Dalam blog Hybrid Cloud kami sebelumnya, kami sering menyebutkan bahwa salah satu opsi utama untuk memanfaatkan penyiapan topologi Hybrid Cloud adalah menggunakan ini sebagai target pemulihan bencana Anda. Adalah umum untuk struktur organisasi bahwa Disaster Recovery Plan (DRP) selalu ditangani sebelum implementasi arsitektur dari pengaturan database Anda, baik di cloud atau di tempat. Anda mungkin berpikir bahwa segala sesuatunya akan gagal secara tak terduga dan dapat mempengaruhi bisnis Anda secara tragis jika tidak ditangani dan dipahami dengan benar. Mengatasi tantangan ini memerlukan DRP (Disaster Recovery Plan) yang efektif, di mana sistem Anda dikonfigurasi dengan baik sesuai dengan kebutuhan aplikasi, infrastruktur, dan bisnis Anda. Kunci keberhasilan dalam situasi seperti ini adalah seberapa cepat kami dapat memperbaiki atau memulihkan dari masalah tersebut.
Sementara DRP menangani keadaan bencana, Business Continuity akan memastikan bahwa DRP diuji dan beroperasi setiap saat bila diperlukan. Opsi Pemulihan Bencana Anda untuk database Anda harus memastikan operasi yang berkelanjutan dan batas-batas yang diharapkan. Itu harus sesuai dengan RTO dan RPO yang Anda inginkan. Sangat penting untuk memastikan bahwa database produksi tersedia untuk aplikasi bahkan selama bencana; jika tidak, itu bisa menjadi kesepakatan yang mahal. DBA, Arsitek, perlu memastikan bahwa lingkungan basis data dapat mempertahankan bencana dan sesuai dengan SLA pemulihan bencana. Penerapan basis data harus dikonfigurasi dengan benar untuk memastikan bencana tidak memengaruhi ketersediaan basis data dan kelangsungan bisnis.
Opsi Pemulihan Bencana
Kluster PostgreSQL Anda harus dikonfigurasi dengan pendekatan sistematis yang berkomitmen pada praktik terbaik dan dapat diterima oleh standar industri. Bersamaan dengan pendekatan sistematis, proses atau mekanisme berikut membantu Anda memastikan bahwa PostgreSQL yang di-deploy ke Hybrid Cloud memiliki kehadiran berikut:
-
Failover/Switchover
-
Pencadangan Otomatis
-
Sangat Tersedia
-
Load Balancing
-
Lingkungan yang Sangat Terdistribusi
Failover/Switchover
Failover adalah proses otomatis jika master Anda gagal; server siaga panas atau server siaga hangat dipromosikan ke peran utama/master. Ini adalah praktik terbaik yang memberikan lingkungan ketersediaan tinggi untuk memiliki setidaknya node sekunder untuk bertindak sebagai kandidat untuk node failover. Setelah server utama gagal, server siaga harus memulai prosedur failover, dan kemudian server sekunder atau siaga akan berperan sebagai master. Sistem failover menggunakan minimal dua server dalam praktik umum, yang berfungsi sebagai server utama dan siaga. Pemeriksaan konektivitasnya dibantu oleh mekanisme detak jantung yang melakukan pemeriksaan tanpa henti dan memverifikasi apakah keduanya dalam keadaan baik dan komunikasi hidup. Namun, dalam beberapa kasus, konektivitas dapat memberikan alarm palsu. Oleh karena itu, di beberapa pengaturan dan lingkungan, keberadaan sistem ketiga seperti node pemantauan terletak pada jaringan atau pusat data yang terpisah. Ini adalah opsi yang sangat mudah untuk mencegah failover yang tidak sesuai atau tidak diinginkan. Node verifikasi yang sangat mudah dapat memiliki fitur dan pemeriksaan tambahan, yang menambah kerumitan. Penyiapan ini memerlukan pengujian penuh dan ketat untuk memastikan failover dilakukan dengan benar ketika ada perubahan dalam implementasi. Selain itu, ini penting untuk mencegah kerusakan PostgreSQL Anda
Misalnya Anda memiliki cluster sekunder atau siaga di pusat data yang berbeda dengan pengaturan perangkat keras yang berbeda; Anda mungkin tidak ingin melakukan failover secara tiba-tiba, terutama jika itu bukan kasus yang ideal karena hanya positif palsu. Namun, dalam skenario ini, node atau cluster target pemulihan data Anda harus memiliki sumber daya dan spesifikasi yang sama dengan node atau cluster utama Anda. Jika target pemulihan data Anda berada di cloud publik dan primer di lokal, pastikan target tersebut telah tercakup dalam perencanaan kapasitas dan resource memiliki spesifikasi yang hampir sama untuk menghindari hasil yang tidak diinginkan.
