Penanganan NULL adalah salah satu aspek yang lebih rumit dari pemodelan data dan manipulasi data dengan SQL. Mari kita mulai dengan fakta bahwa upaya untuk menjelaskan dengan tepat apa itu NULL tidak sepele dalam dan dari dirinya sendiri. Bahkan di antara orang-orang yang memiliki pemahaman yang baik tentang teori relasional dan SQL, Anda akan mendengar pendapat yang sangat kuat baik yang mendukung maupun menentang penggunaan NULL dalam database Anda. Suka atau tidak, sebagai praktisi database Anda sering harus berurusan dengan mereka, dan mengingat bahwa NULL memang menambah kerumitan penulisan kode SQL Anda, ada baiknya untuk menjadikannya prioritas untuk dipahami dengan baik. Dengan cara ini Anda dapat menghindari bug dan jebakan yang tidak perlu.
Artikel ini adalah yang pertama dalam seri tentang kompleksitas NULL. Saya mulai dengan liputan tentang apa itu NULL dan bagaimana perilakunya dalam perbandingan. Saya kemudian membahas inkonsistensi perlakuan NULL dalam elemen bahasa yang berbeda. Terakhir, saya membahas fitur standar yang hilang terkait dengan penanganan NULL di T-SQL dan menyarankan alternatif yang tersedia di T-SQL.
Sebagian besar cakupan relevan dengan platform apa pun yang menerapkan dialek SQL, tetapi dalam beberapa kasus saya menyebutkan aspek yang khusus untuk T-SQL.
Dalam contoh saya, saya akan menggunakan database sampel yang disebut TSQLV5. Anda dapat menemukan skrip yang membuat dan mengisi database ini di sini, dan diagram ER-nya di sini.
NULL sebagai penanda untuk nilai yang hilang
Mari kita mulai dengan memahami apa itu NULL. Dalam SQL, NULL adalah penanda, atau pengganti, untuk nilai yang hilang. Ini adalah upaya SQL untuk merepresentasikan dalam database Anda sebuah kenyataan di mana nilai atribut tertentu terkadang ada dan terkadang hilang. Misalnya, Anda perlu menyimpan data karyawan dalam tabel Karyawan. Anda memiliki atribut untuk nama depan, nama tengah, dan nama belakang. Atribut nama depan dan nama belakang adalah wajib, dan oleh karena itu Anda mendefinisikannya sebagai tidak mengizinkan NULL. Atribut nama tengah adalah opsional, dan oleh karena itu Anda mendefinisikannya sebagai mengizinkan NULL.
Jika Anda bertanya-tanya apa yang dikatakan model relasional tentang nilai-nilai yang hilang, pencipta model Edgar F. Codd percaya pada mereka. Bahkan, ia bahkan membuat perbedaan antara dua jenis nilai yang hilang:Missing But Applicable (penanda A-Values), dan Missing But Inapplicable (penanda I-Values). Jika kita mengambil atribut nama tengah sebagai contoh, dalam kasus di mana seorang karyawan memiliki nama tengah, tetapi karena alasan privasi memilih untuk tidak membagikan informasi, Anda akan menggunakan penanda A-Values. Dalam kasus di mana seorang karyawan tidak memiliki nama tengah sama sekali, Anda akan menggunakan penanda I-Values. Di sini, atribut yang sama terkadang bisa relevan dan ada, terkadang Hilang Tapi Dapat Diterapkan dan terkadang Hilang Tapi Tidak Dapat Diterapkan. Kasus lain bisa lebih jelas, hanya mendukung satu jenis nilai yang hilang. Misalnya, Anda memiliki tabel Pesanan dengan atribut yang disebut tanggal pengiriman yang menyimpan tanggal pengiriman pesanan. Pesanan yang dikirim akan selalu memiliki tanggal pengiriman yang sesuai dan relevan. Satu-satunya kasus untuk tidak memiliki tanggal pengiriman yang diketahui adalah untuk pesanan yang belum dikirim. Jadi di sini, nilai tanggal pengiriman yang relevan harus ada, atau penanda I-Values harus digunakan.
