Pelaporan Operasional memberikan dukungan untuk pemantauan dan pengendalian aktivitas perusahaan sehari-hari. Tujuan artikel blog ini adalah untuk membuat Anda lebih mengenal laporan operasional yang tersedia di ClusterControl.
Laporan operasional ClusterControl membekali Anda dengan informasi tentang status infrastruktur database Anda, yang dapat Anda gunakan untuk mengaudit lingkungan Anda atau sebagai bagian dari dukungan operasional. Laporan ini terdiri dari pemeriksaan yang berbeda dan menangani berbagai tugas DBA sehari-hari. Ide di balik pelaporan operasional ClusterControl adalah untuk menempatkan semua data yang paling relevan ke dalam satu dokumen yang dapat dianalisis dengan cepat untuk mendapatkan pemahaman yang jelas tentang status database dan prosesnya.
Dengan ClusterControl Anda dapat menjadwalkan laporan lintas lingkungan seperti "Laporan Sistem Harian", "Laporan Peningkatan Paket", "Laporan Perubahan Skema", serta "Cadangan" dan "Ketersediaan". Laporan ini akan membantu Anda menjaga keamanan dan operasional lingkungan Anda. Anda juga akan melihat rekomendasi tentang cara memperbaiki kesenjangan. Laporan dapat ditujukan ke SysOps, DevOps, atau bahkan manajer yang ingin mendapatkan pembaruan status rutin tentang kesehatan sistem tertentu.
Mengapa Saya Membutuhkan Laporan Operasional?
Anda mungkin sudah memiliki alat pemantauan yang sangat baik dengan semua metrik/grafik yang mungkin dan Anda mungkin juga telah menyiapkan peringatan berdasarkan metrik dan ambang batas (beberapa bahkan akan memiliki penasihat otomatis yang memberi mereka rekomendasi atau memperbaiki sesuatu secara otomatis.) Itu bagus - memiliki visibilitas ke dalam sistem itu penting; namun demikian, Anda harus dapat memproses banyak informasi. Alat terintegrasi seperti ClusterControl memiliki keuntungan karena semua bit informasi yang berbeda-beda terletak di tempat yang sama.
Pada sistem yang lebih kecil, Anda mungkin ingin melakukan beberapa pemeriksaan manual, tetapi di lingkungan yang lebih besar, tidak mungkin untuk menganalisis semuanya secara real time. Itu juga terdengar seperti buang-buang waktu. Untuk memastikan sistem Anda dalam kondisi yang baik, Anda harus melalui cukup banyak informasi. Biasanya, itu mencakup statistik host, statistik basis data, status pencadangan, log, dan sebagainya.
Apa yang Harus Dipantau dan Seberapa Sering?
Setelah Anda menyiapkan semua alat pemantauan/pengelolaan basis data, Anda perlu membuat rutinitas untuk memeriksa kesehatan basis data. Seberapa sering Anda ingin melakukannya terserah Anda dan harus didasarkan pada ukuran/beban kerja lingkungan Anda atau oleh standar kepatuhan perusahaan atau industri Anda. Untuk pengaturan yang lebih kecil, pemeriksaan harian akan berfungsi. Untuk konfigurasi yang lebih besar, Anda mungkin harus melakukannya setiap minggu atau lebih. Alasan di baliknya adalah bahwa tes reguler harus memungkinkan Anda untuk bertindak secara proaktif dan memperbaiki masalah apa pun sebelum terjadi atau menjadi parah. Tentu saja, Anda pada akhirnya akan mengembangkan pola Anda, tetapi berikut adalah beberapa tip tentang apa yang mungkin ingin Anda lihat.
Apa yang harus dipantau mungkin terkait dengan peran yang Anda mainkan dalam organisasi TI Anda. DBA, DevOps, Pengembang, atau Manajemen TI masing-masing akan memiliki kebutuhan yang berbeda.
 ClusterControl Laporan operasional
ClusterControl Laporan operasional Penjadwal Laporan Operasi
Sebelum kita mulai menjelaskan laporan operasional tertentu, mari kita lihat sekilas penjadwal laporan. Anda dapat menyiapkan laporan otomatis berulang berdasarkan nama cluster Anda. Tingkat generasi dibagi menjadi jenis harian, mingguan, bulanan. Masing-masing akan memberi Anda opsi untuk menyiapkan laporan sesuai kebutuhan seperti setiap hari ke-5 setiap bulan untuk jenis bulanan atau setiap Selasa jika Anda mengambil laporan Mingguan.
