Menganalisis kueri populasi kunci lagi
Di bagian 3 dari seri penelusuran ODBC kami, kami akan mengambil wawasan lebih lanjut tentang Access yang mengelola kunci untuk tabel tertaut ODBC dan bagaimana mengurutkan dan mengelompokkan kueri SELECT bersama-sama. Dalam artikel sebelumnya kita telah mempelajari bagaimana recordset tipe-dinaset sebenarnya adalah 2 kueri terpisah dengan kueri pertama yang hanya mengambil kunci dari tabel tertaut ODBC yang kemudian digunakan untuk mengisi data. Dalam artikel ini, kita akan mempelajari sedikit lebih banyak tentang bagaimana Access mengelola kunci dan bagaimana Access menyimpulkan kunci apa yang digunakan untuk tabel tertaut ODBC di antara konsekuensi yang dimilikinya. Kita akan mulai dengan penyortiran.
Menambahkan pengurutan ke kueri
Anda melihat di artikel sebelumnya bahwa kami memulai dengan SELECT simple sederhana tanpa ada urutan tertentu. Anda juga melihat bagaimana Access pertama kali mengambil CityID dan gunakan hasil kueri pertama untuk kemudian mengisi kueri berikutnya untuk memberikan tampilan yang cepat kepada pengguna saat membuka kumpulan rekaman besar. Jika Anda pernah mengalami situasi di mana menambahkan pengurutan atau pengelompokan ke kueri, tiba-tiba menjadi lambat, ini akan menjelaskan alasannya.
Mari kita tambahkan pengurutan pada StateProvinceID dalam kueri Access:
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;Sekarang jika kita menelusuri ODBC SQL, kita akan melihat output:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)Jika dibandingkan dengan trace dari artikel sebelumnya, terlihat bahwa keduanya sama kecuali query pertama. Access menempatkan pengurutan di kueri pertama yang digunakan untuk mendapatkan kunci. Itu masuk akal karena dengan menerapkan pengurutan pada kunci yang digunakannya untuk menelusuri rekaman, Access dijamin memiliki korespondensi satu-ke-satu antara posisi ordinal rekaman dan bagaimana seharusnya diurutkan. Kemudian mengisi catatan dengan cara yang persis sama. Satu-satunya perbedaan adalah urutan kunci yang digunakan untuk mengisi kueri lainnya.
Mari kita pertimbangkan apa yang terjadi ketika kita menambahkan GROUP BY dengan menghitung kota per negara bagian:
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;Pelacakan akan menghasilkan:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" Anda mungkin juga memperhatikan bahwa kueri sekarang terbuka dengan lambat, dan meskipun mungkin disetel sebagai recordset tipe dynaset, Access memilih untuk mengabaikan ini dan pada dasarnya memperlakukannya sebagai recordset tipe snapshot. Ini masuk akal karena kueri tidak dapat diperbarui dan karena Anda tidak dapat benar-benar menavigasi ke posisi arbitrer dalam kueri seperti ini. Jadi, Anda harus menunggu sampai semua baris telah diambil sebelum Anda dapat menjelajah dengan bebas. StateProvinceID tidak dapat digunakan untuk mencari catatan karena akan ada beberapa catatan di Cities meja. Meskipun saya menggunakan GROUP BY dalam contoh ini, tidak perlu pengelompokan yang menyebabkan Access menggunakan kumpulan rekaman tipe snapshot. Menggunakan DISTINCT misalnya akan memiliki efek yang sama. Aturan praktis yang berguna untuk memprediksi apakah Access akan menggunakan recordset tipe dynaset adalah dengan menanyakan apakah baris tertentu dalam recordset yang dihasilkan dipetakan kembali ke tepat satu baris di sumber data ODBC. Jika tidak demikian, Access akan menggunakan perilaku snapshot meskipun kueri seharusnya menggunakan dynaset. Akibatnya, hanya karena defaultnya adalah recordset tipe-dinaset, itu tidak menjamin bahwa itu sebenarnya adalah recordset tipe-dinaset. Itu hanya permintaan , bukan permintaan.
