Sistem Manajemen Basis Data adalah kotak informasi yang kuat. Kami akan mencoba merancang Sistem Manajemen Basis Data agar basis data tetap dikelola dengan baik dan memenuhi tujuannya.
Pada artikel ini, kita akan membahas merancang dan mengelola sistem database berukuran besar. Kami akan menggunakan beberapa konstitusi yang akan mencakup teknologi Database, penyimpanan, distribusi data, aset server, pola arsitektur, dan beberapa lainnya.
Sebaiknya, kita harus mencari database berukuran besar di domain Telco, platform eCommerce, domain Asuransi, sistem Perbankan, Kesehatan, sistem Energi, dll. Kita harus mengingat beberapa parameter sebelum memilih teknologi database yang tepat. yaitu, Lalu Lintas, TPS (Transaksi Per Detik), perkiraan penyimpanan per hari, HA, dan DR.
Merancang Basis Data Berukuran Besar
Saat membangun database kita, kita harus memperhatikan beberapa parameter karena seringkali sangat bermasalah untuk mengganti database dengan pengganti. Mari kita pertimbangkan sekarang.
Teknologi Basis Data
Teknologi database adalah faktor utama. Jika Anda memilih sistem manajemen basis data yang tepat, ini akan membantu bisnis Anda berjalan dengan efisien dan mudah.
Ada berbagai teknologi database dengan banyak fitur. Namun, saat bekerja dengan teknologi database sumber terbuka, Anda mungkin tidak mendapatkan akses ke beberapa fitur eksplisit dari solusi yang telah ditentukan sebelumnya. Teknologi database perusahaan seperti Microsoft SQL Server, Oracle, dll. akan menyediakannya.
Banyak teknologi database perusahaan menerapkan HA (Ketersediaan Tinggi), DR (Pemulihan Bencana), Pencerminan, Replikasi Data, Replika Baca Sekunder, dan solusi bisnis yang jauh lebih nyaman dan siap dikonfigurasi. Mereka mungkin ada atau tidak ada di database sumber terbuka.
Ada banyak banyak alasan. Misalnya, terkadang kami menemukan bahwa arsitektur yang ada sedang terganggu karena faktor-faktor yang disebutkan di atas tidak berfungsi seperti yang kami butuhkan.
Penyimpanan
Penyimpanan berdampak pada kinerja solusi bisnis secara drastis. Solusi bisnis memerlukan penyimpanan atau SSD berperingkat pertama dengan jumlah IOPS tertentu. Namun, apakah begitu? Lokal atau Cloud, ukuran dan jenis Penyimpanan menentukan biaya infrastruktur.
Sambil mempertimbangkan kinerja penyimpanan, kita perlu memperhatikan jenis data dan perilaku pemrosesan data. Kita perlu memilih pilihan penyimpanan sesuai dengan data pengguna dan pemrosesannya. Jika pengguna akan menggunakan beberapa database, kita perlu menyediakan pilihan penyimpanan di atas SAN untuk database yang berbeda untuk tipe data dan perilaku pemrosesan data.
Insinyur Database akan memberikan retrospeksi yang lebih baik pada berbagai database yang diperlukan perhitungan IOPS jika pengguna tidak memerlukan penyimpanan premium sama sekali.
Distribusi Data
Sebagian besar teknologi database terbaru (SQL atau NoSQL) menawarkan fitur partisi atau Sharding.
- Partisi mendistribusikan ulang data dalam sistem File yang didasarkan pada kunci partisi.
- Sharding mendistribusikan informasi ke seluruh node database dan data akan disimpan di mesin yang sama atau berbeda.
Pada dasarnya, setiap layanan database atau tabel database tidak memerlukan fitur Partisi/Sharding data. Mereka hanya perlu diterapkan pada database yang menyimpan objek berukuran lebih besar. Itu akan meningkatkan kinerja.
Aset Server
Mesin yang berbeda memerlukan jenis dan ukuran Memori dan CPU yang berbeda. Anda harus mempertimbangkan aset tingkat perangkat keras, seperti Memori, Prosesor, dll. Misalnya, mesin yang harus menangani basis data yang lebih besar atau banyak basis data akan membutuhkan lebih banyak memori dan CPU. Oleh karena itu, kualitas Memori dan Prosesor sangat penting. Ini akan menangani berbagai jenis prosesor yang tersedia di pasar dengan cache CPU yang berbeda.
