Failover adalah kemampuan sistem untuk terus bekerja meskipun terjadi beberapa kegagalan. Ini menunjukkan bahwa fungsi sistem diasumsikan oleh komponen sekunder jika komponen utama gagal atau jika diperlukan. Jadi, jika Anda menerjemahkannya ke lingkungan multi-cloud PostgreSQL, itu berarti bahwa ketika node utama Anda gagal (atau alasan lain seperti yang akan kami sebutkan di bagian selanjutnya) di penyedia cloud utama Anda, Anda harus dapat mempromosikan node siaga di yang kedua untuk menjaga sistem tetap berjalan.
Secara umum, semua penyedia cloud memberi Anda opsi failover di penyedia cloud yang sama, tetapi mungkin saja Anda perlu melakukan failover ke penyedia cloud lain yang berbeda. Tentu saja, Anda dapat melakukannya secara manual, tetapi Anda juga dapat menggunakan beberapa fitur ClusterControl seperti auto-failover atau mempromosikan tindakan budak untuk membuatnya dengan cara yang ramah dan mudah.
Di blog ini, Anda akan melihat mengapa Anda perlu failover, bagaimana melakukannya secara manual, dan bagaimana menggunakan ClusterControl untuk tugas ini. Kami akan menganggap Anda memiliki instalasi ClusterControl yang sedang berjalan dan cluster database Anda sudah dibuat di dua penyedia cloud yang berbeda.
Untuk Apa Failover Digunakan?
Ada beberapa kemungkinan penggunaan failover.
Kegagalan Master
Jika node utama Anda sedang down atau bahkan jika Penyedia Cloud utama Anda mengalami beberapa masalah, Anda harus melakukan failover untuk memastikan ketersediaan sistem Anda. Dalam hal ini, memiliki cara otomatis untuk melakukan ini mungkin diperlukan untuk mengurangi waktu henti.
Migrasi
Jika Anda ingin memigrasikan sistem dari satu Penyedia Cloud ke Penyedia Cloud lainnya dengan meminimalkan waktu henti, Anda dapat menggunakan failover. Anda dapat membuat replika di Penyedia Cloud sekunder, dan setelah disinkronkan, Anda harus menghentikan sistem Anda, mempromosikan replika dan failover Anda, sebelum mengarahkan sistem Anda ke node utama baru di Penyedia Cloud sekunder.
Pemeliharaan
Jika Anda perlu melakukan tugas pemeliharaan pada node utama PostgreSQL, Anda dapat mempromosikan replika, melakukan tugas, dan membangun kembali primer lama sebagai node siaga.
Setelah ini, Anda dapat mempromosikan primer lama, dan ulangi proses pembangunan kembali pada node siaga, kembali ke keadaan awal.
Dengan cara ini, Anda dapat bekerja di server Anda, tanpa menghadapi risiko offline atau kehilangan informasi saat melakukan tugas pemeliharaan apa pun.
Upgrade
Dimungkinkan untuk memutakhirkan versi PostgreSQL Anda (sejak PostgreSQL 10) atau bahkan memutakhirkan Sistem Operasi Anda menggunakan replikasi logis tanpa waktu henti, seperti yang dapat dilakukan dengan mesin lain.
Langkahnya sama dengan bermigrasi ke Penyedia Cloud baru, hanya saja replika Anda akan menggunakan versi PostgreSQL atau OS yang lebih baru dan Anda perlu menggunakan replikasi logis karena Anda tidak dapat menggunakan streaming replikasi antara versi yang berbeda.
Failover bukan hanya tentang database, tetapi juga aplikasinya. Bagaimana mereka tahu database mana yang harus dihubungkan? Anda mungkin tidak ingin memodifikasi aplikasi Anda, karena ini hanya akan memperpanjang waktu henti Anda, jadi, Anda dapat mengonfigurasi Load Balancer yang ketika node utama Anda tidak aktif, node tersebut akan secara otomatis mengarah ke server yang dipromosikan.
