Menggunakan lingkungan multi-cloud atau multi-datacenter berguna untuk topologi geo-distributed atau bahkan untuk rencana pemulihan bencana, dan sebenarnya, itu menjadi lebih populer saat ini, oleh karena itu konsep split-brain juga menjadi lebih penting karena risikonya meningkat dalam skenario semacam ini. Anda harus mencegah perpecahan untuk menghindari potensi kehilangan data atau inkonsistensi data, yang dapat menjadi masalah besar bagi bisnis.
Di blog ini, kita akan melihat apa itu split-brain, dan bagaimana ClusterControl dapat membantu Anda menghindari masalah penting ini.
Apa itu Split-Brain?
Di dunia PostgreSQL, split-brain terjadi ketika lebih dari satu node utama tersedia pada saat yang sama (tanpa alat pihak ketiga untuk memiliki lingkungan multi-master) yang memungkinkan aplikasi untuk menulis di kedua node. Dalam hal ini, Anda akan memiliki informasi yang berbeda pada setiap node, yang menghasilkan inkonsistensi data dalam cluster. Memperbaiki masalah ini mungkin sulit karena Anda harus menggabungkan data, sesuatu yang terkadang tidak mungkin dilakukan.
PostgreSQL Split-Brain dalam Topologi Multi-Cloud
Misalkan Anda memiliki topologi multi-cloud berikut untuk PostgreSQL (yang merupakan topologi yang cukup umum saat ini):
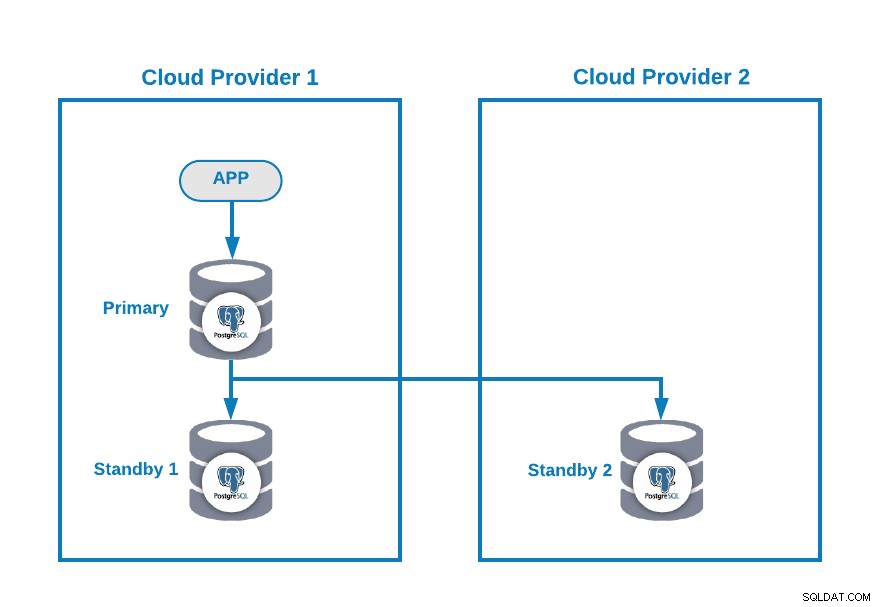
Tentu saja, Anda dapat meningkatkan lingkungan ini dengan, misalnya, menambahkan Server Aplikasi di Penyedia Cloud 2, tetapi dalam kasus ini, mari gunakan konfigurasi dasar ini.
Jika node utama Anda tidak aktif, salah satu node siaga harus dipromosikan sebagai node utama baru dan Anda harus mengubah alamat IP di aplikasi Anda untuk menggunakan node utama baru ini.
Ada berbagai cara untuk membuat ini secara otomatis. Misalnya, Anda dapat menggunakan alamat IP virtual yang ditetapkan untuk node utama Anda dan memantaunya. Jika gagal, promosikan salah satu node siaga dan migrasikan alamat IP virtual ke node utama baru ini, sehingga Anda tidak perlu mengubah apa pun di aplikasi Anda, dan ini dapat dibuat menggunakan skrip atau alat Anda sendiri.
Saat ini, Anda tidak memiliki masalah apa pun, tetapi… jika node utama lama Anda kembali, Anda harus memastikan bahwa Anda tidak akan memiliki dua node utama dalam cluster yang sama pada waktu yang bersamaan .
Metode yang paling umum untuk menghindari situasi ini adalah:
- STONITH:Tembak Node Lain Di Kepala.
- SMITH:Tembak Diriku Di Kepala.
