Saat ini, sudah umum untuk melihat sejumlah besar data dalam database perusahaan, tetapi tergantung pada ukurannya, mungkin sulit untuk mengelola dan kinerjanya dapat terpengaruh selama lalu lintas tinggi jika kita tidak mengonfigurasi atau mengimplementasikannya dengan cara yang benar. . Secara umum, jika kami memiliki database yang besar dan kami ingin memiliki waktu respons yang rendah, kami ingin menskalakannya. PostgreSQL tidak terkecuali untuk saat ini. Ada banyak pendekatan yang tersedia untuk menskalakan PostgreSQL, tetapi pertama-tama, mari pelajari apa itu penskalaan.
Skalabilitas adalah properti dari sistem/database untuk menangani jumlah permintaan yang terus meningkat dengan menambahkan sumber daya.
Alasan jumlah permintaan ini bisa bersifat sementara, misalnya, jika kami meluncurkan diskon untuk penjualan, atau permanen, untuk peningkatan pelanggan atau karyawan. Bagaimanapun, kita harus dapat menambah atau menghapus sumber daya untuk mengelola perubahan ini pada permintaan atau peningkatan lalu lintas.
Di blog ini, kita akan melihat bagaimana kita dapat menskalakan database PostgreSQL kita dan kapan kita perlu melakukannya.
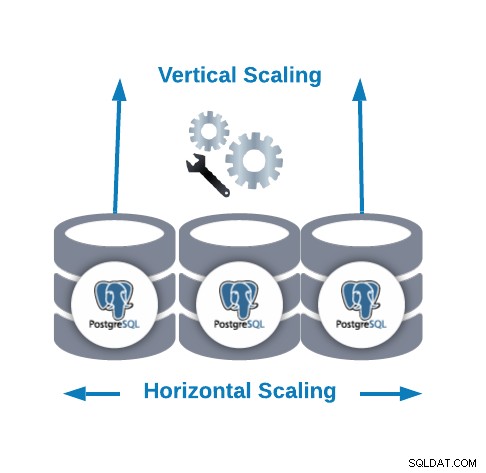
Penskalaan Horizontal vs Penskalaan Vertikal
Ada dua cara utama untuk menskalakan database kami...
- Penskalaan Horizontal (penskalaan):Ini dilakukan dengan menambahkan lebih banyak node database membuat atau meningkatkan cluster database.
- Penskalaan Vertikal (penskalaan):Dilakukan dengan menambahkan lebih banyak sumber daya perangkat keras (CPU, Memori, Disk) ke node database yang ada.
Untuk Horizontal Scaling, kita dapat menambahkan lebih banyak node database sebagai node slave. Ini dapat membantu kami meningkatkan kinerja baca dengan menyeimbangkan lalu lintas antar node. Dalam hal ini, kita perlu menambahkan penyeimbang beban untuk mendistribusikan lalu lintas ke node yang benar bergantung pada kebijakan dan status node.
Untuk menghindari satu titik kegagalan menambahkan hanya satu penyeimbang beban, kita harus mempertimbangkan untuk menambahkan dua atau lebih simpul penyeimbang beban dan menggunakan beberapa alat seperti “Keepalived”, untuk memastikan ketersediaannya.
Karena PostgreSQL tidak memiliki dukungan multi-master asli, jika kita ingin menerapkannya untuk meningkatkan kinerja penulisan, kita perlu menggunakan alat eksternal untuk tugas ini.
Untuk Penskalaan Vertikal, mungkin diperlukan untuk mengubah beberapa parameter konfigurasi agar PostgreSQL dapat menggunakan sumber daya perangkat keras yang baru atau lebih baik. Mari kita lihat beberapa parameter ini dari dokumentasi PostgreSQL.
- work_mem:Menentukan jumlah memori yang akan digunakan oleh operasi sortir internal dan tabel hash sebelum menulis ke file disk sementara. Beberapa sesi yang berjalan dapat melakukan operasi seperti itu secara bersamaan, sehingga total memori yang digunakan bisa berkali-kali lipat dari nilai work_mem.
- maintenance_work_mem:Menentukan jumlah maksimum memori yang akan digunakan oleh operasi pemeliharaan, seperti VACUUM, CREATE INDEX, dan ALTER TABLE ADD FOREIGN KEY. Setelan yang lebih besar dapat meningkatkan performa untuk menyedot debu dan memulihkan dump database.
- autovacuum_work_mem:Menentukan jumlah maksimum memori yang akan digunakan oleh setiap proses pekerja autovacuum.
