Artikel ini adalah bagian ke-7 dari seri tentang ekspresi tabel bernama. Dalam Bagian 5 dan Bagian 6 saya membahas aspek konseptual dari ekspresi tabel umum (CTEs). Bulan ini dan selanjutnya fokus saya beralih ke pertimbangan pengoptimalan CTE.
Saya akan mulai dengan cepat meninjau kembali konsep tidak bersarang dari ekspresi tabel bernama dan menunjukkan penerapannya pada CTE. Saya kemudian akan mengalihkan fokus saya ke pertimbangan persistensi. Saya akan berbicara tentang aspek persistensi CTE rekursif dan nonrekursif. Saya akan menjelaskan kapan masuk akal untuk tetap menggunakan CTE versus kapan sebenarnya lebih masuk akal untuk bekerja dengan tabel sementara.
Dalam contoh saya, saya akan terus menggunakan database sampel TSQLV5 dan PerformanceV5. Anda dapat menemukan skrip yang membuat dan mengisi TSQLV5 di sini , dan diagram ER-nya di sini. Anda dapat menemukan skrip yang membuat dan mengisi PerformanceV5 di sini.
Pergantian/penghapusan sarang
Di Bagian 4 dari seri ini, yang berfokus pada optimalisasi tabel turunan, saya menjelaskan proses unnesting/substitusi ekspresi tabel. Saya menjelaskan bahwa ketika SQL Server mengoptimalkan kueri yang melibatkan tabel turunan, itu menerapkan aturan transformasi ke pohon awal operator logis yang dihasilkan oleh parser, mungkin menggeser berbagai hal melintasi batas ekspresi tabel yang semula. Hal ini terjadi pada tingkat ketika Anda membandingkan rencana untuk kueri menggunakan tabel turunan dengan rencana untuk kueri yang langsung bertentangan dengan tabel dasar yang mendasari di mana Anda menerapkan logika unnesting sendiri, mereka terlihat sama. Saya juga menjelaskan teknik untuk mencegah unnesting menggunakan filter TOP dengan jumlah baris yang sangat banyak sebagai input. Saya mendemonstrasikan beberapa kasus di mana teknik ini cukup berguna—satu di mana tujuannya adalah untuk menghindari kesalahan dan lainnya untuk alasan pengoptimalan.
Versi TL;DR dari substitusi/unnesting CTE adalah bahwa prosesnya sama dengan tabel turunan. Jika Anda senang dengan pernyataan ini, Anda dapat melewati bagian ini dan langsung melompat ke bagian berikutnya tentang Kegigihan. Anda tidak akan melewatkan hal penting yang belum pernah Anda baca sebelumnya. Namun, jika Anda seperti saya, Anda mungkin ingin bukti bahwa memang demikian. Kemudian, Anda mungkin ingin melanjutkan membaca bagian ini dan menguji kode yang saya gunakan saat saya meninjau kembali contoh kunci yang tidak bersarang yang sebelumnya saya tunjukkan dengan tabel turunan dan mengonversinya untuk menggunakan CTE.
Di Bagian 4 saya mendemonstrasikan kueri berikut (kami akan menyebutnya Kueri 1):
GUNAKAN TSQLV5; SELECT orderid, orderdate FROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3 WHERE orderdate>='20180401';
Kueri melibatkan tiga tingkat bersarang dari tabel turunan, ditambah kueri luar. Setiap level memfilter rentang tanggal pesanan yang berbeda. Rencana untuk Query 1 ditunjukkan pada Gambar 1.
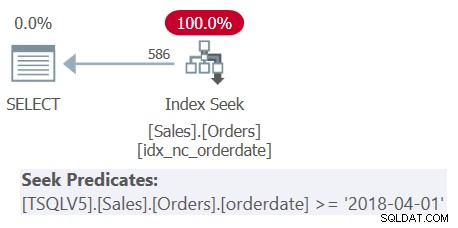 Gambar 1:Rencana eksekusi untuk Kueri 1
Gambar 1:Rencana eksekusi untuk Kueri 1
Rencana pada Gambar 1 dengan jelas menunjukkan bahwa unnesting dari tabel turunan terjadi karena semua predikat filter digabung menjadi predikat filter encompassing tunggal.
