Di blog kami sebelumnya, kami telah mempelajari Pengenalan Hadoop dan Fitur Hadoop , Sekarang di blog ini, kita akan membahas fitur HDFS NameNode High Availability secara detail.
Pertama-tama kita akan membahas tentang HDFS NemNode High Availability Architecture, selanjutnya dengan implementasi Hadoop High Availability Architecture menggunakan Quorum Journal Nodes dan Shared Storage.
HDFS NameNode Ketersediaan Tinggi
Di HDFS , data sangat tersedia dan dapat diakses meskipun terjadi kegagalan perangkat keras. HDFS adalah sistem penyimpanan paling andal yang dirancang untuk menyimpan file yang sangat besar.
HDFS mengikuti topologi master/slave. Di mana master adalah NameNode dan budak adalah DataNode . NameNode menyimpan meta-data. Metadata mencakup jumlah blok, lokasinya, replikanya, dan detail lainnya. Untuk pengambilan data yang lebih cepat, metadata tersedia di master. NameNode memelihara dan memberikan tugas ke node slave.
NameNode adalah Single Point of Failure (SPOF) sebelum Hadoop 2.0. Cluster HDFS memiliki satu NameNode. Jika NameNode gagal, seluruh cluster akan mati.
Satu titik kegagalan membatasi ketersediaan tinggi dengan cara berikut:
- Jika ada pemicu peristiwa yang tidak direncanakan, seperti node mogok, cluster tidak akan tersedia kecuali jika operator memulai ulang namenode baru.
- Aktivitas pemeliharaan yang direncanakan juga seperti peningkatan perangkat keras pada NameNode akan mengakibatkan waktu henti klaster Hadoop.
Arsitektur Ketersediaan Tinggi NameNode HDFS
Pengenalan Hadoop 2.0 mengatasi SPOF ini dengan memberikan dukungan ke beberapa NameNode. Arsitektur HDFS NameNode High Availability menyediakan opsi untuk menjalankan dua NameNode redundan dalam cluster yang sama dalam konfigurasi aktif/pasif dengan hot standby.
- NamaNode Aktif – Ini menangani semua operasi klien HDFS di cluster HDFS.
- Node Nama Pasif – Ini adalah namenode siaga. Ini memiliki data yang mirip dengan NameNode aktif.
Jadi, setiap kali Active NameNode gagal, NameNode pasif akan mengambil semua tanggung jawab node aktif. Dengan demikian, cluster HDFS terus bekerja.
Masalah dalam menjaga konsistensi di cluster HDFS High Availability adalah sebagai berikut:
- Active dan Standby NameNode harus selalu sinkron satu sama lain, yaitu mereka harus memiliki metadata yang sama. Izin ini untuk memulihkan kluster Hadoop ke status namespace yang sama dengan yang mengalami error. Dan ini akan memberi kita kegagalan cepat.
- Seharusnya hanya ada satu NameNode yang aktif dalam satu waktu. Jika tidak, dua NameNode akan menyebabkan kerusakan data. Kami menyebut skenario ini sebagai “Skenario Terpisah-Otak ”, dimana sebuah cluster akan dibagi menjadi cluster yang lebih kecil. Masing-masing percaya bahwa itu adalah satu-satunya cluster yang aktif. "Fencing" menghindari Fencing seperti itu adalah proses untuk memastikan bahwa hanya satu NameNode yang tetap aktif pada waktu tertentu.
Implementasi Hadoop High Availability Architecture
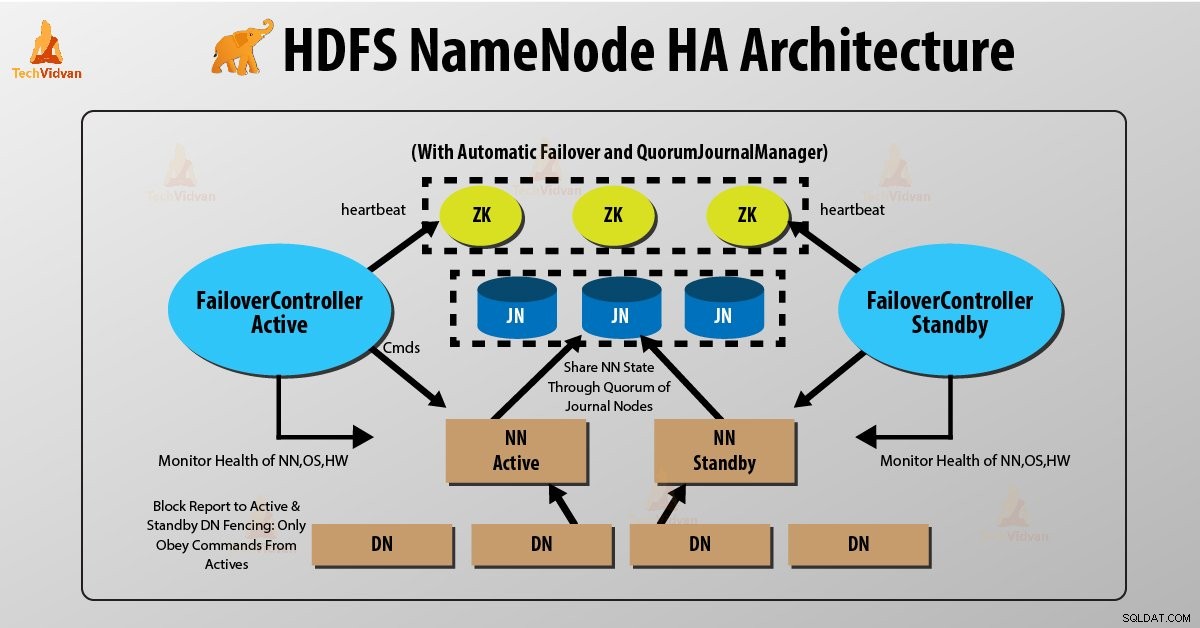
Dua NameNode berjalan pada waktu yang sama di HDFS NameNode High Availability Architecture. Klien HDFS dapat mengimplementasikan konfigurasi Active dan Standby NameNode dengan dua cara berikut:
- Menggunakan Node Jurnal Kuorum
- Menggunakan Penyimpanan Bersama
1. Menggunakan Node Jurnal Kuorum
Node Jurnal Kuorum adalah implementasi HDFS. QJN menyediakan log edit. Ini memungkinkan untuk membagikan log edit ini antara NameNode yang aktif dan standby.
