Dapatkan ikhtisar tentang mekanisme yang tersedia untuk mencadangkan data yang disimpan di Apache HBase, dan cara memulihkan data tersebut jika terjadi berbagai skenario pemulihan/kegagalan data
Dengan peningkatan adopsi dan integrasi HBase ke dalam sistem bisnis penting, banyak perusahaan perlu melindungi aset bisnis penting ini dengan membangun strategi pencadangan dan pemulihan bencana (BDR) yang kuat untuk klaster HBase mereka. Kedengarannya menakutkan untuk mencadangkan dan memulihkan data yang berpotensi berukuran petabyte dengan cepat dan mudah, HBase dan ekosistem Apache Hadoop menyediakan banyak mekanisme bawaan untuk mencapai hal itu.
Dalam posting ini, Anda akan mendapatkan ikhtisar tingkat tinggi tentang mekanisme yang tersedia untuk mencadangkan data yang disimpan di HBase, dan cara memulihkan data tersebut jika terjadi berbagai skenario pemulihan/kegagalan data. Setelah membaca posting ini, Anda harus dapat membuat keputusan yang terdidik tentang strategi BDR mana yang terbaik untuk kebutuhan bisnis Anda. Anda juga harus memahami pro, kontra, dan implikasi kinerja dari setiap mekanisme. (Detail di sini berlaku untuk CDH 4.3.0/HBase 0.94.6 dan yang lebih baru.)
Catatan:Pada saat penulisan ini, Cloudera Enterprise 4 menawarkan fungsi pencadangan dan pemulihan bencana siap produksi untuk HDFS dan Hive Metastore melalui Cloudera BDR 1.0 sebagai fitur berlisensi individual. HBase tidak termasuk dalam rilis GA itu; oleh karena itu, diperlukan berbagai mekanisme yang dijelaskan dalam blog ini. (Cloudera Enterprise 5, saat ini dalam versi beta, menawarkan manajemen snapshot HBase melalui Cloudera BDR.)
Cadangan
HBase adalah penyimpanan data terdistribusi gabungan pohon-log terstruktur dengan mekanisme internal yang kompleks untuk memastikan akurasi data, konsistensi, versi, dan sebagainya. Jadi, bagaimana Anda bisa mendapatkan salinan cadangan yang konsisten dari data ini yang berada dalam kombinasi HFiles dan Write-Ahead-Logs (WALs) pada HDFS dan dalam memori pada lusinan server wilayah?
Mari kita mulai dengan yang paling tidak mengganggu, jejak data terkecil, mekanisme yang paling tidak berdampak pada kinerja, dan lanjutkan ke alat bergaya forklift yang paling mengganggu:
- Snapshot
- Replikasi
- Ekspor
- CopyTable
- API yang Dapat Ditampilkan
- Cadangan offline data HDFS
Tabel berikut memberikan ikhtisar untuk membandingkan pendekatan ini dengan cepat, yang akan saya jelaskan secara rinci di bawah ini.
| Dampak Kinerja | Jejak Data | Waktu Henti | Cadangan Tambahan | Kemudahan Penerapan | Mean Time To Recovery (MTTR) | |
| Snapshot | Minimal | Kecil | Ringkasan (Hanya saat Pemulihan) | Tidak | Mudah | Detik |
| Replikasi | Minimal | Besar | Tidak ada | Intrinsik | Sedang | Detik |
| Ekspor | Tinggi | Besar | Tidak ada | Ya | Mudah | Tinggi |
| CopyTable | Tinggi | Besar | Tidak ada | Ya | Mudah | Tinggi |
| API | Sedang | Besar | Tidak ada | Ya | Sulit | Terserah Anda |
| Manual | T/A | Besar | Panjang | Tidak | Sedang | Tinggi |
Snapshot
Pada CDH 4.3.0, snapshot HBase berfungsi penuh, kaya fitur, dan tidak memerlukan waktu henti cluster selama pembuatannya. Rekan saya Matteo Bertozzi meliput snapshot dengan sangat baik di entri blognya dan penyelaman mendalam berikutnya. Di sini saya hanya akan memberikan gambaran umum tingkat tinggi.
