Kita semua membuat kesalahan, dan kita semua bisa belajar dari kesalahan orang lain. Dalam posting ini, kita akan melihat banyak sumber online untuk menghindari desain database yang buruk yang dapat menyebabkan banyak masalah dan menghabiskan waktu dan uang. Dan dalam artikel yang akan datang, kami akan memberi tahu Anda di mana menemukan tips dan praktik terbaik.
Kesalahan dan Kesalahan Desain Basis Data yang Harus Dihindari
Ada banyak sumber daya online untuk membantu perancang basis data menghindari kesalahan dan kesalahan umum. Jelas, artikel ini bukan daftar lengkap dari setiap artikel di luar sana. Sebagai gantinya, kami telah meninjau dan mengomentari berbagai sumber yang berbeda sehingga Anda dapat menemukan yang paling cocok untuk Anda.
Rekomendasi kami
Jika hanya ada satu artikel di antara sumber-sumber ini yang akan Anda baca, artikel tersebut seharusnya 'Cara Membuat Desain Basis Data Salah yang Mengerikan' dari Robert Sheldon
Mari kita mulai dengan blog DATAVERSITY yang menyediakan berbagai sumber daya yang cukup bagus:
Kesalahan Kunci Utama dan Kunci Asing yang Harus Dihindari
oleh Michael Blaha | blog DATAVERSITAS | 2 September 2015
Lebih Banyak Kesalahan Desain Basis Data – Kebingungan dengan Hubungan Banyak-ke-Banyak
oleh Michael Blaha | blog DATAVERSITAS | 30 September 2015
Kesalahan Desain Basis Data Lain-Lain
oleh Michael Blaha | blog DATAVERSITAS | 26 Oktober 2015
Michael Blaha telah menyumbangkan satu set tiga artikel yang bagus. Setiap artikel membahas perangkap yang berbeda dari pemodelan database dan desain fisik; topik termasuk kunci, hubungan, dan kesalahan umum. Selain itu, ada diskusi dengan Michael mengenai beberapa poin. Jika Anda mencari jebakan seputar kunci dan hubungan, ini adalah tempat yang baik untuk memulai.
Mr Blaha menyatakan bahwa "sekitar 20% dari database melanggar aturan kunci utama". Wow! Itu berarti bahwa sekitar 20% pengembang basis data tidak membuat kunci utama dengan benar. Jika statistik ini benar, maka itu benar-benar menunjukkan pentingnya alat pemodelan data yang sangat "mendorong" atau bahkan mengharuskan pemodel untuk mendefinisikan kunci utama.
Mr Blaha juga berbagi heuristik bahwa "sekitar 50% dari database" memiliki masalah kunci asing (menurut pengalamannya dengan database warisan yang telah ia pelajari). Dia mengingatkan kita untuk menghindari hubungan informal antar tabel dengan menyematkan nilai dari satu tabel ke tabel lain daripada menggunakan kunci asing.
Saya telah melihat masalah ini berkali-kali. Saya akui bahwa hubungan informal dapat diperlukan oleh fungsionalitas yang akan diimplementasikan, tetapi lebih sering terjadi karena kemalasan sederhana. Misalnya, kita mungkin ingin menunjukkan id pengguna seseorang yang memodifikasi sesuatu, jadi kita menyimpan id pengguna langsung di tabel. Tetapi bagaimana jika pengguna itu mengubah id penggunanya? Kemudian hubungan informal ini terputus. Hal ini sering kali disebabkan oleh desain dan pemodelan yang buruk.
Mendesain Basis Data Anda:5 Kesalahan Teratas yang Harus Dihindari
oleh Henrique Netzka | blog DATAVERSITAS | 2 November 2015
Saya sedikit kecewa dengan artikel ini, karena artikel ini memiliki beberapa item yang cukup spesifik (menyimpan protokol dalam CLOB) dan beberapa yang sangat umum (pikirkan tentang lokalisasi). Secara keseluruhan, artikelnya baik-baik saja, tetapi apakah ini benar-benar 5 kesalahan teratas yang harus dihindari? Menurut saya, ada beberapa kesalahan umum lainnya yang seharusnya masuk daftar.
Namun, sebagai catatan positif, ini adalah salah satu dari sedikit artikel yang menyebutkan globalisasi dan lokalisasi secara bermakna. Saya bekerja di lingkungan yang sangat multi-bahasa dan telah melihat beberapa implementasi lokalisasi yang mengerikan, jadi saya senang menemukan masalah ini disebutkan. Kolom bahasa dan kolom zona waktu mungkin tampak jelas, tetapi sangat jarang muncul dalam model database.