Memiliki instance Load Balancer tunggal bukanlah pilihan terbaik karena dapat menjadi satu titik kegagalan. Oleh karena itu, Anda juga dapat menerapkan failover untuk Load Balancer, menggunakan layanan seperti Keepalive. Dengan cara ini, jika Anda memiliki masalah dengan Load Balancer utama Anda, Keepalive akan memigrasikan IP Virtual ke Load Balancer sekunder Anda, dan semuanya terus bekerja secara transparan.
Pilihan lain adalah penggunaan DNS. Dengan mempromosikan node siaga di Penyedia Cloud sekunder, Anda secara langsung mengubah alamat IP hostname yang mengarah ke node utama. Dengan cara ini, Anda tidak perlu memodifikasi aplikasi Anda, dan meskipun tidak dapat dilakukan secara otomatis, ini merupakan alternatif jika Anda tidak ingin menerapkan Load Balancer.
Cara Menggagalkan PostgreSQL Secara Manual
Sebelum melakukan failover manual, Anda harus memeriksa status replikasi. Mungkin saja, ketika Anda perlu failover, node siaga tidak up-to-date, karena kegagalan jaringan, beban tinggi, atau masalah lain, jadi Anda perlu memastikan node siaga Anda memiliki semua (atau hampir semua informasi. Jika Anda memiliki lebih dari satu node siaga, Anda juga harus memeriksa node mana yang paling canggih dan memilihnya untuk failover.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Saat Anda memilih node utama baru, pertama-tama, Anda dapat menjalankan perintah pg_lsclusters untuk mendapatkan informasi cluster:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logKemudian, Anda hanya perlu menjalankan perintah pg_ctlcluster dengan tindakan promo:
$ pg_ctlcluster 12 main promoteDaripada perintah sebelumnya, Anda dapat menjalankan perintah pg_ctl dengan cara ini:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedKemudian, node siaga Anda akan dipromosikan menjadi primer, dan Anda dapat memvalidasinya dengan menjalankan kueri berikut di node utama baru Anda:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Jika hasilnya adalah “f”, itu adalah simpul utama baru Anda.
Sekarang, Anda harus mengubah alamat IP basis data utama di aplikasi Anda, Load Balancer, DNS, atau implementasi yang Anda gunakan yang, seperti yang kami sebutkan, mengubahnya secara manual akan meningkatkan waktu henti. Anda juga perlu memastikan konektivitas Anda antara penyedia yang dapat berfungsi dengan baik, aplikasi dapat mengakses node utama baru, pengguna aplikasi memiliki hak istimewa untuk mengaksesnya dari penyedia cloud yang berbeda, dan Anda harus membangun kembali node siaga di remote atau bahkan di penyedia cloud lokal, untuk mereplikasi dari primer baru, jika tidak, Anda tidak akan memiliki opsi failover baru jika diperlukan.
Cara Failover PostgreSQL Menggunakan ClusterControl
ClusterControl memiliki sejumlah fitur yang terkait dengan replikasi PostgreSQL dan failover otomatis. Kami akan menganggap Anda telah menginstal server ClusterControl dan mengelola lingkungan PostgreSQL Multi-Cloud Anda.
Dengan ClusterControl, Anda dapat menambahkan node standby atau node Load Balancer sebanyak yang Anda butuhkan tanpa batasan IP jaringan. Artinya, node siaga tidak perlu berada di jaringan node utama yang sama atau bahkan di penyedia cloud yang sama. Dalam hal failover, ClusterControl memungkinkan Anda melakukannya secara manual atau otomatis.
Kegagalan Manual
Untuk melakukan failover manual, buka ClusterControl -> Pilih Cluster -> Nodes, dan di Node Actions dari salah satu node standby Anda, pilih "Promote Slave".
