Meningkatnya permintaan untuk sistem ketersediaan tinggi dan SLA yang ketat mendorong kami untuk mengganti prosedur manual dengan solusi otomatis. Tetapi apakah Anda memiliki waktu dan sumber daya yang diperlukan untuk mengatasi sendiri kerumitan operasi failover? Apakah Anda akan mengorbankan waktu henti basis data produksi untuk mempelajarinya dengan cara yang sulit?
ClusterControl menyediakan dukungan lanjutan untuk deteksi dan penanganan kegagalan. Ini digunakan oleh banyak organisasi perusahaan, menjaga sistem produksi yang paling penting tetap aktif dan berjalan dalam mode 24/7.
Solusi manajemen basis data ini juga mendukung Anda dengan penyebaran proxy beban yang berbeda. Proxy ini memainkan peran kunci dalam tumpukan HA sehingga tidak perlu menyesuaikan string koneksi aplikasi atau entri DNS untuk mengalihkan koneksi aplikasi ke node master baru.
Ketika kegagalan terdeteksi, ClusterControl melakukan semua pekerjaan latar belakang untuk memilih master baru, menyebarkan server slave fail-over, dan mengonfigurasi penyeimbang beban. Di blog ini, Anda akan mempelajari cara mencapai failover otomatis TimescaleDB di sistem produksi Anda.
Menyebarkan Seluruh Topologi Replikasi
Mulai dari ClusterControl 1.7.2 Anda dapat menerapkan seluruh pengaturan replikasi TimescaleDB dengan cara yang sama seperti Anda menggunakan PostgreSQL:Anda dapat menggunakan menu “Deploy Cluster” untuk menerapkan server siaga utama dan satu atau lebih TimescaleDB. Mari kita lihat seperti apa.
Pertama, Anda perlu menentukan detail akses saat men-deploy cluster baru menggunakan ClusterControl. Ini memerlukan akses kata sandi root atau sudo ke semua node tempat cluster baru Anda akan diterapkan.
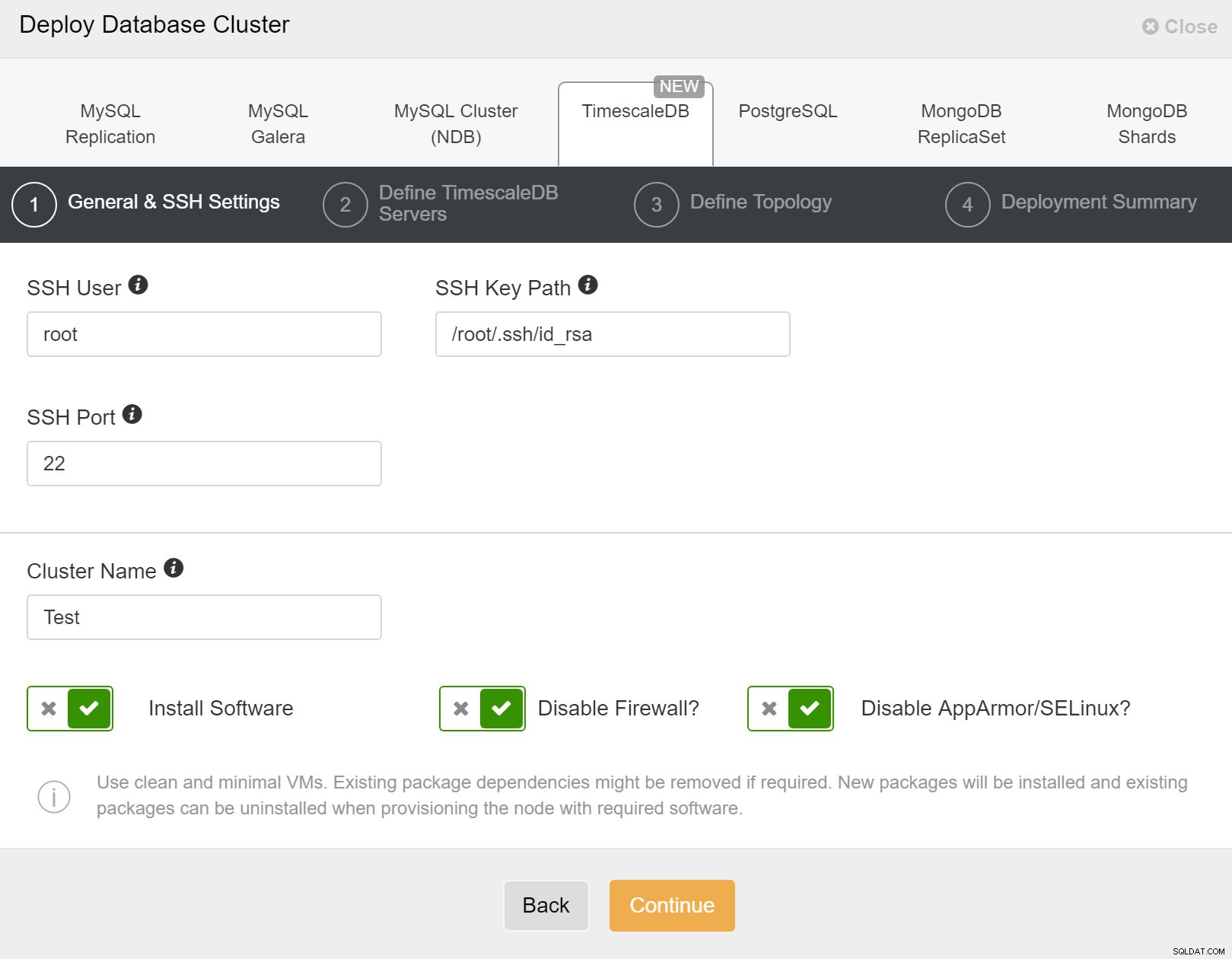 ClusterControl:Menyebarkan cluster baru
ClusterControl:Menyebarkan cluster baru Selanjutnya, kita perlu mendefinisikan pengguna dan kata sandi untuk pengguna TimescaleDB.