Saya menjelaskan bahwa Anda dapat mencegah proses unnesting dengan menggunakan filter TOP yang berarti (sebagai lawan dari TOP 100 PERCENT) dengan jumlah baris yang sangat besar sebagai input, seperti yang ditunjukkan oleh kueri berikut (kami akan menyebutnya Kueri 2):
SELECT orderid, orderdate FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>=20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3 WHERE orderdate>='20180401';
Rencana untuk Query 2 ditunjukkan pada Gambar 2.
 Gambar 2:Rencana eksekusi untuk Kueri 2
Gambar 2:Rencana eksekusi untuk Kueri 2
Rencana tersebut dengan jelas menunjukkan bahwa unnesting tidak terjadi karena Anda dapat melihat batas tabel turunan secara efektif.
Mari kita coba contoh yang sama menggunakan CTE. Berikut Kueri 1 yang dikonversi untuk menggunakan CTE:
WITH C1 AS ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ), C2 AS ( SELECT * FROM C1 WHERE orderdate>='20180201' ), C3 AS ( SELECT * FROM C2 WHERE orderdate>=' 20180301' ) PILIH orderid, orderdate FROM C3 WHERE orderdate>='20180401';
Anda mendapatkan rencana yang sama persis seperti yang ditunjukkan sebelumnya pada Gambar 1, di mana Anda dapat melihat bahwa unnesting terjadi.
Berikut Kueri 2 yang dikonversi untuk menggunakan CTE:
WITH C1 AS ( SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE orderdate>='20180101' ), C2 AS ( SELECT TOP (9223372036854775807) * FROM C1 WHERE orderdate>='20180201' ), C3 AS ( SELECT TOP (9223372036854775807) * FROM C2 WHERE orderdate>='20180301' ) SELECT orderid, orderdate FROM C3 WHERE orderdate>='20180401';
Anda mendapatkan rencana yang sama seperti yang ditunjukkan sebelumnya pada Gambar 2, di mana Anda dapat melihat bahwa unnesting tidak terjadi.
Selanjutnya, mari kita tinjau kembali dua contoh yang saya gunakan untuk mendemonstrasikan kepraktisan teknik untuk mencegah unnesting—hanya kali ini menggunakan CTE.
Mari kita mulai dengan kueri yang salah. Kueri berikut mencoba mengembalikan baris pesanan dengan diskon yang lebih besar dari diskon minimum, dan kebalikan dari diskon lebih besar dari 10:
PILIH orderid, productid, discount FROM Sales.OrderDetails WHERE discount> (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount> 10.0;
Diskon minimum tidak boleh negatif, melainkan nol atau lebih tinggi. Jadi, Anda mungkin berpikir bahwa jika sebuah baris memiliki diskon nol, predikat pertama harus bernilai salah, dan bahwa hubungan pendek harus mencegah upaya untuk mengevaluasi predikat kedua, sehingga menghindari kesalahan. Namun, ketika Anda menjalankan kode ini, Anda mendapatkan kesalahan pembagian dengan nol:
Msg 8134, Level 16, State 1, Line 99 Ditemukan kesalahan pembagian dengan nol.
Masalahnya adalah bahwa meskipun SQL Server mendukung konsep hubung singkat pada tingkat pemrosesan fisik, tidak ada jaminan bahwa itu akan mengevaluasi predikat filter dalam urutan tertulis dari kiri ke kanan. Upaya umum untuk menghindari kesalahan tersebut adalah dengan menggunakan ekspresi tabel bernama yang menangani bagian logika pemfilteran yang ingin Anda evaluasi terlebih dahulu, dan memiliki kueri luar yang menangani logika pemfilteran yang ingin Anda evaluasi kedua. Inilah solusi yang dicoba menggunakan CTE:
WITH C AS ( SELECT * FROM Sales.OrderDetails WHERE discount> (SELECT MIN(discount) FROM Sales.OrderDetails) ) SELECT orderid, productid, discount FROM C WHERE 1.0 / discount> 10.0;
Sayangnya, pelepasan ekspresi tabel menghasilkan persamaan logis dengan kueri solusi asli, dan ketika Anda mencoba menjalankan kode ini, Anda mendapatkan kesalahan pembagian dengan nol lagi:
Msg 8134, Level 16, State 1, Line 108 Ditemukan kesalahan pembagian dengan nol.