Perancang SQL memilih untuk tidak masuk ke dalam perbedaan nilai hilang yang berlaku versus tidak dapat diterapkan, dan memberi kami NULL sebagai penanda untuk segala jenis nilai yang hilang. Untuk sebagian besar, SQL dirancang untuk mengasumsikan bahwa NULL mewakili jenis nilai yang hilang Tapi Berlaku. Akibatnya, terutama ketika Anda menggunakan NULL sebagai pengganti untuk nilai yang tidak dapat diterapkan, penanganan SQL NULL default mungkin bukan yang Anda anggap benar. Terkadang Anda perlu menambahkan logika penanganan NULL eksplisit untuk mendapatkan perlakuan yang Anda anggap tepat untuk Anda.
Sebagai praktik terbaik, jika Anda mengetahui bahwa suatu atribut tidak seharusnya mengizinkan NULL, pastikan Anda menerapkannya dengan batasan NOT NULL sebagai bagian dari definisi kolom. Ada beberapa alasan penting untuk ini. Salah satu alasannya adalah jika Anda tidak menerapkan ini, pada satu titik atau lainnya, NULL akan sampai di sana. Ini bisa menjadi hasil dari bug dalam aplikasi atau mengimpor data yang buruk. Menggunakan batasan, Anda tahu bahwa NULL tidak akan pernah sampai ke tabel. Alasan lainnya adalah pengoptimal mengevaluasi batasan seperti NOT NULL untuk pengoptimalan yang lebih baik, menghindari pekerjaan yang tidak perlu mencari NULL, dan mengaktifkan aturan transformasi tertentu.
Perbandingan yang melibatkan NULL
Ada beberapa kesulitan dalam evaluasi predikat SQL ketika NULL terlibat. Pertama-tama saya akan membahas perbandingan yang melibatkan konstanta. Nanti saya akan membahas perbandingan yang melibatkan variabel, parameter, dan kolom.
Saat Anda menggunakan predikat yang membandingkan operan dalam elemen kueri seperti WHERE, ON, dan HAVING, kemungkinan hasil perbandingan bergantung pada apakah salah satu operan dapat berupa NULL. Jika Anda mengetahui dengan pasti bahwa tidak ada operan yang dapat berupa NULL, hasil predikat akan selalu TRUE atau FALSE. Inilah yang dikenal sebagai logika predikat dua nilai, atau singkatnya, logika dua nilai saja. Ini adalah kasusnya, misalnya, saat Anda membandingkan kolom yang didefinisikan sebagai tidak mengizinkan NULL dengan beberapa operan non-NULL lainnya.
Jika salah satu operan dalam perbandingan mungkin NULL, katakanlah, kolom yang memungkinkan NULL, menggunakan operator kesetaraan (=) dan ketidaksetaraan (<>,>, <,>=, <=, dll.), Anda adalah sekarang pada belas kasihan logika predikat bernilai tiga. Jika dalam perbandingan tertentu kedua operan tersebut merupakan nilai non-NULL, Anda masih mendapatkan TRUE atau FALSE sebagai hasilnya. Namun, jika salah satu operan adalah NULL, Anda mendapatkan nilai logika ketiga yang disebut UNKNOWN. Perhatikan bahwa itulah yang terjadi bahkan ketika membandingkan dua NULL. Perlakuan TRUE dan FALSE oleh sebagian besar elemen SQL cukup intuitif. Perlakuan UNKNOWN tidak selalu intuitif. Selain itu, elemen SQL yang berbeda menangani kasus UNKNOWN secara berbeda, seperti yang akan saya jelaskan secara rinci nanti dalam artikel di bawah "inkonsistensi perlakuan NULL."