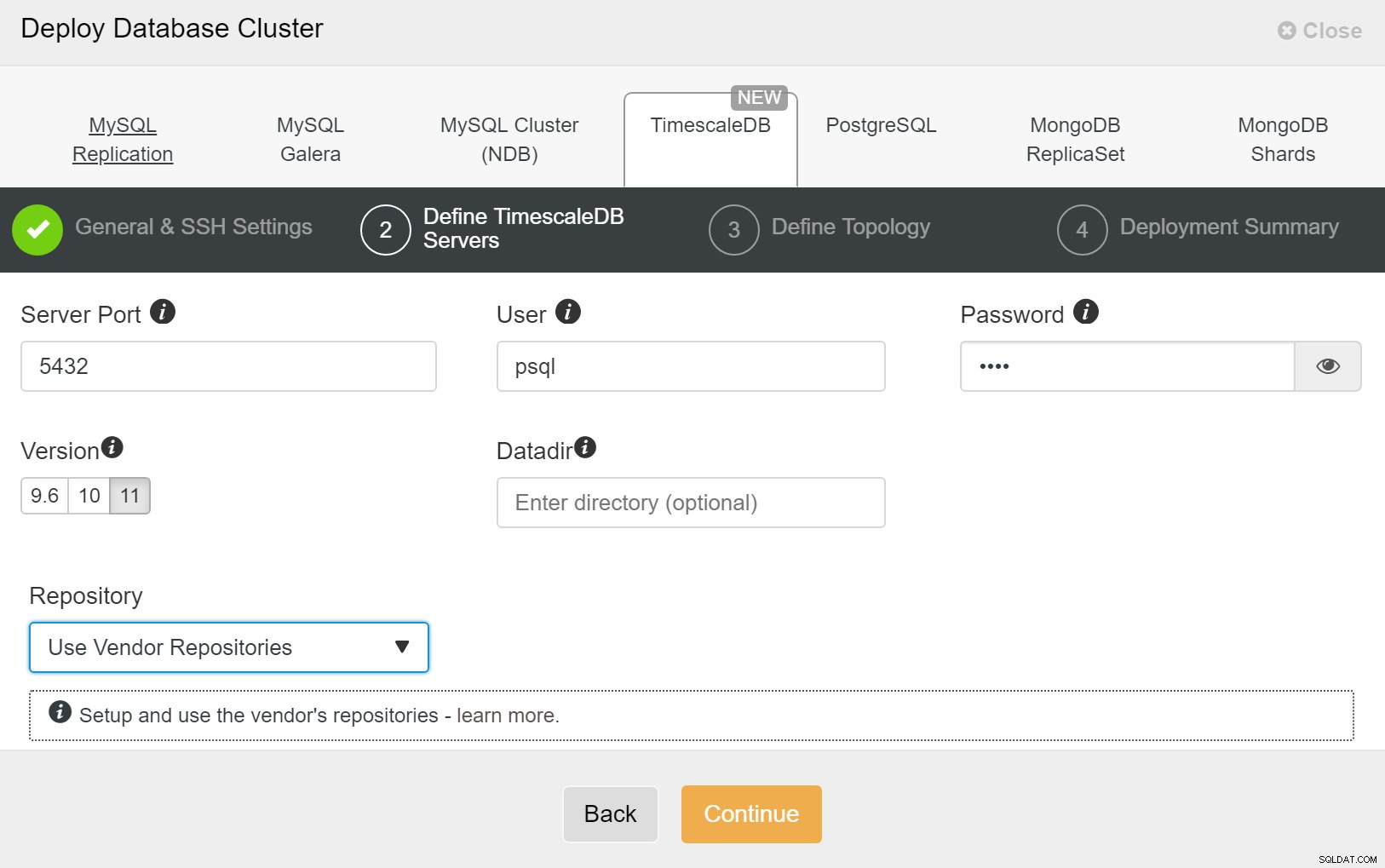 ClusterControl:Menyebarkan cluster database
ClusterControl:Menyebarkan cluster database Terakhir, Anda ingin menentukan topologi - host mana yang harus menjadi host utama dan host mana yang harus dikonfigurasi sebagai standby. Saat Anda menentukan host di topologi, ClusterControl akan memeriksa apakah akses ssh berfungsi seperti yang diharapkan - ini memungkinkan Anda mengetahui masalah konektivitas sejak awal. Pada layar terakhir, Anda akan ditanya tentang jenis replikasi sinkron atau asinkron.