- autovacuum_max_workers:Menentukan jumlah maksimum proses autovacuum yang dapat berjalan pada satu waktu.
- max_worker_processes:Menyetel jumlah maksimum proses latar belakang yang dapat didukung sistem. Tentukan batas proses seperti menyedot debu, pos pemeriksaan, dan pekerjaan pemeliharaan lainnya.
- max_parallel_workers:Menyetel jumlah maksimum pekerja yang dapat didukung sistem untuk operasi paralel. Pekerja paralel diambil dari kumpulan proses pekerja yang ditetapkan oleh parameter sebelumnya.
- max_parallel_maintenance_workers:Menyetel jumlah maksimum pekerja paralel yang dapat dimulai dengan satu perintah utilitas. Saat ini, satu-satunya perintah utilitas paralel yang mendukung penggunaan pekerja paralel adalah CREATE INDEX, dan hanya ketika membangun indeks B-tree.
- effective_cache_size:Menetapkan asumsi perencana tentang ukuran efektif cache disk yang tersedia untuk satu kueri. Ini diperhitungkan dalam perkiraan biaya penggunaan indeks; nilai yang lebih tinggi membuat pemindaian indeks lebih mungkin digunakan, nilai yang lebih rendah membuat pemindaian berurutan lebih mungkin digunakan.
- shared_buffers:Menyetel jumlah memori yang digunakan server database untuk buffer memori bersama. Pengaturan yang jauh lebih tinggi dari minimum biasanya diperlukan untuk kinerja yang baik.
- temp_buffers:Menyetel jumlah maksimum buffer sementara yang digunakan oleh setiap sesi database. Ini adalah buffer sesi-lokal yang hanya digunakan untuk akses ke tabel sementara.
- effective_io_concurrency:Menyetel jumlah operasi I/O disk bersamaan yang diharapkan PostgreSQL dapat dijalankan secara bersamaan. Menaikkan nilai ini akan meningkatkan jumlah operasi I/O yang setiap sesi PostgreSQL mencoba untuk memulai secara paralel. Saat ini, setelan ini hanya memengaruhi pemindaian heap bitmap.
- max_connections:Menentukan jumlah maksimum koneksi bersamaan ke server database. Meningkatkan parameter ini memungkinkan PostgreSQL menjalankan lebih banyak proses backend secara bersamaan.
Pada titik ini, ada pertanyaan yang harus kita tanyakan. Bagaimana kita bisa tahu jika kita perlu menskalakan database kita dan bagaimana kita bisa tahu cara terbaik untuk melakukannya?
Pemantauan
Menskalakan database PostgreSQL kami adalah proses yang kompleks, jadi kami harus memeriksa beberapa metrik untuk dapat menentukan strategi terbaik untuk menskalakannya.
Kami dapat memantau penggunaan CPU, Memori, dan Disk untuk menentukan apakah ada beberapa masalah konfigurasi atau jika memang, kami perlu menskalakan basis data kami. Misalnya, jika kita melihat beban server tinggi tetapi aktivitas database rendah, mungkin tidak perlu menskalakannya, kita hanya perlu memeriksa parameter konfigurasi untuk mencocokkannya dengan sumber daya perangkat keras kita.
Memeriksa ruang disk yang digunakan oleh node PostgreSQL per database dapat membantu kami mengonfirmasi apakah kami memerlukan lebih banyak disk atau bahkan partisi tabel. Untuk memeriksa ruang disk yang digunakan oleh database/tabel kita dapat menggunakan beberapa fungsi PostgreSQL seperti pg_database_size atau pg_table_size.
Dari sisi database, kita harus memeriksa
- Jumlah koneksi
- Menjalankan kueri
- Penggunaan indeks
- Kembung
- Keterlambatan Replikasi
Ini bisa menjadi metrik yang jelas untuk mengonfirmasi apakah penskalaan database kami diperlukan.
ClusterControl sebagai Sistem Penskalaan dan Pemantauan
ClusterControl dapat membantu kita mengatasi kedua cara penskalaan yang kita lihat sebelumnya dan untuk memantau semua metrik yang diperlukan untuk mengonfirmasi persyaratan penskalaan. Mari kita lihat caranya...
Jika Anda belum menggunakan ClusterControl, Anda dapat menginstalnya dan menyebarkan atau mengimpor database PostgreSQL Anda saat ini dengan memilih opsi "Impor" dan ikuti langkah-langkahnya, untuk memanfaatkan semua fitur ClusterControl seperti pencadangan, failover otomatis, peringatan, pemantauan, dan banyak lagi.