Sebagai contoh, anggaplah Anda perlu membuat kueri tabel Sales.Orders di database sampel TSQLV5, dan mengembalikan pesanan yang dikirimkan pada 2 Januari 2019. Anda menggunakan kueri berikut:
USE TSQLV5; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = '20190102';
Jelas bahwa predikat filter dievaluasi ke TRUE untuk baris dengan tanggal pengiriman 2 Januari 2019, dan baris tersebut harus dikembalikan. Juga jelas bahwa predikat mengevaluasi ke FALSE untuk baris di mana tanggal pengiriman ada, tetapi bukan 2 Januari 2019, dan bahwa baris tersebut harus dibuang. Tapi bagaimana dengan baris dengan tanggal pengiriman NULL? Ingat bahwa predikat berbasis kesetaraan dan predikat berbasis ketidaksetaraan menghasilkan UNKNOWN jika salah satu operan adalah NULL. Filter WHERE dirancang untuk membuang baris seperti itu. Anda harus ingat bahwa filter WHERE mengembalikan baris yang predikat filternya dievaluasi ke TRUE, dan membuang baris yang predikatnya dievaluasi ke FALSE atau UNKNOWN.
Kueri ini menghasilkan keluaran berikut:
orderid shippeddate ----------- ----------- 10771 2019-01-02 10794 2019-01-02 10802 2019-01-02
Misalkan Anda perlu mengembalikan pesanan yang tidak dikirim pada tanggal 2 Januari 2019. Sejauh yang Anda ketahui, pesanan yang belum dikirim seharusnya dimasukkan ke dalam output. Anda menggunakan kueri yang mirip dengan yang terakhir, hanya meniadakan predikat, seperti:
SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = '20190102');
Kueri ini mengembalikan output berikut:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
Output secara alami mengecualikan baris dengan tanggal pengiriman 2 Januari 2019, tetapi juga mengecualikan baris dengan tanggal pengiriman NULL. Apa yang bisa kontra intuitif di sini adalah apa yang terjadi ketika Anda menggunakan operator NOT untuk meniadakan predikat yang dievaluasi menjadi UNKNOWN. Jelas, NOT TRUE adalah FALSE dan NOT FALSE adalah TRUE. Namun, NOT UNKNOWN tetap UNKNOWN. Logika SQL di balik desain ini adalah jika Anda tidak tahu apakah suatu proposisi itu benar, Anda juga tidak tahu apakah proposisi itu tidak benar. Ini berarti bahwa ketika menggunakan operator persamaan dan ketidaksamaan dalam predikat filter, baik bentuk positif maupun negatif dari predikat tidak mengembalikan baris dengan NULL.
Contoh ini cukup sederhana. Ada kasus rumit yang melibatkan subquery. Ada bug umum saat Anda menggunakan predikat NOT IN dengan subquery, ketika subquery mengembalikan NULL di antara nilai yang dikembalikan. Kueri selalu mengembalikan hasil kosong. Alasannya adalah bahwa bentuk positif dari predikat (bagian IN) mengembalikan TRUE ketika nilai luar ditemukan, dan UNKNOWN ketika tidak ditemukan karena perbandingan dengan NULL. Kemudian negasi predikat dengan operator NOT selalu mengembalikan FALSE atau UNKNOWN, masing-masing—tidak pernah TRUE. Saya membahas bug ini secara mendetail dalam bug T-SQL, perangkap, dan praktik terbaik – subkueri, termasuk solusi yang disarankan, pertimbangan pengoptimalan, dan praktik terbaik. Jika Anda belum terbiasa dengan bug klasik ini, pastikan Anda memeriksa artikel ini karena bug tersebut cukup umum, dan ada beberapa langkah sederhana yang dapat Anda lakukan untuk menghindarinya.