PostgreSQL tidak menyediakan cara apa pun untuk mengotomatiskan proses ini. Anda harus membuatnya sendiri.
Cara Menghindari Split-Brain di PostgreSQL dengan ClusterControl
Sekarang, mari kita lihat bagaimana ClusterControl dapat membantu Anda dengan tugas ini.
Pertama, Anda dapat menggunakannya untuk menerapkan atau mengimpor lingkungan PostgreSQL Multi-Cloud Anda dengan cara yang mudah seperti yang Anda lihat di entri blog ini.
Kemudian, Anda dapat meningkatkan topologi Anda dengan menambahkan Load Balancer (HAProxy), yang juga dapat Anda lakukan menggunakan ClusterControl mengikuti blog ini. Jadi, Anda akan memiliki sesuatu seperti ini:
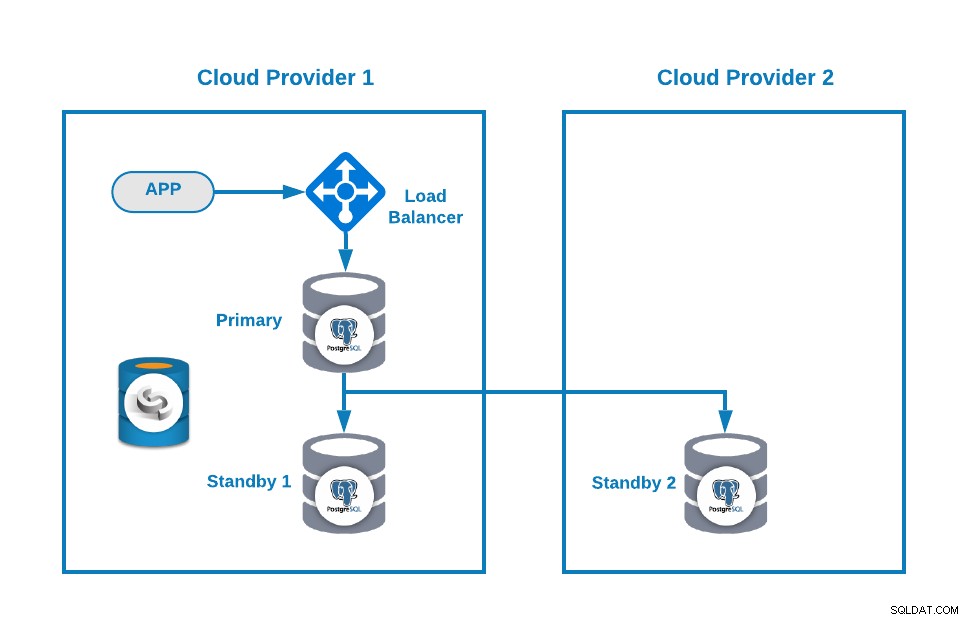
ClusterControl memiliki fitur auto-failover yang mendeteksi kegagalan master dan mempromosikan standby node dengan data terbaru sebagai primer baru. Itu juga gagal selama sisa node siaga untuk mereplikasi dari node utama baru.
HAProxy dikonfigurasi oleh ClusterControl dengan dua port berbeda secara default, satu baca-tulis dan satu baca-saja. Di port baca-tulis, Anda memiliki node utama sebagai online dan node lainnya sebagai offline, dan di port read-only, Anda memiliki node utama dan node siaga online. Dengan cara ini, Anda dapat menyeimbangkan lalu lintas membaca antara node Anda tetapi Anda memastikan bahwa pada saat menulis, port baca-tulis akan digunakan, menulis di node utama yaitu server yang online.