Penskalaan Horizontal
Untuk penskalaan horizontal, jika kita masuk ke tindakan cluster dan memilih “Add Replication Slave”, kita dapat membuat replika baru dari awal atau menambahkan database PostgreSQL yang ada sebagai replika.
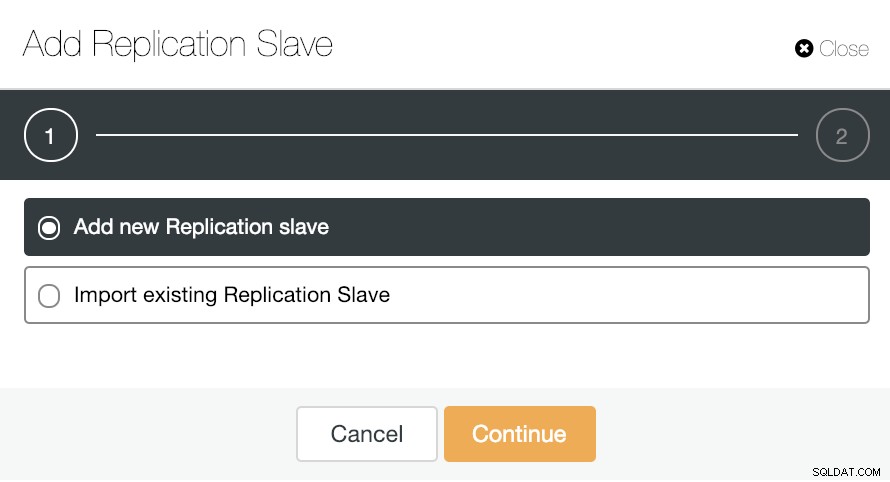
Mari kita lihat bagaimana menambahkan budak replikasi baru bisa menjadi tugas yang sangat mudah.
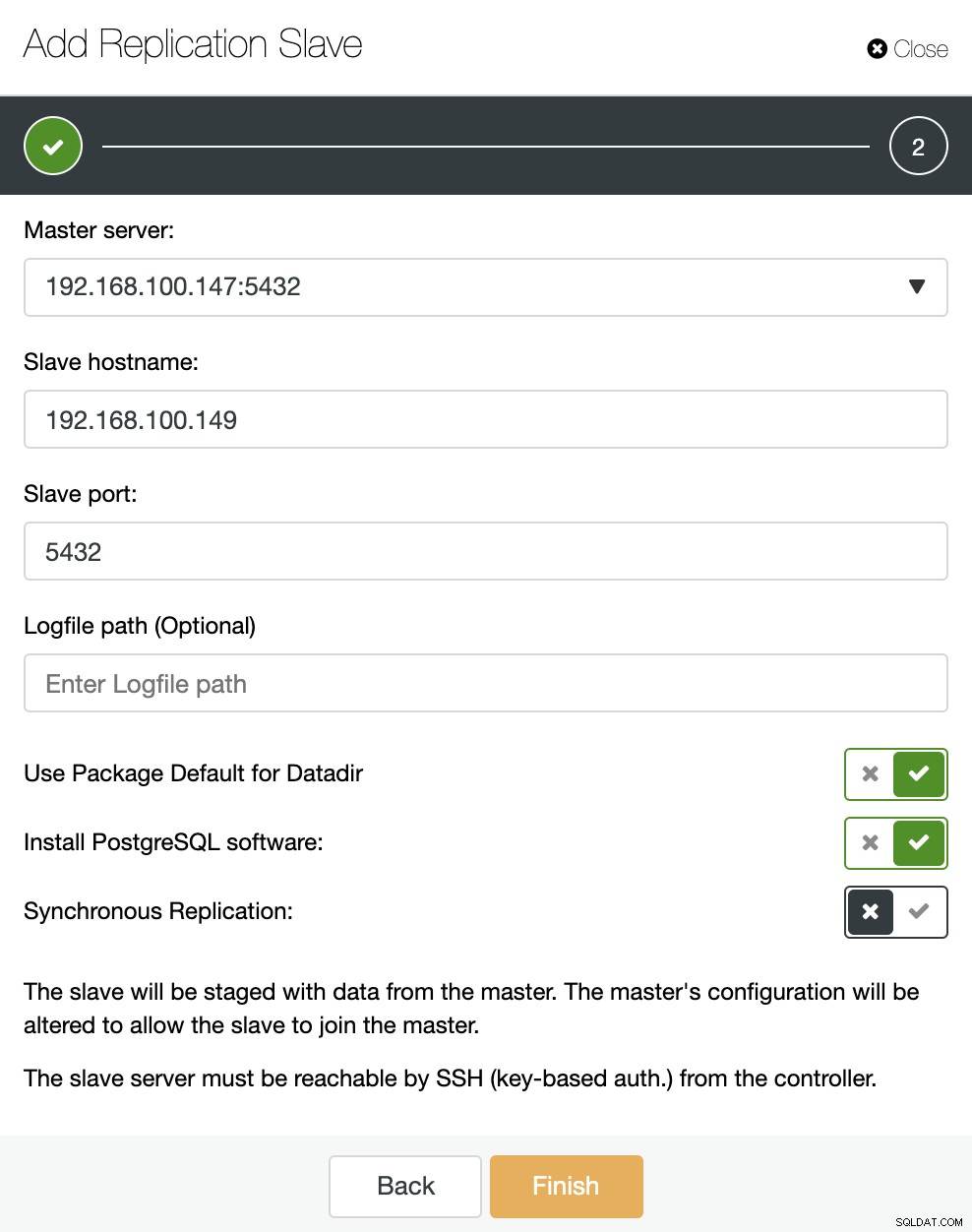
Seperti yang Anda lihat pada gambar, kita hanya perlu memilih server Master kami, masukkan alamat IP untuk server budak baru kami dan port database. Kemudian, kita