Di blog sebelumnya, saya dan kolega saya menunjukkan kepada Anda bagaimana Anda dapat memantau kinerja, mengelola dan menerapkan cluster, menjalankan pencadangan, dan bahkan mengaktifkan failover otomatis untuk TimescaleDB.
Di blog ini kami akan menunjukkan cara menskalakan instans TimescaleDB tunggal Anda ke cluster multi-simpul hanya dalam beberapa langkah sederhana.
Kami akan mulai dengan pengaturan umum, instance node tunggal yang berjalan di CentosOS. Node sedang aktif dan berjalan dan sudah dipantau dan dikelola oleh ClusterControl.
Jika Anda ingin mempelajari cara menerapkan atau mengimpor instans TimescaleDB Anda, lihat blog yang ditulis oleh rekan saya Sebastian Insausti, “Cara Mudah Menyebarkan TimescaleDB.”
Pengaturannya terlihat sebagai berikut...
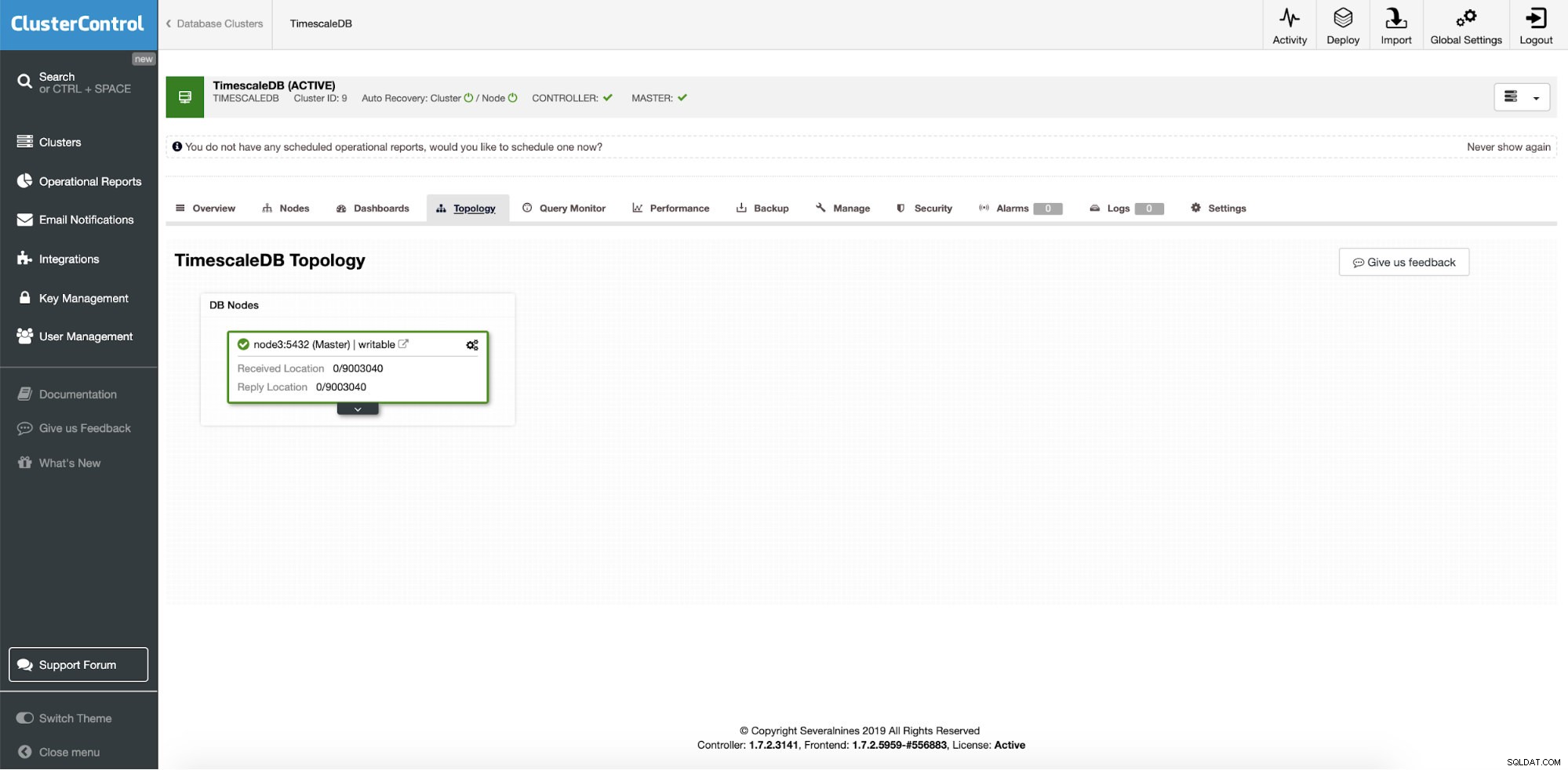 ClusterControl:TimescaleDB contoh tunggal
ClusterControl:TimescaleDB contoh tunggal Jadi, ini adalah instance produksi tunggal dan kami ingin mengonversinya menjadi cluster tanpa waktu henti. Tujuan utama kami adalah untuk menskalakan operasi pembacaan aplikasi ke mesin lain dengan opsi untuk menggunakannya sebagai pementasan server HA saat menulis server mogok.
