Masalah jeda replikasi di PostgreSQL bukanlah masalah yang tersebar luas di sebagian besar penyiapan. Meskipun, itu dapat terjadi dan ketika itu terjadi, itu dapat memengaruhi pengaturan produksi Anda. PostgreSQL dirancang untuk menangani banyak utas, seperti paralelisme kueri atau menerapkan utas pekerja untuk menangani tugas tertentu berdasarkan nilai yang ditetapkan dalam konfigurasi. PostgreSQL dirancang untuk menangani beban berat dan stres, tetapi terkadang (karena konfigurasi yang buruk) server Anda mungkin masih bermasalah.
Mengidentifikasi jeda replikasi di PostgreSQL bukanlah tugas yang rumit untuk dilakukan, tetapi ada beberapa pendekatan berbeda untuk melihat masalahnya. Di blog ini, kita akan melihat hal-hal apa saja yang harus diperhatikan saat replikasi PostgreSQL Anda lambat.
Jenis Replikasi di PostgreSQL
Sebelum masuk ke topik, mari kita lihat dulu bagaimana replikasi di PostgreSQL berkembang karena ada beragam pendekatan dan solusi saat menangani replikasi.
Siaga hangat untuk PostgreSQL diimplementasikan dalam versi 8.2 (pada tahun 2006) dan didasarkan pada metode pengiriman log. Ini berarti bahwa catatan WAL dipindahkan langsung dari satu server database ke server lain untuk diterapkan, atau hanya pendekatan analog dengan PITR, atau sangat mirip dengan apa yang Anda lakukan dengan rsync.
Pendekatan ini, meskipun lama, masih digunakan sampai sekarang dan beberapa institusi sebenarnya lebih menyukai pendekatan yang lebih tua ini. Pendekatan ini menerapkan pengiriman log berbasis file dengan mentransfer catatan WAL satu file (segmen WAL) pada satu waktu. Meskipun memiliki sisi negatifnya; Kegagalan besar pada server utama, transaksi yang belum dikirim akan hilang. Ada jendela untuk kehilangan data (Anda dapat menyetelnya dengan menggunakan parameter archive_timeout, yang dapat disetel serendah beberapa detik, tetapi setelan rendah seperti itu akan secara substansial meningkatkan bandwidth yang diperlukan untuk pengiriman file).
Di PostgreSQL versi 9.0, Replikasi Streaming diperkenalkan. Fitur ini memungkinkan kami untuk tetap lebih up-to-date jika dibandingkan dengan pengiriman log berbasis file. Pendekatannya adalah dengan mentransfer catatan WAL (file WAL terdiri dari catatan WAL) dengan cepat (hanya pengiriman log berbasis catatan), antara server master dan satu atau beberapa server siaga. Protokol ini tidak perlu menunggu file WAL diisi, tidak seperti pengiriman log berbasis file. Dalam praktiknya, proses yang disebut penerima WAL, yang berjalan di server siaga, akan terhubung ke server utama menggunakan koneksi TCP/IP. Di server utama, ada proses lain bernama pengirim WAL. Perannya adalah mengirimkan registri WAL ke server siaga saat terjadi.
Pengaturan Replikasi Asinkron dalam replikasi streaming dapat menimbulkan masalah seperti kehilangan data atau kelambatan slave, jadi versi 9.1 memperkenalkan replikasi sinkron. Dalam replikasi sinkron, setiap komit dari transaksi tulis akan menunggu hingga konfirmasi diterima bahwa komit telah ditulis ke disk log tulis-depan dari server utama dan server siaga. Metode ini meminimalkan kemungkinan kehilangan data, karena untuk itu kita membutuhkan master dan standby untuk gagal pada saat yang bersamaan.
Kelemahan yang jelas dari konfigurasi ini adalah waktu respons untuk setiap transaksi tulis meningkat, karena kita harus menunggu sampai semua pihak merespons. Tidak seperti MySQL, tidak ada dukungan seperti di lingkungan semi-sinkron MySQL, itu akan gagal kembali ke asinkron jika batas waktu telah terjadi. Jadi di Dengan PostgreSQL, waktu untuk komit adalah (minimal) perjalanan pulang pergi antara primer dan siaga. Transaksi read-only tidak akan terpengaruh oleh itu.