Saat menggunakan dan mempersiapkan mekanisme failover Anda di PostgreSQL Cluster dalam Hybrid Cloud, Anda harus memastikan bahwa alat Anda sangat cocok untuk melakukan pekerjaan yang seharusnya dicapai. Ada alat pihak ketiga yang tidak disertakan dalam PostgreSQL terkait dengan failover lanjutan. Misalnya, ada ClusterControl, pg_auto_failover oleh CitusData (c/o Microsoft), Pgpool-II, Bucardo, dan lainnya. Alat utilitas canggih ini menyediakan pagar simpul atau dikenal sebagai STONITH (tembak simpul lain di kepala). Ini memastikan bahwa node utama atau master Anda yang gagal akan menghindari menerima penulisan atau kembali online seperti keadaan sebelumnya untuk melayani transaksi normal. Masalah ini umumnya dikenal sebagai skenario otak terbelah. Itu kehilangan sinkronisasi data karena kegagalan (tingkat perangkat keras atau sumber daya) tetapi server utama Anda, yang seharusnya hanya satu server utama, bertindak seolah-olah melakukan permintaan penulisan data penerima normal yang menyebabkan kerusakan data di seluruh cluster.
Pencadangan Otomatis
Cadangan selalu memberikan jaminan dan perlindungan yang tinggi terhadap kehilangan data. Pencadangan memaksimalkan RPO Anda karena membantu meminimalkan kehilangan data saat terjadi bencana. Hal-hal yang harus Anda pertimbangkan dan persiapkan untuk pencadangan otomatis Anda meliputi alat/perangkat keras pencadangan, redundansi data cadangan, keamanan, kinerja, kecepatan, dan penyimpanan data.
Alat Cadangan
Anda harus memiliki pilihan terbaik untuk alat cadangan Anda di sini. Kecepatan, volume penyimpanan yang signifikan, dan ketersediaan yang tinggi dapat menjadi pilihan yang Anda inginkan. Beberapa mengandalkan penyimpanan SAN atau NAS atau menyebarkan datanya ke penyedia penyimpanan cadangan pihak ketiga lainnya. Sangat penting bahwa alat pencadangan Anda menawarkan kecepatan untuk menulis dan membaca data, terutama jika Anda menerapkan kompresi dan enkripsi untuk data Anda saat istirahat. Dekompresi dan dekripsi membutuhkan sumber daya, jadi Anda harus mempertimbangkan kapan Anda harus menggunakan pemulihan data. Selama keadaan ini, Anda harus menentukan bahwa Anda harus mencapai RPO maksimum dan melakukan SLA (Perjanjian Tingkat Layanan) yang dapat dicapai kepada pelanggan Anda. Ini juga ideal bahwa Anda mungkin harus mengisolasi cadangan Anda dari jaringan lokal Anda atau menyimpannya di lokasi yang jauh. Pendekatan alternatif adalah terlibat dengan penyedia pihak ketiga. Misalnya, menyimpan cadangan Anda di awan bisa menjadi pilihan, dan fasilitasnya sangat canggih dan memenuhi kebutuhan Anda.
Redundansi Data Cadangan
Menyebarkan data Anda di beberapa lokasi adalah solusi ideal. Ini memperkuat peluang pemulihan data Anda, misalnya, kesalahan manusia atau kesalahan logika perangkat lunak yang menyebabkan Anda menghapus salinan cadangan lama tetapi secara keliru menghapus seluruh salinan cadangan penting. Di beberapa lingkungan canggih, seperti penyimpanan di lingkungan cloud seperti Amazon S3, Cloud Storage by Google, atau Azure Blob Storage menawarkan replikasi file Anda yang disimpan. Ini memberikan lebih banyak redundansi dan dapat disiapkan dengan cara yang fleksibel yang sesuai dengan kebutuhan Anda.
