Posting ini memiliki “string terlampir:untuk alasan yang bagus. Kita akan menjelajahi jauh ke dalam SQL VARCHAR, tipe data yang berhubungan dengan string.
Juga, ini "hanya untuk mata Anda" karena tanpa string, tidak akan ada posting blog, halaman web, instruksi permainan, resep yang di-bookmark, dan banyak lagi untuk dibaca dan dinikmati oleh mata kita. Kami berurusan dengan trilyun string setiap hari. Jadi, sebagai pengembang, Anda dan saya bertanggung jawab untuk membuat data semacam ini efisien untuk disimpan dan diakses.
Dengan pemikiran ini, kami akan membahas apa yang paling penting untuk penyimpanan dan kinerja. Masukkan yang harus dan yang tidak boleh dilakukan untuk tipe data ini.
Tapi sebelum itu, VARCHAR hanyalah salah satu tipe string dalam SQL. Apa yang membuatnya berbeda?
Apa itu VARCHAR dalam SQL? (Dengan Contoh)
VARCHAR adalah tipe data string atau karakter dengan ukuran yang bervariasi. Anda dapat menyimpan huruf, angka, dan simbol dengannya. Dimulai dengan SQL Server 2019, Anda dapat menggunakan berbagai karakter Unicode saat menggunakan susunan dengan dukungan UTF-8.
Anda dapat mendeklarasikan kolom atau variabel VARCHAR menggunakan VARCHAR[(n)], di mana n singkatan dari ukuran string dalam byte. Rentang nilai untuk n adalah 1 hingga 8000. Itu banyak data karakter. Tetapi terlebih lagi, Anda dapat mendeklarasikannya menggunakan VARCHAR(MAX) jika Anda membutuhkan string raksasa hingga 2GB. Itu cukup besar untuk daftar rahasia dan hal-hal pribadi Anda di buku harian Anda! Namun, perhatikan bahwa Anda juga dapat mendeklarasikannya tanpa ukuran dan defaultnya adalah 1 jika Anda melakukannya.
Mari kita beri contoh.
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
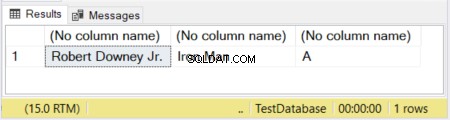
Pada Gambar 1, 2 kolom pertama telah ditentukan ukurannya. Kolom ketiga dibiarkan tanpa ukuran. Jadi, kata “Avengers” terpotong karena VARCHAR tanpa ukuran dinyatakan default ke 1 karakter.
Sekarang, mari kita coba sesuatu yang besar. Namun perhatikan bahwa kueri ini akan memakan waktu cukup lama untuk dijalankan – 23 detik di laptop saya.
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
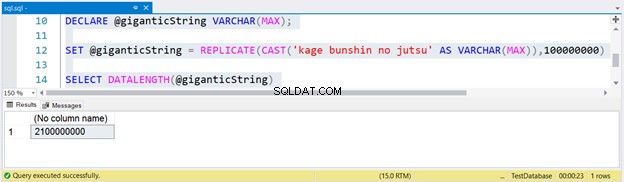
Untuk menghasilkan string besar, kami mereplikasi kage bunshin no jutsu 100 juta kali. Perhatikan CAST dalam REPLICATE. Jika Anda tidak CAST ekspresi string ke VARCHAR(MAX), hasilnya akan terpotong hingga 8000 karakter saja.
Tapi bagaimana SQL VARCHAR dibandingkan dengan tipe data string lainnya?
Perbedaan antara CHAR dan VARCHAR dalam SQL
Dibandingkan dengan VARCHAR, CHAR adalah tipe data karakter dengan panjang tetap. Tidak peduli seberapa kecil atau besar nilai yang Anda masukkan ke variabel CHAR, ukuran akhirnya adalah ukuran variabel. Periksa perbandingan di bawah ini.
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
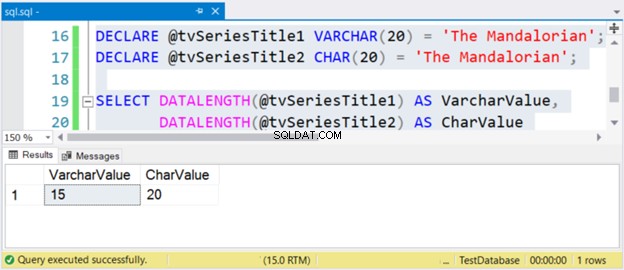
Ukuran string “The Mandalorian” adalah 15 karakter. Jadi, VarcharValue kolom dengan benar mencerminkannya. Namun, CharValue mempertahankan ukuran 20 – diisi dengan 5 spasi di sebelah kanan.