dapat memilih apakah kita ingin ClusterControl menginstal perangkat lunak untuk kita dan jika slave replikasi harus Synchronous atau Asynchronous.
Dengan cara ini, kita dapat menambahkan replika sebanyak yang kita inginkan dan menyebarkan lalu lintas baca di antara mereka menggunakan penyeimbang beban, yang juga dapat kita terapkan dengan ClusterControl.
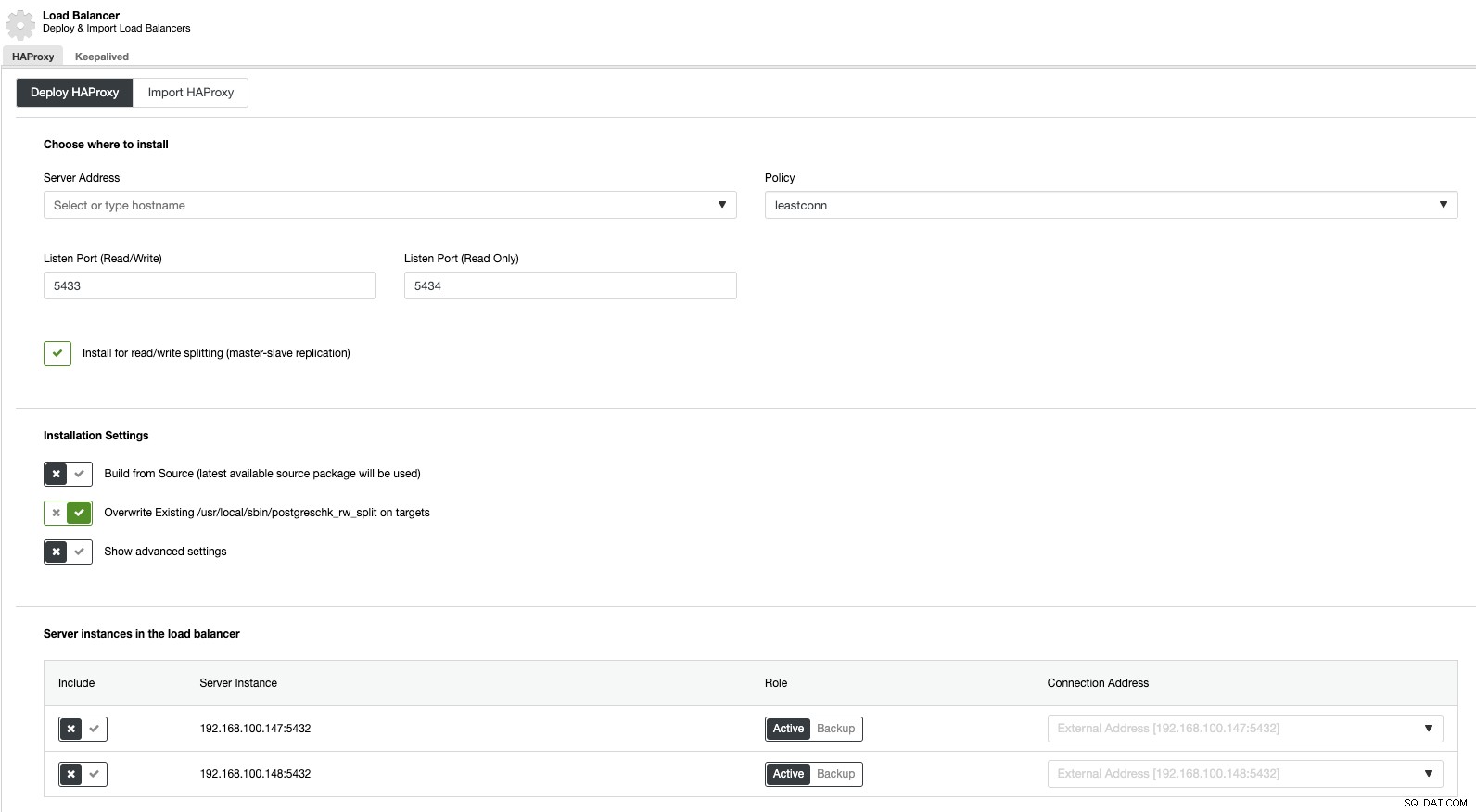
Sekarang, jika kita masuk ke tindakan cluster dan memilih “Add Load Balancer”, kita dapat menerapkan HAProxy Load Balancer baru atau menambahkan yang sudah ada.