Lebih banyak node juga akan mengurangi waktu henti pemeliharaan aplikasi. Seperti patching yang diterapkan dalam mode rolling restart - satu node ditambal pada saat itu sementara node lain melayani koneksi database.
Persyaratan terakhir adalah membuat satu alamat untuk cluster baru kita sehingga node baru kita akan terlihat untuk aplikasi dari satu tempat.

Kami dapat meringkas rencana tindakan kami menjadi dua langkah utama:
- Menambahkan replika bacaan
- Instal dan konfigurasikan Haproxy
Menambahkan Replika Bacaan
Jika kita masuk ke tindakan cluster dan memilih “Add Replication Slave”, kita dapat membuat replika baru dari awal atau menambahkan database TimescaleDB yang ada sebagai replika.
 ClusterControl:Tambahkan budak replikasi
ClusterControl:Tambahkan budak replikasi 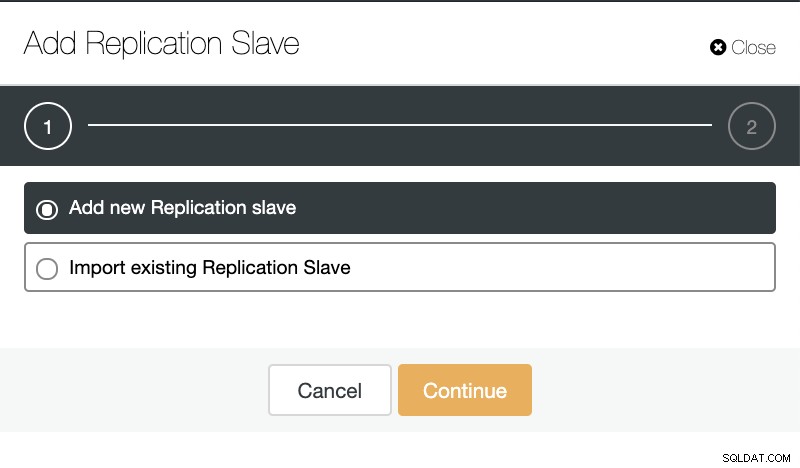 ClusterControl:Tambahkan budak Replikasi baru, Impor Budak Replikasi yang ada
ClusterControl:Tambahkan budak Replikasi baru, Impor Budak Replikasi yang ada Seperti yang Anda lihat pada gambar di bawah, kita hanya perlu memilih server Master, masukkan alamat IP untuk server slave baru dan port database.