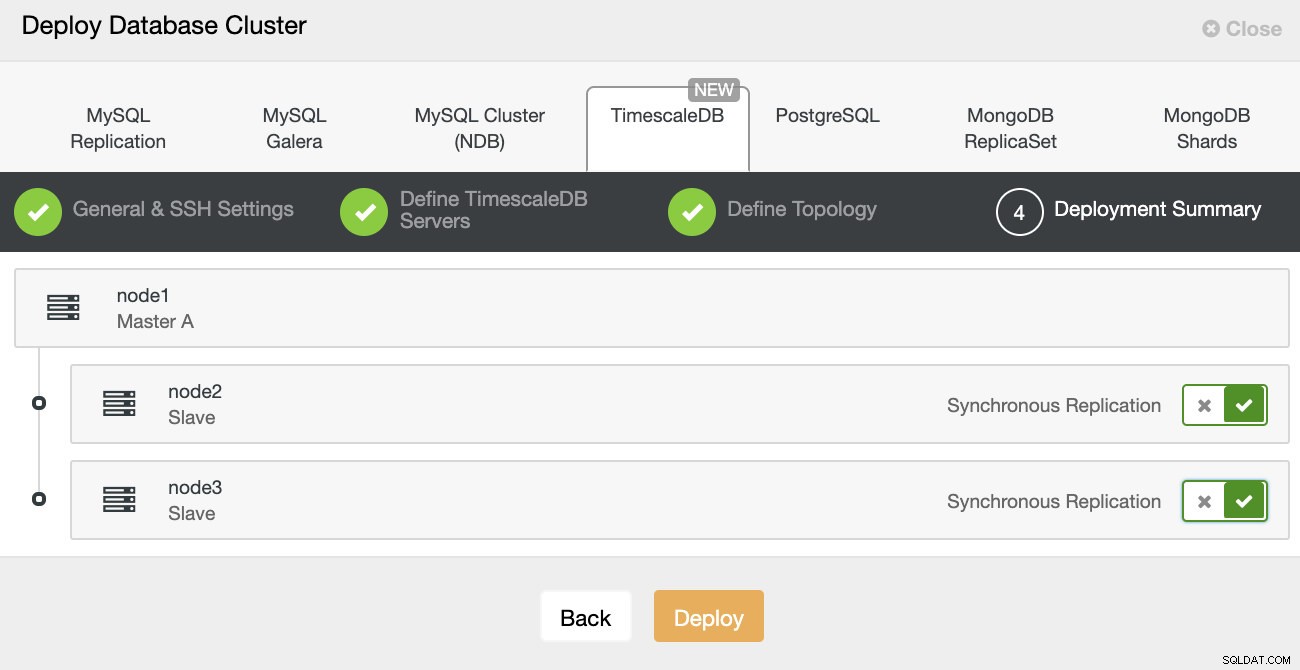 Penyebaran ClusterControl
Penyebaran ClusterControl Itu saja, kemudian masalah memulai penyebaran. Pekerjaan dibuat di ClusterControl, dan Anda akan dapat mengikuti kemajuannya.
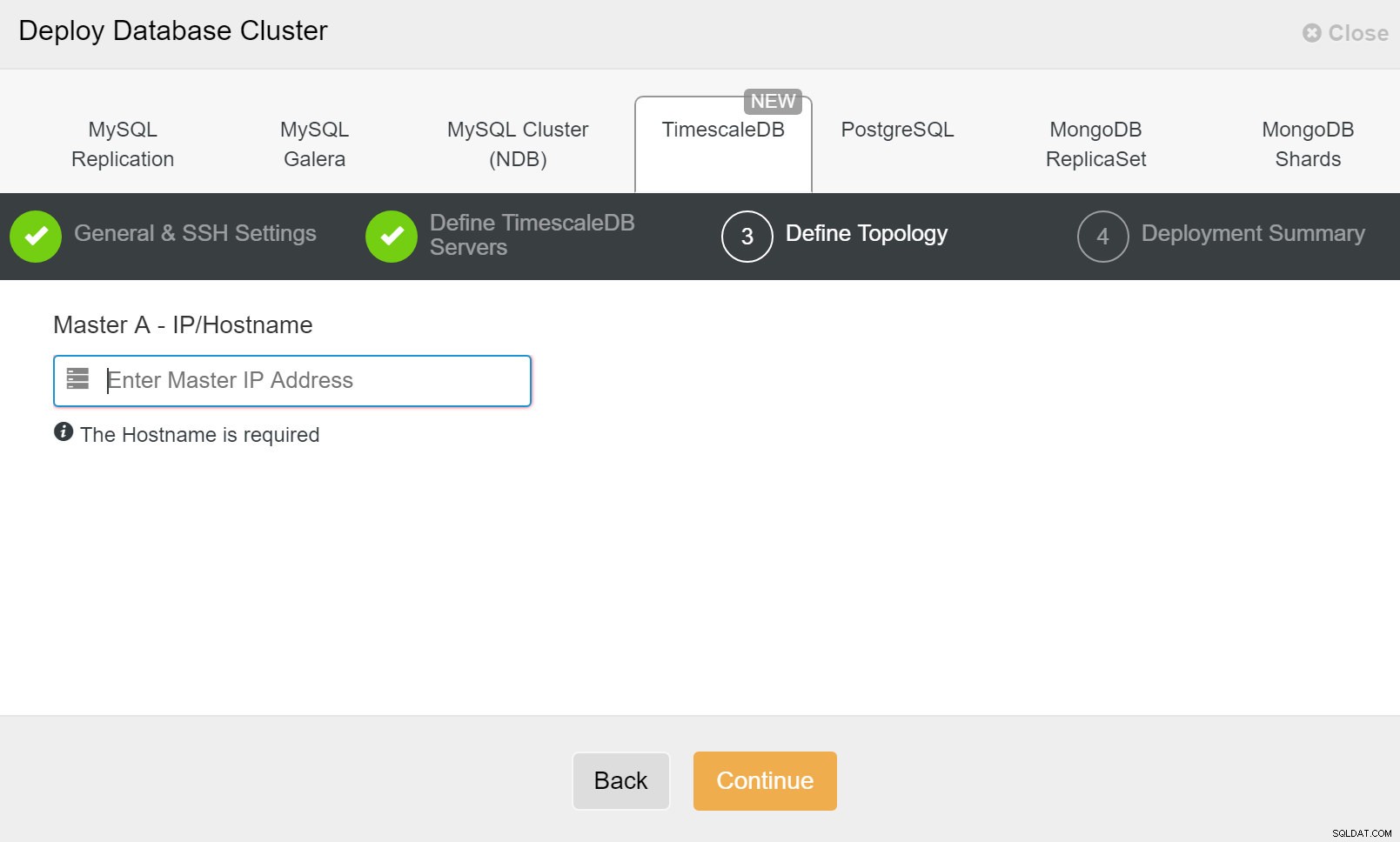 ClusterControl:Tentukan topologi untuk klaster TimescleDb
ClusterControl:Tentukan topologi untuk klaster TimescleDb Setelah Anda selesai, Anda akan melihat pengaturan topologi