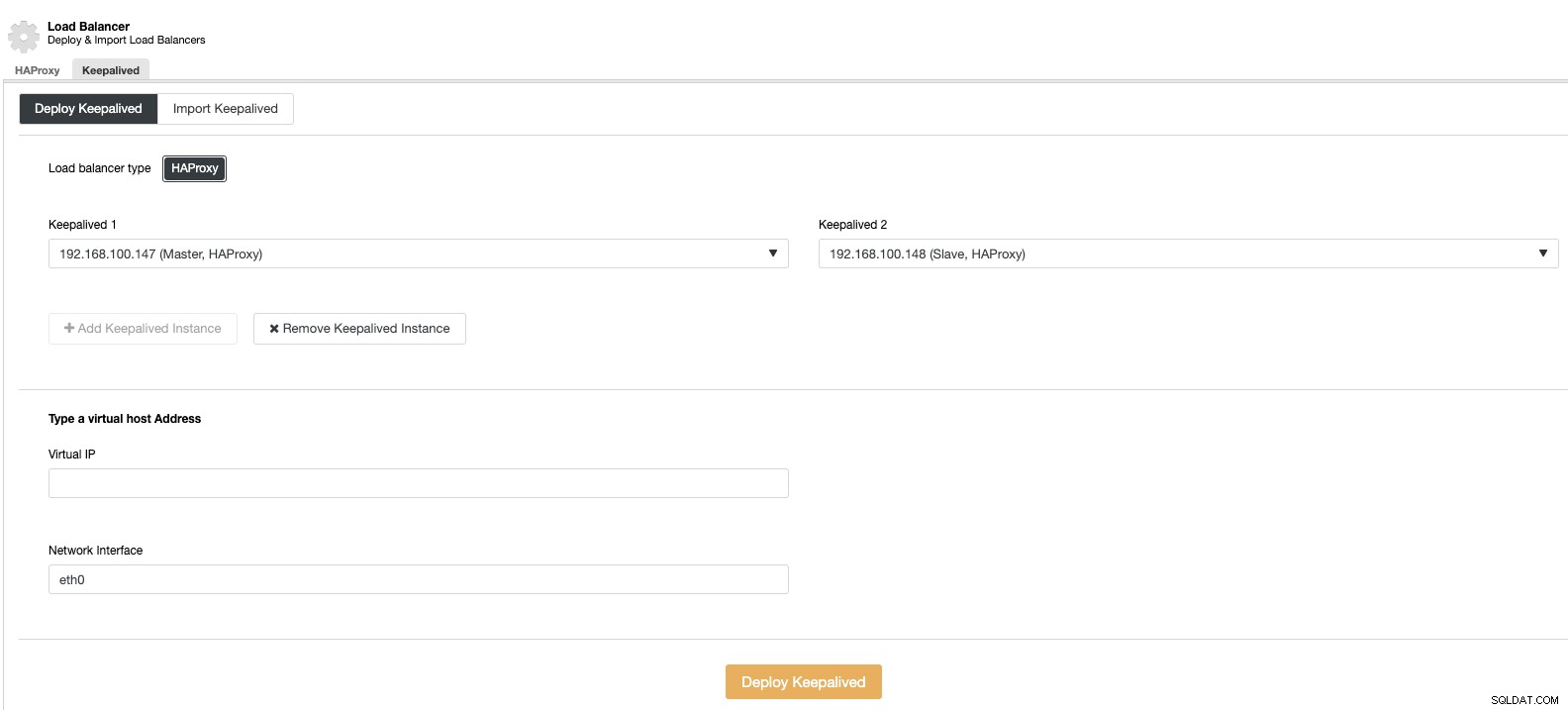
Kemudian, di bagian penyeimbang beban yang sama, kita dapat menambahkan layanan Keepalive yang berjalan di node penyeimbang beban untuk meningkatkan lingkungan ketersediaan tinggi kita.
