Teknik inti menyimpan file dalam penyimpanan terletak pada sistem file yang digunakan oleh lingkungan operasi. Tidak seperti sistem file umum, Hadoop menggunakan sistem file berbeda yang menangani kumpulan data besar di seluruh jaringan terdistribusi. Ini disebut Sistem File Terdistribusi Hadoop (HDFS) . Artikel ini memperkenalkan ide tersebut, dengan informasi latar belakang terkait untuk memulai.
Apa itu Sistem File?
Sebuah sistem file biasanya adalah metode dan struktur data yang digunakan sistem operasi untuk mengelola file pada disk atau partisi. Dari perspektif disk magnetik, setiap data adalah muatan yang disimpan di sektor-sektor di seluruh trek. Pikirkan trek sebagai baris spiral dan sektor sebagai sel kecil melintasi trek spiral. Sekarang, jika kita meminta disk untuk menemukan beberapa data, itu, paling banter, dapat mengarahkan kembali kepalanya ke beberapa sektor dalam urutan spiral. Data mentah ini tidak berarti kecuali sistem operasi muncul; itu bertugas membatasi informasi dari kumpulan sektor untuk dikenali sebagai file. Sistem operasi mengatur informasi ke dalam struktur data pembukuan yang disebut sistem file. Struktur ini mendefinisikan pola pembukuan. Namun, ada beberapa perbedaan teknis tentang bagaimana OS mengelola struktur ini. Misalnya Windows menggunakan model FAT32, NTFS, Linux menggunakan EXT2, EXT3, dan lain sebagainya. Namun, ide dasarnya adalah bahwa mereka semua mengatur data menurut beberapa struktur yang ditentukan.
Organisasi sistem file terutama bertanggung jawab untuk mengelola pembuatan, modifikasi, dan penghapusan file (direktori juga file), partisi disk, ukuran file, dan sebagainya, dan mereka langsung beroperasi pada sektor mentah disk atau partisi.
File dalam Sistem Terdistribusi
Karakteristik sistem terdistribusi berbeda dalam arti bahwa penyimpanan tersebar di beberapa mesin dalam jaringan. Repositori tunggal tidak dapat berisi sejumlah besar data. Jika satu mesin memiliki kapasitas penyimpanan dan daya pemrosesan yang terbatas, tetapi, ketika pekerjaan pemrosesan dan penyimpanan didistribusikan di antara mesin-mesin di seluruh jaringan, daya dan efisiensi menjadi berlipat ganda. Ini tidak hanya membuka kemungkinan kekuatan pemrosesan yang luas tetapi juga memanfaatkan penggunaan infrastruktur yang ada. Hasil ini adalah bahwa biaya diminimalkan, namun efisiensi meningkat. Setiap mesin tunggal dalam jaringan menjadi pekerja keras potensial yang menampung data terbatas sementara secara kolektif menjadi bagian dari penyimpanan tak terbatas dan kekuatan pemrosesan yang luas. Imbalannya adalah kompleksitas. Jika itu dapat dimanfaatkan dengan teknik inovatif, sistem terdistribusi sangat baik untuk menangani masalah data besar. Sistem file HDFS bertujuan untuk mencapai itu. Bahkan, di luar HDFS, ada banyak sistem file terdistribusi serupa lainnya, seperti GPFS (Sistem File Paralel Umum) IBM, Ceph, (tautan Wikipedia:daftar sistem file terdistribusi), dan sejenisnya. Mereka semua mencoba untuk mengatasi masalah ini dari berbagai arah dengan tingkat keberhasilan yang bervariasi.
Ikhtisar HDFS
Sistem file normal dirancang untuk bekerja pada satu mesin atau satu lingkungan operasi. Kumpulan data di Hadoop membutuhkan kapasitas penyimpanan melebihi apa yang dapat disediakan oleh satu mesin fisik. Oleh karena itu, menjadi penting untuk mempartisi data di sejumlah mesin. Ini memerlukan proses khusus untuk mengelola file di seluruh jaringan terdistribusi. HDFS adalah sistem file yang secara khusus menangani masalah ini. Sistem file ini lebih kompleks daripada sistem file biasa karena harus berurusan dengan pemrograman jaringan, fragmentasi, toleransi kesalahan, kompatibilitas dengan sistem file lokal, dan sebagainya. Ini memberdayakan Hadoop untuk menjalankan aplikasi Big Data di beberapa server. Hal ini ditandai dengan sangat toleran terhadap kesalahan dengan throughput data yang tinggi di seluruh perangkat keras berbiaya rendah. Tujuan dari sistem file HDFS adalah sebagai berikut:
- Untuk menangani file yang sangat besar
- Akses data streaming ke sistem file harus memanfaatkan pola tulis sekali dan baca berkali-kali.