Siaga Namenode berkomunikasi dan menyinkronkan dengan NameNode aktif untuk ketersediaan tinggi. Itu akan terjadi oleh sekelompok daemon yang disebut "Journal node". Node Jurnal Kuorum berjalan sebagai sekelompok node jurnal. Setidaknya tiga node jurnal harus ada di sana.
Untuk N node jurnal, sistem dapat mentolerir paling banyak (N-1)/2 kegagalan. Dengan demikian, sistem terus bekerja. Jadi, untuk tiga node jurnal, sistem dapat mentolerir kegagalan satu {(3-1)/2} di antaranya.
Setiap kali node aktif melakukan modifikasi apa pun, ia mencatat modifikasi ke semua node jurnal.
Simpul siaga membaca suntingan dari simpul jurnal dan berlaku untuk Namespace-nya sendiri secara konstan. Dalam kasus failover, standby akan memastikan bahwa ia telah membaca semua suntingan dari node jurnal sebelum mempromosikan dirinya ke status Aktif. Ini memastikan bahwa status namespace benar-benar disinkronkan sebelum terjadi kegagalan.
Untuk memberikan failover cepat, node siaga harus memiliki informasi terbaru tentang lokasi blok data di cluster. Agar hal ini terjadi, alamat IP dari NameNode tersedia untuk semua datanode dan mereka mengirim informasi lokasi blok dan detak jantung ke kedua NameNode.
Pagar NameNode
Untuk operasi cluster HA yang benar, hanya satu NameNodes yang harus aktif pada satu waktu. Jika tidak, status namespace akan menyimpang di antara dua NameNodes. Jadi, pagar adalah proses untuk memastikan properti ini dalam sebuah cluster.
- Node jurnal melakukan pagar ini dengan mengizinkan hanya satu NameNode menjadi penulis pada satu waktu.
- NameNode standby bertanggung jawab untuk menulis ke node jurnal dan melarang NameNode lainnya untuk tetap aktif.
- Akhirnya NameNode yang baru aktif dapat melakukan aktivitasnya.
2. Menggunakan Penyimpanan Bersama
NameNode yang standby dan aktif melakukan sinkronisasi satu sama lain dengan menggunakan “perangkat penyimpanan bersama”. Untuk implementasi ini, NameNode aktif dan Namenode standby harus memiliki akses ke direktori tertentu pada perangkat penyimpanan bersama (yaitu Sistem file jaringan).
Saat NameNode aktif melakukan modifikasi namespace apa pun, ia mencatat catatan modifikasi ke file log edit yang disimpan di direktori bersama. NameNode standby mengawasi direktori ini untuk pengeditan, dan ketika pengeditan terjadi, NameNode standby menerapkannya ke namespacenya sendiri. Jika terjadi kegagalan, NameNode standby akan memastikan bahwa ia telah membaca semua suntingan dari penyimpanan bersama sebelum mempromosikan dirinya ke status Aktif. Ini memastikan bahwa status namespace benar-benar disinkronkan sebelum terjadi failover.
Untuk mencegah "skenario split-brain" di mana status namespace menyimpang di antara dua NameNode, administrator harus mengonfigurasi setidaknya satu metode pagar untuk penyimpanan bersama.
Kesimpulan
Oleh karena itu, Hadoop 2.0 HDFS HA menyediakan NameNode aktif tunggal dan NameNode standby tunggal. Namun beberapa penerapan memerlukan tingkat toleransi kesalahan yang tinggi . Hadoop versi baru 3.0, memungkinkan pengguna untuk menjalankan banyak NameNodes standby.
Misalnya, mengkonfigurasi lima journalnode dan tiga NameNode. Akibatnya hadoop cluster mampu mentolerir kegagalan dua node daripada satu.
Silakan bagikan pengalaman dan saran Anda terkait HDFS NameNode High Availability di bagian komentar di bawah.