Dengan menggunakan trik kami dengan filter TOP di kueri dalam, Anda mencegah penghapusan ekspresi tabel, seperti:
WITH C AS ( SELECT TOP (9223372036854775807) * FROM Sales.OrderDetails WHERE discount> (SELECT MIN(discount) FROM Sales.OrderDetails) ) SELECT orderid, productid, discount FROM C WHERE 1.0 / discount> 10.0;
Kali ini kode berhasil dijalankan tanpa kesalahan.
Mari kita lanjutkan ke contoh di mana Anda menggunakan teknik untuk mencegah unnesting untuk alasan pengoptimalan. Kode berikut hanya mengembalikan pengirim dengan tanggal pemesanan maksimum pada atau setelah 1 Januari 2018:
GUNAKAN PerformanceV5; DENGAN C AS ( SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) SELECT shipperid, maxod FROM C WHERE maxod> ='20180101';
Jika Anda bertanya-tanya mengapa tidak menggunakan solusi yang lebih sederhana dengan kueri yang dikelompokkan dan filter HAVING, ini ada hubungannya dengan kepadatan kolom pengirim. Tabel Pesanan memiliki 1.000.000 pesanan, dan pengiriman pesanan tersebut ditangani oleh lima pengirim, artinya rata-rata, setiap pengirim menangani 20% dari pesanan. Rencana untuk kueri yang dikelompokkan yang menghitung tanggal pemesanan maksimum per pengirim akan memindai semua 1.000.000 baris, menghasilkan ribuan halaman yang dibaca. Memang, jika Anda hanya menyorot kueri dalam CTE (kami akan menyebutnya Kueri 3) menghitung tanggal pesanan maksimum per pengirim dan memeriksa rencana pelaksanaannya, Anda akan mendapatkan rencana yang ditunjukkan pada Gambar 3.
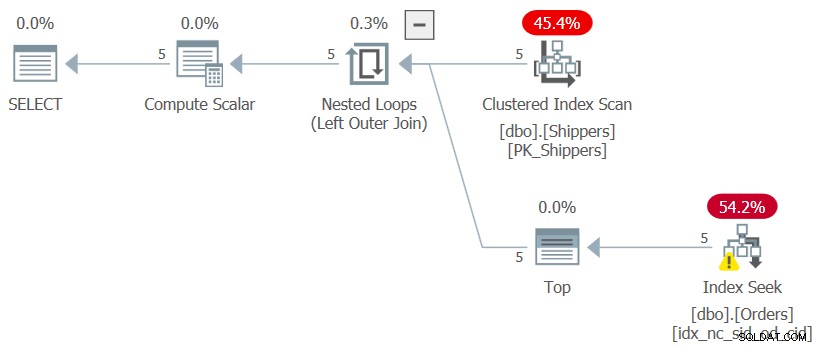 Gambar 3:Rencana eksekusi untuk Kueri 3
Gambar 3:Rencana eksekusi untuk Kueri 3
Paket memindai lima baris dalam indeks berkerumun di Pengirim. Per pengirim, rencana menerapkan pencarian terhadap indeks penutup pada Pesanan, di mana (pengirim, tanggal pesanan) adalah kunci utama indeks, langsung ke baris terakhir di setiap bagian pengirim di tingkat daun untuk menarik tanggal pesanan maksimum untuk saat ini pengirim. Karena kami hanya memiliki lima pengirim, hanya ada lima operasi pencarian indeks, menghasilkan rencana yang sangat efisien. Berikut adalah ukuran kinerja yang saya dapatkan ketika saya menjalankan kueri dalam CTE:
durasi:0 md, CPU:0 md, dibaca:15
Namun, ketika Anda menjalankan solusi lengkap (kami akan menyebutnya Query 4), Anda mendapatkan rencana yang sama sekali berbeda, seperti yang ditunjukkan pada Gambar 4.
 Gambar 4:Rencana eksekusi untuk Kueri 4
Gambar 4:Rencana eksekusi untuk Kueri 4
Apa yang terjadi adalah bahwa SQL Server menghapus ekspresi tabel, mengonversi solusi menjadi setara logis dari kueri yang dikelompokkan, menghasilkan pemindaian indeks penuh pada Pesanan. Berikut adalah angka kinerja yang saya dapatkan untuk solusi ini:
durasi:316 md, CPU:281 md, dibaca:3854
Apa yang kita butuhkan di sini adalah untuk mencegah terjadinya unnesting dari ekspresi tabel, sehingga kueri dalam akan dioptimalkan dengan pencarian terhadap indeks pada Pesanan, dan agar kueri luar hanya menghasilkan penambahan operator Filter di rencana. Anda mencapai ini menggunakan trik kami dengan menambahkan filter TOP ke kueri dalam, seperti ini (kami akan menyebut solusi ini Kueri 5):
WITH C AS ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) SELECT shipperid , maxod FROM C WHERE maxod>='20180101';
Rencana untuk solusi ini ditunjukkan pada Gambar 5.