Sangat Tersedia
Kluster PostgreSQL yang sangat tersedia di Hybrid Cloud selalu memastikan bahwa komunikasi database Anda memastikan waktu aktif. Kasus ideal ketersediaan tinggi tergantung pada pengukuran ketersediaan Anda. Dalam hal ini, pengaturan umum untuk PostgreSQL yang digunakan di cloud hybrid dapat berupa database Anda yang dihosting di cloud publik dapat berupa cluster sekunder Anda yang bertindak sebagai cluster pemulihan data jika cluster utama gagal atau mengalami bencana jaringan dan dapat mengambil banyak waktu henti. Dalam beberapa pengaturan, ada kemungkinan bahwa cluster sekunder yang terletak di cloud publik mungkin tidak secanggih yang utama, katakanlah ini adalah cloud lokal atau pribadi Anda. Aplikasi Anda dapat bermain-main untuk membatasi pengunjung atau lalu lintas yang dapat terhubung ke database Anda. Jenis skenario ini dapat mengurangi biaya penyiapan Anda, tetapi tentu saja, ini hanya bergantung pada kebutuhan Anda. Jika jenis aplikasi Anda sangat besar dan harus terus-menerus menerima situasi lalu lintas normal hingga sibuk, pastikan sumber daya cluster sekunder Anda harus sekuat primer untuk memastikan ketersediaan tinggi, yaitu 99,9999999%.
Untuk mencapai cluster PostgreSQL yang sangat tersedia di lingkungan cloud hybrid, Anda harus memiliki mekanisme failover. Jika terjadi kegagalan dan cluster utama atau server utama mati, server sekunder atau siaga kemudian dapat mengambil peran sebagai master di mana pun lokasinya. Yang paling penting adalah fungsionalitasnya, dan kinerjanya, terutama dari sudut pandang aplikasi atau klien, tidak terpengaruh sama sekali atau setidaknya sangat minim.
Keseimbangan Beban
Mekanisme penyeimbangan muatan untuk klaster PostgreSQL Anda membantu penyiapan cloud hibrid Anda, yang lebih mudah dikelola dan kurang berisiko, terutama saat terjadi beban lalu lintas tinggi. Dalam banyak situasi, server menerima beban tinggi yang parah menyebabkan server panik. Ini mengarah ke status server yang tidak dapat digunakan karena sumber daya yang sibuk dikonsumsi oleh banyak utas yang berjalan di latar belakang. Situasi ini dapat diperbaiki dengan memperbaiki kueri buruk dan arsitektur desain database Anda. Ini harus mencakup bagaimana Anda mendistribusikan pembacaan terhadap beban tulis dan pemahaman mendalam tentang persyaratan aplikasi Anda seperti penyiapan master-master atau hanya satu master tetapi menskalakannya secara vertikal untuk menyediakan sumber daya komputasi dan memori yang lebih tinggi. Ada juga banyak pilihan alat pihak ketiga seperti pgbouncer dan Pgpool II untuk membantu penerapan PostgreSQL Anda di lingkungan cloud hybrid.
Lingkungan yang Sangat Terdistribusi
Dari segi skalabilitas, sangat terdistribusi di banyak lokasi atau penyedia cloud yang berbeda (on-prem atau cloud pribadi dan publik) memberikan lebih banyak fleksibilitas dan tolerabilitas dalam lingkungan cloud hybrid dan ini bagus untuk pemulihan bencana. Ini fleksibel ketika perlu failover di lokasi cloud tertentu yang menguntungkan untuk bencana alam atau bencana, terutama jika wilayah yang Anda tentukan di mana cluster utama Anda berada saat ini hancur atau dipengaruhi oleh penyebab alami. Ini adalah penyebab tak terelakkan yang harus Anda pahami dan dapat diandalkan dari situasi saat ini. Aplikasi dan klien Anda harus dilayani terus menerus tanpa henti. Ini berfungsi untuk tersedia secara publik di cloud sementara juga melayani di lingkungan pribadi atau di tempat. Pengaturan ini menambah kompleksitas yang lebih tinggi dan membutuhkan pengetahuan tingkat lanjut di sisi database serta keamanan dan jaringan. Pengoptimalan dan penyetelan sangat penting untuk keberhasilan di sini karena sangat penting bahwa saat melayani keamanan yang diperketat untuk merangkum data Anda saat bepergian di internet, kinerja harus terbukti stabil dan tidak terpengaruh oleh penyiapan yang diterapkan.
Karena kerumitan penyiapan, memiliki alat sangat ideal untuk mengelola penerapan dan memfasilitasi status keseluruhan basis data Anda, mengawasi satu aspek kluster Anda tetapi di seluruh tingkat dari cloud pribadi lokal, dan pada aspek cloud publik. Semua penyiapan harus dijaga pada tingkat yang dapat dikelola dan langsung sehingga jika terjadi alarm dan peringatan, mudah untuk memperbaiki dan mengatasi masalah dengan benar dan tepat waktu.
ClusterControl Untuk Pemulihan Bencana Dalam Lingkungan Cloud Hybrid
ClusterControl memungkinkan organisasi atau perusahaan mengelola database dengan fleksibel dan mengurangi kerumitan penyiapan secara keseluruhan. ClusterControl menawarkan failover, pencadangan otomatis, menyediakan penyiapan yang sangat tersedia, penyeimbangan beban, dan mendukung penerapan lingkungan terdistribusi, sehingga memudahkan untuk menambahkan node baik di cloud publik atau pribadi atau lokal.