 Penjadwal Laporan Operasional Kontrol Cluster
Penjadwal Laporan Operasional Kontrol Cluster Di bagian kedua dari penjadwal laporan, Anda dapat memilih penerima. Ini adalah kesempatan yang baik untuk menyiapkan beberapa peringatan untuk tim pengelola, kemudian lebih banyak peringatan teknis untuk dukungan TI. Menjadwalkan ini dengan benar dapat sangat menghilangkan tugas dari TI, yaitu ketika manajemen meminta laporan ketersediaan atau tim keamanan perlu mengetahui versi paket dan perubahan skema.
Laporan Cadangan
Laporan Pencadangan Mingguan adalah laporan HTML yang memberikan gambaran umum tentang pencadangan untuk periode pelaporan untuk semua cluster yang dikelola. Laporan cadangan dibagi menjadi dua bagian; ringkasan pencadangan dan detail pencadangan.
Di bagian utama laporan, Anda dapat melihat ringkasan semua klaster Anda dengan jenis klaster, pencadangan terakhir, pencadangan yang gagal dan berhasil, tingkat keberhasilan, dan periode retensi. Yang juga penting adalah Anda juga akan melihat informasi tentang cluster tanpa set cadangan. Ini sangat membantu jika Anda lupa menyetel cadangan atau jika pencadangan berhenti berfungsi karena suatu alasan.
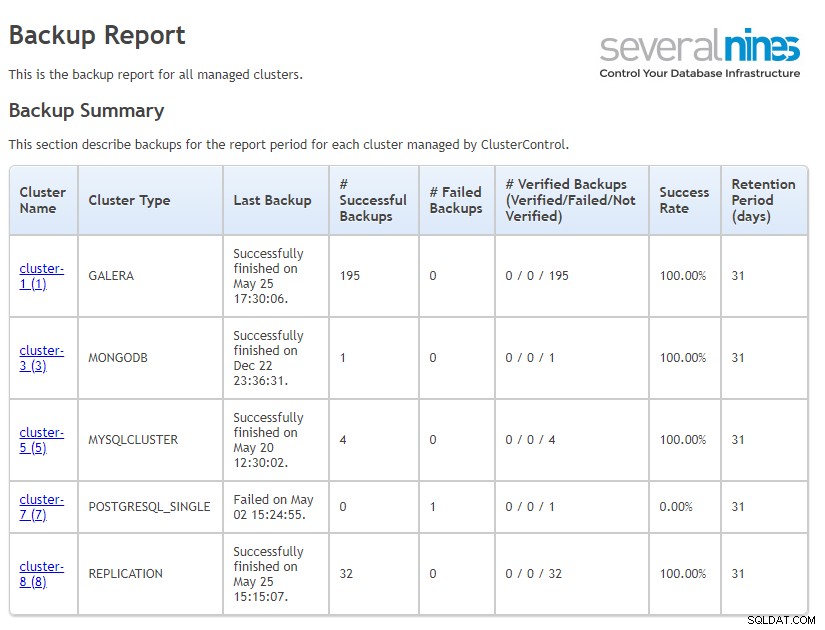 ClusterControl Ringkasan Pencadangan Laporan Operasional
ClusterControl Ringkasan Pencadangan Laporan Operasional Dalam detail pencadangan, Anda dapat melacak ID cadangan tertentu dengan informasi detail tentang lokasi, ukuran, waktu, dan metode. Kami menggunakan template yang sama dengan data untuk tipe database yang berbeda sehingga ketika Anda mengelola lingkungan campuran Anda, Anda akan mendapatkan nuansa dan tampilan yang sama. Ini membantu mengelola cadangan basis data yang berbeda dengan lebih baik.
Bagaimana cara kerja solusi ini? Kami mengumpulkan informasi tentang proses pencadangan, sistem, platform, dan perangkat di infrastruktur pencadangan saat pekerjaan pencadangan dipicu. Semua informasi itu dikumpulkan dan disimpan dalam CMON (database repositori ClusterControl), jadi tidak perlu lagi menanyakan database tertentu.
Laporan Cluster Default
Laporan Cluster Default menyimpan semua informasi rinci tentang cluster tertentu. Dimulai dengan review berbagai alert yang terkait dengan cluster group.
