Meskipun ada berbagai cara untuk memulihkan database PostgreSQL Anda, salah satu pendekatan paling mudah untuk memulihkan data Anda dari cadangan logis. Pencadangan logis memainkan peran penting untuk Disaster and Recovery Planning (DRP). Pencadangan logis adalah pencadangan yang dilakukan, misalnya menggunakan pg_dump atau pg_dumpall, yang menghasilkan pernyataan SQL untuk mendapatkan semua data tabel yang ditulis ke file biner.
Disarankan juga untuk menjalankan pencadangan logis berkala jika pencadangan fisik Anda gagal atau tidak tersedia. Untuk PostgreSQL, memulihkan dapat menjadi masalah jika Anda tidak yakin alat apa yang digunakan. Alat pencadangan pg_dump biasanya dipasangkan dengan alat pemulihan pg_restore.
pg_dump dan pg_restore bertindak bersama-sama jika terjadi bencana dan Anda perlu memulihkan data Anda. Meskipun mereka melayani tujuan utama dump dan restore, itu memang mengharuskan Anda untuk melakukan beberapa tugas tambahan ketika Anda perlu memulihkan cluster Anda dan melakukan failover (jika primer atau master aktif Anda mati karena kegagalan perangkat keras atau kerusakan sistem VM). Anda akan menemukan dan menggunakan alat pihak ketiga yang dapat menangani failover atau pemulihan cluster otomatis.
Di blog ini, kita akan melihat cara kerja pg_restore dan membandingkannya dengan cara ClusterControl menangani pencadangan dan pemulihan data Anda jika terjadi bencana.
Mekanisme pg_restore
pg_restore berguna saat mendapatkan tugas berikut:
- dipasangkan dengan pg_dump untuk menghasilkan file yang dihasilkan SQL yang berisi data, peran akses, database, dan definisi tabel
- memulihkan database PostgreSQL dari arsip yang dibuat oleh pg_dump dalam salah satu format non-teks biasa.
- Ini akan mengeluarkan perintah yang diperlukan untuk merekonstruksi database ke keadaan saat itu disimpan.
- memiliki kemampuan untuk selektif atau bahkan menyusun ulang item sebelum dipulihkan berdasarkan file arsip
- File arsip dirancang agar portabel di berbagai arsitektur.
- pg_restore dapat beroperasi dalam dua mode.
- Jika nama database ditentukan, pg_restore menghubungkan ke database itu dan mengembalikan konten arsip langsung ke database.
- atau, skrip yang berisi perintah SQL yang diperlukan untuk membangun kembali database dibuat dan ditulis ke file atau output standar. Output skripnya memiliki kesetaraan dengan format yang dihasilkan oleh pg_dump
- Oleh karena itu, beberapa opsi yang mengontrol output serupa dengan opsi pg_dump.
Setelah Anda memulihkan data, yang terbaik dan disarankan untuk menjalankan ANALYZE pada setiap tabel yang dipulihkan sehingga pengoptimal memiliki statistik yang berguna. Meskipun memperoleh READ LOCK, Anda mungkin harus menjalankan ini selama lalu lintas rendah atau selama periode pemeliharaan.
Kelebihan pg_restore
pg_dump dan pg_restore secara bersamaan memiliki kemampuan yang nyaman digunakan oleh DBA.
- pg_dump dan pg_restore memiliki kemampuan untuk berjalan secara paralel dengan menentukan opsi -j. Menggunakan -j/--jobs
memungkinkan Anda menentukan berapa banyak pekerjaan yang berjalan secara paralel dapat dijalankan terutama untuk memuat data, membuat indeks, atau membuat batasan menggunakan beberapa pekerjaan bersamaan. - Sangat praktis untuk digunakan, Anda dapat membuang atau memuat database atau tabel tertentu secara selektif
- Ini memungkinkan dan memberikan fleksibilitas pengguna pada database tertentu, skema, atau menyusun ulang prosedur yang akan dijalankan berdasarkan daftar. Anda bahkan dapat membuat dan memuat urutan SQL secara longgar seperti mencegah acls atau hak istimewa sesuai dengan kebutuhan Anda. Ada banyak pilihan yang sesuai dengan kebutuhan Anda.