Seringkali, kita menemukan masalah yang mungkin tidak kita sadari. Kami tidak memperhatikan pemanfaatan dan peran cache CPU dari perangkat keras. Namun sangat penting untuk memilih dan memenuhi persyaratan perangkat keras dengan sistem database yang lebih besar.
Pola Arsitektur
Dalam perancangan basis data, pola Arsitektur selalu memiliki peran yang patut dicontoh. Sebelumnya, sistem database dirancang dengan cara yang sangat monolitik. Sekarang, kami menggunakan berbasis Layanan Mikro atau Hybrid (Monolitik + Mikro).
Performa, perluasan, dan waktu henti nol sangat bergantung pada pola arsitektur dan desain basis data. Setiap aplikasi dapat memiliki database terpisah, dan semua database dapat digabungkan secara longgar satu sama lain. Jika ada aplikasi atau database yang down, bagian lain dari produk tidak akan terganggu. Semua layanan mikro akan independen dan dapat digabungkan secara longgar.
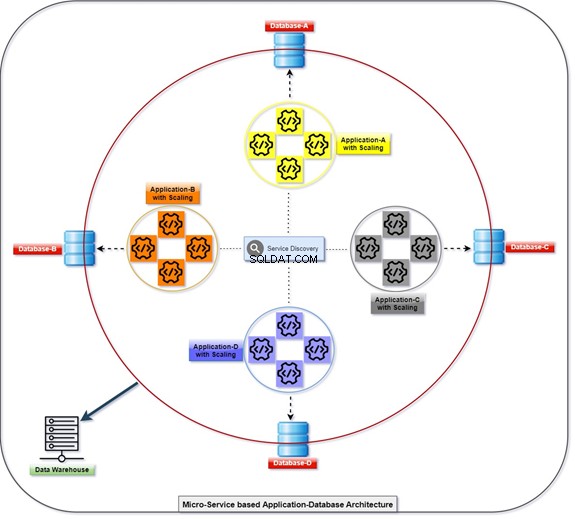
Layanan Mikro
Diagram di bawah ini menjelaskan bagaimana semua aplikasi disebarkan dan berkomunikasi dengan bantuan database mereka, yang digabungkan secara longgar pada saat yang bersamaan. Kita dapat memanipulasi data dengan T-SQL. Informasi akan dikumpulkan atau diakumulasikan oleh berbagai aplikasi, dan klien akan dapat mengakses data. Lihat diagram dengan jumlah aplikasi yang diskalakan dan database terintegrasinya.
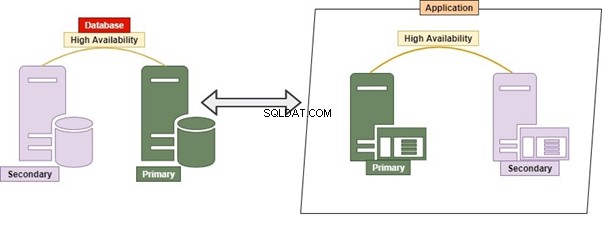
Monolitik
RDBMS mana yang harus kita gunakan? Itu bisa Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB, atau database lainnya. Cara konvensional untuk menangani semua tabel atau objek yang dikelola dalam satu atau beberapa database dalam satu server dikenal sebagai Monolitik.
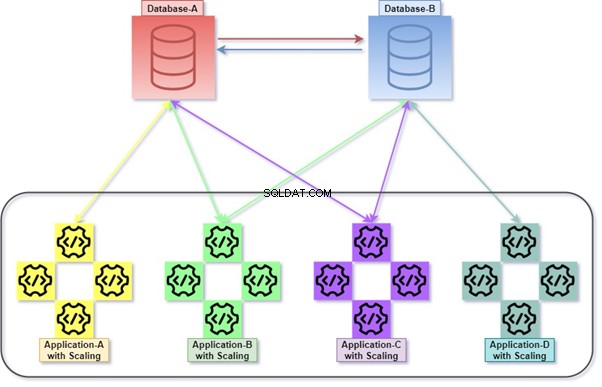
Hibrida
Hybrid merupakan permutasi dari Monolithic dan Micro Service. Ini adalah praktik yang cukup umum, karena memungkinkan banyak aplikasi, banyak basis data, dan server basis data. Banyak database dan server database dapat digabungkan dengan erat satu sama lain.