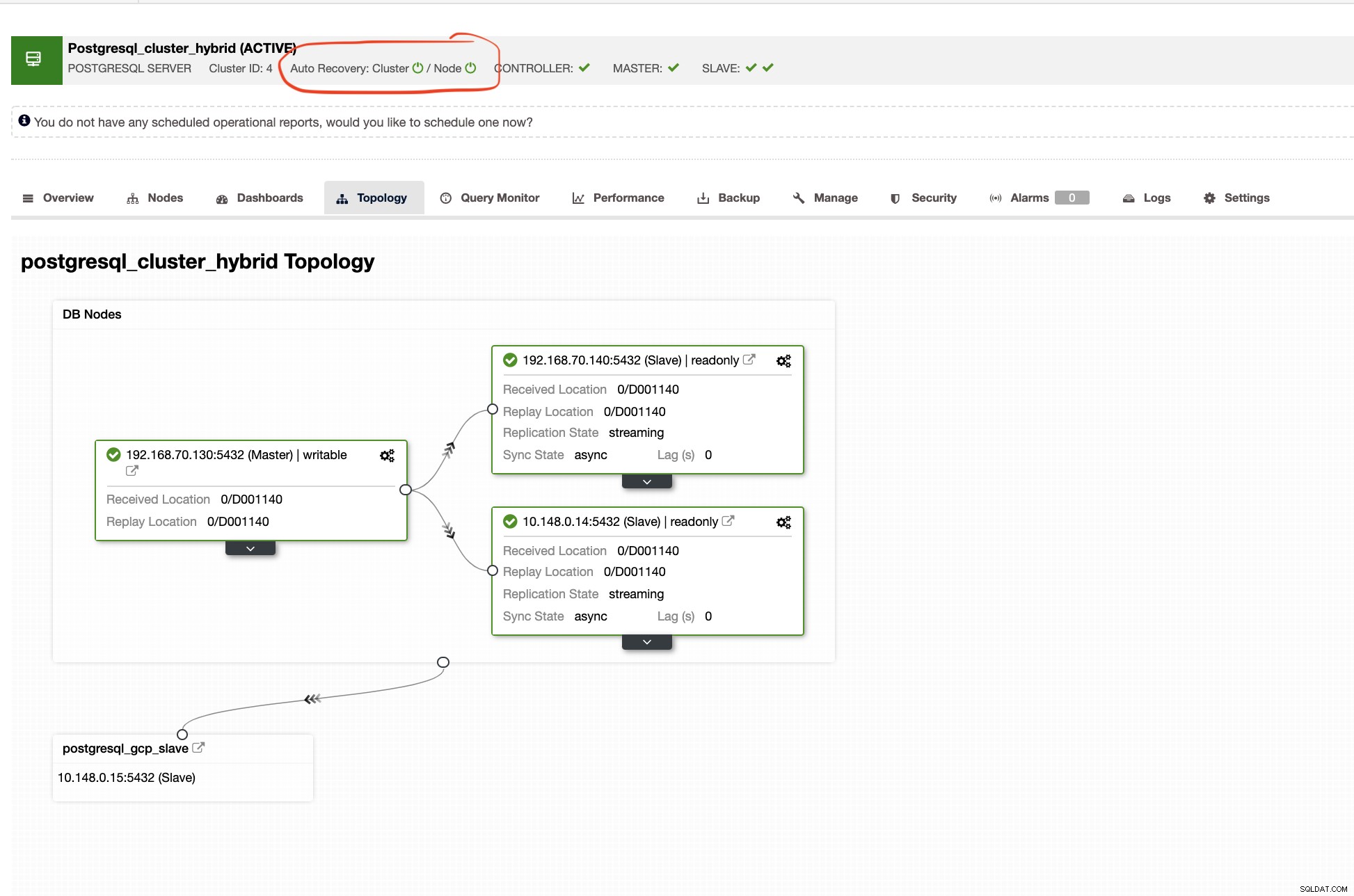
Pemulihan Otomatis Kontrol Cluster
Pemulihan Otomatis dari ClusterControl mewakili banyak mekanisme failover dan karakteristik pemulihan terutama ketika sebuah node turun atau sebuah cluster mengalami penurunan. Ini dapat dengan mudah dilakukan seperti yang ditunjukkan pada tangkapan layar di bawah ini:
Cadangkan dan Pulihkan
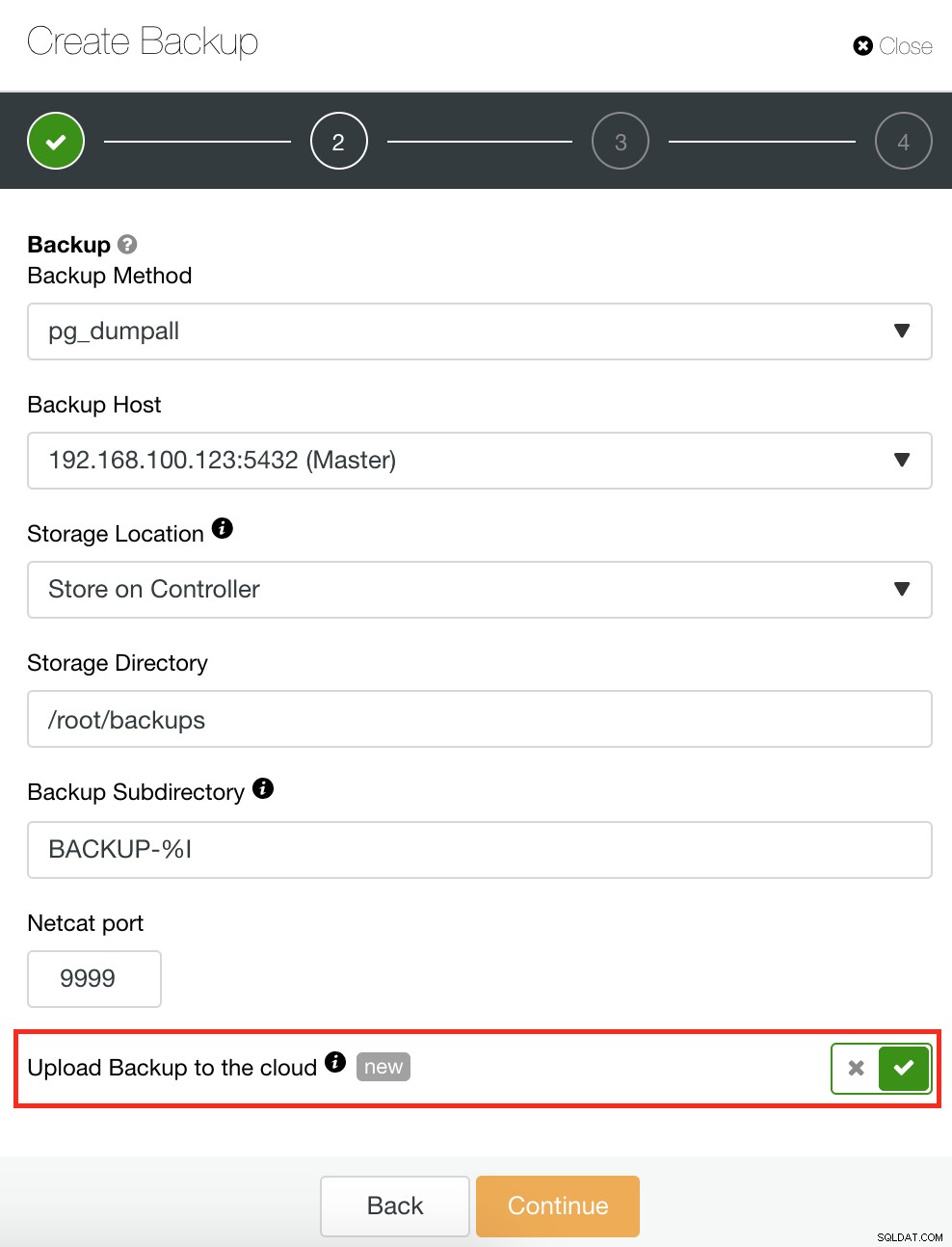
ClusterControl juga memiliki fitur Pencadangan dan Pemulihan yang memungkinkan Anda mengelola pencadangan, membuat pencadangan, menjadwalkan pencadangan, dan memulihkan pencadangan. Mengelola pencadangan Anda sangat mudah dan membuat atau