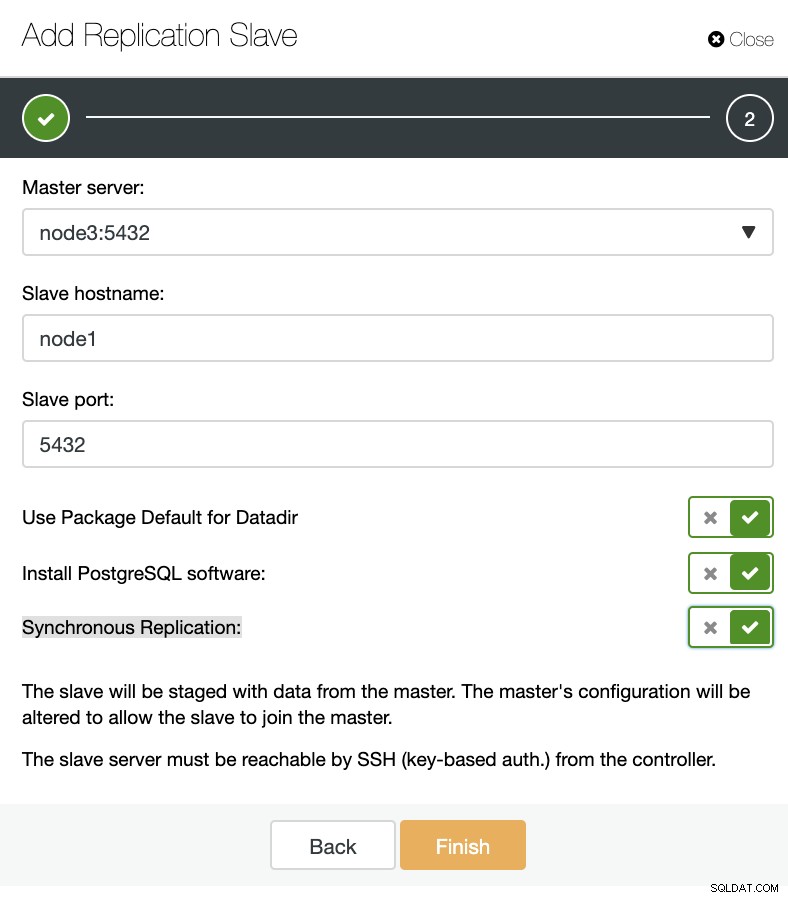 ClusterControl:Tambahkan budak replikasi
ClusterControl:Tambahkan budak replikasi Kemudian kita dapat memilih apakah kita ingin ClusterControl menginstal perangkat lunak untuk kita dan jika slave replikasi harus Synchronous atau Asynchronous. Saat Anda mengimpor server budak yang ada, Anda dapat menggunakan opsi impor sebagai berikut:
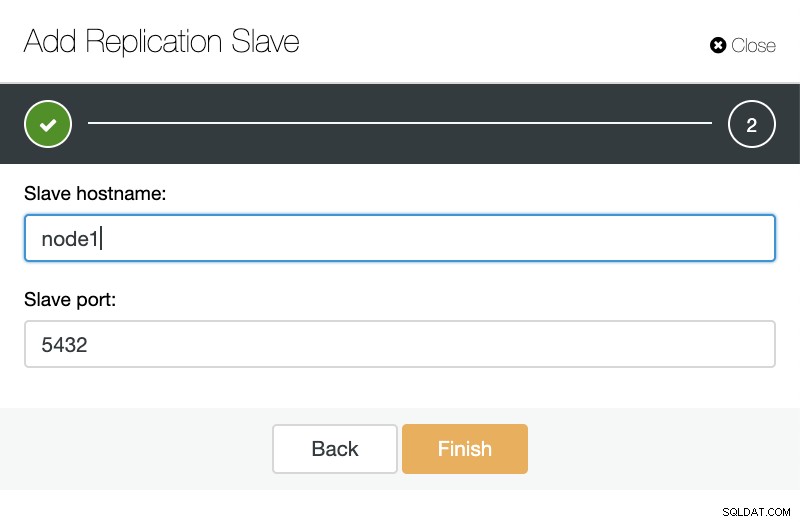 ClusterControl:Impor replikasi budak untuk TimescaleDB
ClusterControl:Impor replikasi budak untuk TimescaleDB Kedua cara, kita dapat menambahkan replika sebanyak yang kita inginkan. Dalam contoh kasus kami, kami akan menambahkan dua node. CusterControl akan membuat tugas internal dan menangani semua langkah yang diperlukan tanpa satu pun dalam satu waktu.
