Dalam Hadoop kami sebelumnya blog yang telah kami pelajari setiap komponen Hadoop Proses MapReduce secara rinci. Kali ini kita akan membahas topik yang sangat menarik yaitu Map Only job di Hadoop.
Pertama, kita akan membahas pengenalan singkat tentang Peta dan Kurangi tahap di Hadoop Mapreduce, kemudian setelah itu kita akan membahas apa itu pekerjaan Map only di Hadoop MapReduce.
Terakhir kita juga akan membahas kelebihan dan kekurangan job Hadoop Map Only dalam tutorial ini.
Apa itu Pekerjaan Hanya Peta Hadoop?
Pekerjaan Hanya Peta di Hadoop adalah proses di mana mapper melakukan semua tugas. Tidak ada tugas yang dilakukan oleh peredam . Keluaran Mapper adalah keluaran akhir.
MapReduce adalah lapisan pemrosesan data Hadoop. Ini memproses data terstruktur dan tidak terstruktur besar yang disimpan di HDFS . MapReduce juga memproses sejumlah besar data secara paralel.
Ini dilakukan dengan membagi pekerjaan (pekerjaan yang diserahkan) menjadi satu set tugas independen (sub-pekerjaan). Di Hadoop, MapReduce bekerja dengan memecah pemrosesan menjadi beberapa fase:Peta dan Kurangi .
- Peta: Ini adalah tahap pertama pemrosesan, di mana kami menentukan semua kode logika kompleks. Dibutuhkan satu set data dan mengubahnya menjadi set data lain. Itu memecah setiap elemen individu menjadi tupel (pasangan nilai kunci ).
- Kurangi: Ini adalah pemrosesan tahap kedua. Di sini kami menentukan pemrosesan ringan seperti agregasi/penjumlahan. Dibutuhkan output dari peta sebagai input. Kemudian menggabungkan tupel tersebut berdasarkan kunci.
Dari contoh penghitungan kata ini, kita dapat mengatakan bahwa ada dua rangkaian proses paralel, memetakan dan mengurangi. Dalam proses peta, input pertama dibagi untuk mendistribusikan pekerjaan di antara semua node peta seperti yang ditunjukkan di atas.
Kemudian framework mengidentifikasi setiap kata dan memetakan ke nomor 1. Dengan demikian, kerangka tersebut menciptakan pasangan yang disebut pasangan tupel (nilai kunci).
Di simpul pemeta pertama, ia melewati tiga kata singa, harimau, dan sungai. Dengan demikian, menghasilkan 3 pasangan kunci-nilai sebagai output dari node. Tiga kunci dan nilai berbeda disetel ke 1 dan proses yang sama berulang untuk semua node.
Kemudian ia meneruskan tupel ini ke node pereduksi. Partisi melakukan pengocokan sehingga semua tupel dengan kunci yang sama menuju ke simpul yang sama.
Dalam proses reduksi yang pada dasarnya terjadi adalah agregasi nilai atau lebih tepatnya operasi pada nilai yang berbagi kunci yang sama.
Sekarang, mari kita pertimbangkan skenario di mana kita hanya perlu melakukan operasi. Kami tidak memerlukan agregasi, dalam hal ini, kami akan memilih 'Pekerjaan Hanya Peta '.