Menentukan kunci yang akan digunakan untuk memilih
Anda mungkin telah memperhatikan di SQL yang ditelusuri sebelumnya di artikel ini dan sebelumnya, Access menggunakan CityID sebagai kunci. Kolom itu diambil dalam kueri pertama, lalu digunakan dalam kueri yang disiapkan berikutnya. Tetapi bagaimana Access mengetahui kolom mana dari tabel tertaut yang harus digunakan? Kecenderungan pertama adalah mengatakan bahwa ia memeriksa kunci utama dan menggunakannya. Namun, itu tidak benar. Faktanya, mesin database Access akan menggunakan SQLStatistics ODBC berfungsi selama penautan atau penautan ulang tabel untuk memeriksa indeks apa yang tersedia. Fungsi ini akan mengembalikan hasil dengan satu baris untuk setiap kolom yang berpartisipasi dalam indeks untuk semua indeks. Kumpulan hasil ini selalu diurutkan dan menurut konvensi, itu akan selalu mengurutkan indeks berkerumun, indeks hash, dan kemudian jenis indeks lainnya. Dalam setiap jenis indeks, indeks akan diurutkan berdasarkan namanya menurut abjad. Mesin database Access akan memilih indeks unik pertama yang ditemukannya meskipun itu bukan kunci utama yang sebenarnya. Untuk membuktikannya, kita akan membuat tabel konyol dengan beberapa indeks ganjil:
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );Jika kemudian kita mengisi tabel dengan beberapa data dan menautkannya di Access dan membuka tampilan lembar data pada tabel tertaut, kita akan melihat ini di ODBC SQL yang dilacak. Untuk singkatnya, hanya 2 perintah pertama yang disertakan.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?Karena
OtherStuff berpartisipasi dalam indeks berkerumun, itu datang sebelum kunci utama yang sebenarnya dan dengan demikian dipilih oleh mesin database Access untuk digunakan dalam recordset tipe dynaset untuk memilih baris individu. Itu juga terlepas dari fakta bahwa nama indeks berkerumun unik akan datang setelah nama indeks utama. Taktik untuk memaksa mesin database Access memilih indeks tertentu untuk tabel adalah dengan mengubah tipenya atau mengganti nama namanya sehingga mengurutkan menurut abjad dalam grup tipe indeks. Dalam kasus SQL Server, kunci utama biasanya berkerumun, dan hanya ada satu indeks berkerumun jadi itu adalah kebetulan yang menyenangkan bahwa biasanya indeks yang benar untuk mesin database Access untuk digunakan. Namun, jika database SQL Server berisi tabel dengan kunci utama nonclustered dan ada indeks unik berkerumun yang mungkin bukan pilihan yang optimal. Dalam kasus di mana tidak ada indeks berkerumun sama sekali, Anda dapat memengaruhi indeks unik mana yang digunakan dengan memberi nama indeks sehingga mengurutkannya sebelum indeks lainnya. Itu dapat membantu dengan perangkat lunak RDBMS lain di mana membuat indeks berkerumun untuk kunci utama tidak praktis atau mungkin. Indeks sisi akses untuk tampilan SQL tertaut atau tabel tanpa indeks
Saat menautkan ke tampilan SQL atau tabel SQL yang tidak memiliki indeks atau kunci utama yang ditentukan, tidak akan ada indeks yang tersedia untuk digunakan oleh mesin database Access. Jika Anda telah menggunakan pengelola tabel tertaut untuk menautkan tabel atau tampilan SQL tanpa indeks, Anda mungkin telah melihat dialog seperti ini:
 Jika kita memilih
Jika kita memilih ID , selesaikan penautan, buka tabel tertaut dalam tampilan desain, lalu dialog indeks, kita akan melihat ini:
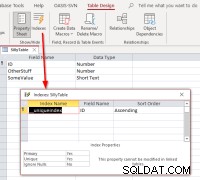 Ini menunjukkan bahwa tabel memiliki indeks bernama