Seiring berkembangnya, PostgreSQL terus meningkat namun replikasinya beragam. Misalnya, Anda dapat menggunakan replikasi asinkron streaming fisik atau menggunakan replikasi streaming logis. Keduanya dipantau secara berbeda meskipun menggunakan pendekatan yang sama saat mengirim data melalui replikasi, yang masih streaming replikasi. Untuk detail lebih lanjut, periksa manual untuk berbagai jenis solusi di PostgreSQL saat menangani replikasi.
Penyebab Replikasi PostgreSQL Terlambat
Seperti yang didefinisikan di blog kami sebelumnya, lag replikasi adalah biaya penundaan untuk transaksi atau operasi yang dihitung berdasarkan perbedaan waktu eksekusi antara primer/master terhadap siaga/slave simpul.
Karena PostgreSQL menggunakan replikasi streaming, PostgreSQL dirancang untuk menjadi cepat karena perubahan dicatat sebagai serangkaian catatan log (byte-by-byte) yang dicegat oleh penerima WAL kemudian menulis catatan log ini ke file WAL. Kemudian proses startup oleh PostgreSQL memutar ulang data dari segmen WAL tersebut dan replikasi streaming dimulai. Di PostgreSQL, jeda replikasi dapat terjadi oleh faktor-faktor berikut:
- Masalah jaringan
- Tidak dapat menemukan segmen WAL dari yang utama. Biasanya, ini disebabkan oleh perilaku pos pemeriksaan di mana segmen WAL diputar atau didaur ulang
- Node sibuk (utama dan siaga). Dapat disebabkan oleh proses eksternal atau beberapa kueri buruk yang disebabkan oleh penggunaan sumber daya yang intensif
- Masalah perangkat keras atau perangkat keras yang buruk menyebabkan kelambatan
- Konfigurasi yang buruk di PostgreSQL seperti sejumlah kecil max_wal_senders yang disetel saat memproses banyak permintaan transaksi (atau volume perubahan yang besar).
Yang Harus Diperhatikan Dengan Replikasi PostgreSQL Lag
Replikasi PostgreSQL masih beragam tetapi pemantauan kesehatan replikasi tidak rumit namun tidak rumit. Dalam pendekatan ini, kami akan menampilkan didasarkan pada penyiapan siaga utama dengan replikasi streaming asinkron. Replikasi logis tidak dapat menguntungkan sebagian besar kasus yang sedang kita diskusikan di sini tetapi tampilan pg_stat_subscription dapat membantu Anda mengumpulkan informasi. Namun, kami tidak akan fokus pada hal itu di blog ini.
Menggunakan Tampilan pg_stat_replication
Pendekatan yang paling umum adalah menjalankan kueri yang mereferensikan tampilan ini di node utama. Ingat, Anda hanya dapat mengumpulkan informasi dari node utama menggunakan tampilan ini. Tampilan ini berisi definisi tabel berikut berdasarkan PostgreSQL 11 seperti yang ditunjukkan di bawah ini:
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | Di mana bidang didefinisikan sebagai (termasuk versi PG <10),
- pid :ID proses dari proses walsender
- usesysid :OID pengguna yang digunakan untuk replikasi Streaming.
- nama pengguna :Nama pengguna yang digunakan untuk replikasi Streaming
- nama_aplikasi :Nama aplikasi terhubung ke master
- client_addr :Alamat replikasi standby/streaming
- namahost_klien :Nama host siaga.
- port_klien :nomor port TCP yang standby berkomunikasi dengan pengirim WAL
- backend_start :Waktu mulai saat PL terhubung ke Master.
- backend_xmin :cakrawala xmin standby dilaporkan oleh hot_standby_feedback.
- negara bagian :Status pengirim WAL saat ini yaitu streaming
- sent_lsn /lokasi_terkirim :Lokasi transaksi terakhir dikirim ke standby.
- write_lsn /tulis_lokasi :Transaksi terakhir ditulis di disk saat standby
- flush_lsn /flush_location :Transaksi terakhir flush pada disk saat standby.
- replay_lsn /replay_location :Transaksi terakhir flush pada disk saat standby.
