Saya telah melihat beberapa diskusi di mana orang memperdebatkan apakah mereka harus melakukan apa pun yang mereka bisa untuk mencegah pengecualian, karena penanganan kesalahan itu "mahal." Tidak ada keraguan bahwa penanganan kesalahan tidak gratis, tetapi saya memperkirakan bahwa pelanggaran batasan setidaknya seefisien memeriksa potensi pelanggaran terlebih dahulu. Ini mungkin berbeda untuk pelanggaran kunci dari pelanggaran batasan statis, misalnya, tetapi dalam posting ini saya akan fokus pada yang pertama.
Pendekatan utama yang digunakan orang untuk menangani pengecualian adalah:
- Biarkan mesin yang menanganinya, dan kembalikan pengecualian apa pun ke penelepon.
- Gunakan
BEGIN TRANSACTIONdanROLLBACKjika@@ERROR <> 0. - Gunakan
TRY/CATCHdenganROLLBACKdiCATCHblok (SQL Server 2005+).
Dan banyak yang mengambil pendekatan bahwa mereka harus memeriksa apakah mereka akan melakukan pelanggaran terlebih dahulu, karena tampaknya lebih bersih untuk menangani duplikat sendiri daripada memaksa mesin untuk melakukannya. Teori saya adalah bahwa Anda harus percaya tetapi memverifikasi; misalnya, pertimbangkan pendekatan ini (kebanyakan kode semu):
IF NOT EXISTS ([row that would incur a violation])
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT ()...
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- well, we incurred a violation anyway;
-- I guess a new row was inserted or
-- updated since we performed the check
ROLLBACK TRANSACTION;
END CATCH
END
Kita tahu bahwa IF NOT EXISTS pemeriksaan tidak menjamin bahwa orang lain tidak akan memasukkan baris pada saat kita membuka INSERT (kecuali kami menempatkan kunci agresif di atas meja dan/atau menggunakan SERIALIZABLE ), tetapi pemeriksaan luar mencegah kami mencoba melakukan kegagalan dan kemudian harus memutar kembali. Kami menghindari seluruh TRY/CATCH struktur jika kita sudah tahu bahwa INSERT akan gagal, dan akan masuk akal untuk mengasumsikan bahwa – setidaknya dalam beberapa kasus – ini akan lebih efisien daripada memasukkan TRY/CATCH struktur tanpa syarat. Ini tidak masuk akal dalam satu INSERT skenario, tetapi bayangkan kasus di mana ada lebih banyak yang terjadi di TRY blokir (dan lebih banyak potensi pelanggaran yang dapat Anda periksa sebelumnya, yang berarti lebih banyak pekerjaan yang mungkin harus Anda lakukan dan kemudian mundur jika terjadi pelanggaran di kemudian hari).
Sekarang, akan menarik untuk melihat apa yang akan terjadi jika Anda menggunakan tingkat isolasi non-default (sesuatu yang akan saya bahas di posting mendatang), terutama dengan konkurensi. Namun, untuk posting ini, saya ingin memulai dengan perlahan, dan menguji aspek-aspek ini dengan satu pengguna. Saya membuat tabel bernama dbo.[Objects] , tabel yang sangat sederhana:
CREATE TABLE dbo.[Objects] ( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY ); GO
Saya ingin mengisi tabel ini dengan 100.000 baris data sampel. Untuk membuat nilai di kolom nama unik (karena PK adalah batasan yang ingin saya langgar), saya membuat fungsi pembantu yang mengambil sejumlah baris dan string minimum. String minimum akan digunakan untuk memastikan bahwa (a) himpunan dimulai di luar nilai maksimum dalam tabel Objects, atau (b) himpunan dimulai pada nilai minimum dalam tabel Objects. (Saya akan menentukan ini secara manual selama pengujian, diverifikasi hanya dengan memeriksa data, meskipun saya mungkin bisa memasukkan pemeriksaan itu ke dalam fungsi.)
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) RETURNS TABLE AS RETURN ( SELECT TOP (@n) name = name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn = ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name >= @minString AND b.name >= @minString ) AS x ); GO
Ini menerapkan CROSS JOIN dari sys.all_objects ke dirinya sendiri, menambahkan row_number unik ke setiap nama, sehingga 10 hasil pertama akan terlihat seperti ini:
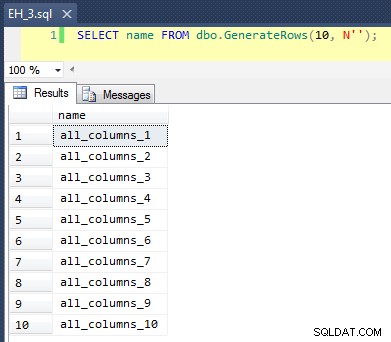
Mengisi tabel dengan 100.000 baris itu sederhana:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name; GO
Sekarang, karena kita akan memasukkan nilai unik baru ke dalam tabel, saya membuat prosedur untuk melakukan beberapa pembersihan di awal dan akhir setiap pengujian – selain menghapus baris baru yang telah kita tambahkan, itu juga akan membersihkan cache dan buffer. Tentu saja bukan sesuatu yang ingin Anda kodekan ke dalam prosedur pada sistem produksi Anda, tetapi cukup baik untuk pengujian kinerja lokal.