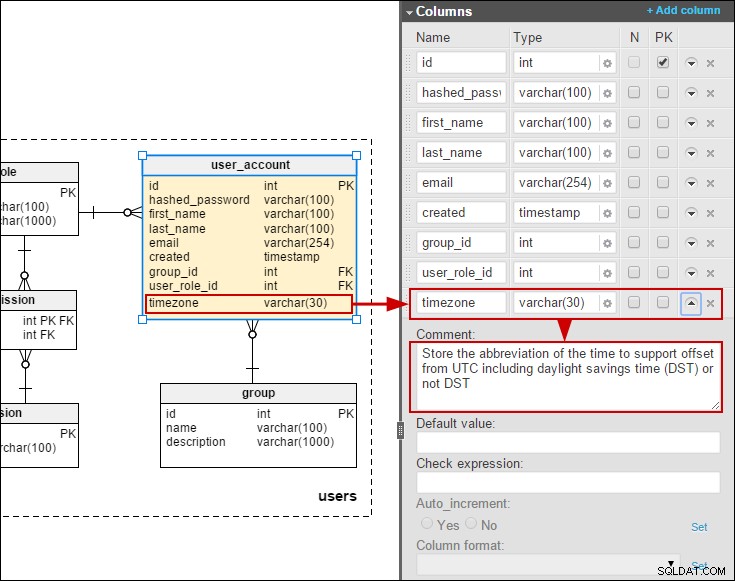
Karena itu, saya pikir akan menarik untuk membuat model termasuk terjemahan yang dapat diubah oleh pengguna akhir (sebagai lawan menggunakan kumpulan sumber daya). Beberapa waktu yang lalu, saya menulis tentang model untuk database survei online. Di sini saya telah membuat model terjemahan pertanyaan dan pilihan jawaban yang disederhanakan:
Dengan asumsi bahwa kita harus mengizinkan pengguna akhir untuk memelihara terjemahan, metode yang lebih disukai adalah menambahkan tabel terjemahan untuk pertanyaan dan tanggapan:
Saya juga telah menambahkan zona waktu ke user_account tabel sehingga kami dapat menyimpan tanggal/waktu dalam waktu lokal pengguna:
7 kesalahan desain database yang umum
oleh Grzegorz Kaczor | Vertabelo blog | 17 Juli 2015
Saya akan membuat sedikit promosi diri di sini. Kami berusaha untuk secara teratur memposting artikel yang menarik dan menarik di sini.
Artikel khusus ini menunjukkan beberapa area penting yang menjadi perhatian, seperti penamaan, pengindeksan, pertimbangan volume, dan jejak audit. Artikel tersebut bahkan membahas masalah yang terkait dengan sistem DBM tertentu, seperti batasan Oracle pada nama tabel. Saya sangat menyukai contoh yang jelas dan bagus, bahkan jika itu menggambarkan bagaimana desainer membuat kesalahan dan kesalahan.
Jelas tidak mungkin untuk membuat daftar setiap kesalahan desain, dan kesalahan yang tercantum mungkin bukan Anda kesalahan paling umum. Ketika kami menulis tentang kesalahan umum, kesalahan yang kami buat atau temukan dalam karya orang lain itulah yang kami gambarkan. Daftar lengkap kesalahan, yang diurutkan berdasarkan frekuensi, tidak mungkin dikompilasi oleh satu orang. Namun demikian, saya pikir artikel ini memberikan beberapa wawasan berguna tentang potensi jebakan. Ini adalah sumber daya yang bagus secara keseluruhan.
Sementara Mr Kaczor membuat beberapa poin menarik dalam artikelnya, saya menemukan komentarnya tentang "tidak mempertimbangkan kemungkinan volume atau lalu lintas" cukup menarik. Secara khusus, rekomendasi untuk memisahkan data yang sering digunakan dari data historis sangat relevan. Ini adalah solusi yang sering kami gunakan dalam aplikasi perpesanan kami; kita harus memiliki riwayat yang dapat dicari dari semua pesan, tetapi pesan yang paling mungkin diakses adalah yang telah diposting dalam beberapa hari terakhir. Jadi memisahkan data “aktif” atau terbaru yang sering diakses (volume data yang jauh lebih kecil) dari data historis jangka panjang (data dalam jumlah besar) umumnya merupakan teknik yang sangat baik.