Penskalaan Vertikal
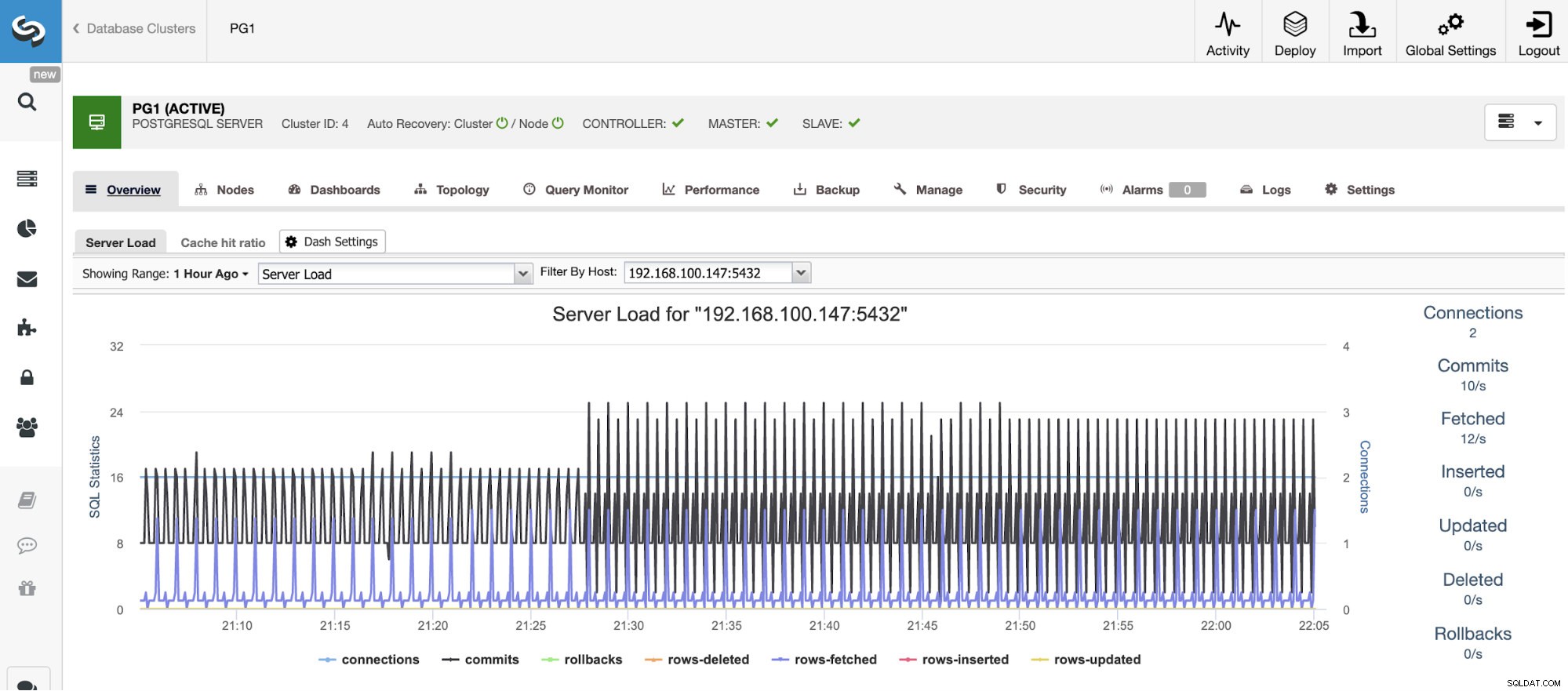
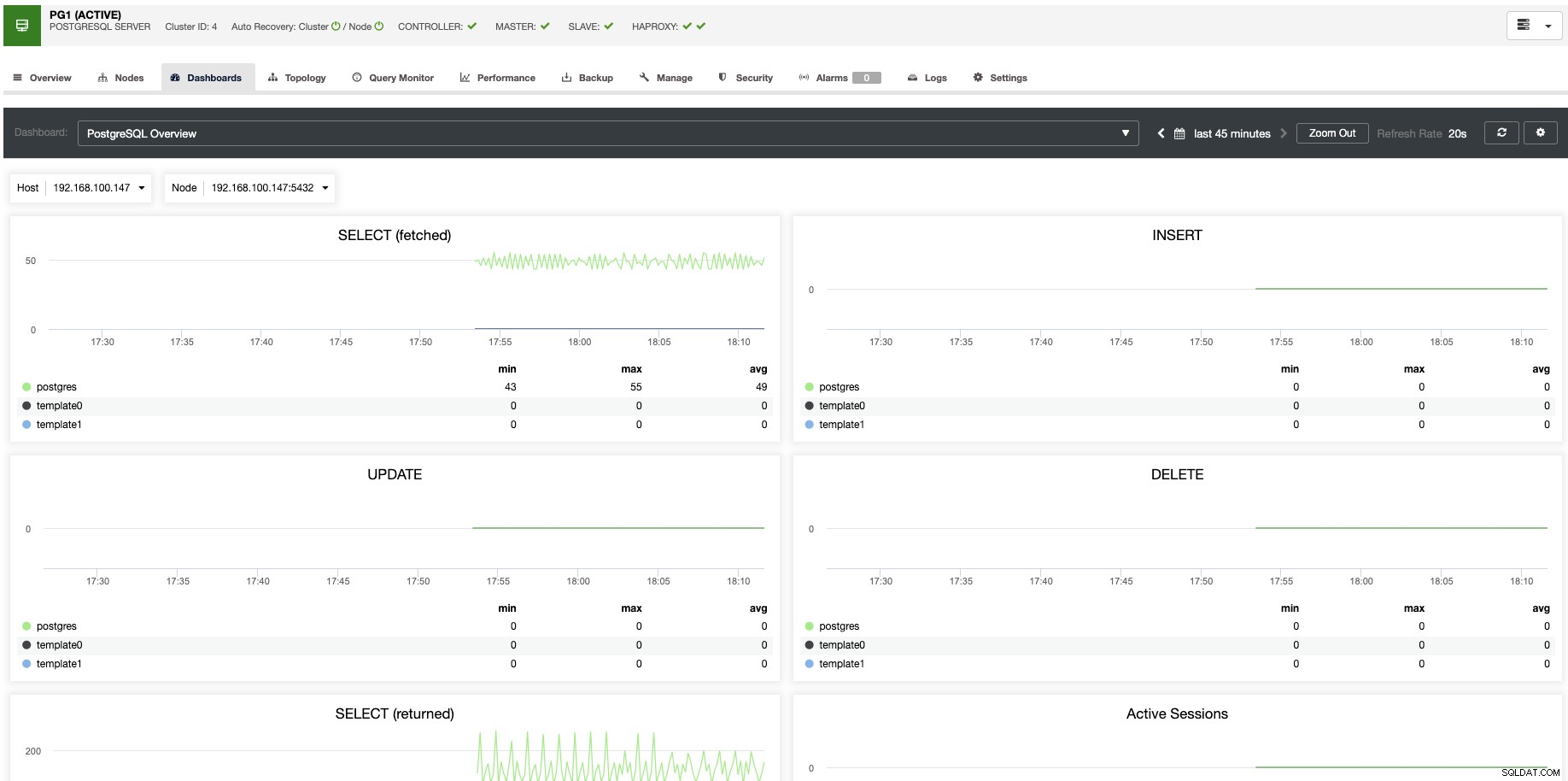
Untuk penskalaan vertikal, dengan ClusterControl kita dapat memantau node database kita dari sisi sistem operasi dan database. Kami dapat memeriksa beberapa metrik seperti penggunaan CPU, Memori, koneksi, kueri teratas, kueri yang berjalan, dan bahkan banyak lagi. Kami juga dapat mengaktifkan bagian Dasbor, yang memungkinkan kami melihat metrik secara lebih mendetail dan lebih bersahabat dengan metrik kami.