Kembali ke kebutuhan kita, bagaimana dengan mencoba mengembalikan pesanan dengan tanggal pengiriman yang berbeda dari 2 Januari 2019, menggunakan operator yang berbeda dari (<>):
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102';
Sayangnya, operator persamaan dan ketidaksetaraan menghasilkan UNKNOWN ketika salah satu operan adalah NULL, jadi kueri ini menghasilkan output berikut seperti kueri sebelumnya, tidak termasuk NULL:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
Untuk mengisolasi masalah perbandingan dengan NULL yang menghasilkan UNKNOWN menggunakan kesetaraan, ketidaksetaraan, dan negasi dari dua jenis operator, semua kueri berikut mengembalikan kumpulan hasil kosong:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = NULL); SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate <> NULL);
Menurut SQL, Anda tidak seharusnya memeriksa apakah ada sesuatu yang sama dengan NULL atau berbeda dari NULL, melainkan jika sesuatu itu NULL atau bukan NULL, masing-masing menggunakan operator khusus IS NULL dan IS NOT NULL. Operator ini menggunakan logika dua nilai, selalu mengembalikan TRUE atau FALSE. Misalnya, gunakan operator IS NULL untuk mengembalikan pesanan yang belum terkirim, seperti:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NULL;
Kueri ini menghasilkan keluaran berikut:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... (21 rows affected)
Gunakan operator IS NOT NULL untuk mengembalikan pesanan yang dikirim, seperti:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT NULL;
Kueri ini menghasilkan keluaran berikut:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (809 rows affected)
Gunakan kode berikut untuk mengembalikan pesanan yang dikirim pada tanggal yang berbeda dari 2 Januari 2019, serta pesanan yang belum dikirim:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102' OR shippeddate IS NULL;
Kueri ini menghasilkan keluaran berikut:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (827 rows affected)
Di bagian selanjutnya dalam seri saya membahas fitur standar untuk perawatan NULL yang saat ini tidak ada di T-SQL, termasuk predikat DISTINCT , yang berpotensi sangat menyederhanakan penanganan NULL.
Perbandingan dengan variabel, parameter, dan kolom
Bagian sebelumnya berfokus pada predikat yang membandingkan kolom dengan konstanta. Namun, pada kenyataannya, Anda sebagian besar akan membandingkan kolom dengan variabel/parameter atau dengan kolom lain. Perbandingan tersebut melibatkan kompleksitas lebih lanjut.
Dari sudut pandang penanganan NULL, variabel dan parameter diperlakukan sama. Saya akan menggunakan variabel dalam contoh saya, tetapi poin yang saya buat tentang penanganannya sama relevannya dengan parameter.
Pertimbangkan kueri dasar berikut (saya akan menyebutnya Kueri 1), yang memfilter pesanan yang dikirimkan pada tanggal tertentu:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Saya menggunakan variabel dalam contoh ini dan menginisialisasinya dengan beberapa tanggal sampel, tetapi ini juga bisa berupa kueri berparameter dalam prosedur tersimpan atau fungsi yang ditentukan pengguna.
Eksekusi kueri ini menghasilkan keluaran berikut:
orderid shippeddate ----------- ----------- 10865 2019-02-12 10866 2019-02-12 10876 2019-02-12 10878 2019-02-12 10879 2019-02-12
Rencana untuk Query 1 ditunjukkan pada Gambar 1.
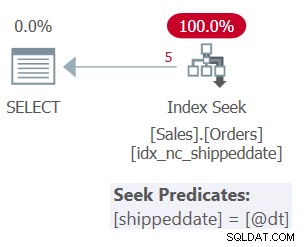 Gambar 1:Rencana untuk Kueri 1
Gambar 1:Rencana untuk Kueri 1
Tabel memiliki indeks penutup untuk mendukung kueri ini. Indeks ini disebut idx_nc_shippeddate, dan ditentukan dengan daftar kunci (tanggal pengiriman, id pesanan). Predikat filter kueri dinyatakan sebagai argumen penelusuran (SARG) , artinya memungkinkan pengoptimal untuk mempertimbangkan penerapan operasi pencarian dalam indeks pendukung, langsung ke kisaran baris yang memenuhi syarat. Apa yang membuat predikat filter SARGable adalah bahwa ia menggunakan operator yang mewakili rentang baris kualifikasi yang berurutan dalam indeks, dan tidak menerapkan manipulasi pada kolom yang difilter. Paket yang Anda dapatkan adalah paket optimal untuk kueri ini.
Tetapi bagaimana jika Anda ingin mengizinkan pengguna untuk meminta pesanan yang belum dikirim? Pesanan tersebut memiliki tanggal pengiriman NULL. Berikut ini upaya untuk memberikan NULL sebagai tanggal input:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Seperti yang sudah Anda ketahui, predikat menggunakan operator kesetaraan menghasilkan UNKNOWN ketika salah satu operan adalah NULL. Akibatnya, kueri ini mengembalikan hasil kosong:
orderid shippeddate ----------- ----------- (0 rows affected)
Meskipun T-SQL mendukung operator IS NULL, T-SQL tidak mendukung operator
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE ISNULL(shippeddate, '99991231') = ISNULL(@dt, '99991231');
Kueri ini menghasilkan keluaran yang benar:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 11075 NULL 11076 NULL 11077 NULL (21 rows affected)
Tetapi rencana untuk kueri ini, seperti yang ditunjukkan pada Gambar 2, tidak optimal.