- Ini memberi Anda kemampuan untuk menghasilkan file SQL seperti pg_dump dari arsip. Ini sangat nyaman jika Anda ingin memuat ke database atau host lain untuk menyediakan lingkungan yang terpisah.
- Mudah dipahami berdasarkan urutan prosedur SQL yang dihasilkan.
- Ini adalah cara mudah untuk memuat data di lingkungan replikasi. Anda tidak memerlukan replika Anda untuk disusun ulang karena pernyataannya adalah SQL yang direplikasi hingga ke node siaga dan pemulihan.
Batasan pg_restore
Untuk pencadangan logis, batasan yang jelas dari pg_restore bersama dengan pg_dump adalah kinerja dan kecepatan saat menggunakan alat. Ini mungkin berguna ketika Anda ingin menyediakan lingkungan database pengujian atau pengembangan dan memuat data Anda, tetapi itu tidak berlaku ketika kumpulan data Anda sangat besar. PostgreSQL harus membuang data Anda satu per satu atau mengeksekusi dan menerapkan data Anda secara berurutan oleh mesin database. Meskipun Anda dapat membuatnya lebih fleksibel untuk mempercepat seperti menentukan -j atau menggunakan --single-transaction untuk menghindari dampak pada database Anda, pemuatan menggunakan SQL masih harus diuraikan oleh mesin.
Selain itu, dokumentasi PostgreSQL menyatakan batasan berikut, dengan penambahan kami saat kami mengamati alat ini (pg_dump dan pg_restore):
- Saat memulihkan data ke tabel yang sudah ada sebelumnya dan opsi --disable-triggers digunakan, pg_restore mengeluarkan perintah untuk menonaktifkan pemicu pada tabel pengguna sebelum memasukkan data, lalu mengeluarkan perintah untuk mengaktifkannya kembali setelah data dimasukkan. Jika pemulihan dihentikan di tengah, katalog sistem mungkin dibiarkan dalam status yang salah.
- pg_restore tidak dapat memulihkan objek besar secara selektif; misalnya, hanya untuk tabel tertentu. Jika arsip berisi objek besar, maka semua objek besar akan dipulihkan, atau tidak satu pun objek tersebut jika dikecualikan melalui -L, -t, atau opsi lainnya.
- Kedua alat tersebut diharapkan menghasilkan ukuran yang sangat besar (file, direktori, atau arsip tar) terutama untuk database yang besar.
- Untuk pg_dump, saat membuang satu tabel atau sebagai teks biasa, pg_dump tidak menangani objek besar. Objek besar harus dibuang dengan seluruh database menggunakan salah satu format arsip non-teks.
- Jika Anda memiliki arsip tar yang dihasilkan oleh alat ini, perhatikan bahwa arsip tar dibatasi hingga ukuran kurang dari 8 GB. Ini adalah batasan yang melekat pada format file tar. Oleh karena itu format ini tidak dapat digunakan jika representasi tekstual dari tabel melebihi ukuran tersebut. Ukuran total arsip tar dan format keluaran lainnya tidak dibatasi, kecuali mungkin oleh sistem operasi.
Menggunakan pg_restore
Menggunakan pg_restore cukup praktis dan mudah digunakan. Karena dipasangkan bersama-sama dengan pg_dump, kedua alat ini bekerja cukup baik selama output target sesuai dengan yang lain. Misalnya, pg_dump berikut tidak akan berguna untuk pg_restore,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Hasil ini akan menjadi psql kompatibel yang terlihat seperti berikut:
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;Tapi ini akan gagal untuk pg_restore karena tidak ada format biasa untuk diikuti:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerSekarang, mari kita beralih ke istilah yang lebih berguna untuk pg_restore.
pg_restore:Jatuhkan dan Pulihkan
Pertimbangkan penggunaan sederhana pg_restore di mana Anda telah menjatuhkan database, mis.