- tulis_lag :Waktu yang berlalu selama WAL berkomitmen dari primer ke siaga (tetapi belum berkomitmen dalam siaga)
- flush_lag :Waktu yang berlalu selama WAL berkomitmen dari primer ke siaga (WAL telah di-flush tetapi belum diterapkan)
- replay_lag :Waktu yang berlalu selama WAL berkomitmen dari primer ke siaga (komit penuh dalam node siaga)
- sinkronisasi_prioritas :Prioritas server siaga dipilih sebagai siaga sinkron
- sync_state :Sinkronisasi Status siaga (apakah asinkron atau sinkron).
Contoh kueri akan terlihat seperti berikut di PostgreSQL 9.6,
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncIni pada dasarnya memberi tahu Anda blok lokasi apa di segmen WAL yang telah ditulis, dihapus, atau diterapkan. Ini memberi Anda gambaran terperinci tentang status replikasi.
Kueri untuk Digunakan di Siaga Node
Dalam node siaga, ada fungsi yang didukung yang dapat Anda mitigasi menjadi kueri dan memberikan gambaran umum tentang kesehatan replikasi siaga Anda. Untuk melakukan ini, Anda dapat menjalankan kueri berikut di bawah ini (permintaan didasarkan pada versi PG> 10),
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Dalam versi yang lebih lama, Anda dapat menggunakan kueri berikut:
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06Apa yang dikatakan kueri? Fungsi didefinisikan sesuai di sini,
- pg_is_in_recovery ():(boolean) Benar jika pemulihan masih berlangsung.
- pg_last_wal_receive_lsn ()/pg_last_xlog_receive_location(): (pg_lsn) Lokasi log write-ahead diterima dan disinkronkan ke disk dengan streaming replikasi.
- pg_last_wal_replay_lsn ()/pg_last_xlog_replay_location(): (pg_lsn) Lokasi log write-ahead terakhir yang diputar ulang selama pemulihan. Jika pemulihan masih berlangsung, ini akan meningkat secara monoton.
- pg_last_xact_replay_timestamp (): (stempel waktu dengan zona waktu) Dapatkan stempel waktu transaksi terakhir yang diputar ulang selama pemulihan.
Menggunakan beberapa matematika dasar, Anda dapat menggabungkan fungsi-fungsi ini. Fungsi yang paling umum digunakan yang digunakan oleh DBA adalah,
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
atau dalam versi PG <10,
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;Meskipun kueri ini telah dipraktikkan dan digunakan oleh DBA. Namun, itu tidak memberi Anda pandangan yang akurat tentang lag. Mengapa? Mari kita bahas ini di bagian selanjutnya.
Mengidentifikasi Lag yang Disebabkan oleh Absennya Segmen WAL
Node siaga PostgreSQL, yang berada dalam mode pemulihan, tidak melaporkan kepada Anda status pasti tentang apa yang terjadi pada replikasi Anda. Tidak, kecuali Anda melihat log PG, Anda dapat mengumpulkan informasi tentang apa yang terjadi. Tidak ada kueri yang dapat Anda jalankan untuk menentukan ini. Dalam kebanyakan kasus, organisasi dan bahkan institusi kecil datang dengan perangkat lunak pihak ketiga untuk memberi tahu mereka saat alarm dinaikkan.
Salah satunya adalah ClusterControl, yang menawarkan kemampuan pengamatan, mengirimkan peringatan saat alarm dinaikkan atau memulihkan node Anda jika terjadi bencana atau malapetaka. Mari kita ambil skenario ini, kluster replikasi streaming asinkron siaga utama saya telah gagal. Bagaimana Anda tahu jika ada yang salah? Mari kita gabungkan yang berikut ini:
Langkah 1:Tentukan apakah Ada Lag
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Langkah 2:Tentukan Segmen WAL yang Diterima Dari Primer dan Bandingkan dengan Siaga Node
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70Untuk versi PG <10 yang lebih lama, gunakan pg_current_xlog_location.
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Sepertinya itu terlihat buruk.