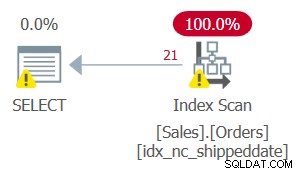 Gambar 2:Rencana untuk Kueri 2
Gambar 2:Rencana untuk Kueri 2
Karena Anda menerapkan manipulasi ke kolom yang difilter, predikat filter tidak lagi dianggap sebagai SARG. Indeks masih menutupi, sehingga dapat digunakan; tetapi alih-alih menerapkan pencarian dalam indeks langsung ke kisaran baris yang memenuhi syarat, seluruh lembar indeks dipindai. Misalkan tabel memiliki 50.000.000 pesanan, dengan hanya 1.000 pesanan yang belum dikirim. Rencana ini akan memindai semua 50.000.000 baris alih-alih melakukan pencarian yang langsung menuju ke 1.000 baris yang memenuhi syarat.
Salah satu bentuk predikat filter yang keduanya memiliki arti yang benar yang kita kejar dan dianggap sebagai argumen pencarian adalah (shippeddate =@dt OR (shippeddate IS NULL AND @dt IS NULL)). Berikut query yang menggunakan predikat SARGable ini (kami akan menyebutnya Query 3):
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE (shippeddate = @dt OR (shippeddate IS NULL AND @dt IS NULL));
Rencana untuk kueri ini ditunjukkan pada Gambar 3.
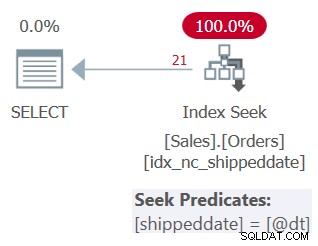 Gambar 3:Rencana untuk Kueri 3
Gambar 3:Rencana untuk Kueri 3
Seperti yang Anda lihat, rencana tersebut menerapkan pencarian di indeks pendukung. Predikat pencarian mengatakan shipdate =@dt, tetapi secara internal dirancang untuk menangani NULL seperti nilai non-NULL demi perbandingan.
Solusi ini umumnya dianggap masuk akal. Itu standar, optimal dan benar. Kelemahan utamanya adalah verbose. Bagaimana jika Anda memiliki beberapa predikat filter berdasarkan kolom NULLable? Anda akan segera berakhir dengan klausa WHERE yang panjang dan rumit. Dan itu menjadi jauh lebih buruk ketika Anda perlu menulis predikat filter yang melibatkan kolom NULLable mencari baris di mana kolom berbeda dari parameter input. Predikatnya kemudian menjadi:(shippeddate <> @dt AND ((shippeddate IS NULL AND @dt IS NOT NULL) OR (shippeddate IS NOT NULL and @dt IS NULL))).
Anda dapat melihat dengan jelas kebutuhan akan solusi yang lebih elegan yang ringkas dan optimal. Sayangnya, beberapa menggunakan solusi tidak standar di mana Anda mematikan opsi sesi ANSI_NULLS. Opsi ini menyebabkan SQL Server menggunakan penanganan yang tidak standar dari operator kesetaraan (=) dan berbeda dari (<>) dengan logika dua nilai alih-alih logika tiga nilai, memperlakukan NULL seperti nilai non-NULL untuk tujuan perbandingan. Setidaknya itu yang terjadi selama salah satu operan adalah parameter/variabel atau literal.
Jalankan kode berikut untuk mematikan opsi ANSI_NULLS di sesi:
SET ANSI_NULLS OFF;
Jalankan kueri berikut menggunakan predikat berbasis kesetaraan sederhana:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Kueri ini mengembalikan 21 pesanan yang belum terkirim. Anda mendapatkan paket yang sama yang ditunjukkan sebelumnya pada Gambar 3, menunjukkan pencarian di indeks.