- Berjalan pada perangkat keras komoditas yang murah
- Ini harus memanfaatkan akses data latensi rendah.
- Mendukung sejumlah besar file
- Mendukung banyak penulis file dengan modifikasi file sewenang-wenang
Dasar-dasar HDFS
Jumlah data terkecil yang dibaca dan ditulis ke disk memiliki sesuatu yang disebut ukuran blok . Biasanya, ukuran blok ini adalah 512 byte dan blok sistem file beberapa kilobyte. HDFS bekerja dengan prinsip yang sama, tetapi ukuran blok jauh lebih besar. Ukuran blok yang lebih besar memanfaatkan pencarian dengan meminimalkan pencarian dan oleh karena itu biaya. Blok-blok ini didistribusikan ke seluruh sesuatu yang disebut cluster , yang tidak lain adalah blok dan salinan blok pada server yang berbeda dalam jaringan. File individual direplikasi di seluruh server dalam cluster.
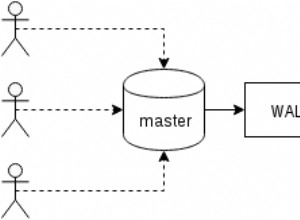
Ada dua jenis node yang beroperasi di cluster dalam pola master-slave. Node master disebut namanode dan node pekerja disebut datanodes . Melalui node ini HDFS memelihara file (dan direktori) sistem pohon dan metadata. Faktanya, sebuah file dipecah menjadi beberapa blok dan disimpan dalam subset datanodes menyebar ke seluruh cluster. kode data bertanggung jawab untuk membaca, menulis, memblokir pembuatan, penghapusan, dan permintaan replikasi dalam sistem file.
namanode , di sisi lain, adalah server yang memantau akses ke sistem file dan memelihara file data di HDFS. Mereka memetakan blok ke datanode dan menangani permintaan membuka, menutup, dan mengganti nama file/direktori.
Datanode adalah bagian inti dari sistem file dan melakukan pekerjaan penyimpanan dan pengambilan permintaan blok dari klien. Node Nama adalah pengelola yang menerima datanodes laporan. Ini berarti bahwa jika node nama dilenyapkan, informasi tentang file akan hilang. Oleh karena itu, Hadoop memastikan bahwa node nama cukup tangguh untuk menahan segala jenis kegagalan. Salah satu teknik untuk memastikannya adalah dengan mencadangkannya di namenode sekunder dengan menggabungkan gambar namespace secara berkala dengan log edit. node nama sekunder biasanya berada di mesin terpisah untuk mengambil alih sebagai namanode utama jika terjadi kegagalan besar.
Ada banyak cara untuk berinteraksi dengan sistem file HDFS, tetapi antarmuka baris perintah mungkin yang paling sederhana dan paling umum. Hadoop dapat diinstal ke satu mesin dan dijalankan untuk merasakannya secara langsung. kami akan membahasnya di artikel berikutnya, jadi pantau terus.
Operasi Sistem File
Operasi sistem file HDFS sangat mirip dengan operasi sistem file normal. Berikut adalah beberapa daftar hanya untuk memberikan gambaran.
Menyalin file dari sistem file lokal ke HDFS:
% hadoop fs -copyFromLocal docs/sales.txt hdfs://localhost/ user/mano/sales.txt
Membuat direktori di HDFS:
% hadoop fs -mkdir students
Mencantumkan file dan direktori di direktori kerja saat ini di HDFS:
% hadoop fs -ls .
Kesimpulan
HDFS adalah implementasi dari apa yang dilakukan oleh sistem file yang diwakili oleh abstraksi Hadoop. Hadoop ditulis dalam bahasa Jawa; karenanya, semua interaksi sistem file diperantarai melalui Java API. Antarmuka baris perintah adalah shell yang disediakan untuk interaksi umum. Studi tentang HDFS membuka cakrawala yang berbeda untuk sektor arsitektur terdistribusi dan prosedur kerjanya yang rumit. Banyak pekerjaan sedang dilakukan untuk menyempurnakan model komputasi ini, yang tidak diragukan lagi adalah Big Data dalam beberapa tahun terakhir.
Referensi
Dokumentasi Arsitektur HDFS