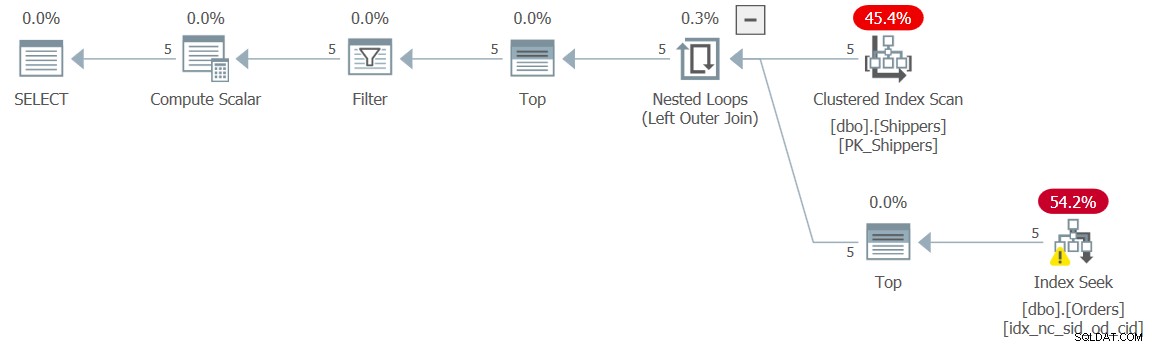 Gambar 5:Rencana eksekusi untuk Kueri 5
Gambar 5:Rencana eksekusi untuk Kueri 5
Rencana tersebut menunjukkan bahwa efek yang diinginkan telah tercapai, dan dengan demikian angka kinerja mengkonfirmasi hal ini:
durasi:0 md, CPU:0 md, dibaca:15
Jadi, pengujian kami mengonfirmasi bahwa SQL Server menangani substitusi/pelepasan CTE seperti halnya untuk tabel turunan. Ini berarti Anda tidak boleh memilih salah satu dari yang lain karena alasan pengoptimalan, melainkan karena perbedaan konseptual yang penting bagi Anda, seperti yang dibahas di Bagian 5.
Kegigihan
Kesalahpahaman umum tentang CTE dan ekspresi tabel bernama secara umum adalah bahwa mereka berfungsi sebagai semacam kendaraan persistensi. Beberapa orang berpikir bahwa SQL Server mempertahankan kumpulan hasil kueri dalam ke tabel kerja, dan bahwa kueri luar benar-benar berinteraksi dengan tabel kerja tersebut. Dalam praktiknya, CTE nonrekursif reguler dan tabel turunan tidak bertahan. Saya menjelaskan logika tidak bersarang yang diterapkan SQL Server saat mengoptimalkan kueri yang melibatkan ekspresi tabel, menghasilkan rencana yang berinteraksi langsung dengan tabel dasar yang mendasarinya. Perhatikan bahwa pengoptimal dapat memilih untuk menggunakan tabel kerja untuk mempertahankan kumpulan hasil antara jika masuk akal untuk melakukannya karena alasan kinerja, atau lainnya, seperti perlindungan Halloween. Ketika melakukannya, Anda melihat operator Spool atau Index Spool dalam paket. Namun, pilihan tersebut tidak terkait dengan penggunaan ekspresi tabel dalam kueri.
CTE rekursif
Ada beberapa pengecualian di mana SQL Server mempertahankan data ekspresi tabel. Salah satunya adalah penggunaan tampilan yang diindeks. Jika Anda membuat indeks berkerumun pada tampilan, SQL Server mempertahankan hasil kueri dalam yang ditetapkan dalam indeks berkerumun tampilan, dan menjaganya tetap sinkron dengan perubahan apa pun di tabel dasar yang mendasarinya. Pengecualian lainnya adalah ketika Anda menggunakan kueri rekursif. SQL Server perlu mempertahankan kumpulan hasil perantara dari jangkar dan kueri rekursif dalam spool sehingga dapat mengakses kumpulan hasil putaran terakhir yang diwakili oleh referensi rekursif ke nama CTE setiap kali anggota rekursif dieksekusi.
