Tutorial Hadoop . ini adalah semua tentang MapReduce Shuffle dan Sorting. Di sini kami akan memberikan deskripsi mendetail tentang fase Hadoop Shuffling and Sorting.
Pertama kita akan membahas apa itu MapReduce Shuffling, selanjutnya dengan MapReduce Sorting, kemudian kita akan membahas tahap secondary sorting MapReduce secara mendetail.
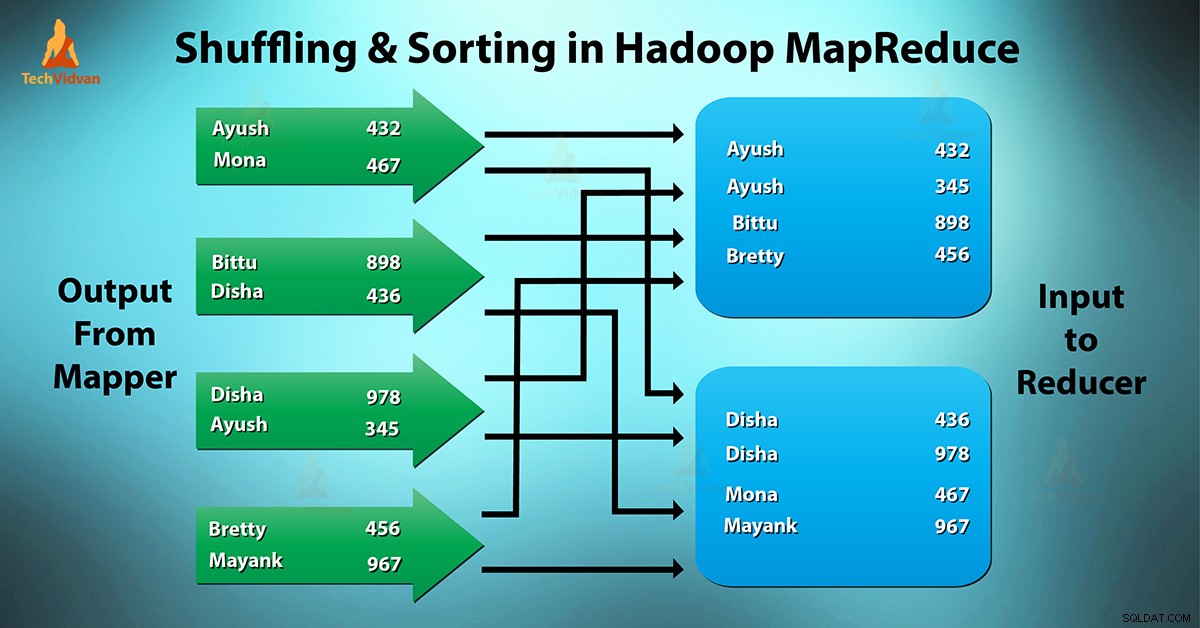
Apa yang dimaksud dengan Pengacakan dan Penyortiran MapReduce?
Mengacak adalah proses transfer pembuat peta keluaran antara ke peredam. Reducer mendapatkan 1 atau lebih kunci dan nilai terkait berdasarkan reduksi.
Kunci perantara – nilai yang dihasilkan oleh mapper diurutkan secara otomatis berdasarkan kunci. Dalam fase Sortir, penggabungan dan pengurutan output peta dilakukan.
Pengacakan dan Penyortiran di Hadoop terjadi secara bersamaan.
Mengacak di MapReduce
Proses mentransfer data dari pembuat peta ke reduksi adalah pengocokan. Ini juga merupakan proses di mana sistem melakukan pengurutan. Kemudian ia mentransfer output peta ke peredam sebagai input. Inilah alasan mengapa fase acak diperlukan untuk reduksi.
Jika tidak, mereka tidak akan memiliki masukan (atau masukan dari setiap pembuat peta). Karena pengocokan dapat dimulai bahkan sebelum fase peta selesai. Jadi ini menghemat waktu dan menyelesaikan tugas dalam waktu yang lebih singkat.
Mengurutkan dalam MapReduce
MapReduce Framework secara otomatis mengurutkan kunci yang dihasilkan oleh pembuat peta. Jadi, sebelum memulai peredam, semua pasangan nilai kunci perantara diurutkan berdasarkan kunci dan bukan berdasarkan nilai. Itu tidak mengurutkan nilai yang diteruskan ke setiap peredam. Mereka bisa dalam urutan apa pun.
Penyortiran dalam tugas MapReduce membantu peredam untuk membedakan dengan mudah kapan tugas pengurangan baru harus dimulai.
Ini menghemat waktu untuk peredam. Peredam di MapReduce memulai tugas pengurangan baru ketika kunci berikutnya dalam data input yang diurutkan berbeda dari yang sebelumnya. Setiap tugas pengurangan mengambil pasangan nilai kunci sebagai input dan menghasilkan pasangan nilai kunci sebagai output.
Hal penting yang perlu diperhatikan adalah bahwa pengacakan dan pengurutan di Hadoop MapReduce tidak akan terjadi sama sekali jika Anda menetapkan nol reduksi (setNumReduceTasks(0)).
Jika peredam adalah nol, maka pekerjaan MapReduce berhenti pada fase peta. Dan fase peta tidak mencakup penyortiran apa pun (bahkan fase peta lebih cepat).
Penyortiran Sekunder di MapReduce
Jika kita ingin mengurutkan nilai peredam, maka kita menggunakan teknik pengurutan sekunder. Teknik ini memungkinkan kita untuk mengurutkan nilai (dalam urutan menaik atau menurun) yang diteruskan ke setiap peredam.
Kesimpulan
Kesimpulannya, Pengurutan dan Penyortiran MapReduce terjadi secara bersamaan untuk meringkas keluaran antara Mapper. Pengurutan Pengacakan Hadoop tidak akan dilakukan jika Anda menetapkan nol reduksi (setNumReduceTasks (0)).
Framework mengurutkan semua pasangan nilai kunci perantara berdasarkan kunci, bukan berdasarkan nilai. Ini menggunakan pengurutan sekunder untuk menyortir berdasarkan nilai. Jika Anda memiliki saran atau pertanyaan terkait dengan fase Pengurutan dan Pengurutan MapReduce, silakan tinggalkan komentar di kotak komentar.
Kami akan dengan senang hati menyelesaikannya.