Kesalahan Umum Desain Basis Data
oleh Troy Blake | Blog DBA senior | 11 Juli 2015
Artikel Troy Blake adalah sumber lain yang bagus, meskipun saya mungkin telah menamai artikel ini "Kesalahan Desain SQL Server Umum".
Misalnya, kami memiliki komentar:"prosedur tersimpan adalah teman terbaik Anda dalam hal menggunakan SQL Server secara efektif". Tidak apa-apa, tetapi apakah ini kesalahan umum yang umum, atau lebih spesifik untuk SQL Server? Saya harus memilih ini menjadi sedikit khusus SQL Server, karena ada kerugian menggunakan prosedur tersimpan, seperti berakhir dengan prosedur tersimpan khusus vendor dan dengan demikian penguncian vendor. Jadi saya tidak suka memasukkan “Tidak Menggunakan Prosedur Tersimpan” dalam daftar ini.
Namun, sisi positifnya, menurut saya penulis memang mengidentifikasi beberapa kesalahan yang sangat umum, seperti perencanaan yang buruk, desain sistem yang buruk, dokumentasi yang terbatas, standar penamaan yang lemah, dan kurangnya pengujian.
Jadi saya akan mengklasifikasikan ini sebagai referensi yang sangat berguna untuk praktisi SQL Server dan referensi yang berguna untuk orang lain.
Tujuh Kesalahan Pemodelan Data
oleh Kurt Cagle | LinkedIn | 12 Juni 2015
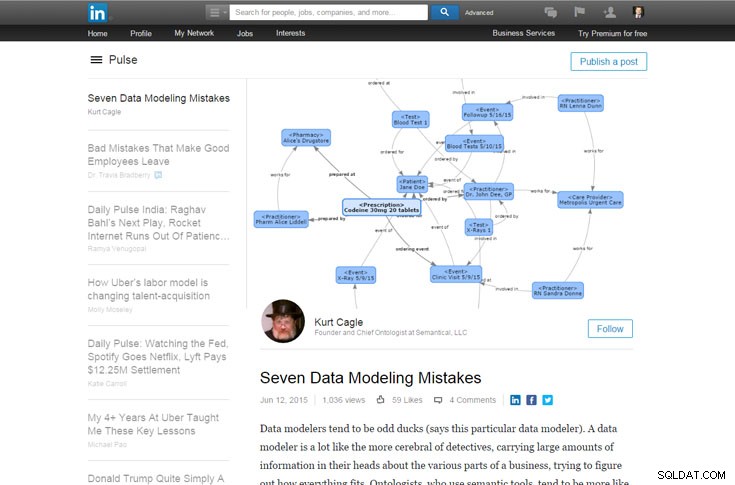
Saya sangat senang membaca daftar kesalahan pemodelan basis data Mr. Cagle. Ini dari pandangan arsitek database; dia dengan jelas mengidentifikasi kesalahan pemodelan tingkat tinggi yang harus dihindari. Dengan tampilan gambar yang lebih besar ini, Anda dapat membatalkan potensi kekacauan pemodelan.
Beberapa jenis yang disebutkan dalam artikel dapat ditemukan di tempat lain, tetapi beberapa di antaranya unik:terlalu dini abstrak atau mencampur model konseptual, logis, dan fisik. Itu tidak sering disebutkan oleh penulis lain, mungkin karena mereka berfokus pada proses pemodelan data daripada tampilan sistem yang lebih besar.
Secara khusus, contoh "Menjadi Terlalu Abstrak Terlalu Dini" menggambarkan proses pemikiran yang menarik untuk membuat beberapa contoh "cerita" dan menguji hubungan mana yang penting dalam domain ini. Ini memfokuskan pemikiran pada hubungan antara objek yang dimodelkan. Ini menghasilkan pertanyaan seperti apa hubungan penting dalam domain ini ?
Berdasarkan pemahaman ini, kami membuat model seputar hubungan daripada memulai pada item domain individual dan membangun hubungan di atasnya. Sementara banyak dari kita mungkin menggunakan pendekatan ini, di antara sumber-sumber ini tidak ada penulis lain yang mengomentarinya. Menurut saya deskripsi dan contoh ini cukup menarik.