dengan peran di cluster. Perhatikan bahwa kami juga menambahkan penyeimbang beban (HAProxy) di depan instance database sehingga failover otomatis tidak memerlukan perubahan dalam pengaturan koneksi database.
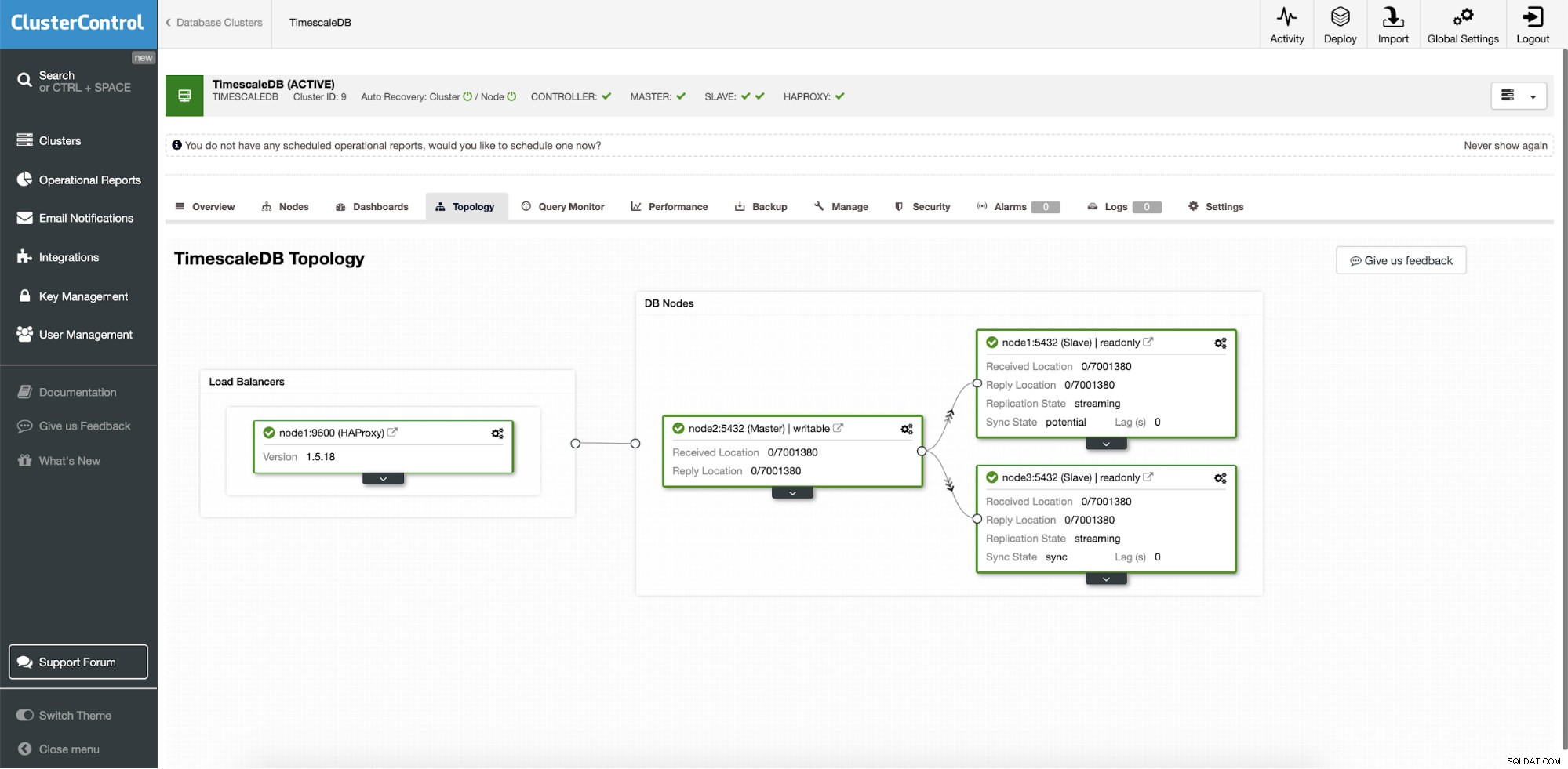 Kontrol Cluster:Topologi
Kontrol Cluster:Topologi Ketika Timescale disebarkan oleh ClusterControl, pemulihan otomatis diaktifkan secara default. Status dapat diperiksa di bilah cluster.