Langkah 3:Tentukan Seberapa Buruknya
Sekarang, mari kita campurkan rumus dari langkah #1 dan langkah #2 dan dapatkan perbedaannya. Bagaimana melakukannya, PostgreSQL memiliki fungsi yang disebut pg_wal_lsn_diff yang didefinisikan sebagai,
pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (location pg_lsn, location pg_lsn): (numerik) Menghitung perbedaan antara dua lokasi log write-ahead
Sekarang, mari kita gunakan untuk menentukan lag. Anda dapat menjalankannya di simpul PG mana pun, karena kami hanya akan memberikan nilai statis:
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104Mari kita perkirakan berapa 1800913104, yang tampaknya sekitar 1,6GiB mungkin tidak ada di node siaga,
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68Terakhir, Anda dapat melanjutkan atau bahkan sebelum kueri melihat log seperti menggunakan tail -5f untuk mengikuti dan memeriksa apa yang terjadi. Lakukan ini untuk kedua node utama/siaga. Dalam contoh ini, kita akan melihat ada masalah,
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
...Saat menghadapi masalah ini, lebih baik untuk membangun kembali node standby Anda. Di ClusterControl, semudah satu klik. Cukup buka bagian Nodes/Topology, dan buat ulang node seperti di bawah ini:
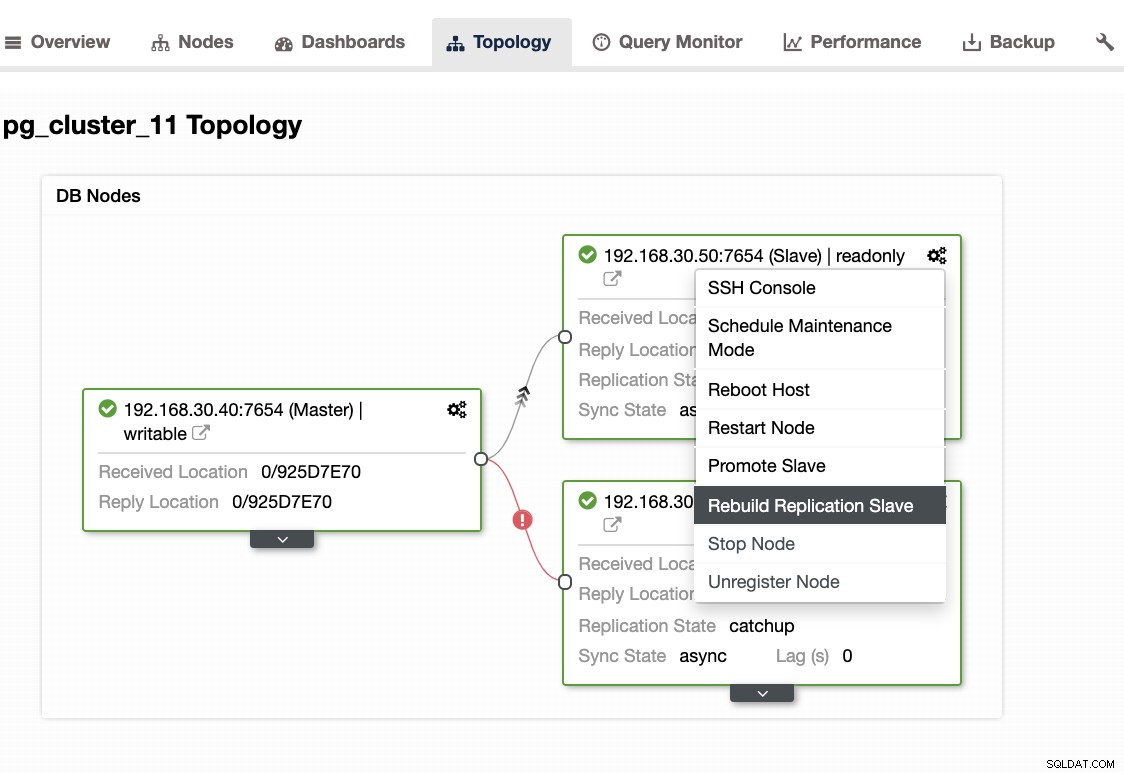
Hal Lain yang Perlu Diperiksa
Anda dapat menggunakan pendekatan yang sama di blog kami sebelumnya (di MySQL), menggunakan alat sistem seperti kombinasi ps, top, iostat, netstat. Misalnya, Anda juga bisa mendapatkan segmen WAL yang dipulihkan saat ini dari node siaga,
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027Bagaimana ClusterControl Dapat Membantu?