CREATE PROCEDURE dbo.EH_Cleanup -- P.S. "EH" stands for Error Handling, not "Eh?" AS BEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID > 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; END GO
Saya juga membuat tabel log untuk melacak waktu mulai dan berakhir untuk setiap pengujian:
CREATE TABLE dbo.RunTimeLog ( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) ); GO
Akhirnya, prosedur tersimpan pengujian menangani berbagai hal. Kami memiliki tiga metode penanganan kesalahan yang berbeda, seperti yang dijelaskan dalam butir di atas:"JustInsert", "Rollback", dan "TryCatch"; kami juga memiliki tiga jenis penyisipan yang berbeda:(1) semua sisipan berhasil (semua baris unik), (2) semua sisipan gagal (semua baris adalah duplikat), dan (3) setengah sisipan berhasil (setengah baris unik, dan setengah baris adalah duplikat). Digabungkan dengan ini adalah dua pendekatan berbeda:periksa pelanggaran sebelum mencoba memasukkan, atau lanjutkan dan biarkan mesin menentukan apakah itu valid. Saya pikir ini akan memberikan perbandingan yang baik dari berbagai teknik penanganan kesalahan yang dikombinasikan dengan kemungkinan tabrakan yang berbeda untuk melihat apakah persentase tabrakan yang tinggi atau rendah akan berdampak signifikan pada hasil.
Untuk pengujian ini saya memilih 40.000 baris sebagai jumlah total upaya penyisipan saya, dan dalam prosedur saya melakukan penyatuan 20.000 baris unik atau tidak unik dengan 20.000 baris unik atau tidak unik lainnya. Anda dapat melihat bahwa saya mengkodekan string cutoff dalam prosedur; harap perhatikan bahwa pada sistem Anda, pemutusan ini hampir pasti akan terjadi di tempat yang berbeda.
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT = 20000 AS BEGIN SET NOCOUNT ON; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT = 1, @LogID INT; -- generate a new log entry INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID = SCOPE_IDENTITY(); -- if we want everything to succeed, we need a set of data -- that has 40,000 rows that are all unique. So union two -- sets that are each >= 20,000 rows apart, and don't -- already exist in the base table: IF @InsertType = 'AllSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N'dm_clr_properties_1398'; -- if we want them all to fail, then it's easy, we can just -- union two sets that start at the same place as the initial -- population: IF @InsertType = 'AllFail' SELECT @CutoffString1 = N'', @CutoffString2 = N''; -- and if we want half to succeed, we need 20,000 unique -- values, and 20,000 duplicates: IF @InsertType = 'HalfSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OPEN c; FETCH NEXT FROM c INTO @Name; WHILE @@FETCH_STATUS = 0 BEGIN SET @Continue = 1; -- let's only enter the primary code block if we -- have to check and the check comes back empty -- (in