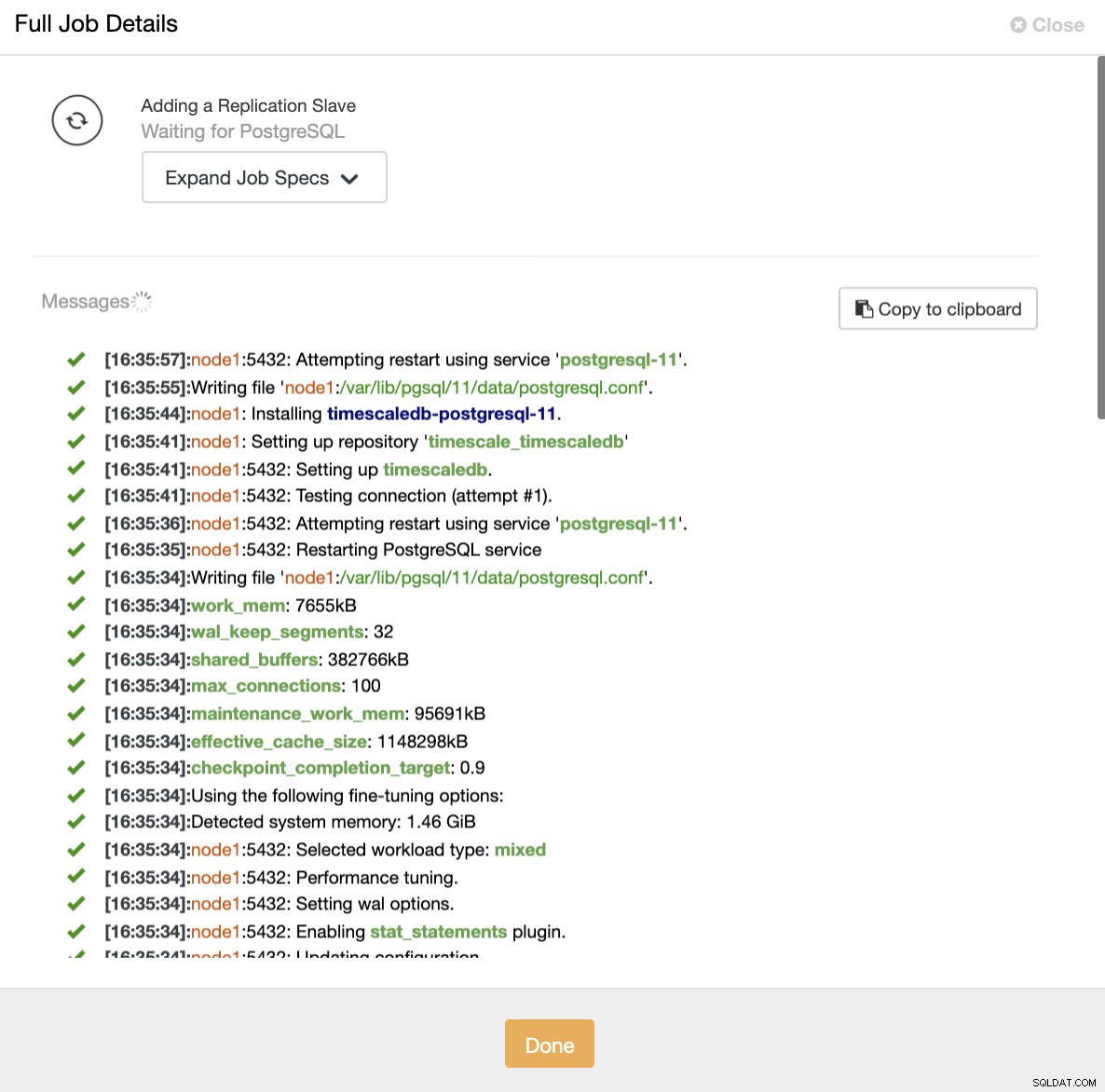 ClusterControl:tambahkan replika baca
ClusterControl:tambahkan replika baca Menambahkan Load Balancer ke TimescaleDB
Pada titik ini, data kami didistribusikan di beberapa node atau pusat data jika Anda memilih untuk menambahkan node slave replikasi di lokasi yang berbeda. Cluster diskalakan dengan dua node replika baca tambahan.