SQL VARCHAR vs NVARCHAR
Dua hal dasar muncul dalam pikiran ketika membandingkan tipe data ini.
Pertama, ini adalah ukuran dalam byte. Setiap karakter di NVARCHAR memiliki dua kali ukuran VARCHAR. NVARCHAR(n) hanya dari 1 hingga 4000.
Kemudian, karakter yang dapat disimpannya. NVARCHAR dapat menyimpan karakter multibahasa seperti Korea, Jepang, Arab, dll. Jika Anda berencana untuk menyimpan lirik K-Pop Korea di database Anda, tipe data ini adalah salah satu pilihan Anda.
Mari kita ambil contoh. Kami akan menggunakan grup K-pop atau Seventeen dalam bahasa Inggris.
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
Kode di atas akan menampilkan nilai string, ukurannya dalam byte, dan jumlah karakter. Jika ini adalah karakter non-Unicode, jumlah karakter sama dengan ukuran dalam byte. Tapi ini tidak terjadi. Lihat Gambar 4 di bawah ini.
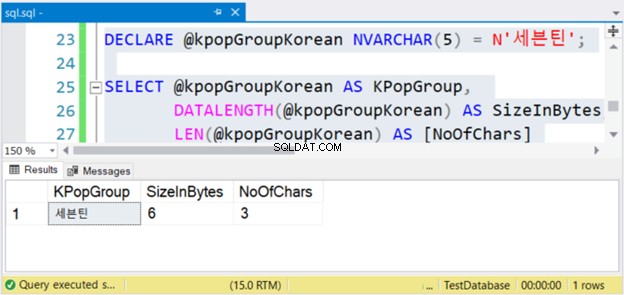
Lihat? Jika NVARCHAR memiliki 3 karakter, ukuran dalam byte adalah dua kali. Tapi tidak dengan VARCHAR. Hal yang sama juga berlaku jika Anda menggunakan karakter bahasa Inggris.
Tapi bagaimana dengan NCHAR? NCHAR adalah padanan dari CHAR untuk karakter Unicode.
SQL Server VARCHAR dengan Dukungan UTF-8
VARCHAR dengan dukungan UTF-8 dimungkinkan pada tingkat server, tingkat basis data, atau tingkat kolom tabel dengan mengubah informasi susunan. Susunan yang digunakan harus mendukung UTF-8.
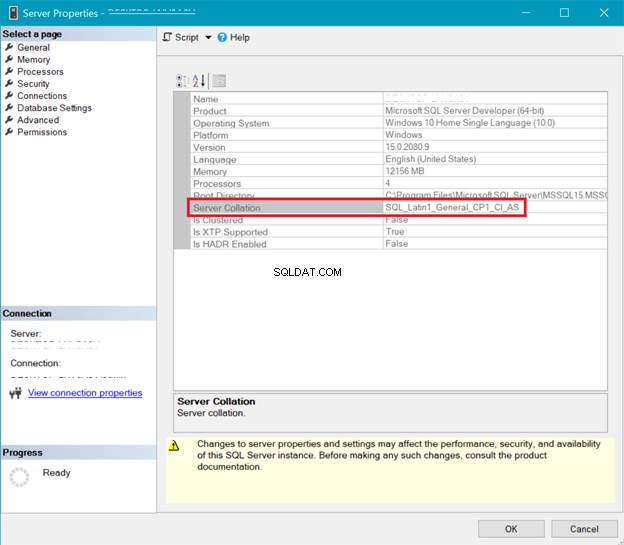
SQL SERVER COLLATION
Gambar 5 menampilkan jendela di SQL Server Management Studio yang menunjukkan susunan server.