Cara Membuat Desain Basis Data Sangat Salah
oleh Robert Sheldon | Pembicaraan Sederhana | 6 Maret 2015
Jika hanya ada satu artikel di antara sumber-sumber ini yang akan Anda baca, artikel ini seharusnya dari Robert Sheldon
Yang sangat saya sukai dari artikel ini adalah bahwa untuk setiap kesalahan yang disebutkan ada tips tentang cara melakukannya dengan benar. Sebagian besar fokus pada menghindari kegagalan daripada memperbaikinya, tetapi saya masih berpikir bahwa mereka sangat berguna. Ada sangat sedikit teori di sini; sebagian besar jawaban langsung tentang menghindari kesalahan saat pemodelan data. Ada beberapa poin SQL Server tertentu, tetapi kebanyakan SQL Server digunakan untuk memberikan contoh penghindaran kesalahan atau jalan keluar dari kegagalan.
Cakupan artikelnya juga cukup luas:mencakup mengabaikan perencanaan, tidak repot dengan dokumentasi, menggunakan konvensi penamaan yang buruk, mengalami masalah dalam normalisasi (terlalu banyak atau terlalu sedikit), gagal pada kunci dan batasan, tidak mengindeks dengan benar, dan melakukan pengujian yang tidak memadai.
Secara khusus, saya menyukai saran praktis mengenai integritas data – kapan harus menggunakan batasan pemeriksaan dan kapan harus mendefinisikan kunci asing. Selain itu, Mr. Sheldon juga menjelaskan situasi ketika tim tunduk pada aplikasi untuk menegakkan integritas. Dia langsung pada titik ketika dia menyatakan bahwa database dapat diakses dengan berbagai cara dan oleh banyak aplikasi. Dia menyimpulkan bahwa "data harus dilindungi di mana ia berada:di dalam database". Hal ini sangat benar sehingga dapat diulangi kepada tim pengembangan dan manajer untuk menjelaskan pentingnya penerapan pemeriksaan integritas dalam model data.
Ini adalah jenis artikel saya, dan Anda dapat mengatakan bahwa orang lain setuju berdasarkan banyak komentar yang mendukungnya. Jadi, nilai tertinggi di sini; itu adalah sumber daya yang sangat berharga.
Sepuluh Kesalahan Umum Desain Basis Data
oleh Louis Davidson | Pembicaraan Sederhana | 26 Februari 2007
Saya menemukan artikel ini cukup bagus, karena mencakup banyak kesalahan desain umum. Ada analogi yang bermakna, contoh, model, dan bahkan beberapa kutipan klasik dari William Shakespeare dan J.R.R. Tolkien.
Beberapa kesalahan dijelaskan secara lebih rinci daripada yang lain, dengan contoh panjang dan kutipan SQL yang menurut saya agak rumit. Tapi itu masalah selera.
Sekali lagi, kami memiliki beberapa topik khusus untuk SQL Server. Misalnya, tujuan tidak menggunakan Prosedur Tersimpan untuk mengakses data adalah baik untuk SQL, tetapi SP tidak selalu merupakan ide yang baik jika tujuannya adalah untuk mendukung banyak DBMS. Selain itu, kami diperingatkan untuk tidak mencoba mengkode objek T-SQL generik. Karena saya jarang bekerja dengan SQL Server atau Sybase, saya tidak menemukan tip ini relevan.
Daftar ini sangat mirip dengan daftar Robert Sheldon, tetapi jika Anda terutama bekerja pada SQL Server, Anda akan menemukan beberapa informasi tambahan.
Lima Kesalahan Desain Basis Data Sederhana yang Harus Anda Hindari
oleh Anith Sen Larson | Pembicaraan Sederhana | 16 Oktober 2009
Artikel ini memberikan beberapa contoh yang berarti untuk setiap kesalahan desain sederhana yang dicakupnya. Di sisi lain, ini agak terfokus pada jenis kesalahan yang serupa:tabel pencarian umum, tabel nilai atribut entitas, dan pemisahan atribut.
Pengamatannya baik-baik saja, dan artikel itu bahkan memiliki referensi, yang cenderung jarang. Namun, saya ingin melihat kesalahan desain database yang lebih umum. Kesalahan ini tampak agak spesifik, tetapi, seperti yang telah saya tulis, kesalahan yang kami tulis umumnya adalah kesalahan yang kami alami secara pribadi.