Misalnya query dengan JOIN antar tabel milik dua atau lebih database dalam database server yang sama atau berbeda. Permintaan jarak jauh yang digunakan untuk pengambilan/manipulasi data dengan server database lain.
Semuanya tentang arsitektur SQL Server. Namun, kita berbicara tentang manipulasi data di antara tabel yang berbeda dalam database yang sama atau database berbeda yang dapat berada di server yang sama atau server yang berbeda.
Baik dalam arsitektur Hybrid atau Monolitik, kami menggunakan JOIN antara berbagai tabel dalam database yang sama atau berbeda. Ini cukup rumit ketika kita mengikuti standar inti Layanan Mikro karena distribusi tabel dapat berada di antara layanan basis data (Dbas).
Di bawah teknologi database Enterprise seperti Microsoft SQL Server, Oracle, dll., pengguna dapat menanyakan tabel database terdistribusi dengan bantuan Linked Server Joins. Tapi itu tidak tersedia di semua teknologi database open-source. Ini dikenal sebagai pendekatan Tight-Coupled yang mungkin tidak berfungsi saat layanan database jarak jauh tidak tersedia.
Sekarang, mari kita bahas membuatnya lepas-pasangan. Mengapa kita membutuhkan manipulasi data antar database jarak jauh?
Mengapa kita Memerlukan Manipulasi Data Antar Database Jarak Jauh?
Pengguna akan membutuhkan data untuk diambil dari lebih dari satu layanan database ketika sistem dirancang dengan bantuan Layanan Mikro atau Hibrida. Keseluruhan proses dilihat dari backend yang dapat menangani jumlah data yang dimanipulasi oleh aplikasi.
Saat kami melihat kueri lintas basis data waktu nyata, kami selalu bergabung dengan tabel entitas master, bukan tabel metadata. Tabel master tidak akan lebih besar dari tabel metadata. Untuk tujuan pelaporan, kami selalu menggunakan data warehouse untuk mengumpulkan semua informasi. Tapi itu tidak mudah untuk dikelola dan dipelihara untuk setiap produk. Jika kami merancang solusi perusahaan, kami dapat membeli gudang. Tapi kami tidak mampu membelinya untuk produk berukuran kecil atau menengah.
Misalnya, kita memerlukan laporan dengan data dari beberapa tabel yang berada di database yang berbeda. Ini bukan tugas yang mudah untuk dilakukan, karena mengumpulkan data menggunakan layanan mikro yang berbeda dan menggabungkannya untuk menghasilkan laporan. Oleh karena itu, data yang diperlukan perlu disinkronkan.
Apa yang dapat kita Gunakan sebagai Solusi Standar Membuat Sinkronisasi Data Tabel Loose-Coupled Antara dua Database?
Replikasi Tabel harus digunakan untuk sinkronisasi data sederhana di antara beberapa database. Contohnya adalah replikasi transaksi untuk sinkronisasi data Simplex dan Replikasi Gabung untuk sinkronisasi data Duplex yang disediakan oleh SQL Server.
Ada beberapa solusi pihak ketiga dan sumber terbuka berbayar yang dapat menyinkronkan data di antara banyak basis data. Bahkan solusi yang digabungkan dengan bantuan antrian pesan seperti Replikasi Transaksi SQL Server dapat dikembangkan oleh pengguna sendiri.
Kesimpulan
DBA mendesain database dengan caranya sendiri. Saat merancang basis data dan memilih sistem manajemen basis data, mereka harus mempertimbangkan banyak aspek. Kami menyajikan faktor yang paling penting untuk desain database, terutama untuk Database berukuran lebih besar. Nantikan materi selanjutnya!