Untuk mendemonstrasikan ini, saya akan menggunakan salah satu kueri rekursif dari Bagian 6 dalam seri ini.
Gunakan kode berikut untuk membuat tabel Karyawan di database tempdb, mengisinya dengan data sampel, dan membuat indeks pendukung:
SET NOCOUNT AKTIF; GUNAKAN tempdb; DROP TABLE JIKA ADA dbo.Karyawan; GO CREATE TABLE dbo.Karyawan ( empid INT NOT NULL CONSTRAINT PK_Kunci UTAMA Karyawan, mgrid INT NULL CONSTRAINT FK_Employees_Employees REFERENSI dbo.Karyawan, empname VARCHAR(25) MONEY NOT NULL);MONEY NOT NULL); INSERT INTO dbo.Employees(empid, mgrid, empname, salary) VALUES(1, NULL, 'David' , $10000.00), (2, 1, 'Eitan' , $7000,00), (3, 1, 'Ina' , $7500.00) , (4, 2, 'Seraph' , $50000.00), (5, 2, 'Jiru' , $5500.00), (6, 2, 'Steve' , $4500.00), (7, 3, 'Aaron' , $50000.00), ( 8, 5, 'Lilach' , $3500,00), (9, 7, 'Rita' , $3000,00), (10, 5, 'Sean' , $3000,00), (11, 7, 'Gabriel', $3000,00), (12, 9, 'Emilia' , $2000,00), (13, 9, 'Michael', $2000,00), (14, 9, 'Didi' , $1500,00); BUAT INDEKS UNIK idx_unc_mgrid_empid PADA dbo.Karyawan(mgrid, empid) INCLUDE(empname, salary); PERGI
Saya menggunakan CTE rekursif berikut untuk mengembalikan semua bawahan dari manajer akar subpohon input, menggunakan karyawan 3 sebagai manajer input dalam contoh ini:
MENNYATAKAN @root SEBAGAI INT =3; DENGAN C AS ( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid ) PILIH empid, mgrid, empname FROM C;
Rencana untuk query ini (kami akan menyebutnya Query 6) ditunjukkan pada Gambar 6.
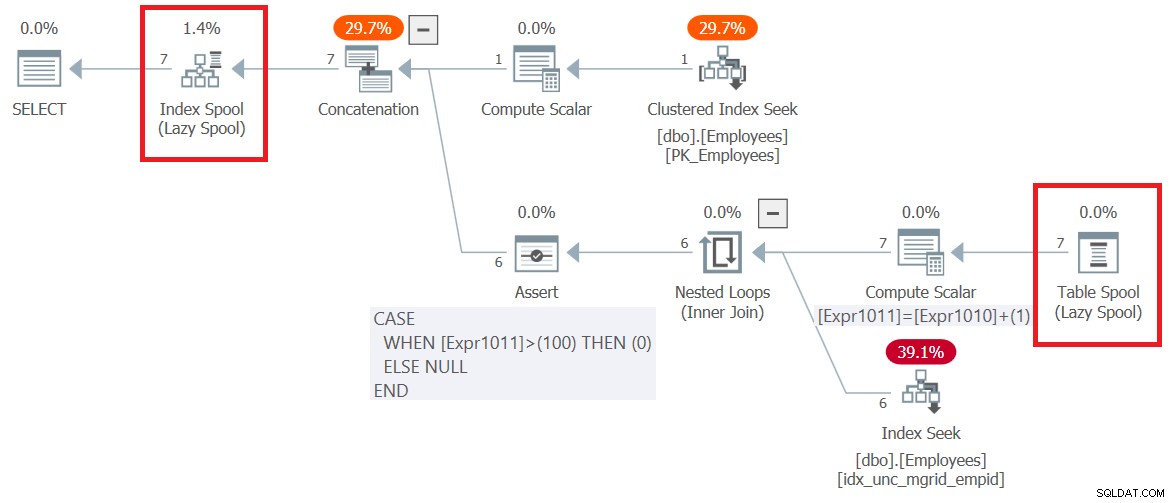 Gambar 6:Rencana eksekusi untuk Kueri 6
Gambar 6:Rencana eksekusi untuk Kueri 6
Perhatikan bahwa hal pertama yang terjadi dalam rencana, di sebelah kanan simpul SELECT root, adalah pembuatan tabel kerja berbasis pohon-B yang diwakili oleh operator Index Spool. Bagian atas rencana menangani logika anggota jangkar. Ini menarik baris input karyawan dari indeks berkerumun pada Karyawan dan menulisnya ke spool. Bagian bawah dari rencana mewakili logika anggota rekursif. Ini dieksekusi berulang kali sampai mengembalikan set hasil kosong. Input luar ke operator Nested Loops memperoleh manajer dari putaran sebelumnya dari spool (operator Table Spool). Input dalam menggunakan operator Index Seek terhadap indeks nonclustered yang dibuat pada Employee(mgrid, empid) untuk mendapatkan bawahan langsung manajer dari babak sebelumnya. Kumpulan hasil dari setiap eksekusi bagian bawah rencana juga ditulis ke spool indeks. Perhatikan bahwa secara keseluruhan, 7 baris ditulis ke spool. Satu dikembalikan oleh anggota jangkar, dan 6 lainnya dikembalikan oleh semua eksekusi anggota rekursif.