 Kontrol Cluster:Cluster Pemulihan Otomatis dan status Node
Kontrol Cluster:Cluster Pemulihan Otomatis dan status Node Konfigurasi Kegagalan
Setelah pengaturan replikasi disebarkan, ClusterControl dapat memantau pengaturan dan secara otomatis memulihkan server yang gagal. Itu juga dapat mengatur perubahan topologi.
Kegagalan otomatis ClusterControl dirancang dengan prinsip-prinsip berikut:
- Pastikan master benar-benar mati sebelum Anda melakukan failover
- Kegagalan hanya sekali
- Jangan melakukan failover ke budak yang tidak konsisten
- Hanya menulis ke master
- Jangan memulihkan master yang gagal secara otomatis
Dengan algoritme bawaan, failover sering kali dapat dilakukan dengan cukup cepat sehingga Anda dapat memastikan SLA tertinggi untuk lingkungan database Anda.
Prosesnya dapat dikonfigurasi. Muncul dengan beberapa parameter yang dapat Anda gunakan untuk mengadopsi pemulihan ke spesifik lingkungan Anda.
| max_replication_lag | Maksimum jeda replikasi yang diizinkan dalam hitungan detik sebelumnya |
| replication_stop_on_error | Prosedur failover/switchover akan gagal jika ditemukan kesalahan yang dapat menyebabkan hilangnya data. Diaktifkan secara default. 0 berarti nonaktifkan, |
| replication_auto_rebuild_slave | Jika SQL THREAD dihentikan dan kode kesalahan bukan nol, maka slave akan secara otomatis dibangun kembali. 1 berarti aktifkan, 0 berarti nonaktifkan (default). |
| replication_failover_blacklist | Daftar nama host:pasangan port yang dipisahkan koma. Server yang masuk daftar hitam tidak akan dianggap sebagai kandidat selama failover. replikasi_failover_blacklist diabaikan jika replica_failover_whitelist disetel. |
| replication_failover_whitelist | Daftar nama host:pasangan port yang dipisahkan koma. Hanya server yang masuk daftar putih yang akan dianggap sebagai kandidat selama failover. Jika tidak ada server dalam daftar putih yang tersedia (naik/terhubung), failover akan gagal. replikasi_failover_blacklist diabaikan jika replica_failover_whitelist disetel. |
Penanganan Kegagalan
Ketika kegagalan master terdeteksi, daftar calon master dibuat dan salah satunya dipilih untuk menjadi master baru. Dimungkinkan untuk memiliki daftar putih server untuk dipromosikan ke primer, serta daftar hitam server yang tidak dapat dipromosikan ke primer. Budak yang tersisa sekarang diambil dari primer baru, dan primer lama tidak dimulai ulang.
Di bawah ini kita dapat melihat simulasi kegagalan node.