menjadwalkan pencadangan itu sederhana namun juga menawarkan opsi lanjutan. Ini juga menawarkan opsi cadangan cloud yang memungkinkan Anda untuk memiliki redundansi data cadangan, memperkuat opsi Pemulihan Bencana Anda. Lihat di bawah:
Seperti yang ditunjukkan di bawah ini, mengelola cadangan Anda menyediakan UI sederhana bagi Anda untuk memilih cadangan mana yang ingin Anda pulihkan, atau Anda mungkin harus membuangnya. Cadangan ClusterControl memungkinkan Anda memilih periode penyimpanan, jadi jika Anda memiliki daftar yang panjang, beberapa di antaranya dapat dihapus saat mencapai periode penyimpanannya. 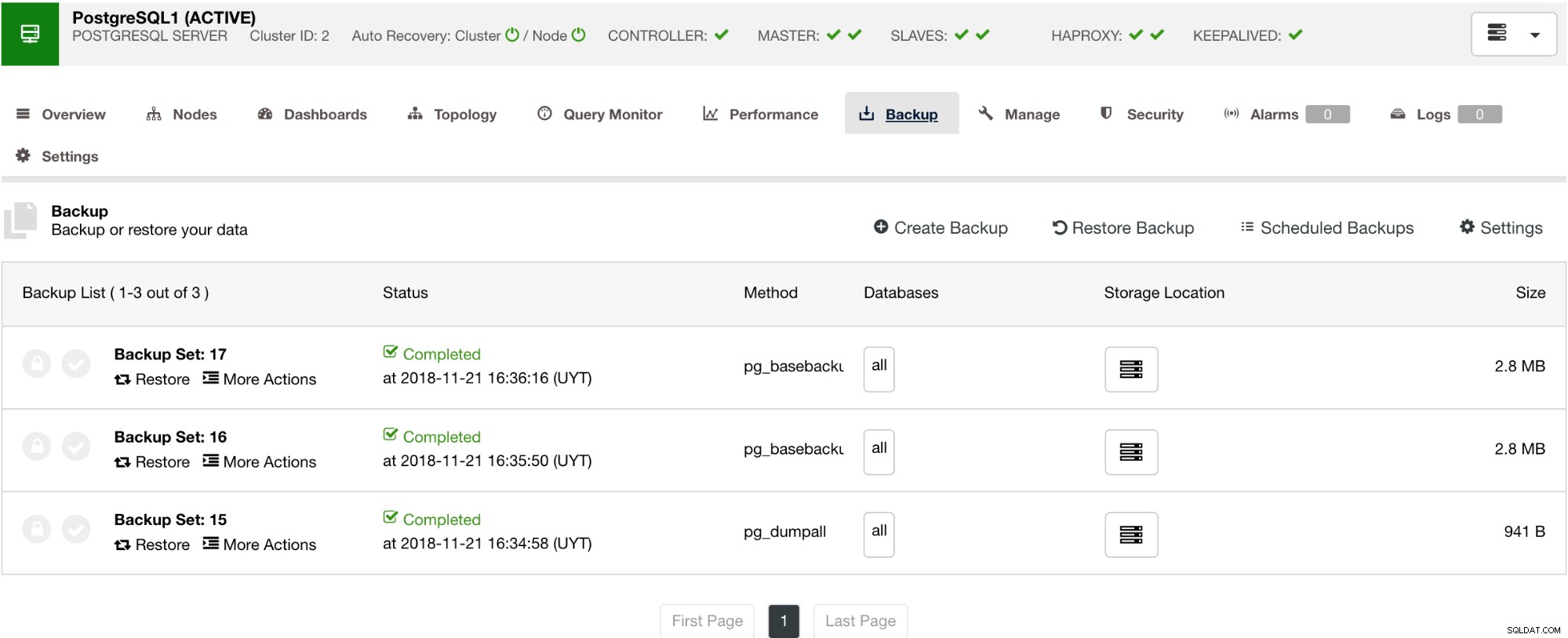