Jalankan kode berikut untuk beralih kembali ke perilaku standar di mana ANSI_NULLS aktif:
SET ANSI_NULLS ON;
Mengandalkan perilaku tidak standar seperti itu sangat tidak disarankan. Dokumentasi juga menyatakan bahwa dukungan untuk opsi ini akan dihapus di beberapa versi SQL Server yang akan datang. Selain itu, banyak yang tidak menyadari bahwa opsi ini hanya berlaku jika setidaknya salah satu operan adalah parameter/variabel atau konstanta, meskipun dokumentasinya cukup jelas. Ini tidak berlaku saat membandingkan dua kolom seperti dalam gabungan.
Jadi bagaimana Anda menangani gabungan yang melibatkan kolom gabungan NULLable jika Anda ingin mendapatkan kecocokan ketika kedua sisinya NULL? Sebagai contoh, gunakan kode berikut untuk membuat dan mengisi tabel T1 dan T2:
DROP TABLE IF EXISTS dbo.T1, dbo.T2; GO CREATE TABLE dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T1 UNIQUE CLUSTERED(k1, k2, k3)); CREATE TABLE dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) VALUES (1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C'),(1, 1, 0, 'D'),(0, NULL, 1, 'F'); INSERT INTO dbo.T2(k1, k2, k3, val2) VALUES (0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I'),(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
Kode membuat indeks penutup pada kedua tabel untuk mendukung gabungan berdasarkan kunci gabungan (k1, k2, k3) di kedua sisi.
Gunakan kode berikut untuk memperbarui statistik kardinalitas, meningkatkan angka sehingga pengoptimal akan berpikir bahwa Anda berurusan dengan tabel yang lebih besar:
UPDATE STATISTICS dbo.T1(UNQ_T1) WITH ROWCOUNT = 1000000; UPDATE STATISTICS dbo.T2(UNQ_T2) WITH ROWCOUNT = 1000000;
Gunakan kode berikut dalam upaya untuk menggabungkan dua tabel menggunakan predikat berbasis kesetaraan sederhana:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.k1 = T2.k1
AND T1.k2 = T2.k2
AND T1.k3 = T2.k3; Sama seperti contoh pemfilteran sebelumnya, di sini juga perbandingan antara NULL menggunakan operator kesetaraan menghasilkan UNKNOWN, menghasilkan ketidakcocokan. Kueri ini menghasilkan keluaran kosong:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- (0 rows affected)
Menggunakan ISNULL atau COALESCE seperti dalam contoh pemfilteran sebelumnya, mengganti NULL dengan nilai yang biasanya tidak muncul dalam data di kedua sisi, menghasilkan kueri yang benar (saya akan merujuk kueri ini sebagai Kueri 4):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON ISNULL(T1.k1, -2147483648) = ISNULL(T2.k1, -2147483648)
AND ISNULL(T1.k2, -2147483648) = ISNULL(T2.k2, -2147483648)
AND ISNULL(T1.k3, -2147483648) = ISNULL(T2.k3, -2147483648); Kueri ini menghasilkan keluaran berikut:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
Namun, sama seperti memanipulasi kolom yang difilter merusak kemampuan SARG predikat filter, manipulasi kolom gabungan mencegah kemampuan untuk mengandalkan urutan indeks. Ini dapat dilihat dalam rencana untuk kueri ini seperti yang ditunjukkan pada Gambar 4.
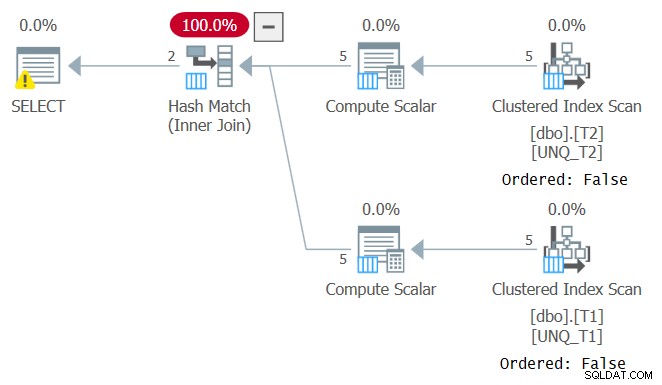 Gambar 4:Rencana untuk Kueri 4
Gambar 4:Rencana untuk Kueri 4
Rencana optimal untuk kueri ini adalah yang menerapkan pemindaian berurutan dari dua indeks penutup yang diikuti oleh algoritme Gabung Gabung, tanpa pengurutan eksplisit. Pengoptimal memilih paket yang berbeda karena tidak dapat mengandalkan urutan indeks. Jika Anda mencoba untuk memaksa algoritma Gabung Gabung menggunakan INNER MERGE JOIN, rencananya masih akan bergantung pada pemindaian indeks yang tidak berurutan, diikuti dengan penyortiran eksplisit. Cobalah!