PENGUMPULAN DATABASE
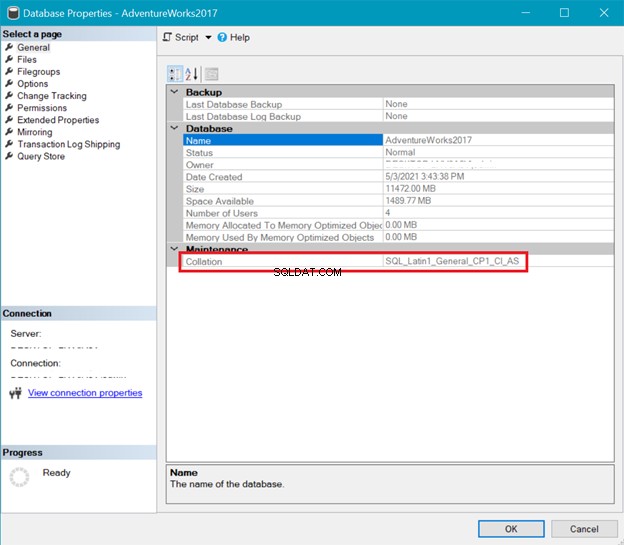
Sementara itu, Gambar 6 menunjukkan susunan AdventureWorks basis data.
PENGUMPULAN KOLOM TABEL
Pemeriksaan server dan database di atas menunjukkan bahwa UTF-8 tidak didukung. String susunan harus memiliki _UTF8 di dalamnya untuk dukungan UTF-8. Tetapi Anda masih dapat menggunakan dukungan UTF-8 di tingkat kolom tabel. Lihat contohnya.
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
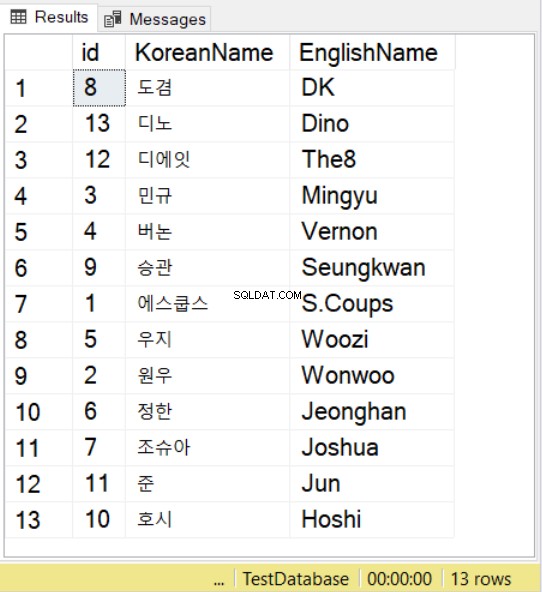
Kode di atas memiliki Latin1_General_100_BIN2_UTF8 susunan untuk KoreanName kolom. Meskipun VARCHAR dan bukan NVARCHAR, kolom ini akan menerima karakter bahasa Korea. Mari kita masukkan beberapa catatan dan kemudian melihatnya.
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
Kami menggunakan nama dari grup K-pop Seventeen menggunakan rekan Korea dan Inggris. Untuk karakter Korea, perhatikan bahwa Anda masih harus mengawali nilainya dengan N , seperti yang Anda lakukan dengan nilai NVARCHAR.
Kemudian, saat menggunakan SELECT dengan ORDER BY, Anda juga dapat menggunakan collation. Anda dapat mengamati ini pada contoh di atas. Ini akan mengikuti aturan penyortiran untuk susunan yang ditentukan.
STORAGE OF VARCHAR DENGAN DUKUNGAN UTF-8
Tapi bagaimana penyimpanan karakter-karakter ini? Jika Anda mengharapkan 2 byte per karakter maka Anda akan terkejut. Lihat Gambar 8.
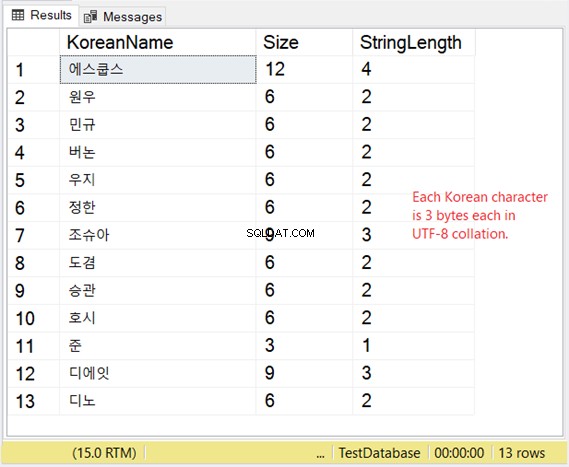
Jadi, jika penyimpanan sangat penting bagi Anda, pertimbangkan tabel di bawah ini saat menggunakan VARCHAR dengan dukungan UTF-8.