Snapshots cukup menangkap momen tepat waktu untuk tabel Anda dengan membuat tautan keras UNIX yang setara ke file penyimpanan tabel Anda di HDFS (Gambar 1). Snapshot ini selesai dalam hitungan detik, menempatkan hampir tidak ada overhead kinerja di cluster, dan membuat jejak data yang sangat kecil. Data Anda tidak diduplikasi sama sekali tetapi hanya dikatalogkan dalam file metadata kecil, yang memungkinkan sistem untuk memutar kembali ke saat itu jika Anda perlu memulihkan snapshot itu.
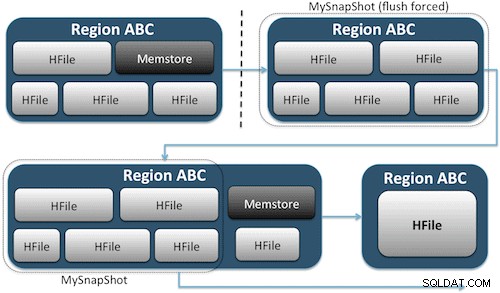
Membuat snapshot tabel semudah menjalankan perintah ini dari shell HBase:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
Setelah mengeluarkan perintah ini, Anda akan menemukan beberapa file data kecil yang terletak di /hbase/.snapshot/myTable (CDH4) atau /hbase/.hbase-snapshots (Apache 0.94.6.1) di HDFS yang berisi informasi yang diperlukan untuk memulihkan snapshot Anda . Memulihkan semudah mengeluarkan perintah ini dari shell:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Catatan:Seperti yang Anda lihat, memulihkan snapshot memerlukan pemadaman singkat karena tabel harus offline. Semua data yang ditambahkan/diperbarui setelah snapshot yang dipulihkan diambil akan hilang.
Jika persyaratan bisnis Anda sedemikian rupa sehingga Anda harus memiliki cadangan data di luar lokasi, Anda dapat menggunakan perintah exportSnapshot untuk menduplikasi data tabel ke dalam kluster HDFS lokal atau kluster HDFS jarak jauh yang Anda pilih.
Snapshots adalah gambar lengkap dari tabel Anda setiap kali; tidak ada fungsi snapshot tambahan yang tersedia saat ini.
Replikasi HBase
Replikasi HBase adalah alat pencadangan overhead yang sangat rendah. (Rekan saya Himanshu Vashishtha membahas replikasi secara mendetail dalam posting blog ini.) Singkatnya, replikasi dapat didefinisikan di tingkat kolom-keluarga, bekerja di latar belakang, dan membuat semua pengeditan tetap sinkron di antara cluster dalam rantai replikasi.
Replikasi memiliki tiga mode:master->slave, master<->master, dan cyclic. Pendekatan ini memberi Anda fleksibilitas untuk menyerap data dari pusat data mana pun dan memastikan bahwa data tersebut direplikasi di semua salinan tabel tersebut di pusat data lainnya. Jika terjadi pemadaman besar-besaran di satu pusat data, aplikasi klien dapat dialihkan ke lokasi alternatif untuk data menggunakan alat DNS.
Replikasi adalah proses yang kuat dan toleran terhadap kesalahan yang memberikan “konsistensi akhir”, yang berarti bahwa setiap saat, pengeditan terbaru ke tabel mungkin tidak tersedia di semua replika tabel itu tetapi dijamin pada akhirnya akan sampai di sana.
Catatan:Untuk tabel yang sudah ada, Anda harus terlebih dahulu menyalin tabel sumber ke tabel tujuan secara manual melalui salah satu cara lain yang dijelaskan dalam posting ini. Replikasi hanya bekerja pada penulisan/pengeditan baru setelah Anda mengaktifkannya.

(Dari halaman Replikasi Apache)
Ekspor
Alat Ekspor HBase adalah utilitas HBase bawaan yang memungkinkan pengeksporan data dengan mudah dari tabel HBase ke SequenceFiles biasa dalam direktori HDFS. Ini menciptakan pekerjaan MapReduce yang membuat serangkaian panggilan API HBase ke cluster Anda, dan satu per satu, mendapatkan setiap baris data dari tabel yang ditentukan dan menulis data itu ke direktori HDFS yang Anda tentukan. Alat ini lebih intensif kinerja untuk cluster Anda karena menggunakan MapReduce dan API klien HBase, tetapi kaya fitur dan mendukung pemfilteran data menurut versi atau rentang tanggal – sehingga memungkinkan pencadangan tambahan.