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Memulihkannya dengan pg_restore sangat mudah,
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump -C/--create here menyatakan bahwa membuat database setelah ditemukan di header. -d postgres menunjuk ke database postgres tetapi itu tidak berarti itu akan membuat tabel ke database postgres. Hal ini mensyaratkan bahwa database harus ada. Jika -C tidak ditentukan, tabel dan catatan akan disimpan ke database yang direferensikan dengan argumen -d.
Memulihkan Secara Selektif Berdasarkan Tabel
Memulihkan tabel dengan pg_restore mudah dan sederhana. Misalnya, Anda memiliki dua tabel yaitu tabel "b" dan "d". Katakanlah Anda menjalankan perintah pg_dump berikut di bawah ini,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Di mana isi direktori ini akan terlihat seperti berikut,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..Jika Anda ingin mengembalikan tabel (yaitu "d" dalam contoh ini),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Harus ada,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:Menyalin Tabel Database ke Database Lain
Anda bahkan dapat menyalin konten database yang ada dan menyimpannya di database target Anda. Sebagai contoh, saya memiliki database berikut,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)Basis data paultest adalah basis data kosong saat kita akan menyalin apa yang ada di dalam basis data maxtest,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Untuk menyalinnya, kita perlu membuang data dari database maxtest sebagai berikut,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Kemudian muat atau pulihkan sebagai berikut,
Sekarang, kami mendapatkan data pada database paultest dan tabel telah disimpan sesuai dengan itu.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Hasilkan file SQL Dengan Re-ordering
Saya telah melihat banyak penggunaan dengan pg_restore tetapi tampaknya fitur ini biasanya tidak ditampilkan. Saya menemukan pendekatan ini sangat menarik karena memungkinkan Anda untuk memesan berdasarkan apa yang tidak ingin Anda sertakan dan kemudian menghasilkan file SQL dari urutan yang ingin Anda lanjutkan.
Misalnya, kita akan menggunakan contoh pgdump_data.tar yang telah kita buat sebelumnya dan membuat daftar. Untuk melakukannya, jalankan perintah berikut:
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listIni akan menghasilkan file seperti yang ditunjukkan di bawah ini:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresSekarang, mari kita pesan ulang atau katakan saya telah menghapus pembuatan SEQUENCE dan juga pembuatan batasan. Ini akan terlihat seperti berikut,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresUntuk menghasilkan file dalam format SQL, cukup lakukan hal berikut:
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Sekarang, file /tmp/selective_data.out akan menjadi file yang dihasilkan SQL dan ini dapat dibaca jika Anda menggunakan psql, tetapi bukan pg_restore. Apa yang hebat tentang ini adalah Anda dapat menghasilkan file SQL sesuai dengan template Anda di mana data hanya dapat dipulihkan dari arsip yang ada atau cadangan yang diambil menggunakan pg_dump dengan bantuan pg_restore.
Pemulihan PostgreSQL dengan ClusterControl
ClusterControl tidak menggunakan pg_restore atau pg_dump sebagai bagian dari fitur-fiturnya. Kami menggunakan pg_dumpall untuk menghasilkan cadangan logis dan, sayangnya, outputnya tidak kompatibel dengan pg_restore.
Ada beberapa cara lain untuk membuat cadangan di PostgreSQL seperti yang terlihat di bawah ini.
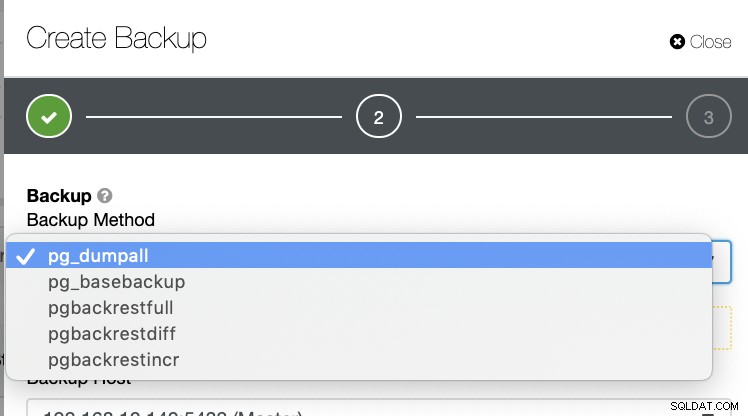
Tidak ada mekanisme seperti itu di mana Anda dapat secara selektif menyimpan tabel, database, atau salin dari satu database ke database lain.