ClusterControl menawarkan cara yang efisien untuk memantau node database Anda dari node utama hingga node slave. Saat membuka tab Ikhtisar, Anda sudah memiliki tampilan kesehatan replikasi Anda:
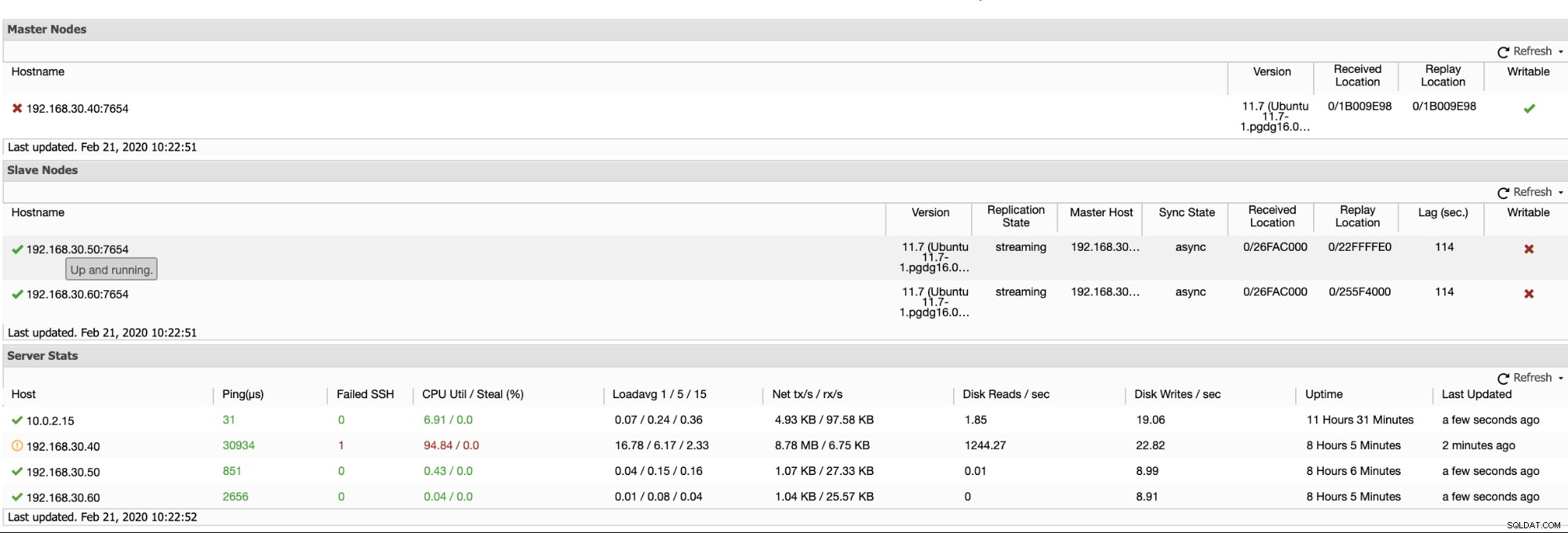
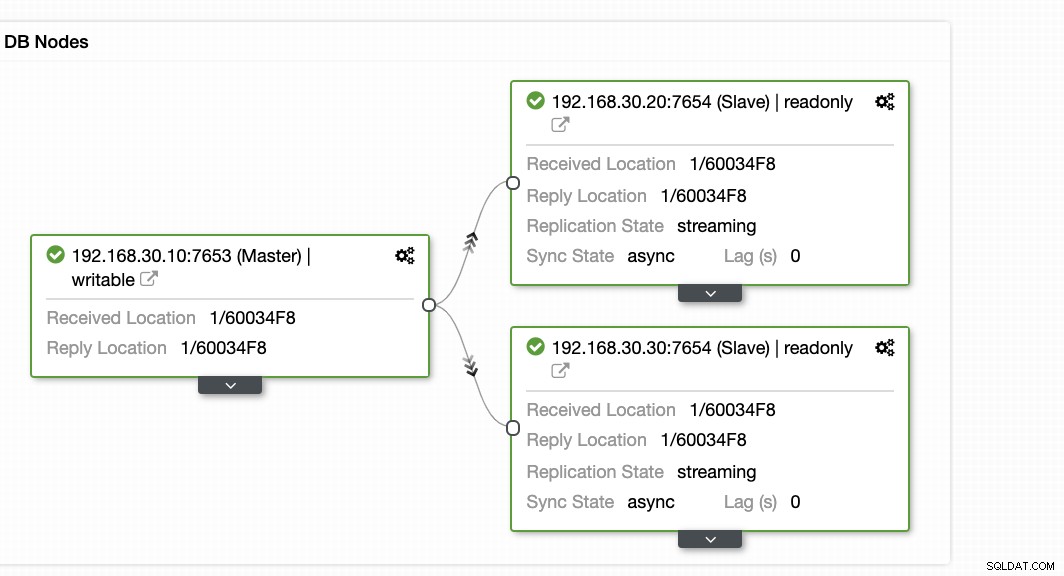
Pada dasarnya, dua tangkapan layar di atas menampilkan bagaimana kesehatan replikasi dan apa yang sedang terjadi segmen WAL. Itu sama sekali tidak. ClusterControl juga menunjukkan aktivitas terkini dari apa yang terjadi dengan Cluster Anda.