Berikut adalah contoh perintah dalam bentuk paling sederhana:
hbase org.apache.hadoop.hbase.mapreduce.Export
Setelah tabel Anda diekspor, Anda dapat menyalin file data yang dihasilkan di mana pun Anda inginkan (seperti penyimpanan di luar lokasi/di luar kluster). Anda juga dapat menentukan klaster/direktori HDFS jarak jauh sebagai lokasi keluaran perintah, dan Ekspor akan langsung menulis konten ke klaster jarak jauh. Harap perhatikan bahwa pendekatan ini akan memperkenalkan elemen jaringan ke jalur tulis ekspor, jadi Anda harus mengonfirmasi bahwa koneksi jaringan Anda ke kluster jarak jauh dapat diandalkan dan cepat.
CopyTable
Utilitas CopyTable tercakup dengan baik dalam entri blog Jon Hsieh, tetapi saya akan merangkum dasar-dasarnya di sini. Mirip dengan Ekspor, CopyTable membuat pekerjaan MapReduce yang menggunakan HBase API untuk membaca dari tabel sumber. Perbedaan utama adalah bahwa CopyTable menulis outputnya langsung ke tabel tujuan di HBase, yang dapat bersifat lokal ke cluster sumber Anda atau pada cluster jarak jauh.
Contoh bentuk perintah yang paling sederhana adalah:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
Perintah ini akan menyalin isi tabel bernama “test” ke tabel di cluster yang sama bernama “testCopy.”
Perhatikan bahwa ada overhead kinerja yang signifikan ke CopyTable karena menggunakan "penempatan" individu untuk menulis data, baris demi baris, ke dalam tabel tujuan. Jika tabel Anda sangat besar, CopyTable dapat menyebabkan memstore di server region tujuan terisi, memerlukan flush memstore yang pada akhirnya akan menyebabkan pemadatan, pengumpulan sampah, dan sebagainya.
Selain itu, Anda harus memperhitungkan implikasi kinerja menjalankan MapReduce melalui HBase. Dengan kumpulan data yang besar, pendekatan tersebut mungkin tidak ideal.
API HTable (seperti aplikasi Java khusus)
Seperti yang selalu terjadi pada Hadoop, Anda selalu dapat menulis aplikasi kustom Anda sendiri yang menggunakan API publik dan menanyakan tabel secara langsung. Anda dapat melakukan ini melalui pekerjaan MapReduce untuk memanfaatkan keunggulan pemrosesan batch terdistribusi kerangka kerja itu, atau melalui cara lain apa pun dari desain Anda sendiri. Namun, pendekatan ini memerlukan pemahaman yang mendalam tentang pengembangan Hadoop dan semua API serta implikasi kinerja dari penggunaannya di cluster produksi Anda.
Cadangan Offline Data HDFS Mentah
Mekanisme pencadangan yang paling kasar — juga yang paling mengganggu — melibatkan jejak data terbesar. Anda dapat mematikan klaster HBase dengan bersih dan secara manual menyalin semua data dan struktur direktori yang berada di /hbase di klaster HDFS Anda. Karena HBase tidak aktif, itu akan memastikan bahwa semua data telah disimpan ke HFiles di HDFS dan Anda akan mendapatkan salinan data yang akurat. Namun, pencadangan tambahan hampir tidak mungkin diperoleh karena Anda tidak akan dapat memastikan data apa yang telah diubah atau ditambahkan saat mencoba pencadangan di masa mendatang.
Penting juga untuk dicatat bahwa memulihkan data Anda akan memerlukan perbaikan meta offline karena .META. tabel akan berisi informasi yang berpotensi tidak valid pada saat pemulihan. Pendekatan ini juga membutuhkan jaringan yang cepat dan andal untuk mentransfer data ke luar lokasi dan memulihkannya nanti jika diperlukan.
Karena alasan ini, Cloudera sangat tidak menganjurkan pendekatan ini untuk pencadangan HBase.