Satu item yang saya sukai adalah aturan praktis khusus untuk memutuskan kapan harus menggunakan batasan cek versus tabel terpisah dengan batasan kunci asing. Beberapa penulis memberikan rekomendasi serupa, tetapi Larson membaginya menjadi "keharusan", "pertimbangan" dan "kasus kuat" - dengan pengakuan bahwa "desain adalah campuran seni dan sains dan oleh karena itu melibatkan pengorbanan". Menurut saya ini sangat benar.
Sepuluh Kesalahan Desain Basis Data Fisik Paling Umum
oleh Craig Mullins | Data dan Teknologi Saat Ini | 5 Agustus 2013
Seperti namanya, "Sepuluh Kesalahan Desain Basis Data Fisik Paling Umum" sedikit lebih berorientasi pada desain fisik daripada desain logis dan konseptual. Tidak ada kesalahan yang disebutkan oleh penulis Craig Mullins yang benar-benar menonjol atau unik, jadi saya akan merekomendasikan informasi ini kepada orang-orang yang bekerja di sisi DBA fisik.
Selain itu, deskripsinya agak pendek, sehingga terkadang sulit untuk melihat mengapa kesalahan tertentu akan menyebabkan masalah. Tidak ada yang salah dengan deskripsi singkat, tetapi mereka tidak memberi Anda banyak hal untuk dipikirkan. Dan tidak ada contoh yang disajikan.
Ada satu hal menarik yang diangkat terkait dengan kegagalan berbagi data. Poin ini kadang-kadang disebutkan dalam artikel lain, tetapi bukan sebagai kesalahan desain. Namun, saya sering melihat masalah ini dengan database yang "dibuat ulang" berdasarkan persyaratan yang sangat mirip, tetapi oleh tim baru atau untuk produk baru
.Sering terjadi bahwa tim produk kemudian menyadari bahwa mereka ingin menggunakan data yang sudah ada di "bapak" database mereka saat ini. Namun, pada kenyataannya, mereka seharusnya meningkatkan induk daripada menciptakan keturunan baru. Aplikasi dimaksudkan untuk berbagi data; desain yang baik dapat memungkinkan database untuk digunakan kembali lebih sering.
Apakah Anda melakukan 5 kesalahan desain database ini?
oleh Thomas Larock | Blog Thomas Larock | 2 Januari 2012
Anda mungkin menemukan beberapa poin menarik saat menjawab pertanyaan Thomas Larock:Apakah Anda Melakukan 5 Kesalahan Desain Database Ini?
Artikel ini agak berat untuk kunci (kunci asing, kunci pengganti, dan kunci yang dihasilkan). Namun, ia memiliki satu poin penting:orang tidak boleh berasumsi bahwa fitur DBMS sama di semua sistem. Saya pikir ini adalah poin yang sangat bagus. Ini juga salah satu yang tidak ditemukan di sebagian besar artikel lain, mungkin karena banyak penulis fokus dan bekerja terutama dengan satu DBMS.
Mendesain Basis Data:7 Hal yang Tidak Ingin Anda Lakukan
oleh Thomas Larock | Blog Thomas Larock | 16 Januari 2013
Pak Larock mendaur ulang beberapa "5 Kesalahan Desain Basis Data" saat menulis "7 Hal yang Tidak Ingin Anda Lakukan", tetapi ada poin bagus lainnya di sini.
Menariknya, beberapa poin yang dibuat Pak Larock tidak banyak ditemukan di sumber lain. Anda mendapatkan beberapa pengamatan yang agak unik, seperti "tidak memiliki ekspektasi kinerja". Ini adalah kesalahan serius dan, berdasarkan pengalaman saya, cukup sering terjadi. Bahkan ketika mengembangkan kode aplikasi, seringkali setelah model data, database, dan aplikasi itu sendiri telah dibuat, orang-orang mulai berpikir tentang persyaratan non-fungsional (ketika tes non-fungsional harus dibuat) dan mulai mendefinisikan ekspektasi kinerja. .
Sebaliknya, ada beberapa poin yang tidak akan saya masukkan dalam daftar Sepuluh Besar saya sendiri, seperti “menjadi besar, berjaga-jaga”. Saya mengerti maksudnya, tetapi itu tidak terlalu tinggi dalam daftar saya saat membuat model data. Tidak ada kekhususan untuk sistem DBM tertentu, jadi itu adalah bonus.