ClusterControl mendukung Point-in-Time Recovery (PITR), tetapi ini tidak memungkinkan Anda untuk mengelola pemulihan data sefleksibel pg_restore. Untuk semua daftar metode pencadangan, hanya pg_basebackup dan pgbackrest yang mampu PITR.
Cara ClusterControl menangani pemulihan adalah ia memiliki kemampuan untuk memulihkan kluster yang gagal selama Pemulihan Otomatis diaktifkan seperti yang ditunjukkan di bawah ini.

Setelah master gagal, slave dapat secara otomatis memulihkan cluster seperti yang dilakukan ClusterControl failover (yang dilakukan secara otomatis). Untuk bagian pemulihan data, satu-satunya pilihan Anda adalah memiliki pemulihan seluruh cluster yang berarti berasal dari cadangan penuh. Tidak ada kemampuan untuk memulihkan secara selektif pada database atau tabel target yang hanya ingin Anda pulihkan. Jika Anda ingin melakukannya, pulihkan cadangan penuh, mudah untuk melakukannya dengan ClusterControl. Anda dapat pergi ke tab Backup seperti yang ditunjukkan di bawah ini,
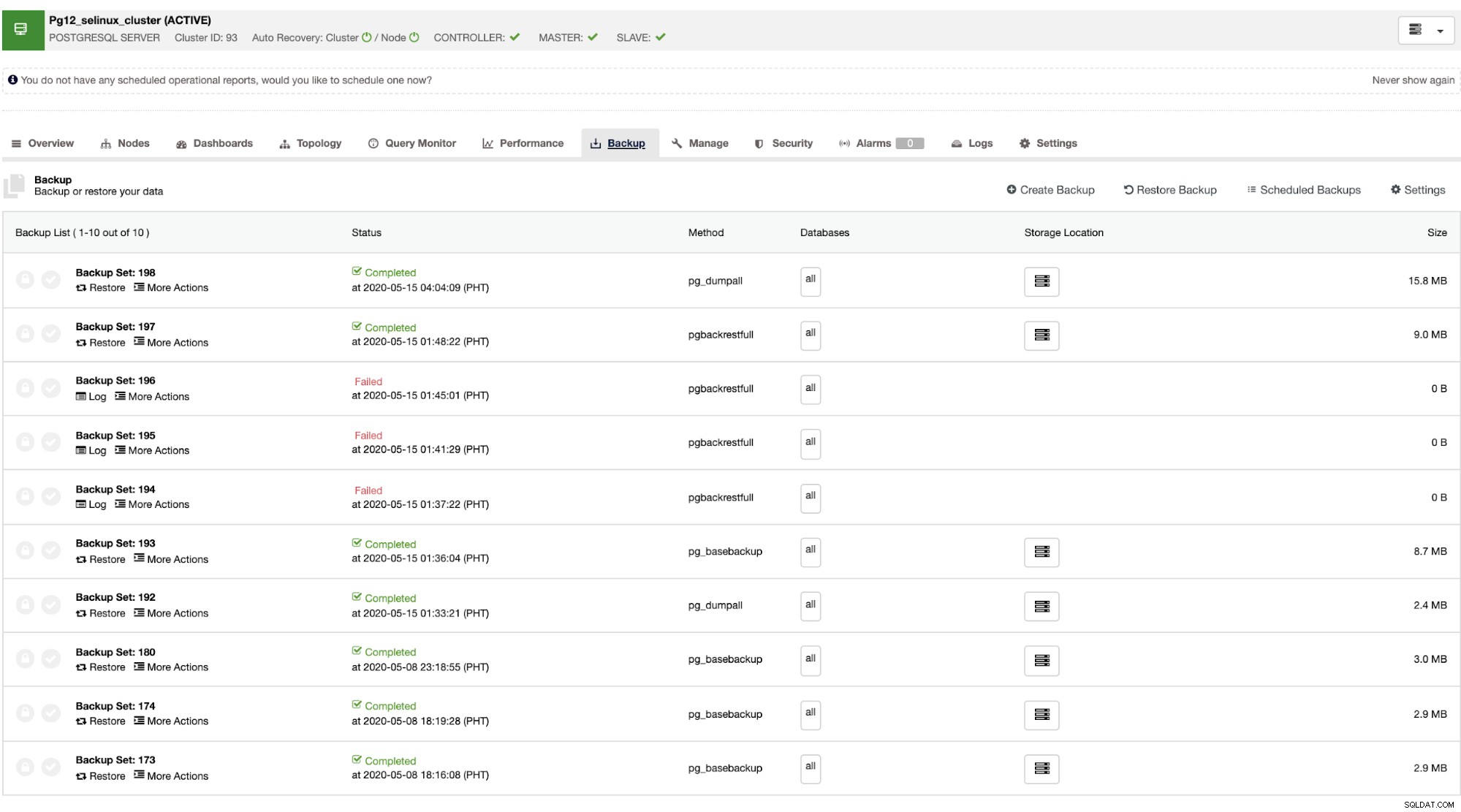
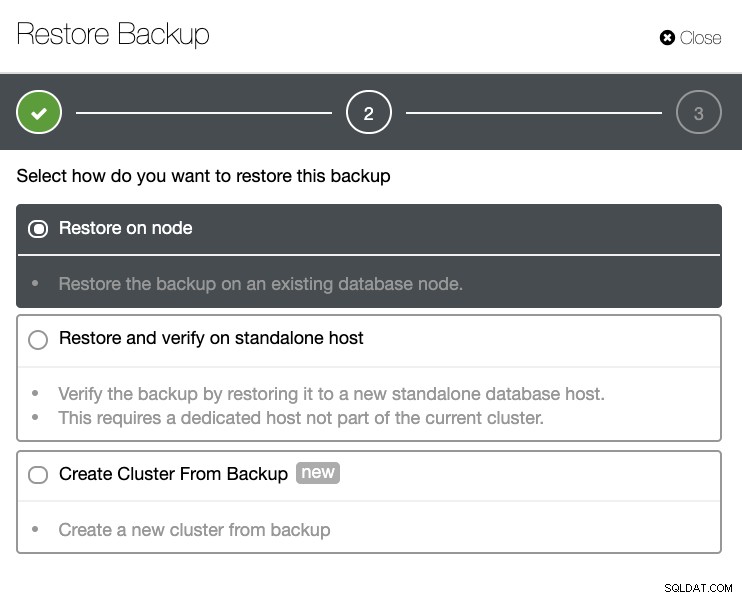
