Dalam posting blog sebelumnya, saya menjelaskan secara singkat bagaimana kami mendapatkan angka kinerja yang diterbitkan dalam pengumuman pglogical. Dalam posting blog ini saya ingin membahas batas kinerja solusi replikasi logis secara umum, dan juga bagaimana penerapannya pada pglogical.
replikasi fisik
Pertama, mari kita lihat bagaimana replikasi fisik (dibangun ke dalam PostgreSQL sejak versi 9.0) bekerja. Sosok yang agak disederhanakan dengan dua hanya dua simpul terlihat seperti ini:
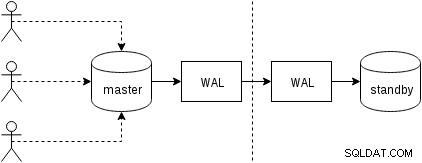
Klien mengeksekusi query pada master node, perubahan ditulis ke log transaksi (WAL) dan disalin melalui jaringan ke WAL pada node standby. Pemulihan pada proses siaga pada siaga kemudian membaca perubahan dari WAL dan menerapkannya ke file data seperti selama pemulihan. Jika standby dalam mode “hot_standby”, klien dapat mengeluarkan query read-only pada node saat ini terjadi.
Ini sangat efisien karena hanya ada sedikit pemrosesan tambahan – perubahan ditransfer dan ditulis ke standby sebagai gumpalan biner buram. Tentu saja, pemulihannya tidak gratis (baik dalam hal CPU dan I/O), tetapi sulit untuk menjadi lebih efisien dari ini.
Potensi kemacetan yang jelas dengan replikasi fisik adalah bandwidth jaringan (mentransfer WAL dari master ke standby) dan juga I/O pada standby, yang mungkin jenuh oleh proses pemulihan yang sering mengeluarkan banyak permintaan I/O acak ( dalam beberapa kasus lebih dari master, tapi jangan masuk ke itu).
replikasi logis
Replikasi logis sedikit lebih rumit, karena tidak berurusan dengan aliran WAL biner buram, tetapi aliran perubahan "logis" (bayangkan pernyataan INSERT, UPDATE atau DELETE, meskipun itu tidak sepenuhnya benar karena kita berurusan dengan representasi terstruktur dari data). Memiliki perubahan logis memungkinkan melakukan hal-hal menarik seperti resolusi konflik, hanya mereplikasi tabel yang dipilih, ke skema yang berbeda atau antara versi yang berbeda (atau bahkan database yang berbeda).
Ada berbagai cara untuk mendapatkan perubahan – pendekatan tradisional adalah dengan menggunakan pemicu yang merekam perubahan ke dalam tabel, dan membiarkan proses kustom terus membaca perubahan tersebut dan menerapkannya di standby dengan menjalankan kueri SQL. Dan semua ini didorong oleh proses daemon eksternal (atau mungkin beberapa proses, berjalan di kedua node), seperti yang diilustrasikan pada gambar berikut

Itulah yang dilakukan slony atau londiste, dan meskipun bekerja dengan cukup baik, itu berarti banyak overhead – misalnya memerlukan menangkap perubahan data dan menulis data beberapa kali (ke tabel asli dan ke tabel "log", dan juga ke WAL untuk kedua tabel tersebut). Kami akan membahas sumber overhead lainnya nanti. Meskipun pglogical perlu mencapai tujuan yang sama, pglogical mencapainya secara berbeda, berkat beberapa fitur yang ditambahkan ke versi PostgreSQL terbaru (sehingga tidak tersedia kembali saat alat lain diimplementasikan):

Artinya, alih-alih mempertahankan log perubahan yang terpisah, pglogical bergantung pada WAL – ini dimungkinkan berkat decoding logis yang tersedia di PostgreSQL 9.4, yang memungkinkan penggalian perubahan logis dari log WAL. Berkat ini pglogical tidak memerlukan pemicu mahal dan biasanya dapat menghindari penulisan data dua kali pada master (kecuali untuk transaksi besar yang mungkin tumpah ke disk).