Selain itu, menarik untuk diperhatikan bagaimana rencana menangani batas maxrecursion default, yaitu 100. Perhatikan bahwa operator Compute Scalar bawah terus meningkatkan penghitung internal yang disebut Expr1011 sebesar 1 dengan setiap eksekusi anggota rekursif. Kemudian, operator Assert menyetel tanda ke nol jika penghitung ini melebihi 100. Jika ini terjadi, SQL Server menghentikan eksekusi kueri dan menghasilkan kesalahan.
Kapan tidak bertahan
Kembali ke CTE nonrekursif, yang biasanya tidak bertahan, Anda harus mencari tahu dari perspektif pengoptimalan kapan sebaiknya menggunakannya versus alat persistensi aktual seperti tabel sementara dan variabel tabel sebagai gantinya. Saya akan membahas beberapa contoh untuk menunjukkan kapan setiap pendekatan lebih optimal.
Mari kita mulai dengan contoh di mana CTE bekerja lebih baik daripada tabel sementara. Itu sering terjadi ketika Anda tidak memiliki beberapa evaluasi CTE yang sama, mungkin hanya solusi modular di mana setiap CTE dievaluasi hanya sekali. Kode berikut (kami akan menyebutnya Kueri 7) mengkueri tabel Pesanan di database Performa, yang memiliki 1.000.000 baris, untuk mengembalikan tahun pesanan di mana lebih dari 70 pelanggan berbeda melakukan pemesanan:
GUNAKAN PerformanceV5; DENGAN C1 AS ( SELECT YEAR(orderdate) AS orderyear, custid FROM dbo.Orders ), C2 AS ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts FROM C1 GROUP BY orderyear ) SELECT orderyear, numcusts FROM C2 WHERE numcusts> 70; /pra>Kueri ini menghasilkan keluaran berikut:
jumlah pesanan tahun ----------- ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000Saya menjalankan kode ini menggunakan Edisi Pengembang SQL Server 2019, dan mendapatkan paket yang ditunjukkan pada Gambar 7.
Gambar 7:Rencana eksekusi untuk Kueri 7
Perhatikan bahwa pelepasan CTE menghasilkan rencana yang menarik data dari indeks pada tabel Pesanan, dan tidak melibatkan spooling set hasil kueri dalam CTE. Saya mendapatkan angka kinerja berikut saat menjalankan kueri ini di mesin saya:
durasi:265 ms, CPU:828 ms, membaca:3970, menulis:0Sekarang mari kita coba solusi yang menggunakan tabel sementara alih-alih CTE (kami akan menyebutnya Solusi 8), seperti:
PILIH TAHUN(tanggal pemesanan) SEBAGAI tahun pemesanan, custid KE #T1 DARI dbo.Orders; PILIH orderyear, COUNT(DISTINCT custid) SEBAGAI numcusts KE #T2 DARI #T1 GROUP BY orderyear; PILIH orderyear, numcusts FROM #T2 WHERE numcusts> 70; DROP TABLE #T1, #T2;Rencana untuk solusi ini ditunjukkan pada Gambar 8.
Gambar 8:Rencana Solusi 8
Perhatikan operator Tabel Sisipkan yang menulis kumpulan hasil ke tabel sementara #T1 dan #T2. Yang pertama sangat mahal karena menulis 1.000.000 baris ke #T1. Berikut adalah angka performa yang saya dapatkan untuk eksekusi ini:
durasi:454 ms, CPU:1517 ms, membaca:14359, menulis:359Seperti yang Anda lihat, solusi dengan CTE jauh lebih optimal.