| Karakter | Ukuran dalam Byte |
| Ascii 0 – 127 | 1 |
| Skrip berbasis Latin, dan Yunani, Sirilik, Koptik, Armenia, Ibrani, Arab, Suryani, Tāna, dan N’Ko | 2 |
| Ayat Asia Timur seperti Cina, Korea, dan Jepang | 3 |
| Karakter dalam rentang 010000–10FFFF | 4 |
Contoh Korea kami adalah skrip Asia Timur, jadi 3 byte per karakter.
Sekarang setelah kita selesai mendeskripsikan dan membandingkan VARCHAR dengan tipe string lainnya, sekarang mari kita bahas Do's and Don'ts
Hal yang harus dilakukan dalam Menggunakan VARCHAR di SQL Server
1. Tentukan Ukuran
Apa yang bisa salah tanpa menentukan ukurannya?
POTONGAN STRING
Jika Anda malas menentukan ukuran, pemotongan string akan terjadi. Anda sudah melihat contohnya sebelumnya.
DAMPAK PENYIMPANAN DAN KINERJA
Pertimbangan lain adalah penyimpanan dan kinerja. Anda hanya perlu mengatur ukuran yang tepat untuk data Anda, tidak lebih. Tapi bagaimana Anda bisa tahu? Untuk menghindari pemotongan di masa mendatang, Anda mungkin hanya mengaturnya ke ukuran terbesar. Itu VARCHAR(8000) atau bahkan VARCHAR(MAX). Dan 2 byte akan disimpan apa adanya. Hal yang sama dengan 2GB. Apakah itu penting?
Menjawab itu akan membawa kita ke konsep bagaimana SQL Server menyimpan data. Saya memiliki artikel lain yang menjelaskan hal ini secara rinci dengan contoh dan ilustrasi.
Singkatnya, data disimpan dalam halaman 8KB. Saat baris data melebihi ukuran ini, SQL Server memindahkannya ke unit alokasi halaman lain yang disebut ROW_OVERFLOW_DATA.
Misalkan Anda memiliki data VARCHAR 2-byte yang mungkin sesuai dengan unit alokasi halaman asli. Saat Anda menyimpan string yang lebih besar dari 8000 byte, data akan dipindahkan ke halaman pelimpahan baris. Kemudian mengecilkannya lagi ke ukuran yang lebih rendah, dan itu akan dipindahkan kembali ke halaman aslinya. Gerakan bolak-balik menyebabkan banyak I/O dan kemacetan kinerja. Mengambil ini dari 2 halaman alih-alih 1 membutuhkan I/O tambahan juga.
Alasan lain adalah pengindeksan. VARCHAR(MAX) adalah NO besar sebagai kunci indeks. Sementara itu, VARCHAR(8000) akan melebihi ukuran kunci indeks maksimum. Itu adalah 1700 byte untuk indeks yang tidak berkerumun dan 900 byte untuk indeks yang berkerumun.
DAMPAK KONVERSI DATA
Namun ada pertimbangan lain:konversi data. Cobalah dengan CAST tanpa ukuran seperti kode di bawah ini.
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
Kode ini akan melakukan konversi tanggal/waktu dengan informasi zona waktu ke VARCHAR.
Jadi, jika kita malas menentukan ukuran saat CAST atau CONVERT, hasilnya dibatasi hanya 30 karakter.
Bagaimana dengan mengonversi NVARCHAR ke VARCHAR dengan dukungan UTF-8? Ada penjelasan rinci tentang ini nanti, jadi teruskan membaca.
2. Gunakan VARCHAR Jika Ukuran String Sangat Bervariasi
Nama dari AdventureWorks basis data bervariasi dalam ukuran. Salah satu nama terpendek adalah Min Su, sedangkan nama terpanjang adalah Osarumwense Uwaifiokun Agbonile. Itu antara 6 dan 31 karakter termasuk spasi. Mari impor nama-nama ini ke dalam 2 tabel dan bandingkan antara VARCHAR dan CHAR.