Sebagai kesimpulan, banyak dari poin-poin ini dapat diringkas di bawah poin:“tidak memahami persyaratan”, yang sebenarnya ada dalam daftar 10 kesalahan teratas saya.
Cara Menghindari 8 Kesalahan Umum Pengembangan Database
oleh Base36 | 6 Desember 2012
Saya cukup tertarik membaca artikel ini. Namun, saya agak kecewa. Tidak banyak diskusi tentang penghindaran, dan inti dari artikel tersebut tampaknya adalah “ini adalah kesalahan database yang umum” dan “mengapa itu adalah kesalahan”; deskripsi tentang cara menghindari kesalahan kurang menonjol.
Selain itu, beberapa dari 8 kesalahan teratas artikel sebenarnya diperdebatkan. Penyalahgunaan kunci utama adalah contohnya. Base36 memberi tahu kita bahwa mereka harus dihasilkan oleh sistem dan bukan berdasarkan data aplikasi di baris. Meskipun saya setuju dengan ini sampai titik tertentu, saya tidak yakin bahwa semua PK harus selalu dihasilkan; itu agak terlalu kategoris.
Di sisi lain, kesalahan "Hard Deletes" menarik dan tidak sering disebutkan di tempat lain. Penghapusan lunak memang menyebabkan masalah lain, tetapi memang benar bahwa hanya menandai baris sebagai tidak aktif memang memiliki keuntungan saat Anda mencoba mencari tahu ke mana perginya data yang ada di sistem kemarin. Mencari melalui log transaksi bukanlah ide saya tentang cara yang menyenangkan untuk menghabiskan hari.
Tujuh Dosa Desain Database yang Mematikan
oleh Jason Tiret | Jurnal Sistem Perusahaan | 16 Februari 2010
Saya cukup berharap ketika saya mulai membaca artikel Jason Tiret, “Tujuh Dosa Mematikan dari Desain Basis Data”. Jadi saya senang menemukan bahwa itu tidak hanya mendaur ulang kesalahan yang ditemukan di banyak artikel lain. Sebaliknya, itu menawarkan "dosa" yang tidak saya temukan di daftar lain:mencoba melakukan semua desain basis data "di depan" dan tidak memperbarui model setelah basis data dalam produksi, ketika perubahan dilakukan pada basis data. (Atau, seperti yang dikatakan Jason, "Tidak memperlakukan model data seperti organisme yang hidup dan bernafas").
Saya telah melihat kesalahan ini berkali-kali. Kebanyakan orang hanya menyadari kesalahan mereka ketika mereka harus memperbarui model yang tidak lagi cocok dengan database sebenarnya. Tentu saja, hasilnya adalah model yang tidak berguna. Seperti yang dinyatakan dalam artikel tersebut, “perubahan perlu menemukan jalan kembali ke model”.
Di sisi lain, sebagian besar item daftar Jason cukup terkenal. Deskripsinya bagus, tetapi contoh-contohnya tidak terlalu banyak. Lebih banyak contoh dan detail akan berguna.
Kesalahan Desain Database yang Paling Umum
oleh Brian Prince | eWeek.com | 19 Maret 2008

Artikel “Kesalahan Desain Database Paling Umum” sebenarnya adalah serangkaian slide dari sebuah presentasi. Ada beberapa pemikiran yang menarik, tetapi beberapa item unik mungkin sedikit esoteris. Saya memikirkan poin-poin seperti “Mengenal RAID” dan keterlibatan pemangku kepentingan.
Secara umum, saya tidak akan memasukkan ini ke dalam daftar bacaan Anda kecuali Anda berfokus pada masalah umum (perencanaan, penamaan, normalisasi, indeks) dan detail fisik.
10 kesalahan desain yang umum
oleh davidm | Blog SQL Server – SQLTeam.com | 12 September 2005
Beberapa poin dalam "Sepuluh kesalahan desain umum" menarik dan relatif baru. Namun, beberapa kesalahan ini cukup kontroversial, seperti "menggunakan NULL" dan de-normalisasi.
Saya setuju bahwa membuat semua kolom sebagai nullable adalah kesalahan, tetapi mendefinisikan kolom sebagai nullable mungkin diperlukan untuk fungsi bisnis tertentu. Oleh karena itu, dapatkah itu dianggap sebagai kesalahan umum? Saya rasa tidak.
Poin lain yang saya permasalahkan adalah de-normalisasi. Ini tidak selalu merupakan kesalahan desain. Misalnya, denormalisasi mungkin diperlukan karena alasan kinerja.