Kapan harus bertahan
Jadi, apakah solusi modular yang hanya melibatkan satu evaluasi dari setiap CTE selalu lebih disukai daripada menggunakan tabel sementara? Belum tentu. Dalam solusi berbasis CTE yang melibatkan banyak langkah, dan menghasilkan rencana yang rumit di mana pengoptimal perlu menerapkan banyak perkiraan kardinalitas di banyak titik berbeda dalam rencana, Anda bisa berakhir dengan akumulasi ketidakakuratan yang menghasilkan pilihan suboptimal. Salah satu teknik untuk mencoba mengatasi kasus seperti itu adalah dengan mempertahankan beberapa hasil antara yang menempatkan diri Anda ke dalam tabel sementara, dan bahkan membuat indeks pada tabel tersebut jika diperlukan, memberikan pengoptimal awal yang baru dengan statistik baru, meningkatkan kemungkinan perkiraan kardinalitas kualitas yang lebih baik yang semoga mengarah pada pilihan yang lebih optimal. Apakah ini lebih baik daripada solusi yang tidak menggunakan tabel sementara adalah sesuatu yang perlu Anda uji. Kadang-kadang pengorbanan biaya ekstra untuk tetap mempertahankan hasil antara demi mendapatkan perkiraan kardinalitas kualitas yang lebih baik akan sepadan.
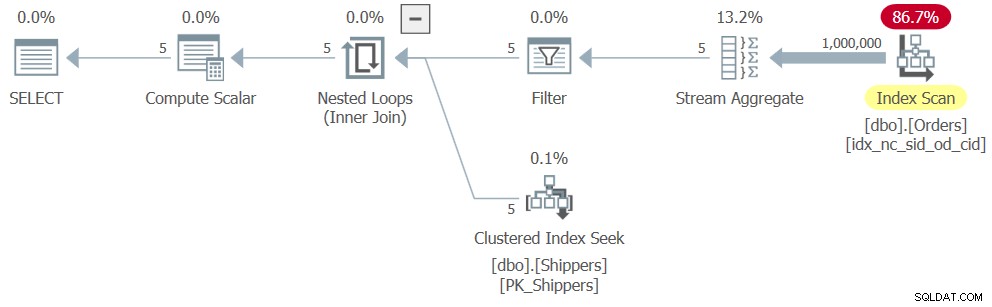
Kasus umum lainnya di mana menggunakan tabel sementara adalah pendekatan yang lebih disukai adalah ketika solusi berbasis CTE memiliki beberapa evaluasi dari CTE yang sama, dan kueri dalam CTE cukup mahal. Pertimbangkan solusi berbasis CTE berikut (kami akan menyebutnya Kueri 9), yang cocok untuk setiap tahun dan bulan pesanan dengan tahun dan bulan pesanan yang berbeda yang memiliki jumlah pesanan terdekat:
WITH OrdCount AS ( SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth, COUNT(*) AS numorders FROM dbo.Orders GROUP BY YEAR(orderdate), MONTH(orderdate) ) SELECT O1.orderyear, O1 .ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 From OrdCount AS O1 CROSS APPLY ( PILIH TOP (1) O2.orderyear, O2.ordermonth, O2.numorders FROM OrdCount AS O2 WHERE O2.orderyear <> O1.orderyear ATAU O2.ordermonth <> O1.ordermonth ORDER BY ABS(O1.numorders - O2.numorders), O2.orderyear, O2.ordermonth ) SEBAGAI O2;Kueri ini menghasilkan keluaran berikut:
orderyear ordermonth numberorderyear2 ordermonth2 numberorder2 ----------- ----------- ----------- -------- --- ----------- ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 4 20561 2016 9 20554 2018 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2016 2 19844 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 21199 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 21211 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 201 6 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11 20494 2016 10 21222 2018 3 21222 2018 11 20575 2016 6 20571 2016 12 21212 2016 3 21211 2019 12 20184 2018 9 20487 2017 1 21223 2016 10 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 21185 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 baris terpengaruh)Rencana untuk Query 9 ditunjukkan pada Gambar 9.