Anda akan memiliki daftar lengkap pencadangan yang berhasil dan gagal. Kemudian memulihkannya dapat dilakukan dengan memilih cadangan target dan mengklik tombol "Pulihkan". Ini akan memungkinkan Anda untuk memulihkan pada node yang ada yang terdaftar dalam ClusterControl, atau memverifikasi pada node yang berdiri sendiri, atau membuat cluster dari cadangan.
Kesimpulan
Menggunakan pg_dump dan pg_restore menyederhanakan pendekatan pencadangan/pembuangan dan pemulihan. Namun, untuk lingkungan database skala besar, ini mungkin bukan komponen yang ideal untuk pemulihan bencana. Untuk prosedur pemilihan dan pemulihan minimal, menggunakan kombinasi pg_dump dan pg_restore memberi Anda kekuatan untuk membuang dan memuat data Anda sesuai dengan kebutuhan Anda.
Untuk lingkungan produksi (terutama untuk arsitektur perusahaan), Anda dapat menggunakan pendekatan ClusterControl untuk membuat pencadangan dan pemulihan dengan pemulihan otomatis.
Kombinasi pendekatan juga merupakan pendekatan yang baik. Ini membantu Anda menurunkan RTO dan RPO dan pada saat yang sama memanfaatkan cara paling fleksibel untuk memulihkan data Anda saat dibutuhkan.