Artikel ini juga sebagian besar kurang detail dan contoh. Percakapan antara DBA dan programmer atau manajer lucu, tetapi saya lebih suka contoh yang lebih konkret dan pembenaran yang mendetail untuk kesalahan umum ini.
OTLT dan EAV:dua kesalahan desain besar yang dilakukan semua pemula
oleh Tony Andrews | Tony Andrews di Oracle dan Database | 21 Oktober 2004
Artikel Pak Andrews mengingatkan kita pada kesalahan “One True Lookup Table” (OTLT) dan Entity-Attribute-Value (EAV) yang disebutkan di artikel lain. Satu poin bagus tentang presentasi ini adalah bahwa presentasi ini berfokus pada dua kesalahan ini, jadi deskripsi dan contoh tepat. Selain itu, penjelasan yang mungkin tentang mengapa beberapa desainer menerapkan OTLT dan EAV diberikan.
Untuk mengingatkan Anda, tabel OTLT biasanya terlihat seperti ini, dengan entri dari beberapa domain dimasukkan ke dalam tabel yang sama:
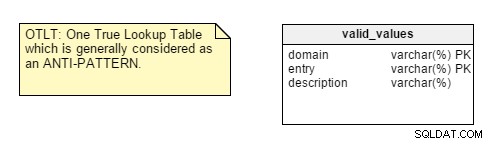
Seperti biasa, ada diskusi seputar apakah OTLT adalah solusi yang bisa diterapkan dan pola desain yang baik. Saya harus mengatakan bahwa saya berpihak pada kelompok anti-OTLT; tabel ini memperkenalkan banyak masalah. Kita mungkin menggunakan analogi menggunakan enumerator tunggal untuk mewakili semua nilai yang mungkin dari semua konstanta yang mungkin. Saya belum pernah melihat itu, sejauh ini.
Kesalahan Basis Data Umum
oleh John Paul Ashenfelter | Dr. Dobb | 01 Januari 2002
Artikel Mr. Ashenfelter mencantumkan 15 kesalahan database yang umum terjadi. Bahkan ada beberapa kesalahan yang tidak sering disebutkan di artikel lain. Sayangnya, deskripsinya relatif singkat dan tidak ada contoh. Kelebihan artikel ini adalah daftarnya mencakup banyak hal dan dapat digunakan sebagai "daftar periksa" kesalahan yang harus dihindari. Meskipun saya mungkin tidak mengklasifikasikan ini sebagai kesalahan basis data yang paling penting, kesalahan tersebut tentu saja termasuk yang paling umum.
Sebagai catatan positif, ini adalah salah satu dari sedikit artikel yang menyebutkan perlunya menangani internasionalisasi format untuk data seperti tanggal, mata uang, dan alamat. Contoh akan bagus di sini. Ini bisa sesederhana “pastikan bahwa Negara adalah kolom yang dapat dibatalkan; di banyak negara, tidak ada negara bagian yang terkait dengan alamat”.
Sebelumnya dalam artikel ini, saya menyebutkan masalah lain dan beberapa pendekatan untuk mempersiapkan globalisasi database Anda, seperti zona waktu dan terjemahan (lokalisasi). Fakta bahwa tidak ada artikel lain yang menyebutkan masalah mata uang dan format tanggal sangat mengganggu. Apakah database kami siap untuk penggunaan global aplikasi kami?
Sebutan Terhormat
Jelas, ada artikel lain yang menjelaskan kesalahan dan kesalahan desain basis data umum, tetapi kami ingin memberi Anda tinjauan luas tentang sumber daya yang berbeda. Anda dapat menemukan informasi tambahan dalam artikel seperti:
10 Kesalahan Umum Desain Database | Blog Kelas MIS | 29 Januari 2012
10 Kesalahan Umum dalam Desain Basis Data | IDG.se | 24 Juni 2010
Sumber Daya Online:Mulai dari mana? Ke mana harus pergi?
Seperti disebutkan sebelumnya, daftar ini jelas tidak dimaksudkan sebagai pemeriksaan menyeluruh dari setiap artikel online yang menjelaskan kesalahan dan kesalahan desain basis data. Sebaliknya, kami telah mengidentifikasi beberapa sumber yang sangat berguna atau memiliki fokus khusus yang mungkin berguna bagi Anda.
Silakan merekomendasikan artikel tambahan.