Mendukung Mekanisme Ketersediaan Tinggi (HA) dan Penyeimbangan Beban (LB)
Anda tidak perlu menyiapkan secara manual atau bahkan meneliti beberapa cara untuk menambahkan ketersediaan tinggi di klaster PostgreSQL Anda. Ada cara mudah dan nyaman untuk menyelesaikan pekerjaan dengan ClusterControl. Jika Anda dapat melihat contoh tangkapan layar, ia memiliki pengaturan HAProxy dan Keepalive. Lihat tangkapan layar di bawah ini:
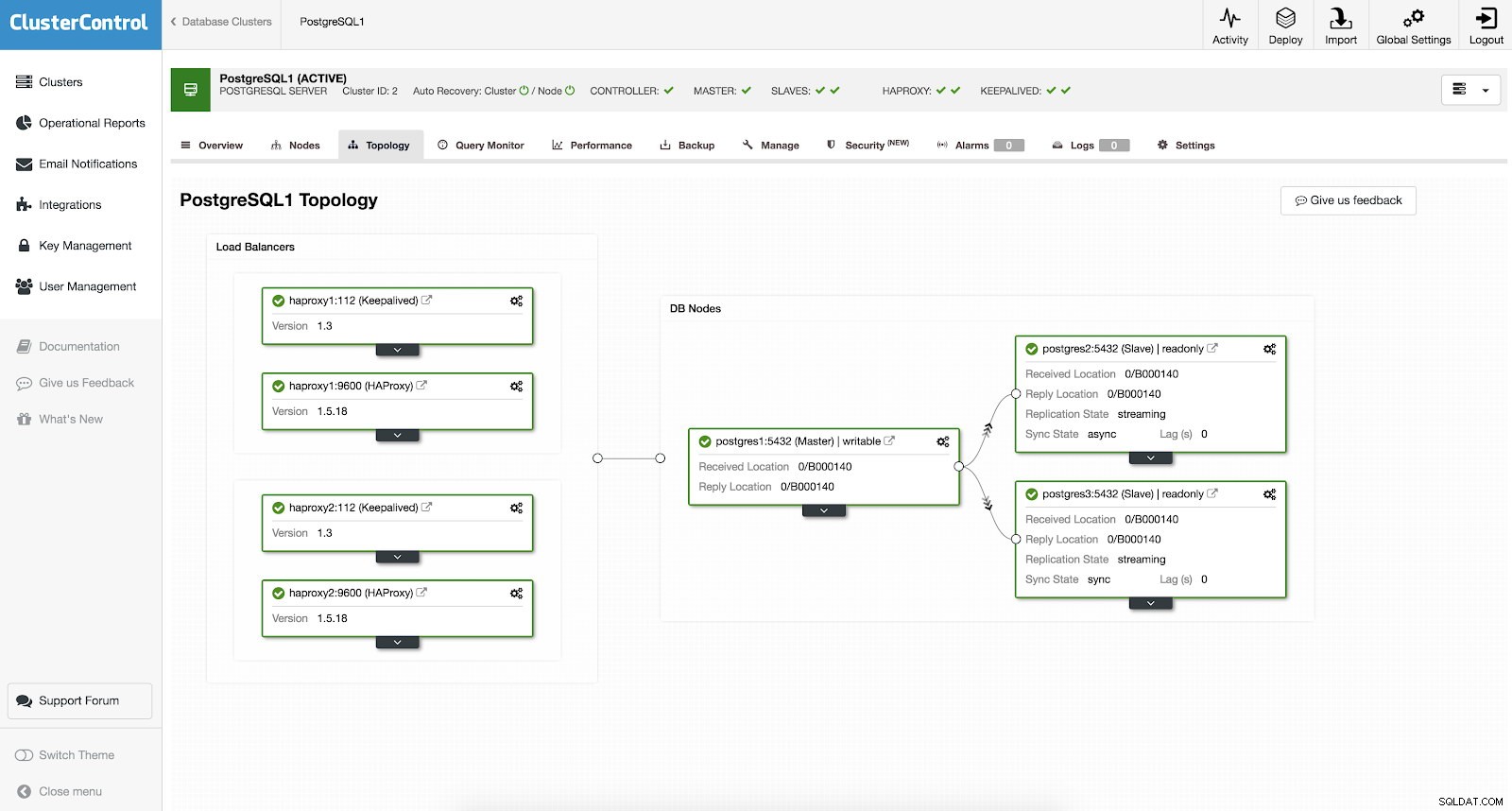
Menyiapkan ketersediaan tinggi dengan ClusterControl dapat dilakukan dengan melalui
Mendukung Lingkungan Terdistribusi
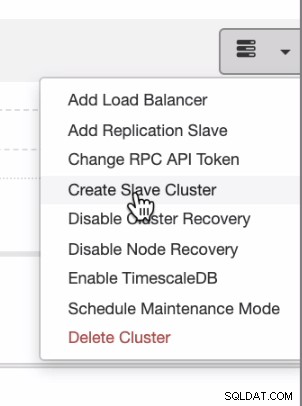