other words, don't try at all if we have -- a duplicate, but only check for a duplicate -- in certain cases: IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name = @Name) SET @Continue = 0; END IF @Continue = 1 BEGIN -- just let the engine catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- begin a transaction, but let the engine catch IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @name; IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION; END ELSE BEGIN COMMIT TRANSACTION; END END -- use try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @Name; COMMIT TRANSACTION; END TRY BEGIN CATCH ROLLBACK TRANSACTION; END CATCH END END FETCH NEXT FROM c INTO @Name; END CLOSE c; DEALLOCATE c; -- update the log entry UPDATE dbo.RunTimeLog SET EndDate = SYSUTCDATETIME() WHERE LogID = @LogID; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; END GO
Sekarang kita dapat memanggil prosedur ini dengan berbagai argumen untuk mendapatkan perilaku berbeda yang kita cari, mencoba memasukkan 40.000 nilai (dan mengetahui, tentu saja, berapa banyak yang harus berhasil atau gagal dalam setiap kasus). Untuk setiap 'metode penanganan kesalahan' (coba saja masukkan, gunakan mulai tran/kembalikan, atau coba/tangkap) dan setiap jenis penyisipan (semua berhasil, setengah berhasil, dan tidak ada yang berhasil), dikombinasikan dengan apakah akan memeriksa pelanggaran atau tidak. pertama, ini memberi kita 18 kombinasi:
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllFail', 20000;
Setelah kami menjalankan ini (dibutuhkan sekitar 8 menit di sistem saya), kami mendapatkan beberapa hasil di log kami. Saya menjalankan seluruh batch lima kali untuk memastikan kami mendapatkan rata-rata yang layak dan untuk memuluskan setiap anomali. Berikut adalah hasilnya:
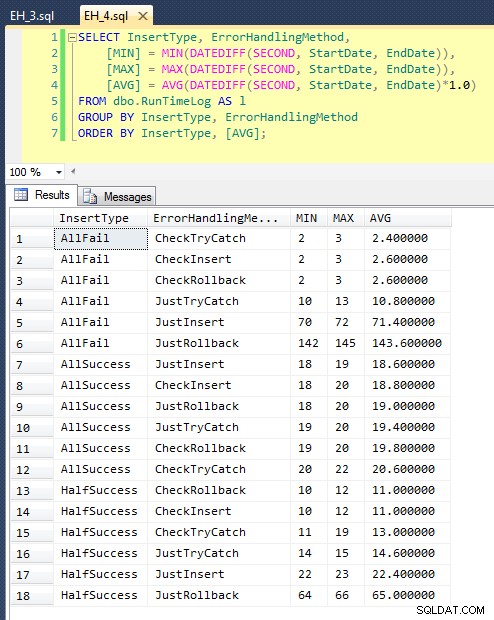
Grafik yang memplot semua durasi sekaligus menunjukkan beberapa outlier yang serius:
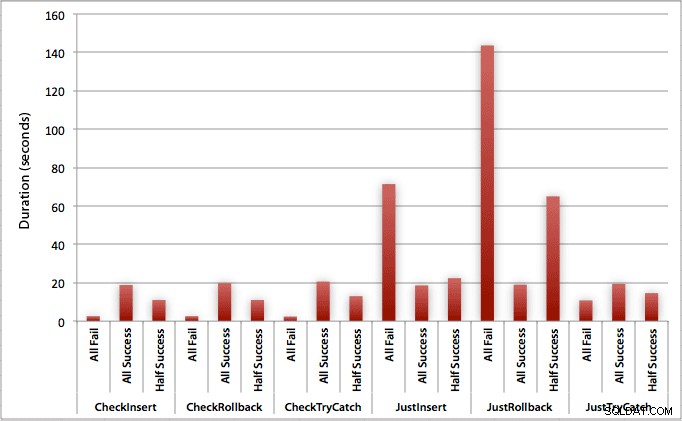
Anda dapat melihat bahwa, dalam kasus di mana kami mengharapkan tingkat kegagalan yang tinggi (dalam pengujian ini, 100%), memulai transaksi dan memutar kembali sejauh ini merupakan pendekatan yang paling tidak menarik (3,59 milidetik per upaya), sementara hanya membiarkan mesin meningkat kesalahan sekitar setengahnya (1,785 milidetik per upaya). Performa terburuk berikutnya adalah kasus di mana kami memulai transaksi kemudian mengembalikannya, dalam skenario di mana kami memperkirakan sekitar setengah dari upaya gagal (rata-rata 1,625 milidetik per upaya). 9 kasus di sisi kiri grafik, tempat kami memeriksa pelanggaran terlebih dahulu, tidak bergerak di atas 0,515 milidetik per percobaan.
Karena itu, grafik individual untuk setiap skenario (% keberhasilan tinggi,% kegagalan tinggi, dan 50-50) benar-benar menunjukkan dampak dari setiap metode.