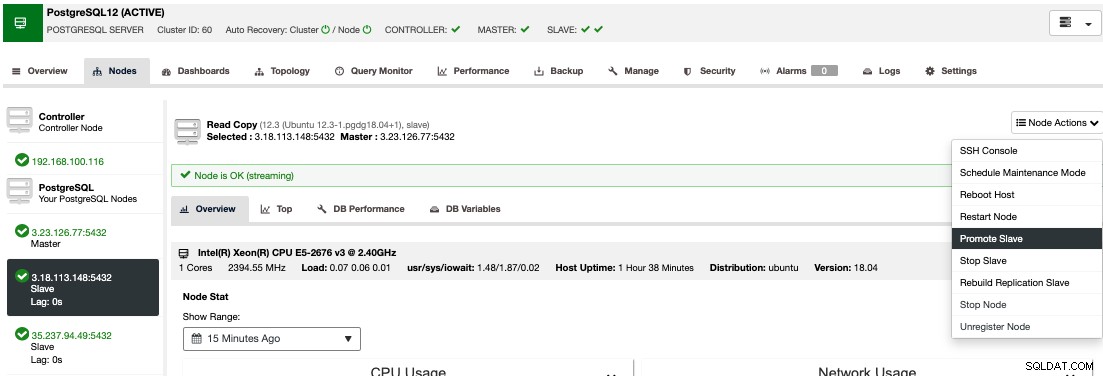
Dengan cara ini, setelah beberapa detik, node siaga Anda menjadi yang utama, dan apa yang utama Anda sebelumnya, berubah menjadi siaga. Jadi, jika replika Anda berada di penyedia cloud lain, node utama baru Anda akan ada di sana, aktif dan berjalan.
Kegagalan Otomatis
Dalam kasus failover otomatis, ClusterControl mendeteksi kegagalan di node utama dan mempromosikan node siaga dengan data terkini sebagai primer baru. Ini juga berfungsi pada node siaga lainnya agar mereka mereplikasi dari primer baru ini.

Dengan mengaktifkan opsi “Pemulihan Otomatis”, ClusterControl akan melakukan failover otomatis sebagai serta memberi tahu Anda tentang masalahnya. Dengan cara ini, sistem Anda dapat pulih dalam hitungan detik, dan tanpa campur tangan Anda.
ClusterControl menawarkan kemungkinan untuk mengonfigurasi daftar putih/daftar hitam untuk menentukan bagaimana Anda ingin server Anda diperhitungkan (atau tidak diperhitungkan) saat memutuskan kandidat utama.
ClusterControl juga melakukan beberapa pemeriksaan selama proses failover, misalnya, secara default, jika Anda berhasil memulihkan node utama lama yang gagal, node tersebut tidak akan diperkenalkan kembali secara otomatis ke cluster, baik sebagai primer maupun sebagai standby, Anda harus melakukannya secara manual. Ini akan menghindari kemungkinan kehilangan data atau inkonsistensi jika standby Anda (yang Anda promosikan) tertunda pada saat kegagalan. Anda mungkin juga ingin menganalisis masalah secara mendetail, tetapi saat menambahkannya ke klaster, Anda mungkin akan kehilangan informasi diagnostik.
Load Balancer
Seperti yang kami sebutkan sebelumnya, Load Balancer adalah alat penting untuk dipertimbangkan untuk failover Anda, terutama jika Anda ingin menggunakan failover otomatis dalam topologi database Anda.
Agar failover menjadi transparan bagi pengguna dan aplikasi, Anda memerlukan komponen di antaranya, karena tidak cukup untuk mempromosikan node utama baru. Untuk ini, Anda dapat menggunakan HAProxy + Keepalive.
Untuk mengimplementasikan solusi ini dengan ClusterControl, buka Cluster Actions -> Add Load Balancer -> HAProxy di cluster PostgreSQL Anda. Jika Anda ingin menerapkan failover untuk Load Balancer Anda, Anda harus mengonfigurasi setidaknya dua instance HAProxy, dan kemudian, Anda dapat mengonfigurasi Keepalived (Cluster Actions -> Add Load Balancer -> Keepalive). Anda dapat menemukan informasi lebih lanjut tentang penerapan ini di entri blog ini.