Tentu saja Anda dapat menggunakan predikat panjang yang mirip dengan predikat SARGable yang ditunjukkan sebelumnya untuk tugas penyaringan:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON (T1.k1 = T2.k1 OR (T1.k1 IS NULL AND T2.K1 IS NULL))
AND (T1.k2 = T2.k2 OR (T1.k2 IS NULL AND T2.K2 IS NULL))
AND (T1.k3 = T2.k3 OR (T1.k3 IS NULL AND T2.K3 IS NULL)); Kueri ini menghasilkan hasil yang diinginkan dan memungkinkan pengoptimal mengandalkan urutan indeks. Namun, harapan kami adalah menemukan solusi yang optimal dan ringkas.
Ada teknik elegan dan ringkas yang tidak banyak diketahui yang dapat Anda gunakan baik dalam gabungan maupun filter, baik untuk tujuan mengidentifikasi kecocokan maupun untuk mengidentifikasi ketidakcocokan. Teknik ini ditemukan dan didokumentasikan sudah bertahun-tahun yang lalu, seperti dalam tulisan Paul White yang luar biasa Undocumented Query Plans:Equality Comparisons from 2011. Tetapi untuk beberapa alasan sepertinya masih banyak orang yang tidak menyadarinya, dan sayangnya akhirnya menggunakan suboptimal, panjang dan solusi tidak standar. Ini tentu saja layak mendapatkan lebih banyak eksposur dan cinta.
Teknik ini bergantung pada fakta bahwa operator himpunan seperti INTERSECT dan EXCEPT menggunakan pendekatan perbandingan berbasis perbedaan saat membandingkan nilai, dan bukan pendekatan perbandingan berbasis kesetaraan atau ketidaksetaraan.
Pertimbangkan tugas bergabung kami sebagai contoh. Jika kami tidak perlu mengembalikan kolom selain kunci gabungan, kami akan menggunakan kueri sederhana (saya akan menyebutnya sebagai Kueri 5) dengan operator INTERSECT, seperti:
SELECT k1, k2, k3 FROM dbo.T1 INTERSECT SELECT k1, k2, k3 FROM dbo.T2;
Kueri ini menghasilkan keluaran berikut:
k1 k2 k3 ----------- ----------- ----------- 0 NULL NULL 0 NULL 1
Rencana untuk kueri ini ditunjukkan pada Gambar 5, mengkonfirmasikan bahwa pengoptimal dapat mengandalkan urutan indeks dan menggunakan algoritme Gabung Bergabung.