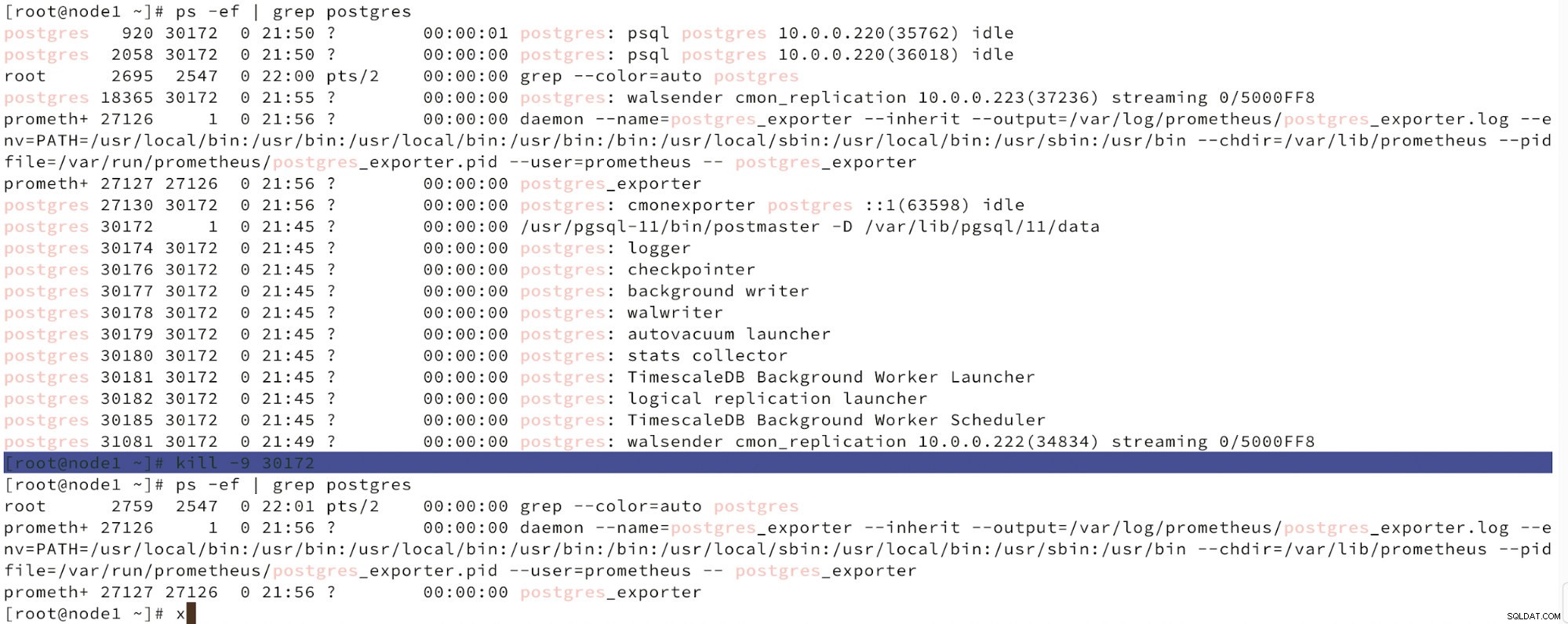 Simulasikan kegagalan master node dengan kill
Simulasikan kegagalan master node dengan kill Ketika kerusakan node terdeteksi dan pemulihan otomatis terdeteksi, ClusterControl memicu pekerjaan untuk melakukan failover. Di bawah ini kita dapat melihat tindakan yang diambil untuk memulihkan cluster.
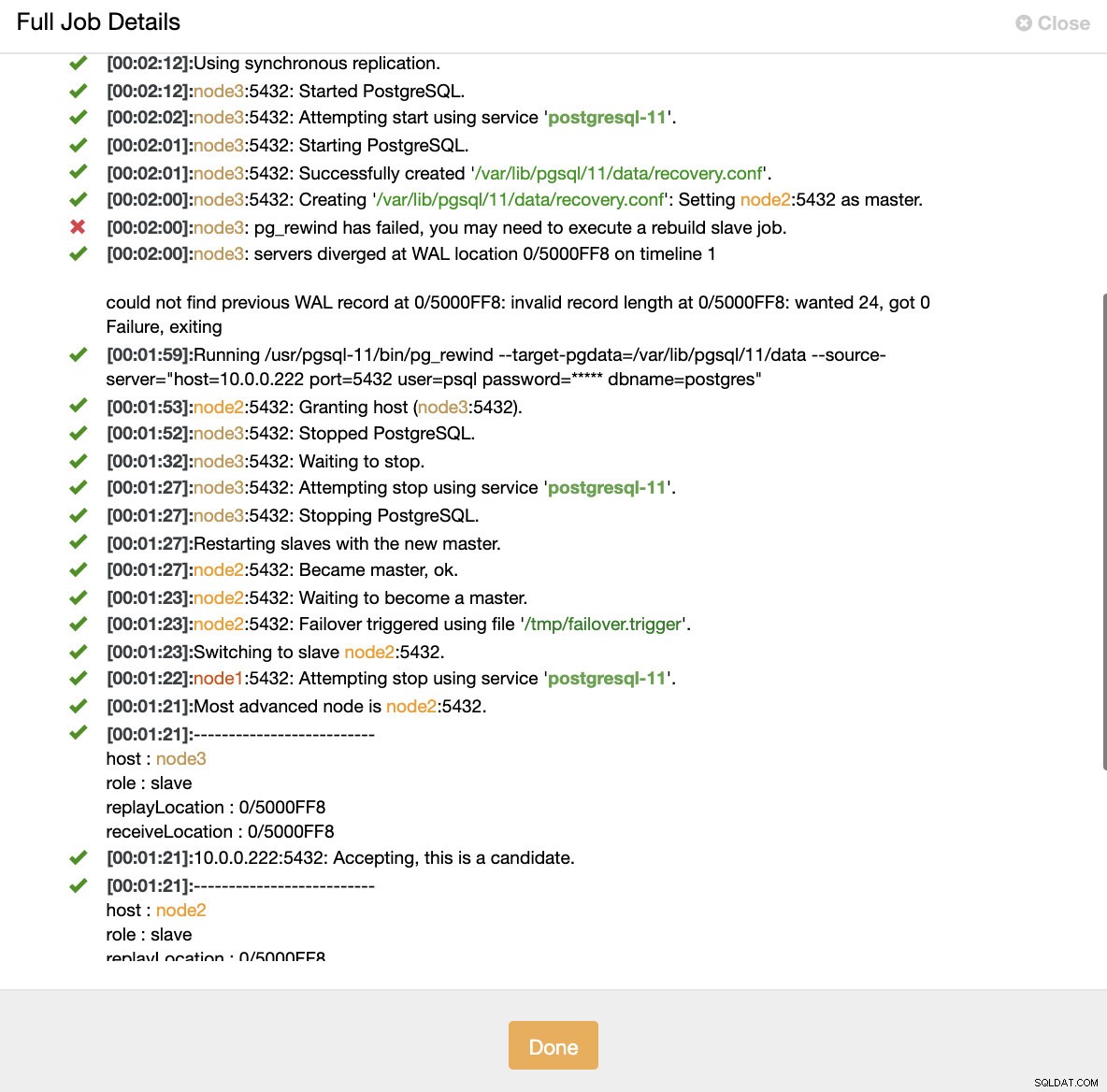 ClusterControl:Pekerjaan dipicu untuk membangun kembali cluster
ClusterControl:Pekerjaan dipicu untuk membangun kembali cluster ClusterControl sengaja membuat primer lama tetap offline karena mungkin saja beberapa data belum ditransfer ke