Gambar 9:Rencana Eksekusi untuk Kueri 9
Bagian atas paket sesuai dengan contoh CTE OrdCount yang disebut sebagai O1. Referensi ini menghasilkan satu evaluasi dari CTE OrdCount. Bagian rencana ini menarik baris dari indeks pada tabel Pesanan, mengelompokkannya menurut tahun dan bulan, dan menggabungkan jumlah pesanan per grup, menghasilkan 49 baris. Bagian bawah rencana sesuai dengan tabel turunan berkorelasi O2, yang diterapkan per baris dari O1, karenanya dieksekusi 49 kali. Setiap eksekusi mengkueri CTE OrdCount, dan karenanya menghasilkan evaluasi terpisah dari kueri dalam CTE. Anda dapat melihat bahwa bagian bawah paket memindai semua baris dari indeks pada Pesanan, mengelompokkan, dan menggabungkannya. Pada dasarnya Anda mendapatkan total 50 evaluasi CTE, menghasilkan 50 kali pemindaian 1.000.000 baris dari Pesanan, mengelompokkan dan menggabungkannya. Kedengarannya bukan solusi yang sangat efisien. Berikut adalah ukuran kinerja yang saya dapatkan saat menjalankan solusi ini di mesin saya:
durasi:16 detik, CPU:56 detik, membaca:130404, menulis:0Mengingat bahwa hanya ada beberapa lusin bulan yang terlibat, yang akan jauh lebih efisien adalah menggunakan tabel sementara untuk menyimpan hasil dari satu aktivitas yang mengelompokkan dan mengagregasi baris dari Pesanan, dan kemudian memiliki input luar dan dalam dari operator APPLY berinteraksi dengan tabel sementara. Inilah solusinya (kami akan menyebutnya Solusi 10) menggunakan tabel sementara alih-alih CTE:
PILIH TAHUN(tanggal pemesanan) SEBAGAI tahun pesanan, BULAN(tanggal pemesanan) SEBAGAI bulan pesanan, COUNT(*) SEBAGAI numorders INTO #OrdCount FROM dbo.Orders GROUP BY YEAR(orderdate), MONTH(orderdate); PILIH O1.orderyear, O1.ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 FROM #OrdCount AS O1 CROSS APPLY ( PILIH TOP (1) O2.orderyear, O2.ordermonth , O2.numorders FROM #OrdCount AS O2 WHERE O2.orderyear <> O1.orderyear OR O2.ordermonth <> O1.ordermonth ORDER BY ABS(O1.numorders - O2.numorders), O2.orderyear, O2.ordermonth ) AS O2; DROP TABLE #OrdCount;Di sini tidak ada gunanya mengindeks tabel sementara, karena filter TOP didasarkan pada perhitungan dalam spesifikasi pemesanannya, dan karenanya pengurutan tidak dapat dihindari. Namun, bisa jadi dalam kasus lain, dengan solusi lain, juga relevan bagi Anda untuk mempertimbangkan pengindeksan tabel sementara Anda. Bagaimanapun, rencana untuk solusi ini ditunjukkan pada Gambar 10.
Gambar 10:Rencana eksekusi untuk Solusi 10
Amati dalam rencana atas bagaimana pengangkatan berat yang melibatkan pemindaian 1.000.000 baris, mengelompokkan dan menggabungkannya, hanya terjadi sekali. 49 baris ditulis ke tabel sementara #OrdCount, dan kemudian denah bawah berinteraksi dengan tabel sementara untuk input luar dan dalam dari operator Nested Loops, yang menangani logika operator APPLY.
Berikut adalah angka kinerja yang saya dapatkan untuk eksekusi solusi ini:
durasi:0,392 detik, CPU:0,5 detik, membaca:3636, menulis:3Ini lebih cepat dalam urutan besarnya daripada solusi berbasis CTE.
Apa selanjutnya?
Pada artikel ini saya memulai cakupan pertimbangan pengoptimalan yang terkait dengan CTE. Saya menunjukkan bahwa proses unnesting/substitusi yang terjadi dengan tabel turunan bekerja dengan cara yang sama dengan CTE. Saya juga membahas fakta bahwa CTE nonrekursif tidak bertahan dan menjelaskan bahwa ketika persistensi merupakan faktor penting untuk kinerja solusi Anda, Anda harus menanganinya sendiri dengan menggunakan alat seperti tabel sementara dan variabel tabel. Bulan depan saya akan melanjutkan diskusi dengan membahas aspek tambahan pengoptimalan CTE.