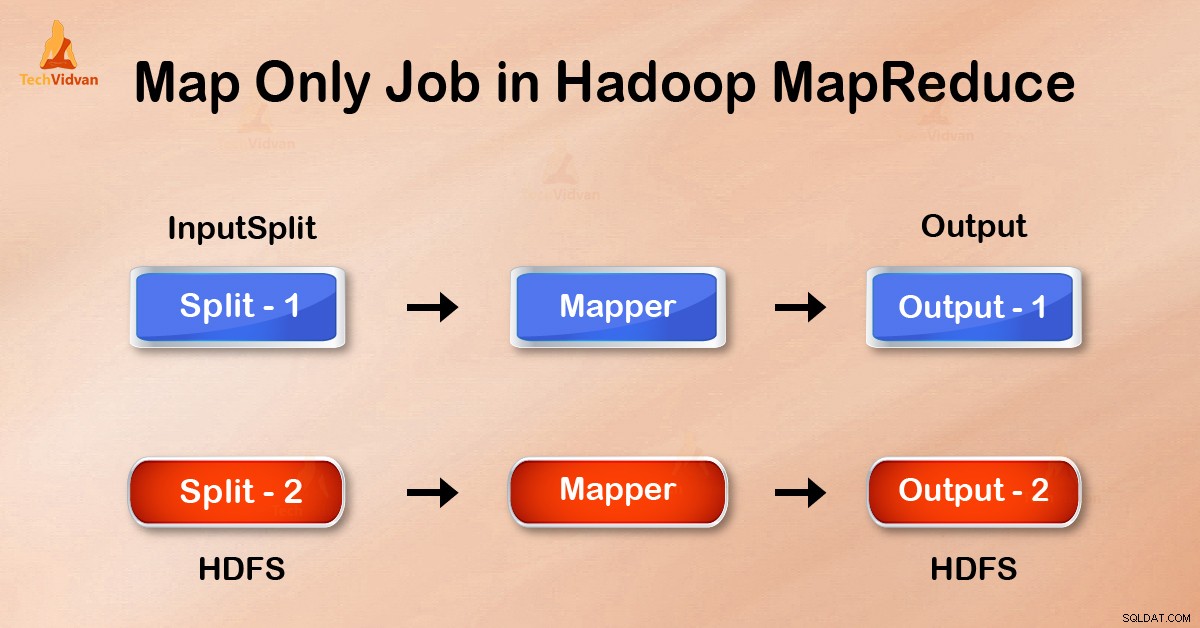
Dalam tugas Map-Only, peta melakukan semua tugas dengan InputSplit . Peredam tidak bekerja. Keluaran pembuat peta adalah keluaran akhir.
Bagaimana cara menghindari Reduce Phase di MapReduce?
Dengan menyetel job.setNumreduceTasks(0) dalam konfigurasi di driver kita dapat menghindari pengurangan fase. Ini akan membuat sejumlah peredam sebagai 0 . Dengan demikian, satu-satunya pembuat peta yang akan menyelesaikan tugas tersebut.
Keuntungan dari pekerjaan hanya Peta di Hadoop
Dalam eksekusi pekerjaan MapReduce di antara fase peta dan pengurangan ada fase kunci, sortir, dan acak. Mengacak –Mengurutkan bertanggung jawab untuk menyortir kunci dalam urutan menaik. Kemudian mengelompokkan nilai berdasarkan kunci yang sama. Fase ini sangat mahal.
Jika fase reduksi tidak diperlukan, kita harus menghindarinya. Karena menghindari fase pengurangan akan menghilangkan fase penyortiran dan pengocokan juga. Oleh karena itu, ini juga akan menghemat kemacetan jaringan.
Alasannya adalah bahwa dalam pengocokan, output dari mapper bergerak untuk mengurangi. Dan ketika ukuran data sangat besar, data yang besar perlu dikirim ke peredam.
Output dari mapper ditulis ke disk lokal sebelum dikirim untuk direduksi. Namun dalam tugas peta saja, keluaran ini langsung ditulis ke HDFS. Hal ini semakin menghemat waktu dan juga mengurangi biaya.
Kesimpulan
Oleh karena itu, kita telah melihat bahwa pekerjaan Map-only mengurangi kemacetan jaringan dengan menghindari fase shuffle, sort, dan reduce. Peta sendiri mengurus keseluruhan pemrosesan dan menghasilkan output. DENGAN menggunakan job.setNumreduceTasks(0) ini tercapai.
Saya harap Anda telah memahami pekerjaan hanya peta Hadoop dan signifikansinya karena kami telah membahas segala sesuatu tentang pekerjaan Hanya Peta di Hadoop. Tetapi jika Anda memiliki pertanyaan, Anda dapat berbagi dengan kami di bagian komentar.