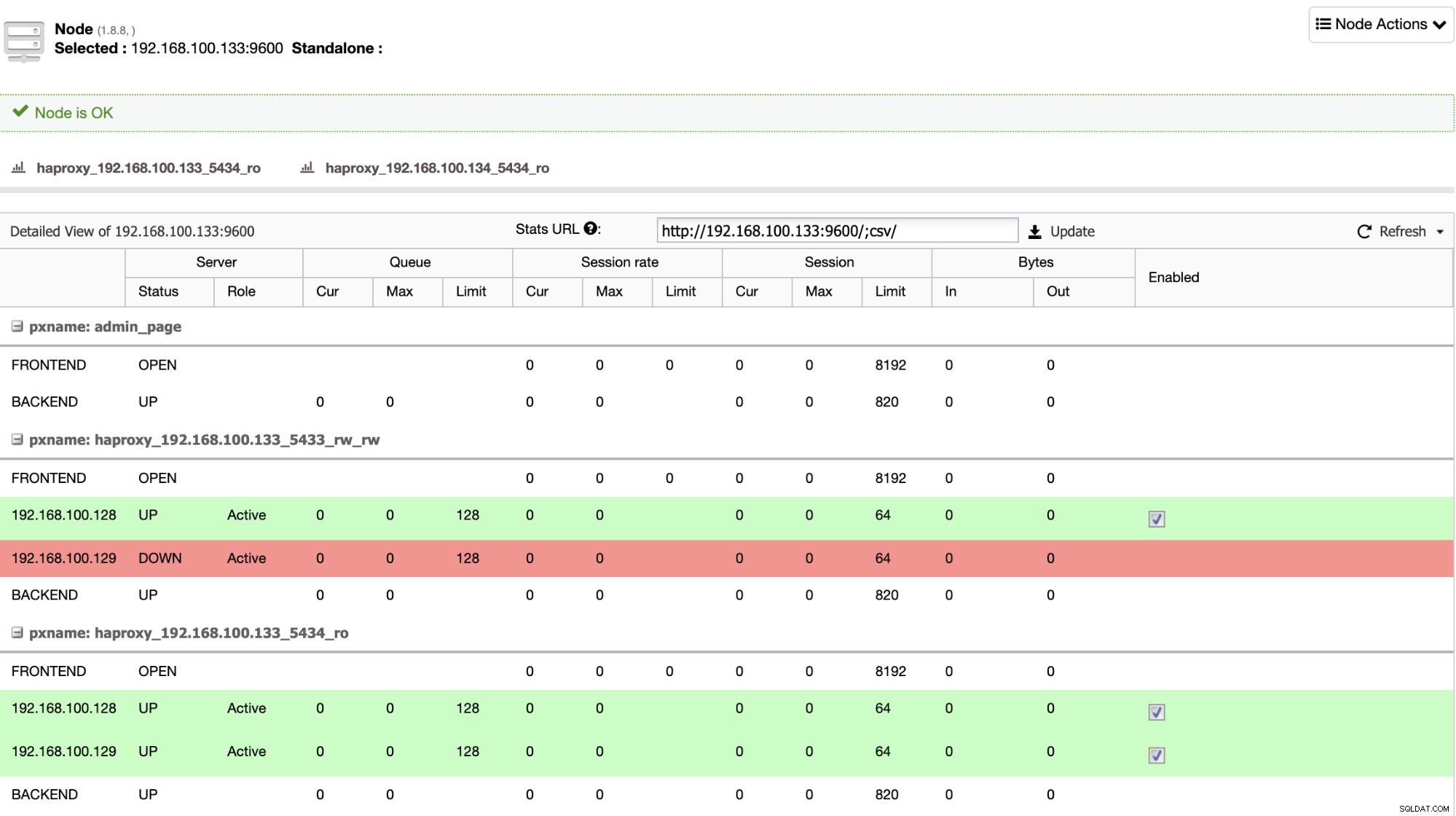
Bila HAProxy mendeteksi bahwa salah satu node Anda, baik primer atau siaga, adalah tidak dapat diakses, secara otomatis menandainya sebagai offline dan tidak memperhitungkan pengiriman lalu lintas ke sana. Pemeriksaan ini dilakukan oleh skrip pemeriksaan kesehatan yang dikonfigurasi oleh ClusterControl pada saat penerapan. Ini memeriksa apakah instance aktif, apakah sedang menjalani pemulihan, atau hanya-baca.
Jika node utama lama Anda kembali, ClusterControl juga akan menghindari memulainya, untuk mencegah potensi split-brain jika Anda memiliki koneksi langsung yang tidak menggunakan Load Balancer, tetapi Anda dapat menambahkannya ke cluster sebagai node siaga secara otomatis atau manual menggunakan ClusterControl UI atau CLI, kemudian Anda dapat mempromosikannya agar memiliki topologi yang sama dengan yang Anda jalankan sebelum masalah.
Kesimpulan
Dengan mengaktifkan opsi "Pemulihan Otomatis", ClusterControl akan melakukan failover otomatis ini serta memberi tahu Anda tentang masalahnya. Dengan cara ini, sistem Anda dapat pulih dalam hitungan detik tanpa campur tangan Anda dan Anda akan terhindar dari perpecahan di lingkungan PostgreSQL Multi-Cloud.
Anda juga dapat meningkatkan lingkungan Ketersediaan Tinggi dengan menambahkan lebih banyak node ClusterControl menggunakan fitur CMON HA yang dijelaskan di blog ini.