Ini menunjukkan bahwa tabel memiliki indeks bernama __uniqueindex tetapi tidak ada di sumber data asli. Apa yang sedang terjadi? Jawabannya adalah Access membuat Access-side indeks untuk penggunaannya untuk membantu mengidentifikasi mana yang dapat digunakan sebagai pengidentifikasi catatan untuk tabel atau tampilan tersebut. Jika Anda secara terprogram menautkan ulang tabel daripada menggunakan Pengelola Tabel Tertaut, Anda akan merasa perlu untuk mereplikasi perilaku agar tabel tertaut tersebut dapat diperbarui. Ini dapat dilakukan dengan menjalankan perintah Access SQL:
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);Anda dapat menggunakan misalnya,
CurrentDb.Execute untuk menjalankan Access SQL untuk membuat indeks pada tabel tertaut. Namun, Anda tidak boleh menjalankannya sebagai kueri pass-through karena indeks sebenarnya tidak dibuat di server. Hanya untuk manfaat Access yang mengizinkan pembaruan pada tabel tertaut itu. Perlu dicatat bahwa Access hanya akan mengizinkan tepat satu indeks untuk tabel tertaut tersebut dan hanya jika belum memiliki indeks. Meskipun demikian, Anda dapat melihat bahwa menggunakan tampilan SQL mungkin merupakan opsi yang diinginkan untuk kasus di mana desain database tidak mengizinkan Anda menggunakan indeks berkerumun dan Anda tidak ingin mengutak-atik nama indeks untuk membujuk mesin database Access untuk menggunakan indeks ini, bukan indeks itu. Anda dapat secara eksplisit mengontrol indeks dan kolom yang harus disertakan saat menautkan tampilan SQL.
Kesimpulan
Dari artikel sebelumnya kita melihat bahwa recordset tipe dynaset biasanya mengeluarkan 2 query. Kueri pertama biasanya berkaitan dengan pengisian. Kami melihat lebih dekat bagaimana Access menangani populasi kunci yang akan digunakan untuk kumpulan data tipe dynaset. Kami melihat bagaimana Access akan benar-benar mengonversi pengurutan apa pun dari kueri Access asli dan kemudian menggunakannya dalam kueri populasi kunci. Kami melihat bahwa urutan kueri populasi kunci berdampak langsung pada bagaimana data dalam kumpulan catatan akan diurutkan dan disajikan kepada pengguna. Ini memungkinkan pengguna untuk melakukan hal-hal seperti melompat ke catatan singkat berdasarkan posisi ordinal daftar.
Kami kemudian melihat bahwa pengelompokan dan operasi SQL lainnya yang mencegah pemetaan satu-satu antara baris yang dikembalikan dan baris asli akan menyebabkan Access memperlakukan kueri Access seolah-olah itu adalah kumpulan rekaman tipe snapshot meskipun meminta kumpulan rekaman tipe dynaset.
Kami kemudian melihat bagaimana Access menentukan kunci yang akan digunakan untuk mengelola pembaruan dengan tabel tertaut ODBC. Bertentangan dengan apa yang kita harapkan, itu tidak akan selalu memilih kunci utama tabel melainkan indeks unik pertama yang ditemukannya, tergantung pada jenis indeks dan nama indeks. Kami membahas strategi untuk memastikan bahwa Access akan memilih indeks unik yang benar. Kami melihat tampilan SQL yang biasanya tidak memiliki indeks apa pun dan mendiskusikan metode bagi kami untuk memberi tahu Access cara mengunci tampilan SQL atau tabel yang tidak memiliki kunci utama apa pun, memungkinkan kami lebih mengontrol bagaimana Access akan menangani pembaruan untuk tabel tertaut ODBC tersebut.
Pada artikel berikutnya kita akan melihat bagaimana Access benar-benar menjalankan pembaruan pada data saat pengguna membuat perubahan melalui kueri Access atau sumber rekaman.
Pakar Akses kami siap membantu. Hubungi kami di 773-809-5456 atau email kami di sales@itimpact.com.