Saya melanjutkan serangkaian artikel tentang dasar-dasar EXPLAIN di PostgreSQL, yang merupakan ulasan singkat Memahami EXPLAIN oleh Guillaume Lelarge.
Untuk lebih memahami masalah ini, saya sangat menyarankan untuk meninjau "Memahami EXPLAIN" asli oleh Guillaume Lelarge dan baca artikel pertama dan kedua saya.
PESAN OLEH
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Pada awalnya, Anda menjalankan pemindaian berurutan (Pemindaian Seq) dari tabel foo dan kemudian, lakukan pengurutan (Urutkan). Tanda -> dari perintah EXPLAIN menunjukkan hierarki langkah (simpul). Semakin awal langkah dijalankan, semakin besar indentasinya.
Sort Key adalah kondisi pengurutan.
Metode Sortir:external merge Disk File sementara pada disk dengan kapasitas 4592 kB digunakan saat menyortir.
Periksa dengan opsi BUFFERS:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
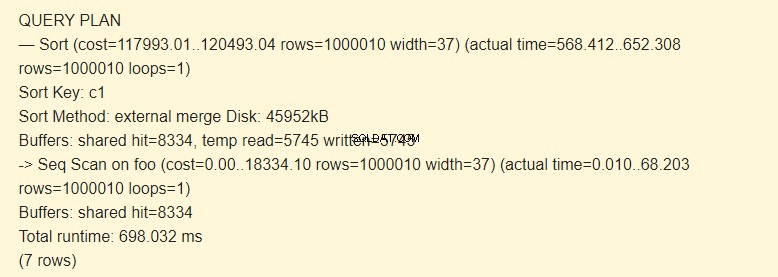
Memang, temp read=5745 tertulis=5745 baris berarti bahwa 45960Kb (5745 blok masing-masing 8 Kb) disimpan dan dibaca dalam file sementara. Operasi dengan 8334 blok dieksekusi di cache.
Operasi dengan sistem file lebih lambat daripada operasi di RAM.
Mari kita coba tingkatkan kapasitas memori work_mem:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Metode Pengurutan:quicksort Memori:102702kB – seluruh pengurutan dieksekusi dalam RAM.
Indeksnya adalah sebagai berikut:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Kami hanya memiliki Pemindaian Indeks yang tersisa, yang secara signifikan memengaruhi kecepatan kueri.
BATAS
Hapus indeks yang dibuat sebelumnya:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
Seperti yang diharapkan, Pemindaian Seq dan Filter digunakan.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan membaca baris tabel dan membandingkannya (Filter) dengan kondisi. Begitu ada 10 record yang memenuhi syarat, scan akan berakhir. Dalam kasus kami, untuk mendapatkan 10 baris hasil, kami harus membaca hanya 3063 catatan daripada seluruh tabel. 3053 baris dari nomor ini ditolak (Baris Dihapus oleh Filter).
Hal yang sama terjadi dengan Pemindaian Indeks.
BERGABUNG
Buat tabel baru dan buat statistiknya:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
Query untuk dua tabel adalah sebagai berikut:
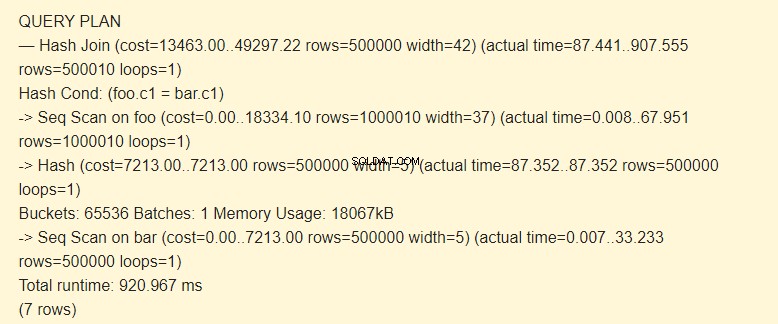
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
Pertama, pemindaian sekuensial (Pemindaian Seq) membaca tabel batang. Sebuah hash (Hash) dihitung untuk setiap baris.
Kemudian, memindai tabel foo, dan untuk setiap baris, hash dihitung yang dibandingkan (Hash Join) dengan hash dari tabel bar dengan kondisi Hash Cond. Jika cocok, string yang dihasilkan akan dikeluarkan.
Memori 18067kB digunakan untuk menyimpan hash untuk bilah.
Tambahkan indeks:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

Hash tidak lagi digunakan. Gabungkan Gabung dan Pemindaian Indeks pada indeks kedua tabel sangat meningkatkan kinerja.
KIRI GABUNG:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
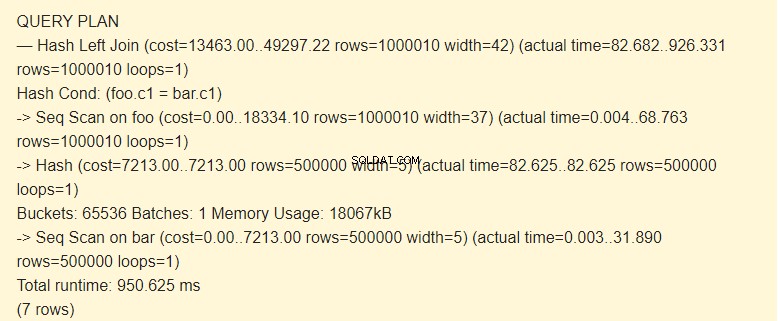
Pemindaian Seq?
Mari kita lihat hasil apa yang akan kita dapatkan jika kita menonaktifkan Seq Scan.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Menurut penjadwal, menggunakan indeks lebih mahal daripada menggunakan hash. Ini dimungkinkan dengan jumlah memori yang dialokasikan cukup besar. Apakah Anda ingat kami meningkatkan work_mem?
Namun, jika Anda tidak memiliki cukup memori, penjadwal akan berperilaku berbeda:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Jika kami menonaktifkan Pemindaian Indeks, hasil apa yang akan ditampilkan EXPLAIN?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
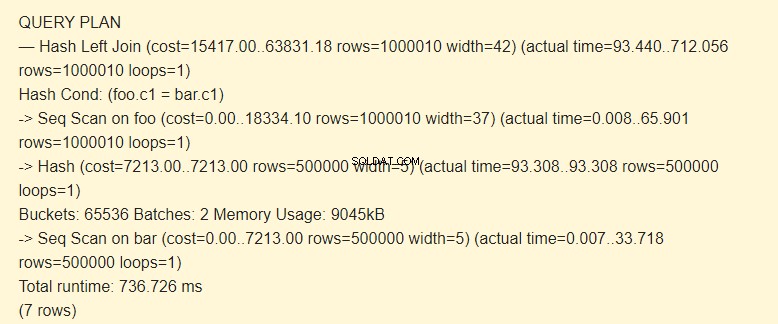
Batch:2 telah meningkatkan biaya. Seluruh hash tidak muat di memori; kami harus membaginya menjadi dua paket 9045kB.
Terima kasih telah membaca artikel saya! Saya harap mereka berguna. Jika Anda memiliki komentar atau umpan balik, jangan ragu untuk memberi tahu saya.