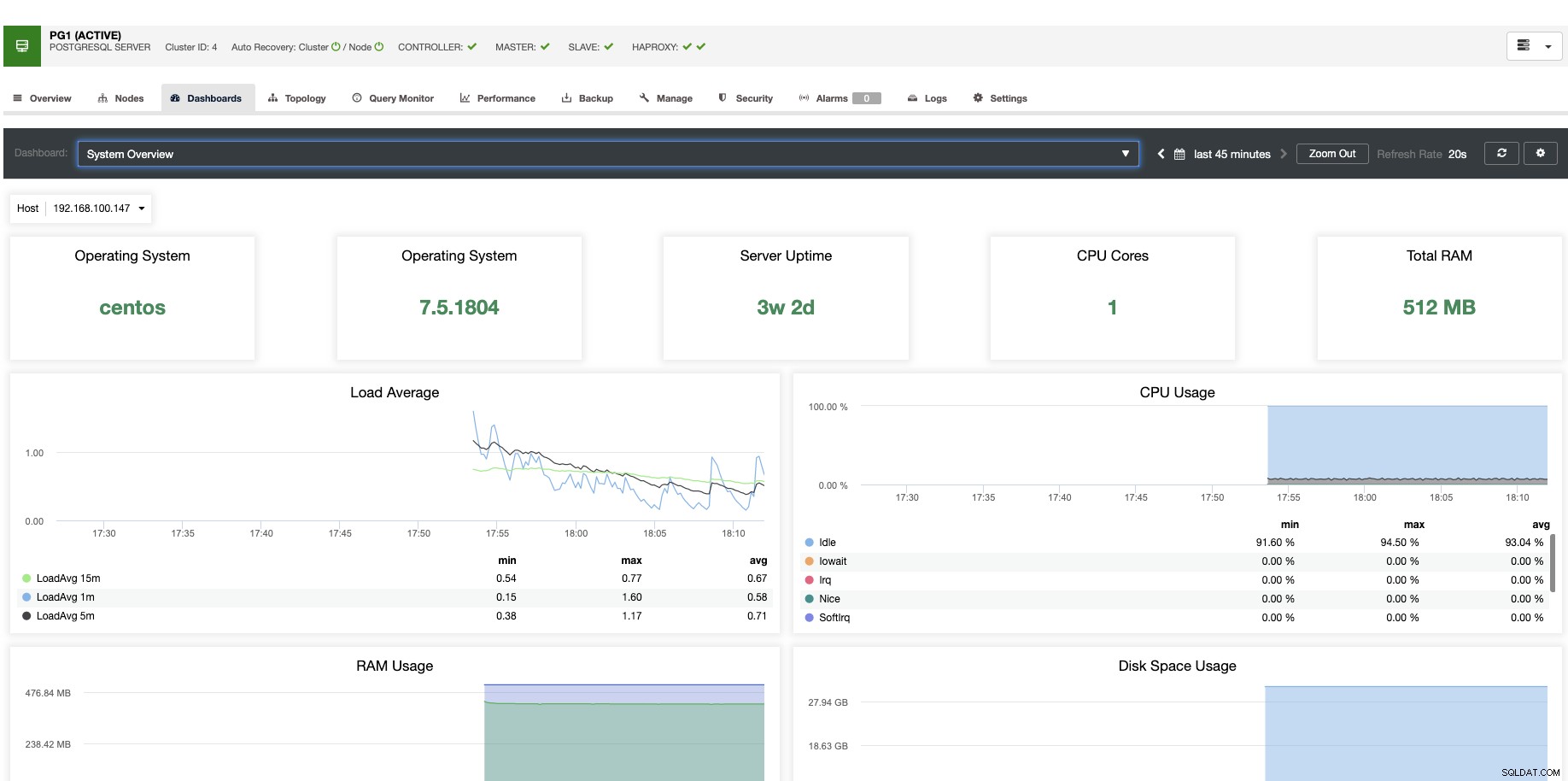
Dari ClusterControl, Anda juga dapat melakukan berbagai tugas manajemen seperti Reboot Host, Rebuild Replication Slave, atau Promote Slave, dengan satu klik.
Kesimpulan
Menskalakan basis data PostgreSQL bisa menjadi tugas yang memakan waktu. Kita perlu tahu apa yang kita butuhkan untuk skala dan apa cara terbaik untuk melakukannya. Pada akhirnya, mengelola dan menskalakan klaster secara manual menjadi sangat memberatkan melewati titik tertentu sehingga sebagian besar beralih ke alat seperti milik kita.
Jika Anda memilih rute manual, periksa kapan harus mempertimbangkan untuk menambahkan node tambahan ke cluster Anda. Ingin terhindar dari kerepotan? Evaluasi ClusterControl secara gratis selama 30 hari untuk melihat bagaimana fitur-fiturnya membuat penanganan skala besar, sumber terbuka menjadi sederhana dan efisien.
Bagaimanapun Anda ingin mengelola dan menskalakan basis data Anda, ikuti kami di Twitter atau LinkedIn, atau berlangganan buletin kami untuk mendapatkan berita terbaru dan praktik terbaik saat mengelola infrastruktur basis data berbasis sumber terbuka, dan kami akan segera bertemu Anda!