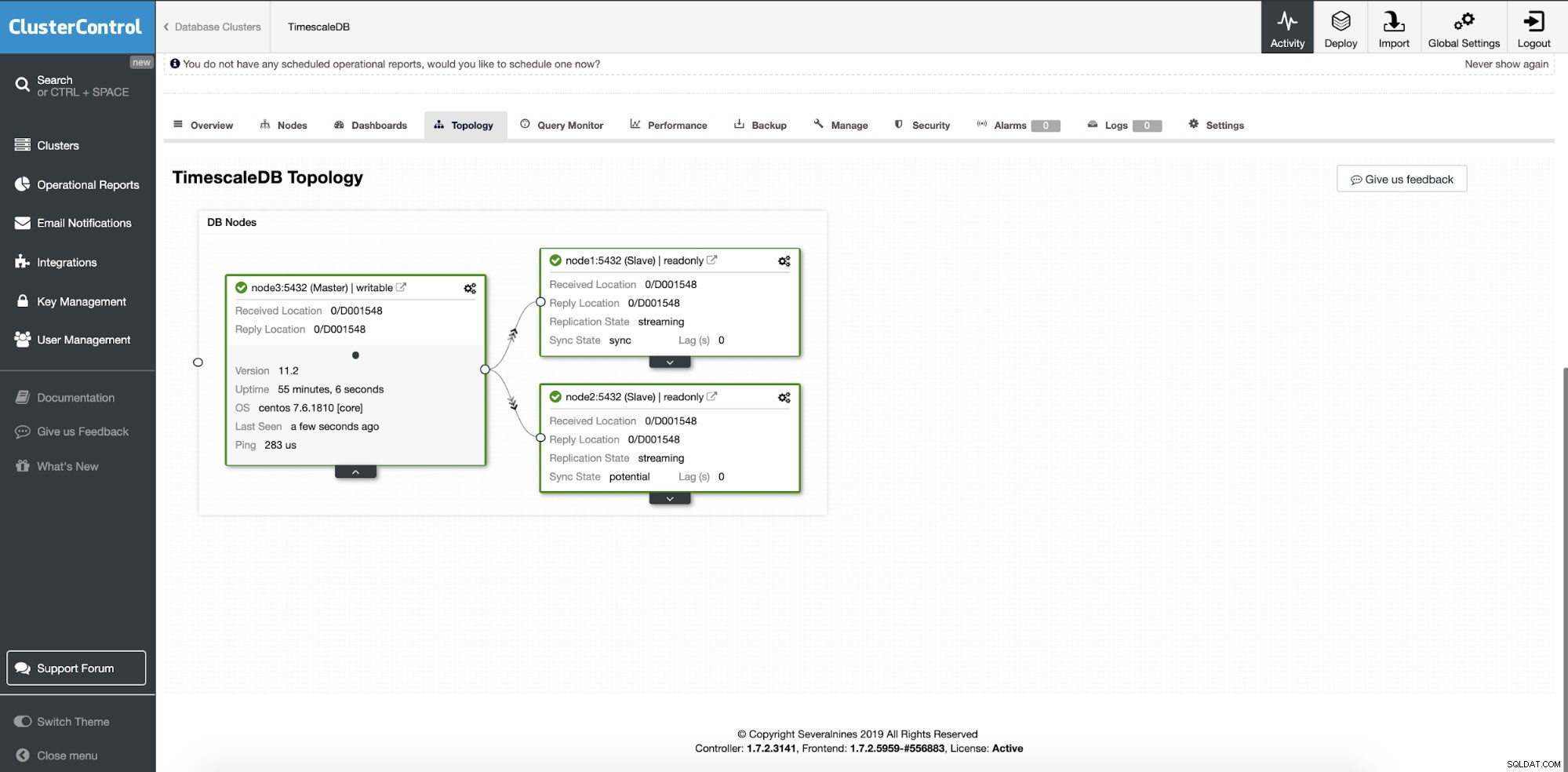 ClusterControl:Dua node ditambahkan
ClusterControl:Dua node ditambahkan Pertanyaannya adalah bagaimana aplikasi mengetahui node database mana yang harus diakses? Kami akan menggunakan HAProxy dan port yang berbeda untuk operasi tulis dan baca.
Dari klaster TimescaleDB, menu konteks memilih untuk menambahkan penyeimbang beban.

Sekarang kita perlu memberikan lokasi server tempat Haproxy harus diinstal, kebijakan apa yang ingin kita gunakan untuk koneksi database dan node mana yang mengambil bagian dari konfigurasi Haproxy.