Setelah mendekode setiap transaksi, itu akan ditransfer ke standby dan proses apply menerapkan perubahannya ke database standby. pglogical tidak menerapkan perubahan dengan menjalankan kueri SQL biasa, tetapi pada tingkat yang lebih rendah, melewati overhead yang terkait dengan penguraian dan perencanaan kueri SQL. Ini memberikan pglogical keuntungan yang signifikan atas solusi yang ada yang semuanya melalui lapisan SQL (sehingga membayar penguraian dan perencanaan).
potensi kemacetan
Jelas, replikasi logis rentan terhadap hambatan yang sama seperti replikasi fisik, yaitu mungkin untuk menjenuhkan jaringan saat mentransfer perubahan, dan I/O saat siaga saat menerapkannya saat siaga. Ada juga cukup banyak overhead karena langkah-langkah tambahan yang tidak ada dalam replikasi fisik.
Kita perlu entah bagaimana mengumpulkan perubahan logis, sementara replikasi fisik hanya meneruskan WAL sebagai aliran byte. Seperti yang telah disebutkan, solusi yang ada biasanya mengandalkan pemicu yang menulis perubahan ke tabel "log". pglogical sebaliknya bergantung pada write-ahead log (WAL) dan decoding logis untuk mencapai hal yang sama, yang lebih murah daripada pemicu dan juga tidak perlu menulis data dua kali dalam banyak kasus (dengan bonus tambahan bahwa kami secara otomatis menerapkan perubahan dalam urutan komit).
Itu tidak berarti tidak ada peluang untuk peningkatan tambahan – misalnya decoding saat ini hanya terjadi setelah transaksi dilakukan, jadi dengan transaksi besar ini dapat meningkatkan lag replikasi. Replikasi fisik hanya mengalirkan perubahan WAL ke node lain dan dengan demikian tidak memiliki batasan ini. Transaksi besar juga dapat tumpah ke disk, menyebabkan duplikasi penulisan, karena hulu harus menyimpannya sampai komit dan dapat dikirim ke hilir.
Pekerjaan di masa mendatang direncanakan untuk memungkinkan pglogical memulai streaming transaksi besar saat transaksi tersebut masih berlangsung di upstream, mengurangi latensi antara commit upstream dan downstream, serta mengurangi amplifikasi penulisan upstream.
Setelah perubahan ditransfer ke standby, proses apply harus benar-benar menerapkannya. Seperti yang disebutkan di bagian sebelumnya, solusi yang ada melakukannya dengan membangun dan menjalankan perintah SQL, sementara pglogical melewati lapisan SQL dan overhead terkait sepenuhnya.
Namun, itu tidak membuat penerapan sepenuhnya gratis karena masih perlu melakukan hal-hal seperti pencarian kunci utama, memperbarui indeks, menjalankan pemicu, dan melakukan berbagai pemeriksaan lainnya. Tapi itu jauh lebih murah daripada pendekatan berbasis SQL. Dalam arti tertentu ini bekerja sangat mirip dengan COPY dan sangat cepat pada tabel sederhana tanpa pemicu, kunci asing, dll.
Dalam semua solusi replikasi logis, setiap langkah tersebut (decoding dan penerapan) terjadi dalam satu proses, jadi waktu CPU cukup terbatas. Ini mungkin hambatan yang paling mendesak di semua solusi yang ada, karena Anda mungkin memiliki mesin yang cukup besar dengan puluhan atau bahkan ratusan klien yang menjalankan kueri secara paralel, tetapi semua itu perlu melalui satu proses decoding perubahan tersebut (pada master) dan satu proses menerapkan perubahan tersebut (dalam keadaan standby).
Batasan "proses tunggal" mungkin agak dilonggarkan dengan menggunakan basis data terpisah, karena setiap basis data ditangani oleh proses terpisah. Dalam hal database tunggal, pekerjaan di masa depan direncanakan untuk diterapkan secara paralel melalui kumpulan pekerja latar belakang untuk mengurangi hambatan ini.