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
Manakah dari 2 yang lebih baik? Mari kita periksa pembacaan logis dengan menggunakan kode di bawah ini dan memeriksa output STATISTICS IO.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
Pembacaan logis:
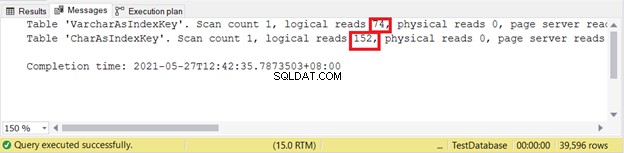
Semakin tidak logis membaca semakin baik. Di sini, kolom CHAR menggunakan lebih dari dua kali lipat pasangan VARCHAR. Jadi, VARCHAR menang dalam contoh ini.
3. Gunakan VARCHAR sebagai Kunci Indeks Alih-alih CHAR Saat Nilai Bervariasi dalam Ukuran
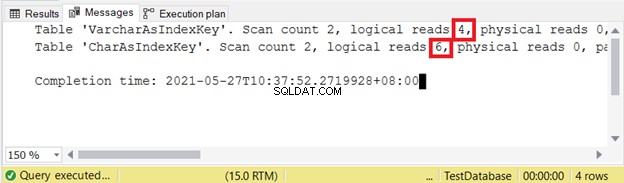
Apa yang terjadi ketika digunakan sebagai kunci indeks? Akankah tarif CHAR lebih baik daripada VARCHAR? Mari gunakan data yang sama dari bagian sebelumnya dan jawab pertanyaan ini.
Kami akan menanyakan beberapa data dan memeriksa pembacaan logis. Dalam contoh ini, filter menggunakan kunci indeks.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
Pembacaan logis:
Oleh karena itu, kunci indeks VARCHAR lebih baik daripada kunci indeks CHAR ketika kunci memiliki ukuran yang bervariasi. Tapi bagaimana dengan INSERT dan UPDATE yang akan mengubah entri indeks?
KETIKA MENGGUNAKAN MASUKKAN DAN PERBARUI
Mari kita uji 2 kasus dan kemudian periksa pembacaan logis seperti yang biasa kita lakukan.
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
Pembacaan logis:
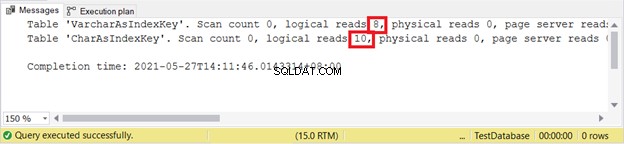
VARCHAR masih lebih baik saat memasukkan catatan. Bagaimana dengan PEMBARUAN?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
Pembacaan logis:
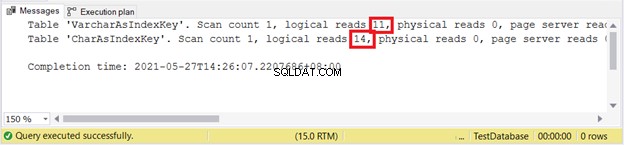
Sepertinya VARCHAR menang lagi.
Akhirnya, itu memenangkan pengujian kami, meskipun mungkin kecil. Apakah Anda memiliki kasus uji yang lebih besar yang membuktikan sebaliknya?
4. Pertimbangkan VARCHAR dengan Dukungan UTF-8 untuk Data Multibahasa (SQL Server 2019+)
Jika ada campuran karakter Unicode dan non-Unicode di tabel Anda, Anda dapat mempertimbangkan VARCHAR dengan dukungan UTF-8 melalui NVARCHAR. Jika sebagian besar karakter berada dalam kisaran ASCII 0 hingga 127, ini dapat menawarkan penghematan ruang dibandingkan dengan NVARCHAR.
Untuk melihat apa yang saya maksud, mari kita bandingkan.
NVARCHAR KE VARCHAR DENGAN DUKUNGAN UTF-8
Apakah Anda sudah memigrasikan database Anda ke SQL Server 2019? Apakah Anda berencana untuk memigrasikan data string Anda ke susunan UTF-8? Kami akan memberikan contoh nilai campuran karakter Jepang dan non-Jepang untuk memberi Anda gambaran.
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
Sekarang setelah data disetel, kami akan memeriksa ukuran dalam byte dari 2 nilai:

Kejutan! Dengan NVARCHAR, ukurannya adalah 30 byte. Itu 15 kali lebih banyak dari 2 karakter. Tetapi ketika dikonversi ke VARCHAR dengan dukungan UTF-8, ukurannya hanya 27 byte. Mengapa 27? Periksa bagaimana ini dihitung.