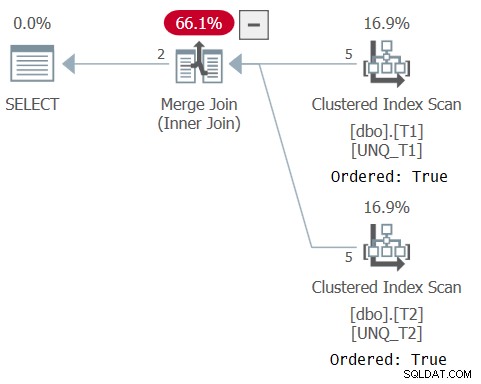 Gambar 5:Rencana untuk Kueri 5
Gambar 5:Rencana untuk Kueri 5
Seperti yang dicatat Paul dalam artikelnya, paket XML untuk operator yang ditetapkan menggunakan operator perbandingan IS implisit (CompareOp="IS" ) sebagai lawan dari operator perbandingan EQ yang digunakan dalam gabungan normal (CompareOp="EQ" ). Masalah dengan solusi yang hanya mengandalkan operator yang ditetapkan adalah membatasi Anda untuk mengembalikan hanya kolom yang Anda bandingkan. Yang benar-benar kami butuhkan adalah semacam hibrida antara gabungan dan operator himpunan, memungkinkan Anda untuk membandingkan subset elemen sambil mengembalikan elemen tambahan seperti gabungan, dan menggunakan perbandingan berbasis perbedaan (IS) seperti yang dilakukan operator himpunan. Ini dapat dicapai dengan menggunakan gabungan sebagai konstruksi luar, dan predikat EXISTS dalam klausa ON gabungan berdasarkan kueri dengan operator INTERSECT yang membandingkan kunci gabungan dari kedua sisi, seperti itu (saya akan merujuk ke solusi ini sebagai Kueri 6):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
Operator INTERSECT beroperasi pada dua query, masing-masing membentuk satu set satu baris berdasarkan tombol join dari kedua sisi. Ketika dua baris sama, kueri INTERSECT mengembalikan satu baris; predikat EXISTS mengembalikan TRUE, menghasilkan kecocokan. Ketika dua baris tidak sama, kueri INTERSECT mengembalikan set kosong; predikat EXISTS mengembalikan FALSE, menghasilkan ketidakcocokan.
Solusi ini menghasilkan keluaran yang diinginkan:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
Rencana untuk kueri ini ditunjukkan pada Gambar 6, mengkonfirmasikan bahwa pengoptimal dapat mengandalkan urutan indeks.
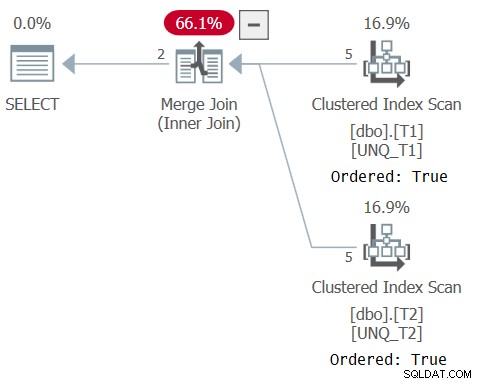 Gambar 6:Rencana untuk Kueri 6
Gambar 6:Rencana untuk Kueri 6
Anda dapat menggunakan konstruksi serupa sebagai predikat filter yang melibatkan kolom dan parameter/variabel untuk mencari kecocokan berdasarkan perbedaan, seperti:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Rencananya sama dengan yang ditunjukkan sebelumnya pada Gambar 3.
Anda juga dapat meniadakan predikat untuk mencari yang tidak cocok, seperti:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Kueri ini menghasilkan keluaran berikut:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10847 2019-02-10 10856 2019-02-10 10871 2019-02-10 10867 2019-02-11 10874 2019-02-11 10870 2019-02-13 10884 2019-02-13 10840 2019-02-16 10887 2019-02-16 ... (825 rows affected)
Atau, Anda dapat menggunakan predikat positif, tetapi ganti INTERSECT dengan KECUALI, seperti:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
Perhatikan bahwa rencana dalam dua kasus bisa berbeda, jadi pastikan untuk bereksperimen dua arah dengan data dalam jumlah besar.
Kesimpulan
NULL menambahkan bagian kompleksitasnya ke penulisan kode SQL Anda. Anda selalu ingin memikirkan potensi keberadaan NULL dalam data, dan memastikan bahwa Anda menggunakan konstruksi kueri yang tepat, dan menambahkan logika yang relevan ke solusi Anda untuk menangani NULL dengan benar. Mengabaikannya adalah cara pasti untuk berakhir dengan bug dalam kode Anda. Bulan ini saya fokus pada apa itu NULL dan bagaimana penanganannya dalam perbandingan yang melibatkan konstanta, variabel, parameter, dan kolom. Bulan depan saya akan melanjutkan liputan dengan membahas inkonsistensi perlakuan NULL dalam elemen bahasa yang berbeda, dan fitur standar yang hilang untuk penanganan NULL.