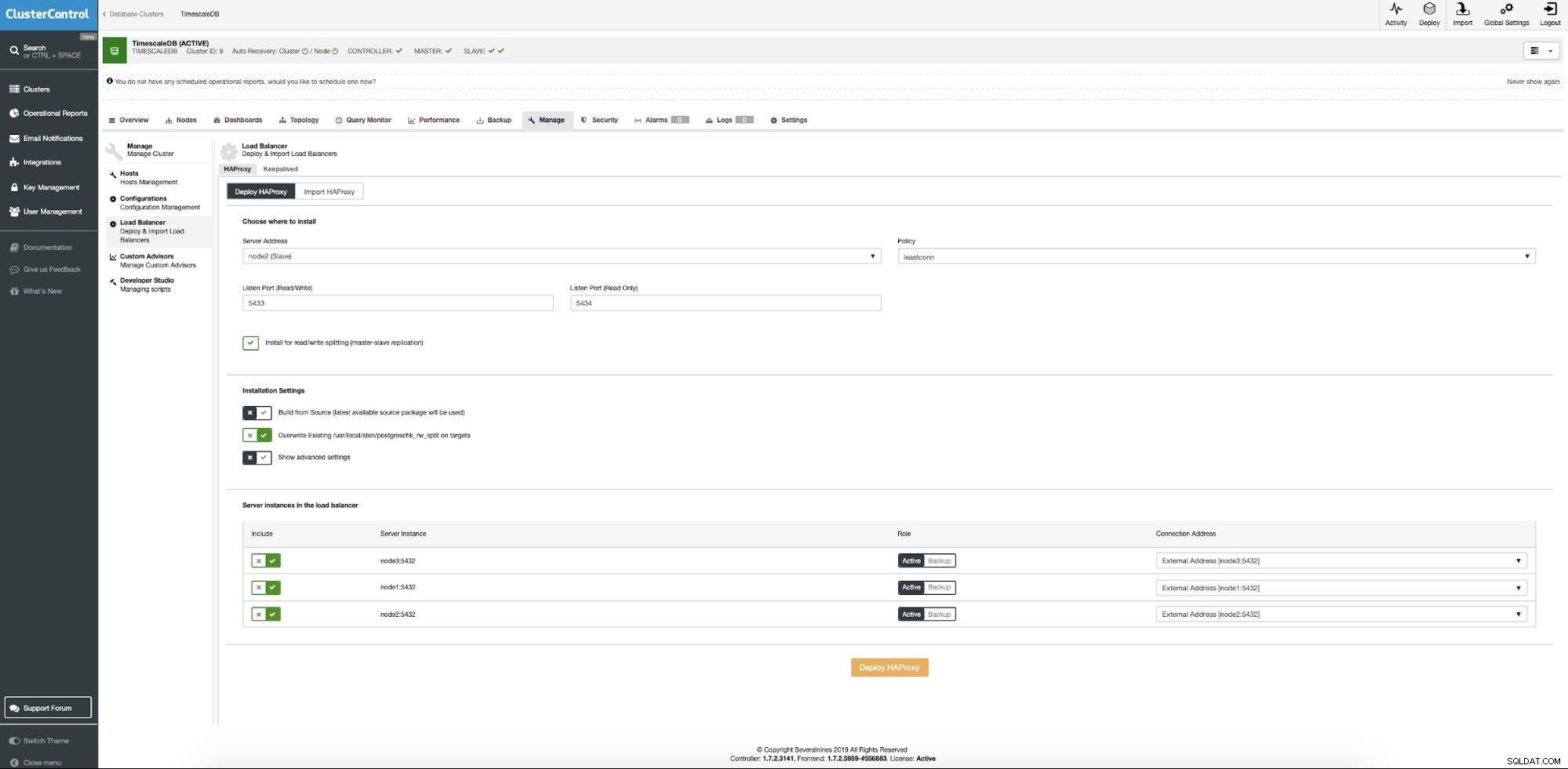
Ketika semua sudah diatur tekan tombol deploy. Setelah beberapa menit, kita harus menyiapkan konfigurasi cluster kita. ClusterControl akan menangani semua prasyarat dan konfigurasi untuk menerapkan penyeimbang beban.
Setelah penyebaran berhasil, kita dapat melihat topologi cluster baru kita; dengan load balancing dan node baca tambahan. Dengan lebih banyak node terpasang, ClusterControl secara otomatis mengaktifkan pemulihan otomatis. Dengan cara ini ketika master node down, operasi failover akan dimulai dengan sendirinya.