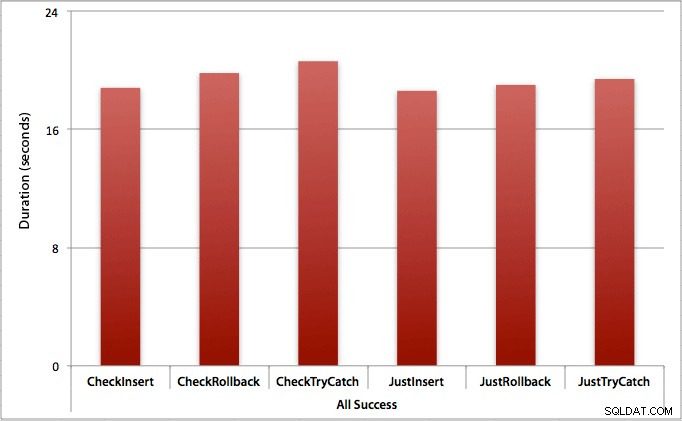
Di mana semua penyisipan berhasil
Dalam kasus ini, kami melihat bahwa overhead untuk memeriksa pelanggaran terlebih dahulu dapat diabaikan, dengan perbedaan rata-rata 0,7 detik di seluruh kumpulan (atau 125 mikrodetik per upaya penyisipan):
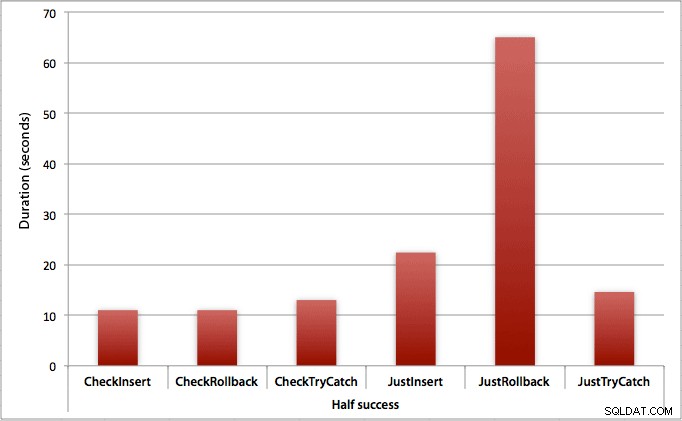
Di mana hanya setengah sisipan yang berhasil
Ketika setengah sisipan gagal, kami melihat lompatan besar dalam durasi metode penyisipan / rollback. Skenario di mana kami memulai transaksi dan mengembalikannya sekitar 6x lebih lambat di seluruh batch jika dibandingkan dengan pemeriksaan pertama (1,625 milidetik per upaya vs. 0,275 milidetik per upaya). Bahkan metode TRY/CATCH 11% lebih cepat saat kita cek dulu:
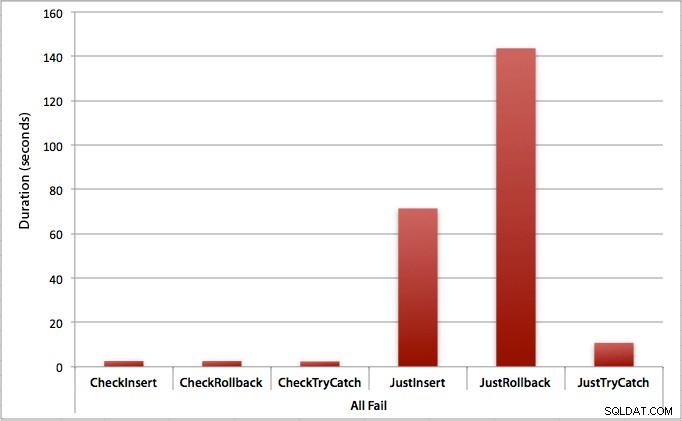
Di mana semua sisipan gagal
Seperti yang Anda duga, ini menunjukkan dampak penanganan kesalahan yang paling menonjol, dan manfaat paling jelas dari pemeriksaan terlebih dahulu. Metode rollback hampir 70x lebih lambat dalam hal ini saat kami tidak memeriksa dibandingkan saat kami melakukannya (3,59 milidetik per upaya vs. 0,065 milidetik per upaya):
Apa ini memberitahu kita? Jika kita berpikir kita akan memiliki tingkat kegagalan yang tinggi, atau tidak tahu berapa tingkat kegagalan potensial kita, maka memeriksa terlebih dahulu untuk menghindari pelanggaran di mesin akan sangat bermanfaat bagi kita. Bahkan dalam kasus di mana kami memiliki penyisipan yang berhasil setiap kali, biaya pemeriksaan pertama sangat kecil dan mudah dibenarkan oleh potensi biaya penanganan kesalahan di kemudian hari (kecuali tingkat kegagalan yang Anda antisipasi tepat 0%).
Jadi untuk saat ini saya pikir saya akan tetap berpegang pada teori saya bahwa, dalam kasus sederhana, masuk akal untuk memeriksa potensi pelanggaran sebelum memberi tahu SQL Server untuk melanjutkan dan tetap memasukkan. Dalam posting mendatang, saya akan melihat dampak kinerja dari berbagai tingkat isolasi, konkurensi, dan bahkan mungkin beberapa teknik penanganan kesalahan lainnya.
[Sebagai tambahan, saya menulis versi singkat dari posting ini sebagai tip untuk mssqltips.com pada bulan Februari.]