Jika Anda ingin memiliki distribusi yang merata dari cloud lokal atau pribadi ke cloud publik, ClusterControl juga mendukung penyebaran cloud. Tetapi untuk cluster PostgreSQL dan Anda berencana untuk memiliki slave sekunder yang berada di cloud yang berbeda, Anda dapat membuat cluster slave seperti yang ditunjukkan di bawah ini,
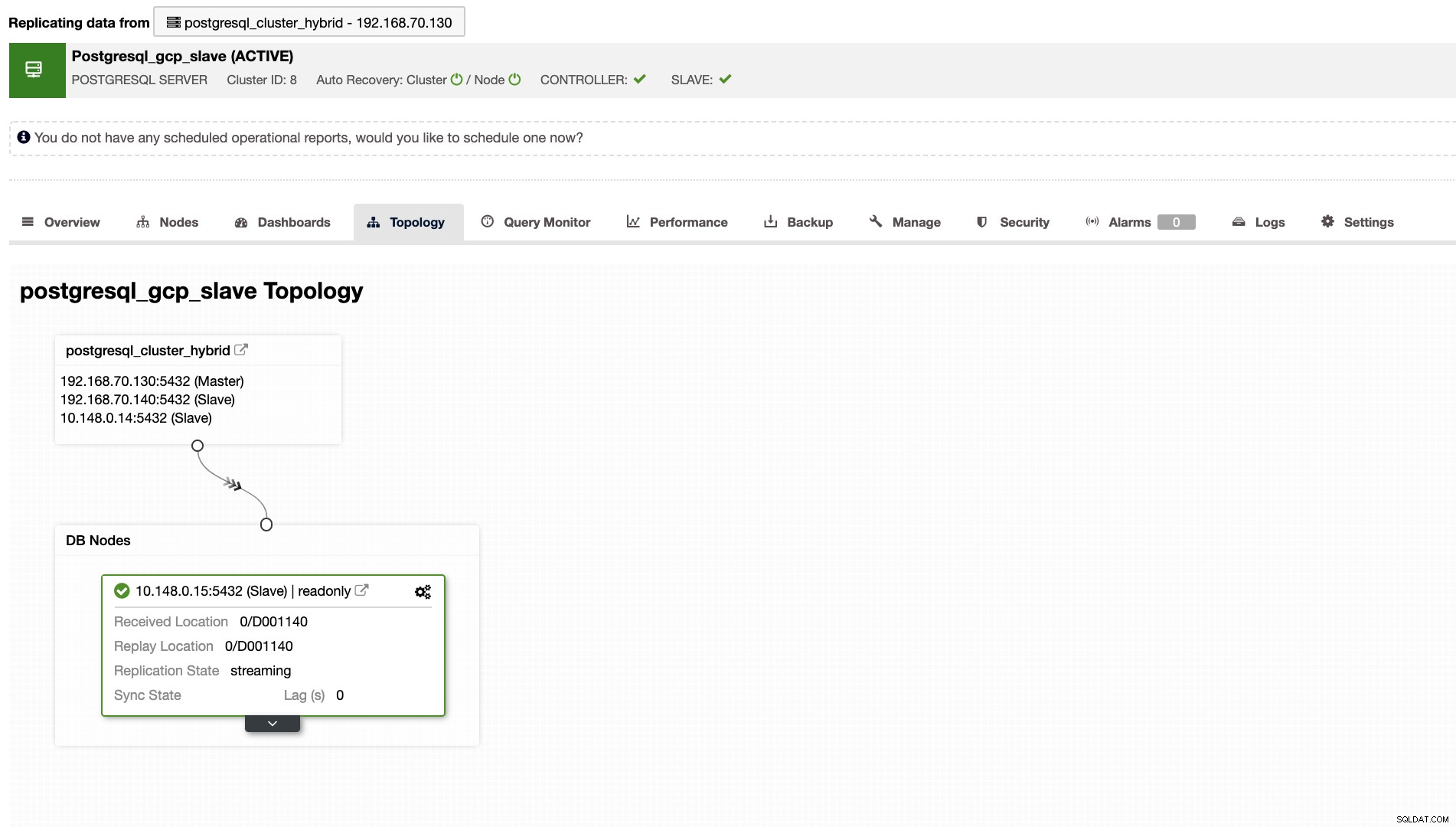
dan Anda dapat tiba dengan hasil akhir seperti yang ditunjukkan di bawah ini,

ClusterControl juga akan menunjukkan topologi cluster yang tepat setiap kali Anda memiliki pengaturan lingkungan cloud hybrid. Lihat berikut di bawah ini,
Sementara di klaster budak, topologi akan menunjukkan pohon asal mengungkapkan masternya. Slave di sini ditampilkan karena terletak di jaringan terpisah yang terutama terletak di Google Cloud, sedangkan master berada di tempat.
Kesimpulan
Dapat diterima bahwa setup cloud hybrid, terutama dengan cluster PostgreSQL menambah kerumitan. Anda harus memiliki alat yang tepat dengan opsi yang ada untuk mendukung perencanaan pemulihan bencana Anda. Ini sangat penting untuk menyelamatkan dan menghindari bisnis Anda dari potensi bencana kerugian finansial dan kehilangan kepercayaan pelanggan. Investasikan pada alat dan keterampilan teknologi Anda yang tepat, dan Anda akan menyelamatkan bisnis Anda dari dampak negatif.