server siaga. Dalam kasus seperti itu, yang utama adalah satu-satunya host yang berisi data ini dan Anda mungkin ingin memulihkan data yang hilang secara manual. Bagi mereka yang ingin agar primer yang gagal dibangun kembali secara otomatis, ada opsi di file konfigurasi cmon:replica_auto_rebuild_slave. Secara default, ini dinonaktifkan tetapi ketika pengguna mengaktifkannya, primer yang gagal akan dibangun kembali sebagai budak dari primer baru. Tentu saja, jika ada kekurangan data yang hanya ada pada primer yang gagal, data tersebut akan hilang.
Membangun Kembali Server Siaga
Fitur yang berbeda adalah pekerjaan "Rebuild Replication Slave" yang tersedia untuk semua slave (atau server siaga) dalam pengaturan replikasi. Ini akan digunakan misalnya ketika Anda ingin menghapus data pada standby dan membangunnya kembali dengan salinan data primer yang baru. Ini dapat bermanfaat jika server siaga tidak dapat terhubung dan mereplikasi dari server utama karena alasan tertentu.
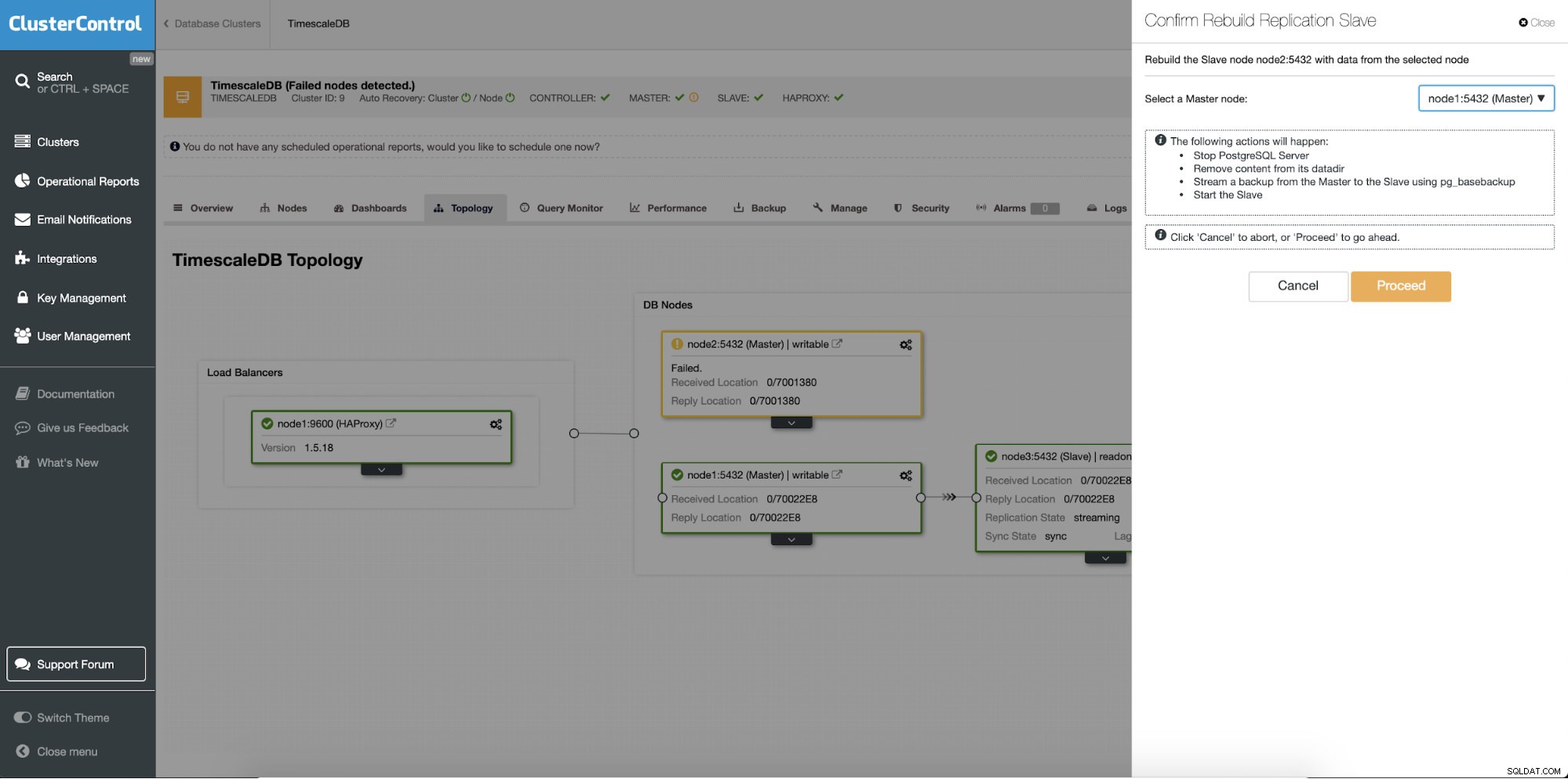 ClusterControl:Membangun kembali budak replikasi
ClusterControl:Membangun kembali budak replikasi 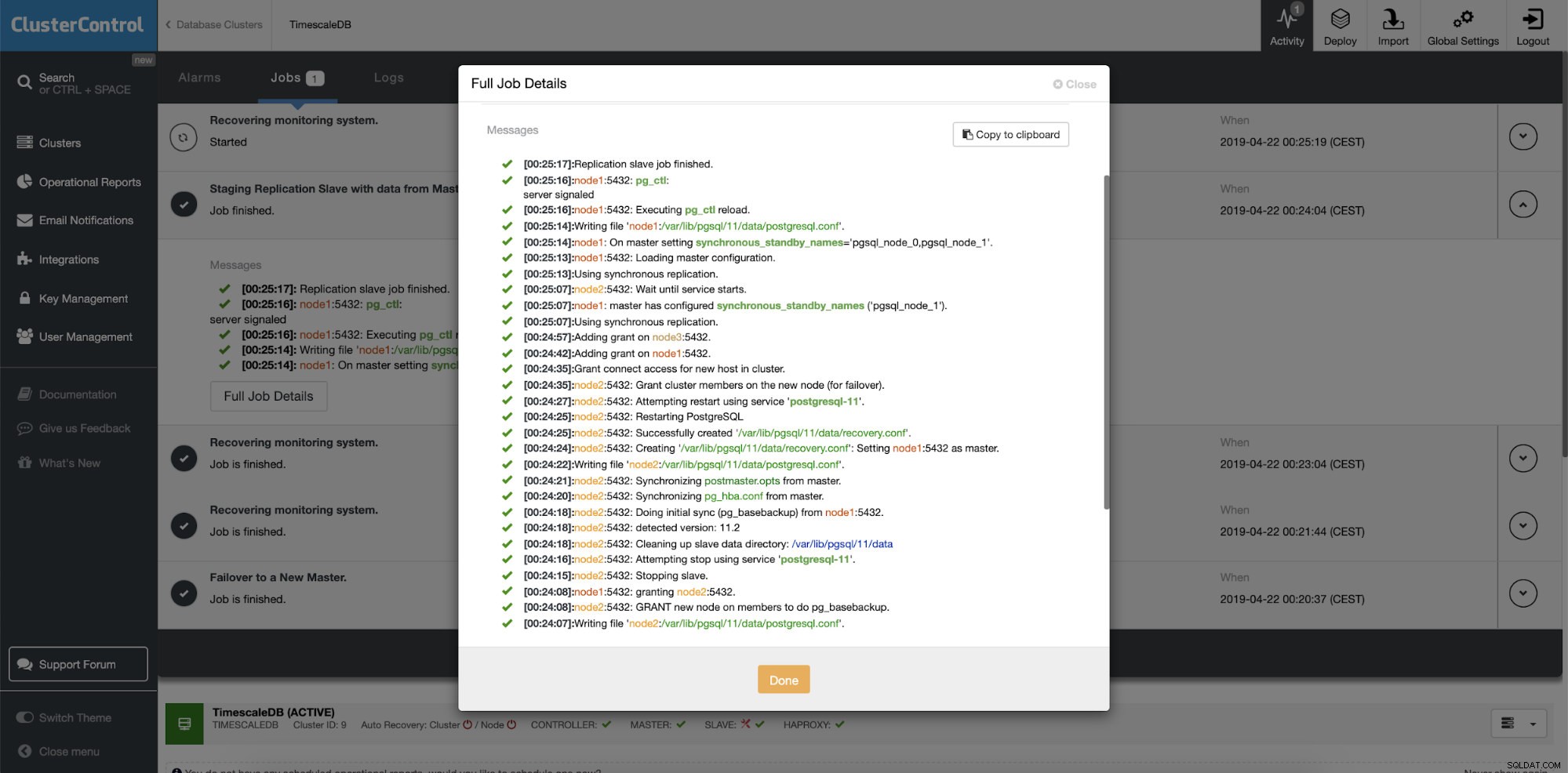 Kontrol Cluster:Membangun kembali budak
Kontrol Cluster:Membangun kembali budak