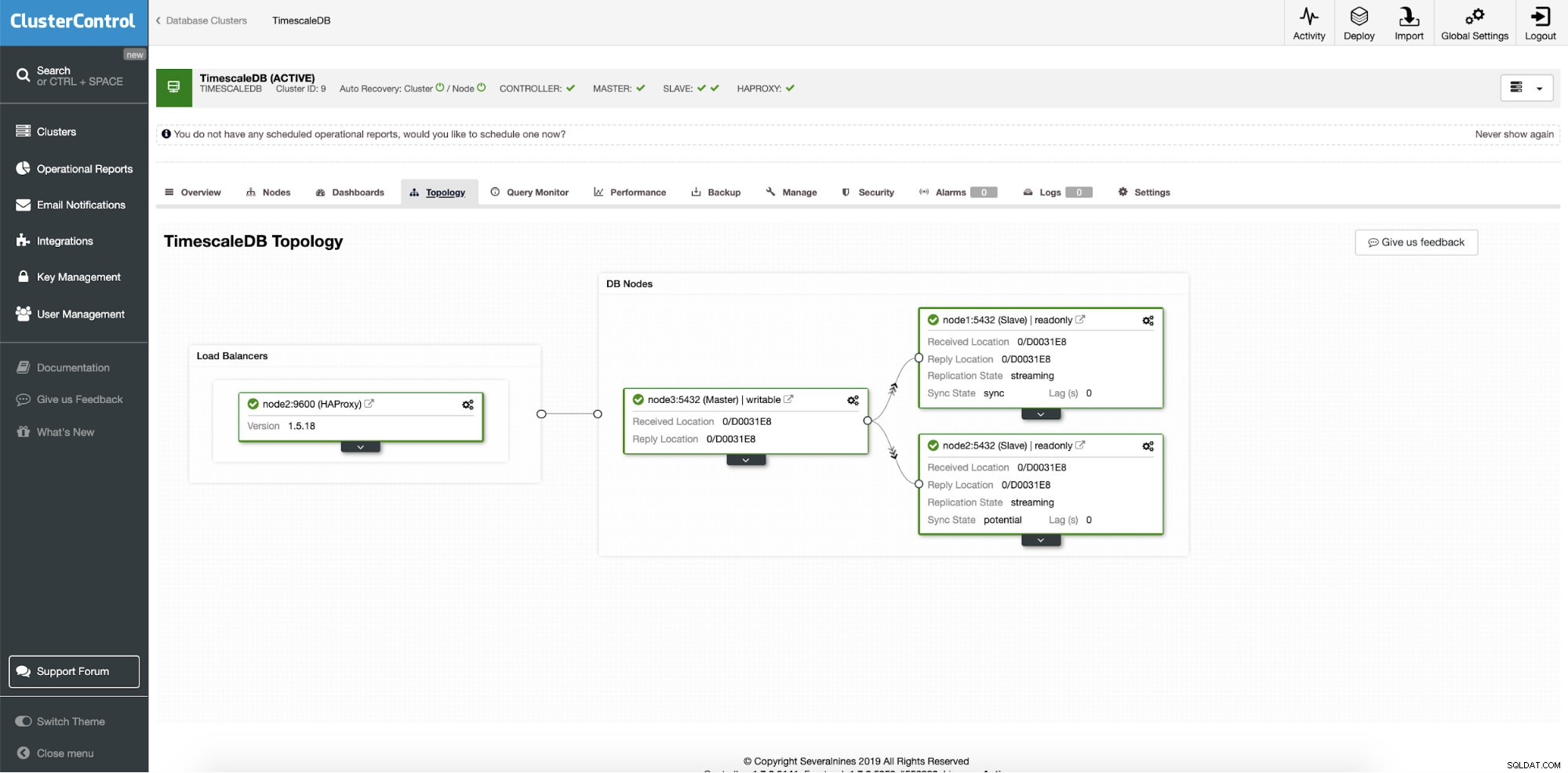 Kontrol Cluster:Topologi akhir
Kontrol Cluster:Topologi akhir Kesimpulan
TimescaleDB adalah database open-source yang diciptakan untuk membuat SQL scalable untuk data time-series. Memiliki cara otomatis untuk memperluas klaster mereka adalah kunci untuk mencapai kinerja dan efisiensi. Seperti yang telah kita lihat di atas, Anda sekarang dapat menskalakan TimescaleDB dengan menggunakan ClusterControl dengan mudah.