Pemulihan Bencana
HBase dirancang untuk menjadi sistem terdistribusi yang sangat toleran terhadap kesalahan dengan redundansi asli, dengan asumsi perangkat keras akan sering gagal. Pemulihan bencana di HBase biasanya datang dalam beberapa bentuk:
- Kegagalan bencana di tingkat pusat data, memerlukan failover ke lokasi cadangan
- Perlu memulihkan salinan data Anda sebelumnya karena kesalahan pengguna atau penghapusan yang tidak disengaja
- Kemampuan untuk memulihkan salinan data Anda tepat waktu untuk tujuan audit
Seperti halnya rencana pemulihan bencana, persyaratan bisnis akan mendorong bagaimana rencana tersebut dirancang dan berapa banyak uang yang akan diinvestasikan di dalamnya. Setelah Anda membuat cadangan pilihan Anda, pemulihan mengambil bentuk yang berbeda tergantung pada jenis pemulihan yang diperlukan:
- Gagal melakukan backup cluster
- Impor Tabel/Pulihkan cuplikan
- Arahkan direktori root HBase ke lokasi pencadangan
Jika strategi pencadangan Anda sedemikian rupa sehingga Anda telah mereplikasi data HBase Anda ke cluster cadangan di pusat data yang berbeda, kegagalan semudah mengarahkan aplikasi pengguna akhir Anda ke cluster cadangan dengan teknik DNS.
Namun, perlu diingat bahwa jika Anda berencana untuk mengizinkan data ditulis ke kluster cadangan selama periode pemadaman, Anda harus memastikan bahwa data kembali ke kluster utama saat pemadaman selesai. Replikasi master-ke-master atau siklik akan menangani proses ini secara otomatis untuk Anda, tetapi skema replikasi master-slave akan membuat kluster master Anda tidak sinkron, memerlukan intervensi manual setelah penghentian.
Bersama dengan fitur Ekspor yang dijelaskan sebelumnya, ada alat Impor terkait yang dapat mengambil data yang sebelumnya dicadangkan oleh Ekspor dan mengembalikannya ke tabel HBase. Implikasi kinerja yang sama yang diterapkan pada Ekspor juga berlaku untuk Impor. Jika skema pencadangan Anda melibatkan pengambilan snapshot, mengembalikan kembali ke salinan data sebelumnya semudah memulihkan snapshot itu.
Anda juga dapat memulihkan dari bencana hanya dengan memodifikasi properti hbase.root.dir di hbase-site.xml dan mengarahkannya ke salinan cadangan direktori /hbase Anda jika Anda telah melakukan salinan offline brute force dari struktur data HDFS . Namun, ini juga merupakan opsi pemulihan yang paling tidak diinginkan karena memerlukan penghentian yang diperpanjang saat Anda menyalin seluruh struktur data kembali ke cluster produksi Anda, dan seperti yang disebutkan sebelumnya, .META. mungkin tidak sinkron.
Kesimpulan
Singkatnya, memulihkan data setelah beberapa bentuk kehilangan atau pemadaman memerlukan rencana BDR yang dirancang dengan baik. Saya sangat menyarankan agar Anda benar-benar memahami persyaratan bisnis Anda untuk waktu aktif, akurasi/ketersediaan data, dan pemulihan bencana. Berbekal pengetahuan mendetail tentang kebutuhan bisnis Anda, Anda dapat dengan cermat memilih alat yang paling sesuai dengan kebutuhan tersebut.
Namun, memilih alat hanyalah permulaan. Anda harus menjalankan pengujian skala besar dari strategi BDR Anda untuk memastikan bahwa itu berfungsi secara fungsional di infrastruktur Anda, memenuhi kebutuhan bisnis Anda, dan bahwa tim operasi Anda sangat memahami langkah-langkah yang diperlukan sebelum pemadaman terjadi dan Anda mengetahui dengan cara yang sulit bahwa rencana BDR Anda tidak akan berhasil.
Jika Anda ingin mengomentari atau mendiskusikan topik ini lebih lanjut, gunakan forum komunitas kami untuk HBase.
Bacaan lebih lanjut:
- Presentasi Strata + Hadoop World 2012 karya Jon Hsieh
- HBase:Panduan Definitif (Lars George)
- Base In Action (Nick Dimiduk/Amandeep Khurana)