Setelah ini, Anda akan memiliki topologi berikut:

HAProxy dikonfigurasi secara default dengan dua port berbeda, satu baca-tulis dan satu hanya-baca.
Di port baca-tulis, Anda memiliki node utama sebagai online dan node lainnya sebagai offline. Di port read-only, Anda memiliki node utama dan node siaga online. Dengan cara ini, Anda dapat menyeimbangkan lalu lintas membaca antar node. Saat menulis, port baca-tulis akan digunakan, yang akan menunjuk ke node utama saat ini.

Ketika HAProxy mendeteksi bahwa salah satu node, baik primer atau siaga, adalah tidak dapat diakses, secara otomatis menandainya sebagai offline. HAProxy tidak akan mengirimkan lalu lintas apa pun ke sana. Pemeriksaan ini dilakukan oleh skrip pemeriksaan kesehatan yang dikonfigurasi oleh ClusterControl pada saat penerapan. Ini memeriksa apakah instance aktif, apakah sedang menjalani pemulihan, atau hanya-baca.
Saat ClusterControl mempromosikan node utama baru, HAProxy menandai yang lama sebagai offline (untuk kedua port) dan menempatkan node yang dipromosikan online di port baca-tulis. Dengan cara ini, sistem Anda terus beroperasi secara normal.
Jika HAProxy aktif (yang telah menetapkan alamat IP Virtual yang terhubung dengan sistem Anda) gagal, Keepalived memigrasikan IP Virtual ini ke HAProxy pasif secara otomatis. Artinya, sistem Anda dapat terus berfungsi secara normal.
Replikasi Cluster-to-Cluster di Cloud
Untuk memiliki lingkungan Multi-Cloud, Anda dapat menggunakan tindakan ClusterControl Add Slave di atas cluster PostgreSQL Anda, tetapi juga fitur Replikasi Cluster-to-Cluster. Saat ini, fitur ini memiliki batasan untuk PostgreSQL yang memungkinkan Anda hanya memiliki satu node jarak jauh, tetapi kami sedang berupaya untuk menghapus batasan itu segera di rilis mendatang.
Untuk menerapkannya, Anda dapat memeriksa bagian “Replikasi Cluster-to-Cluster di Cloud” di entri blog ini.

Jika sudah terpasang, Anda dapat mempromosikan kluster jarak jauh yang akan menghasilkan cluster PostgreSQL independen dengan node utama yang berjalan di penyedia cloud sekunder.

Jadi, jika Anda membutuhkannya, Anda akan menjalankan cluster yang sama di penyedia cloud baru hanya dalam beberapa detik.
Kesimpulan
Memiliki proses failover otomatis adalah wajib jika Anda ingin mengurangi waktu henti, dan juga menggunakan teknologi yang berbeda seperti HAProxy dan Keepalived akan meningkatkan failover ini.
Fitur ClusterControl yang kami sebutkan di atas akan memungkinkan Anda untuk dengan cepat melakukan failover antara Penyedia Cloud yang berbeda dan mengelola penyiapan dengan cara yang mudah dan bersahabat.
Hal terpenting yang harus dipertimbangkan sebelum melakukan proses failover antara Penyedia Cloud yang berbeda adalah konektivitas. Anda harus memastikan bahwa aplikasi atau koneksi database Anda akan bekerja seperti biasa menggunakan penyedia cloud utama tetapi juga sekunder jika terjadi failover, dan, untuk alasan keamanan, Anda harus membatasi lalu lintas hanya dari sumber yang diketahui, jadi hanya antara Cloud Penyedia dan tidak mengizinkannya dari sumber eksternal mana pun.