 ClusterControl Laporan klaster default
ClusterControl Laporan klaster default Bagian selanjutnya adalah tentang keadaan node yang merupakan bagian dari cluster. Anda memiliki daftar node dalam cluster, jenisnya, perannya (master atau slave), status node, waktu aktif, dan OS.
 ClusterControl Waktu operasi dan peran simpul laporan klaster default
ClusterControl Waktu operasi dan peran simpul laporan klaster default Bagian lain dari laporan ini adalah ringkasan cadangan, sama seperti yang telah kita bahas di atas.
 ClusterControl Detail cadangan laporan cluster default
ClusterControl Detail cadangan laporan cluster default Berikutnya menyajikan ulasan kueri teratas di cluster. Terakhir, kita melihat “Ikhtisar status node” di mana Anda akan diberikan grafik yang terkait dengan metrik OS dan MySQL untuk setiap node.

 ClusterControl Default gambaran cluster status node
ClusterControl Default gambaran cluster status node Tingkatkan Laporan
Laporan klaster ini akan membantu Anda menjaga paket Anda tetap mutakhir dan aman. Laporan Peningkatan mengumpulkan informasi dari sistem operasi dan membandingkannya dengan paket yang tersedia di repositori.
Laporan ini dibagi menjadi empat bagian; ringkasan upgrade, paket database, paket keamanan, dan paket lainnya. Anda dapat dengan cepat membandingkan apa yang telah Anda instal di sistem Anda dan menemukan peningkatan atau patch yang disarankan.



Laporan Deteksi Perubahan Skema
Laporan Deteksi Perubahan Skema menunjukkan perubahan DDL pada database Anda. Untuk bekerja dengan benar itu memerlukan parameter tambahan dalam file konfigurasi ClusterControl. Jika ini tidak disetel, Anda akan melihat informasi berikut:schema_change_detection_address tidak disetel di /etc/cmon.d/cmon_1.cnf. Setelah itu di tempat contoh output mungkin seperti di bawah ini:
 Laporan perubahan Skema Kontrol Cluster
Laporan perubahan Skema Kontrol Cluster Laporan Ketersediaan
Last but not least adalah Laporan Ketersediaan. Ketersediaan sangat sulit diukur dan dilaporkan, meskipun ini merupakan KPI penting dalam SLA mana pun antara Anda dan pelanggan. Dengan mengingat hal itu, kami membuat laporan yang dapat mengukur waktu aktif basis data Anda. Skrip dimasukkan ke akun Anda selama pemeliharaan terencana yang dapat Anda atur di ClusterControl. Berdasarkan informasi laporan, Anda dapat melihat apakah Anda sejalan dengan SLA internal atau eksternal Anda dan merencanakan perubahan dalam infrastruktur database untuk mempertahankan sembilan yang direncanakan.
 Laporan perubahan Skema Kontrol Cluster
Laporan perubahan Skema Kontrol Cluster Bagian utama dari laporan ini menjelaskan waktu aktif/nonaktif dan ketersediaan untuk periode pelaporan untuk setiap cluster yang dikelola oleh ClusterControl. Informasi tersebut digabungkan untuk semua cluster terlepas dari jenis clusternya.
 ClusterControl Laporan ketersediaan riwayat status cluster
ClusterControl Laporan ketersediaan riwayat status cluster Di bawah secara detail, Anda dapat melihat perubahan status penting yang terjadi dalam periode pelaporan, serta pengontrol dimulai ulang. Pengaktifan ulang pengontrol tidak memengaruhi waktu aktif atau waktu henti dan pemeliharaan yang direncanakan tidak akan dihitung dalam laporan.
 ClusterControl Ketersediaan laporan riwayat simpul
ClusterControl Ketersediaan laporan riwayat simpul Kesimpulan
Somenines ClusterControl dapat membantu Anda mencakup beberapa aspek kepatuhan sistem database Anda. Dimulai dengan detail riwayat pencadangan, yang dapat Anda gunakan untuk melacak hal-hal seperti penyelesaian pencadangan, riwayat, dan server tanpa kebijakan pencadangan yang tepat untuk mengemas laporan pemutakhiran dengan paket sistem usang dan perubahan skema. Dengan beberapa langkah, Anda dapat menjadwalkan pemeriksaan tingkat perusahaan pada database open source Anda. Semua ini akan memberikan wawasan yang lebih baik kepada manajemen dan tim pendukung Anda tentang operasi DB Anda.