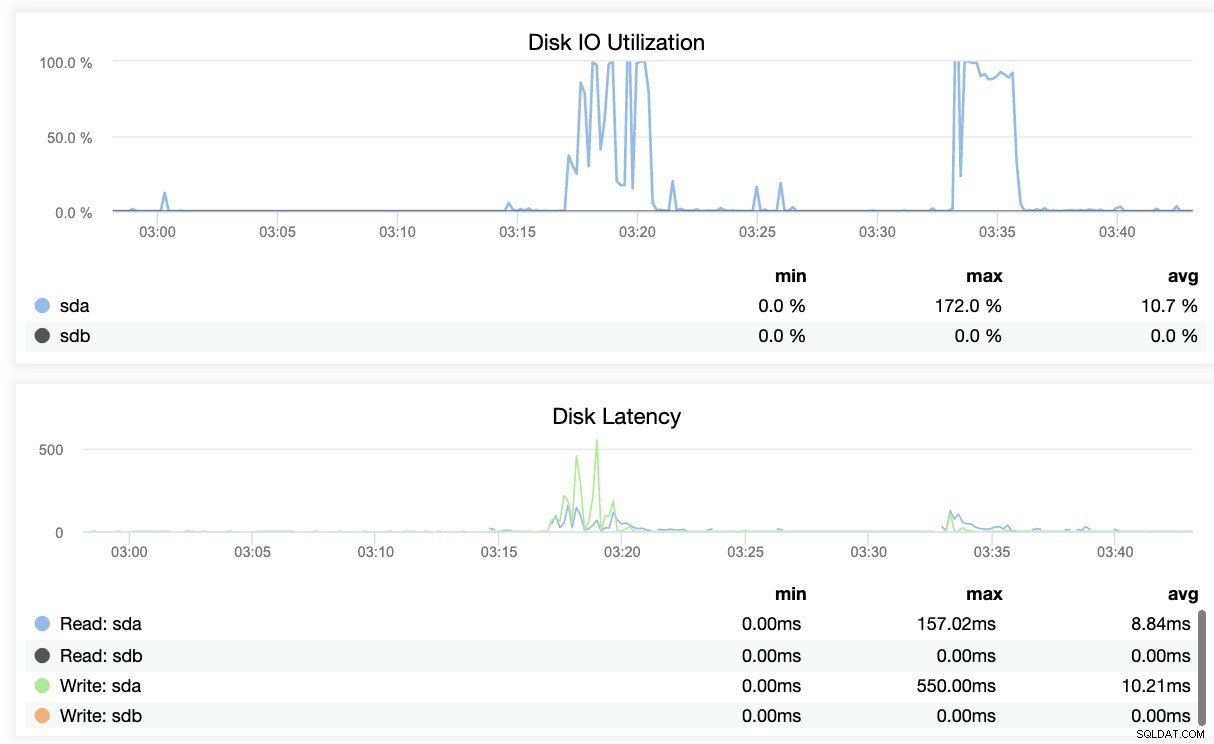
Kesimpulan
Memantau kesehatan replikasi di PostgreSQL dapat berakhir dengan pendekatan yang berbeda selama Anda dapat memenuhi kebutuhan Anda. Menggunakan alat pihak ketiga dengan observabilitas yang dapat memberi tahu Anda jika terjadi bencana adalah rute sempurna Anda, baik sumber terbuka atau perusahaan. Yang paling penting adalah, Anda memiliki rencana pemulihan bencana dan kelangsungan bisnis yang direncanakan sebelum masalah seperti itu.