Jadi, 9 karakter masing-masing 1 byte. Itu menarik karena, dengan NVARCHAR, huruf bahasa Inggris juga 2 byte. Karakter Jepang lainnya masing-masing 3 byte.
Jika ini semua karakter Jepang, string 15 karakter akan menjadi 45 byte dan juga menggunakan ukuran maksimum VarcharUTF8 kolom. Perhatikan bahwa ukuran NVarcharValue kolom kurang dari VarcharUTF8 .
Ukurannya tidak boleh sama saat mengonversi dari NVARCHAR, atau datanya mungkin tidak muat. Anda dapat merujuk ke Tabel 1 sebelumnya.
Pertimbangkan dampak pada ukuran saat mengonversi NVARCHAR ke VARCHAR dengan dukungan UTF-8.
Larangan dalam Menggunakan VARCHAR di SQL Server
1. Ketika Ukuran String Tetap dan Tidak Dapat Dibatalkan, Gunakan CHAR Sebagai gantinya.
Aturan umum saat string berukuran tetap diperlukan adalah menggunakan CHAR. Saya mengikuti ini ketika saya memiliki persyaratan data yang membutuhkan ruang dengan bantalan kanan. Jika tidak, saya akan menggunakan VARCHAR. Saya memiliki beberapa kasus penggunaan ketika saya perlu membuang string dengan panjang tetap tanpa pembatas ke dalam file teks untuk klien.
Selanjutnya, saya menggunakan kolom CHAR hanya jika kolom tidak dapat dibatalkan. Mengapa? Karena ukuran kolom CHAR dalam byte saat NULL sama dengan ukuran kolom yang ditentukan. Namun VARCHAR ketika NULL memiliki ukuran 1 tidak peduli berapa banyak ukuran yang ditentukan. Jalankan kode di bawah ini dan lihat sendiri.
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2. Jangan Gunakan VARCHAR(n) Jika n Akan Melebihi 8000 Bytes. Gunakan VARCHAR(MAX) Sebagai gantinya.
Apakah Anda memiliki string yang akan melebihi 8000 byte? Ini adalah waktu untuk menggunakan VARCHAR(MAX). Tetapi untuk bentuk data yang paling umum seperti nama dan alamat, VARCHAR(MAX) berlebihan dan akan memengaruhi kinerja. Dalam pengalaman pribadi saya, saya tidak ingat persyaratan bahwa saya menggunakan VARCHAR(MAX).
3. Saat Menggunakan Karakter Multibahasa dengan SQL Server 2017 dan Di Bawah. Gunakan NVARCHAR Sebagai gantinya.
Ini adalah pilihan yang jelas jika Anda masih menggunakan SQL Server 2017 dan di bawahnya.
Intinya
Tipe data VARCHAR telah membantu kami dengan baik untuk banyak aspek. Itu untuk saya sejak SQL Server 7. Namun terkadang, kami masih membuat pilihan yang buruk. Dalam posting ini, SQL VARCHAR didefinisikan dan dibandingkan dengan tipe data string lainnya dengan contoh. Dan sekali lagi, inilah yang harus dan tidak boleh dilakukan untuk database yang lebih cepat:
Lakukan:
- Tentukan ukurannya n di VARCHAR[(n)] meskipun itu opsional.
- Gunakan saat ukuran string sangat bervariasi.
- Pertimbangkan kolom VARCHAR sebagai kunci indeks, bukan CHAR.
- Dan jika Anda sekarang menggunakan SQL Server 2019, pertimbangkan VARCHAR untuk string multibahasa dengan dukungan UTF-8.
Larangan:
- Jangan gunakan VARCHAR saat ukuran string tetap dan tidak dapat dibatalkan.
- Jangan gunakan VARCHAR(n) saat ukuran string melebihi 8000 byte.
- Dan jangan gunakan VARCHAR untuk data multibahasa saat menggunakan SQL Server 2017 dan sebelumnya.
Apakah Anda memiliki sesuatu yang lain untuk ditambahkan? Beri tahu kami di bagian Komentar. Jika menurut Anda ini akan membantu teman pengembang Anda, silakan bagikan ini di platform media sosial favorit Anda.